






HashMap和HashTable的区别
先说结论:
HashMap 线程是不安全的 (没有使用锁)
HashTable 线程是安全的 (使用了synchronized)
HashMap 允许存放key值 null 存放在 index=0 的位置
HashTable 不允许存放key值为null
测试如下:
源码:
package hashmapTest;
import java.util.HashMap;
import java.util.Hashtable;
/**
* @BelongsProject: ConcurrentHashMap
* @BelongsPackage: hashmapTest
* @Author: 晚风
* @CreateTime: 2023-02-26 14:54
* @Description: TODO
* @Version: 1.0
*/
public class Test01 {
public static void main(String[] args) {
// 1. HashMap 和 HashTable 的区别
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put(null,"");
/**
* 在多线程的情况下 同时写的操作, 使用put方法
* 会共享到同一个table数组 就会发生线程安全问题
* 为了不涉及线程安全的问题。这个时候就要使用 HashTable
* HashTable
*/
Hashtable<Object, Object> hashtable = new Hashtable<>();
hashtable.put(null,"");
}
}其中: HashMap的put源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}看不懂没关系,我也看不懂,可以看成事没有加锁的HashTable
HashTable的put源码:
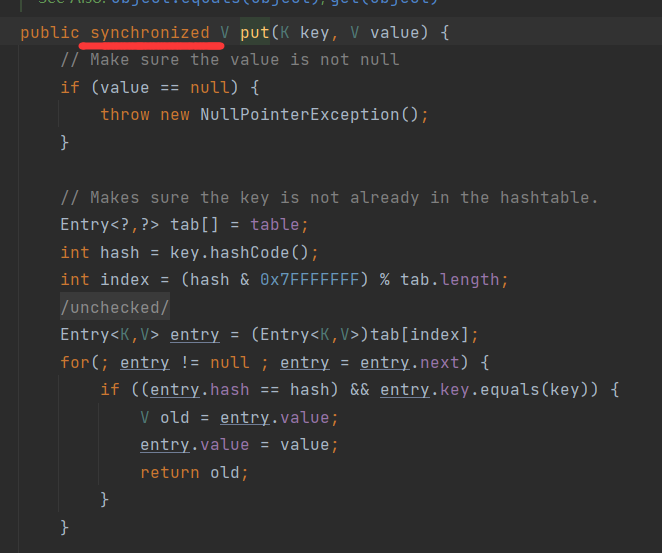
这里使用了 synchronized锁,保证了线程安全性。
测试1: 注掉第28行的 hashtable.put(null,"");
运行结果:

测试2:注释掉 18行的hashMap.put(null,"");
运行结果:
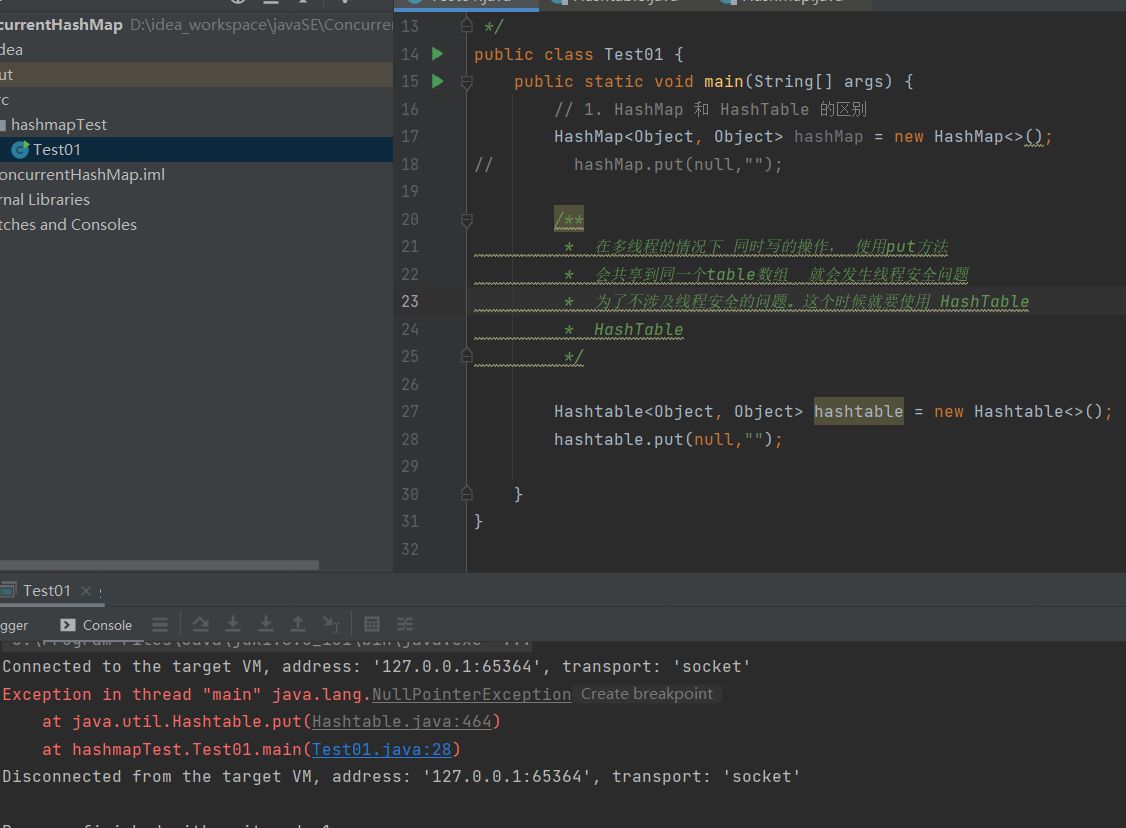
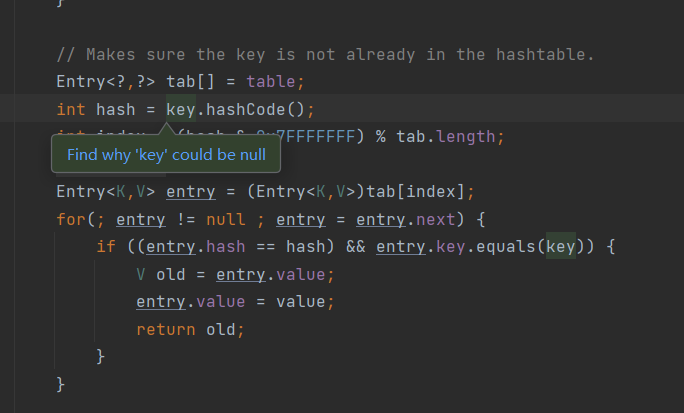
这里报了空指针异常,点击进来之后的源码
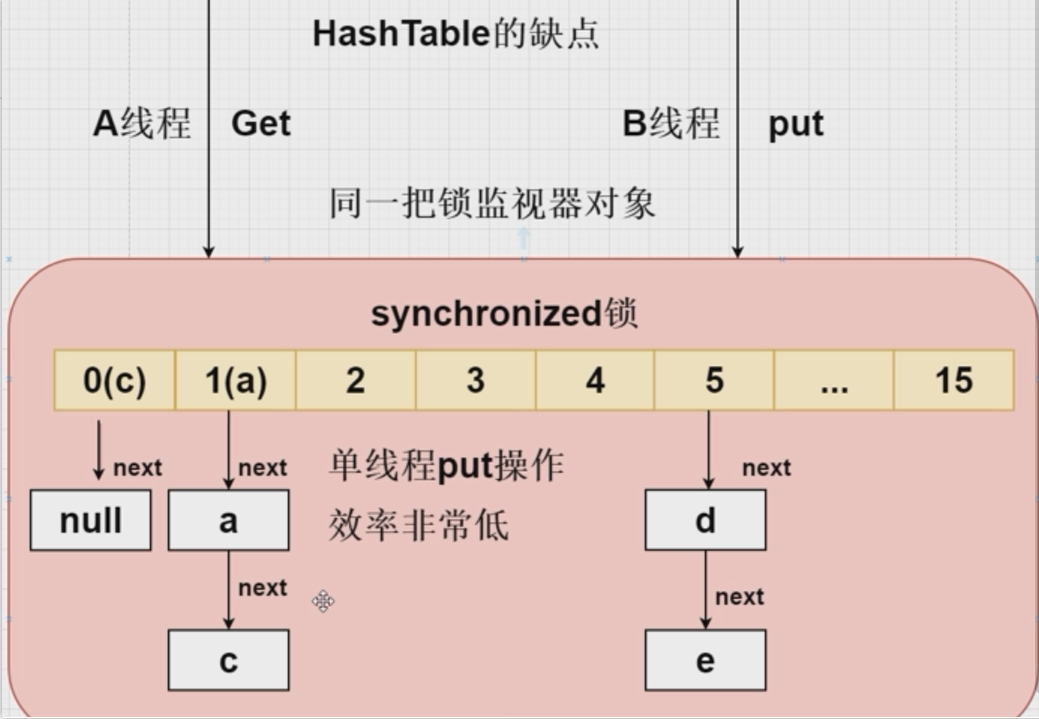
为什么不使用HashTable
HashTable 底层 通过 synchronized 保证线程安全性问题
保证线程安全性问题 ---加上锁 --- 发生锁的竞争
HashTable 当多个线程在访问get或者put操作的时候会发生this锁的竞争,多个线程竞争锁 最终只会有一个线程获取到this锁,获取不到的this锁 可能会阻塞等待。最终将我们的HashTable中的get或者put方法改成单线程执行 效率是非常低的
所以在多线程的情况下不推荐使用 HashTable
package hashmapTest;
import java.util.Hashtable;
/**
* @BelongsProject: ConcurrentHashMap
* @BelongsPackage: hashmapTest
* @Author: 晚风
* @CreateTime: 2023-02-26 19:23
* @Description: TODO
* @Version: 1.0
*/
public class Test02 {
public static void main(String[] args) {
// 线程安全性 当多个线程 在同时访问到 同一个共享数据 做写的操作的时候 会发生线程安全性的问题? 会
// 当多个线程 同时访问到 同一个共享数据 做读的操作的时候 不会
Hashtable<Object, Object> hashtable = new Hashtable<>();
new Thread(new Runnable() {
@Override
public void run() {
hashtable.put("a","a");
}
},"a线程").start();
new Thread(new Runnable() {
@Override
public void run() {
hashtable.get("a");
}
},"b线程").start();
/**
* b线程 获取到 this 锁在做get操作, 另外的线程无法 访问 hashTable做get或者put操作
* */
}
}3.ConcurrentHashMap1.7实现原理
ConcurrentHashMap 1.7
就是将一个大的HashTable集合拆分成n多个HashTable集合 (默认16个) ----分段锁设计
concurrentHashMap 1.8
取消了分段锁的设计
ConcurrentHashMap get方法没有锁的竞争
HashTable get方法有锁的竞争
如图:
在一个大的HashTable集合中,synchronized锁直接锁住了所有的index,所以多线程会变成单线程(synchronized是那个红色的,把所有的都包裹住了)
而在ConcurrentHashMap 1.7 中,如图:
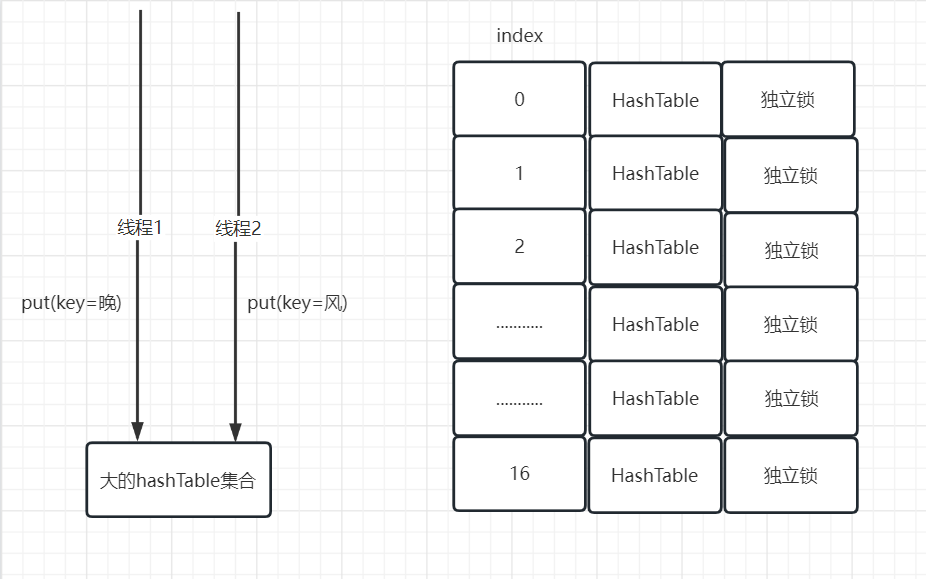
例如:现在有(进程1 key=晚) (进程2 key=风)两个线程对一个大的hashTable进行操作, 一个大的hashTable会分成多个小的hashTable(默认16个,也可以更多或者更少),。
假如现在线程1 晚根据key(晚)计算存放具体的小的 HashTable index=2;线程2 风根据key(风)计算存放具体的小的 HashTableindex=16的hashTable,那么请问会不会发生锁的竞争呢?
答案是: 不会的,这个大家应该知道。
那现在又假如: 假如现在线程1 晚根据key(晚)计算存放具体的小的 HashTable index=2;线程2 风根据key(风)计算存放具体的小的 HashTableindex=2的hashTable,那么请问会不会发生锁的竞争呢?
答案是: 会,但是这个概率很小,对吧,毕竟有16个小的甚至可能更多。
那么给出结论:
在多线程的情况下访问我们的ConcurrentHashMap 1.7做写的操作,如果多个线程写入的key最终计算落到不同的小的HashTable集合中,那就可以实现我们的多线程同时写入key,不会发生锁的竞争。
在多线程的情况下访问我们的ConcurrentHashMap 1.7做写的操作,如果多个线程写入的key最终计算落到相同的小的HashTable集合中,那就不可以实现我们的多线程同时写入key,就会发生锁的竞争。
4.手写出ConcurrentHashMap
按照前面的思路,代码如下:
package hashmapTest;
import java.util.Hashtable;
/**
* @BelongsProject: ConcurrentHashMap
* @BelongsPackage: hashmapTest
* @Author: 晚风
* @CreateTime: 2023-02-26 23:22
* @Description: TODO
* @Version: 1.0
*/
public class ConcurrentHashMap<K, V> {
/**
* 先创建一个 存放 小的HashTable的集合
* */
private Hashtable<K, V>[] hashtables;
/**
* ConcurrentHashMap该怎么设计呢
* 1.首先创建出默认的十六个小的HashTable集合
* */
public ConcurrentHashMap(){
hashtables = new Hashtable[16];
for (int i = 0; i < hashtables.length; i++) {
hashtables[i] = new Hashtable<>();
}
}
public void put(K k, V v){
//1.首先计算出最小的HashTable 集合中
int indexHashTable = k.hashCode()%hashtables.length;
//2.将key存入最小的HashTable 集合中
hashtables[indexHashTable].put(k, v);
}
public V get(K k){
//1.还是首先计算出最小的HashTable集合
int indexHashTable = k.hashCode()%hashtables.length;
//2.然后读取最小的HashTable集合中的值
return hashtables[indexHashTable].get(k);
}
public static void main(String[] args) {
ConcurrentHashMap<String, String> concurrentHashMap = new ConcurrentHashMap<>();
concurrentHashMap.put("m","m");
concurrentHashMap.put("n","n");
System.out.println(concurrentHashMap.get("m"));
}
}
运行结果如下:
总结:ConcurrentHashMap 底层采用 分段锁设计 将一个大的HashTable 线程安全的集合拆分成n多个小的HashTable集合,默认初始化16个小的HashTable集合。
如果同时16个线程 最终计算index值 落地到不同的小的HashTable集合 不会发生锁的竞争,同时可以支持16个线程访问 ConcurrentHashMap 写的操作, 效率非常高
(都是看的课程里面,最后总结和课程里面的知识)















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









