






HiBench 是一个大数据基准套件,可帮助评估不同的大数据框架的速度、吞吐量和系统资源利用率。
它包含一组 Hadoop、Spark 和流式工作负载,包括 Sort、WordCount、TeraSort、Repartition、Sleep、SQL、PageRank、 Nutch indexing、Bayes、Kmeans、NWeight 和增强型 DFSIO 等。
它还包含多个用于 Spark Streaming 的流式工作负载、Flink、Storm 和 Gearpump。
hibench作为一个测试hadoop的基准测试框架,提供了对于hive:(aggregation,scan,join),排序(sort,TeraSort),大数据基本算法(wordcount,pagerank,nutchindex),机器学习算法(kmeans,bayes),集群调度(sleep),吞吐(dfsio),以及新加入5.0版本的流测试: we provide following streaming workloads for SparkStreaming, Storm .
HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming。
本节测试hadoop的sort、wordcount、sleep以及dfsio,都是micro这个类别。
一、ubuntu下安装hadoop
1、创建hadoop用户
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限
$ su - hadoop #切换当前用户为用户hadoop
$ sudo apt-get update #更新hadoop用户的apt,方便后面的安装2、安装ssh,并且设置ssh无密码登录
$ sudo apt-get install openssh-server #安装SSH server
$ ssh localhost #登陆SSH,第一次登陆输入yes
$ exit #退出登录的ssh localhost
$ cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
$ ssh-keygen -t rsa
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost 3、jdk安装
$ sudo apt-get install openjdk-8-jre openjdk-8-jdk
$ cd
$ vim .bashrc #添加JAVA PATH
# JAVA PATH
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64添加后先按ESC,然后再输入ZZ(两个大写),然后更新环境变量
$ source .bashrc
$ java -version #测试java环境看到相应版本信息输出即表明配置正确
4、hadoop安装
先在windows下去这个网站下载https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz(ubuntu里面下载速度太慢),然后把文件传到ubuntu里面,再解压缩(由于后面要下载HiBench,而保证HiBench配置成功的前提就是要保证hadoop的版本是要2.x,最好不要下载3.x的版本)
下载后
$ sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local
$ sudo mv hadoop-2.6.0 hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop 安装好后,在hadoop用户下给hadoop配置环境变量,若用户不是hadoop则输入 su - hadoop切换用户 切换完成后输入 vim /etc/profile(权限要求root) 在文件底部添加
export HADOOP_HOME=/usr/local/hadoop #这里的路径不能照抄,要找到自己hadoop刚刚解压到哪里了
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后按ESC,再输入ZZ(大写)保存退出
最后输入
$ hadoop version出现版本信息则证明成功了
5、hadoop伪分布式配置
$ cd /usr/local/hadoop/etc/hadoop/
$ vim core-site.xml然后修改里面<configuration>的内容为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>保存退出,然后
$ vim hdfs-site.xml修改里面<configuration>的内容为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后:
$ cd
$ cd /usr/local/hadoop
$ bin/hdfs namenode -format # namenode 格式化
$ sbin/start-dfs.sh # 开启守护进程
$ jps # 判断是否启动成功若成功启动后会有以下显示

二、安装HiBench
前提要求
python 2.x(x>=2.6)
$ python --version #输入这个即可查看当前版本若不符合要求
$ sudo apt-get install python2.7
$ sudo apt update即可
1、安装maven
$ wget https://dlcdn.apache.org/maven/maven-3/3.8.5/binaries/apache-maven-3.8.5-bin.zip --no-check-certificate
$ unzip apache-maven-3.8.5-bin.zip -d /usr/local/
$ cd
$ vim .bashrc进入后添加maven环境
# set maven environment
export M3_HOME=/usr/local/apache-maven-3.8.5
export PATH=$M3_HOME/bin:$PATH保存退出后:
$ source .bashrc
$ mvn -v若显示出maven版本号相关信息则表明成功
换镜像加快下载速度
$ vim /usr/local/apache-maven-3.8.5/conf/setting.xml<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>安装bc(bc 用于生成 report 信息,再后面运行完后能看到运行的时间等信息)
$ sudo apt-get install bc2、下载HiBench
$ cd
$ git clone https://github.com/intel-bigdata/HiBench.git #若报错则把https换成http切到HiBench下(进入你安装的HiBench的目录下),执行对应的安装操作,可以选择自己想要安装的模块。以安装hadoop框架下用于测试sql的模块为例:
$ mvn -Phadoopbench -Dmodules -Psql -Dscala=2.11 clean package或者构建全部框架:
$ mvn -Dspark=2.4 -Dscala=2.11 clean package成功后如下图所示:
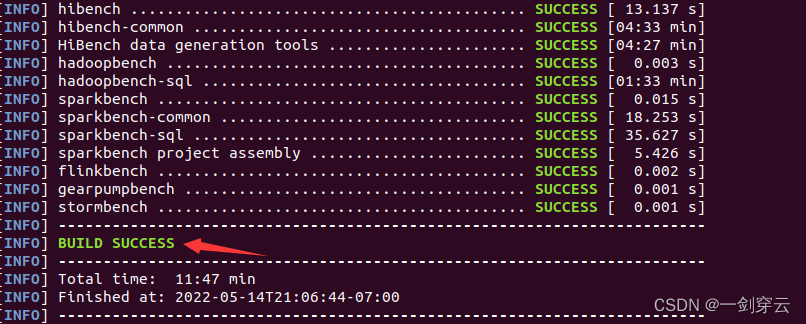
3、配置HiBench
1、hibench.conf,配置数据集大小和并行度
$ cd
$ cd HiBench/conf
$ vim HiBench.conf# Data scale profile. Available value is tiny, small, large, huge, gigantic and bigdata.
# The definition of these profiles can be found in the workload's conf file i.e. conf/workloads/micro/wordcount.conf
hibench.scale.profile tiny
# Mapper number in hadoop, partition number in Spark
hibench.default.map.parallelism 8
# Reducer nubmer in hadoop, shuffle partition number in Spark
hibench.default.shuffle.parallelism 82、hadoop.conf,配置hadoop集群的相关信息,这一步要搞清楚自己机器上hadoop的安装目录,不能照抄
$ cp hadoop.conf.template hadoop.conf
$ vim hadoop.conf # Hadoop home hadoop的家目录
hibench.hadoop.home /usr/local/hadoop #这个是上面hadoop的安装目录
# The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop
# Hadoop configraution directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop
# The root HDFS path to store HiBench data
hibench.hdfs.master hdfs://master:9000
# Hadoop release provider. Supported value: apache
hibench.hadoop.release apache上面HDFS的path是怎么得到的呢?需要到hadoop的安装目录下找到etc/hadoop/core-site.xml,就能看到hdfs的命名空间
amax@master:/usr/local/hadoop/etc/hadoop$ vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 配置操作hdfs的存冲大小 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 配置临时数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
~3、修改frameworks.lst和benchmark.lst(两个文件都在conf文件夹内),指定要使用的benchmark和在哪个平台上运行,上面下载的是hadoop,所以在frameworks.lst中把spark注释掉
hadoop
#spark这里对hadoop的sort、wordcount、sleep以及dfsio进行测试,所以把benchmark.lst文件里其他注释掉
micro.sleep
micro.sort
micro.terasort
micro.wordcount
micro.repartition
micro.dfsioe
#sql.aggregation
#sql.join
#sql.scan
#websearch.nutchindexing
#websearch.pagerank
#ml.bayes
#ml.kmeans
#ml.lr
#ml.als
#ml.pca
#ml.gbt
#ml.rf
#ml.svd
#ml.linear
#ml.lda
#ml.svm
#ml.gmm
#ml.correlation
#ml.summarizer
#graph.nweight4、运行HiBench 在运行过程中我碰到的错误是,提示Get workers from yarn-site.xml page failed,这也有可能是很多人会碰到的,解决办法是: 在HiBench安装目录conf目录下修改hibench.conf文件,要配置hibench.masters.hostnames 和hibench.slaves.hostnames两项。 配置为集群的master节点和slaves节点对应的主机名。
hibench.masters.hostnames node1.novalocal #文件里面这两行的hostnames后面原本都是空的
hibench.slaves.hostnames node1.novalocal node2.novalocal node3.novalocal若打开文件一时找不到,可以用里面的搜索功能:
这样子就能找到了。(很多教程都没有说这一步,导致配了很多次,上网找才到这个问题解决办法)

然后要在hadoop的安装目录下启动hadoop
$ ./start-all.sh接着切换到Hibench目录下,增加权限(要直到自己的目录在哪,我这里是直接安装在home的目录下,所以cd后能直接cd HiBench/bin)
$ cd
$ cd HiBench/bin
$ chmod +x -R functions/
$ chmod +x -R workloads/
$ chmod +x run_all.sh然后执行
$ ./run_all.sh当出现这样子时就证明运行成功了

此时因为我们是在HiBench/bin目录下运行./run_all.sh指令的,要想查看测试生成的报告,要到report文件夹下,report文件夹在HiBench文件夹下,和bin是同级的
$ cd
$ cd HiBench/report然后打开hibench.report文件夹即可
$ cat hibench.report显示的效果类似于下图
 :
:
Duration:运行时间
Throughput :实际吞吐量(单位时间内的字节数)
Throughput/node:每个节点的吞吐量
然后输入以下命令能查看日志文件
$ cd wordcount/hadoop/
$ cat bench.log 
这样子就完成啦!















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









