







 本文详细介绍了分布式环境下的GHS算法,这是一种基于Prim算法的分布式最小生成树构建方法。文章涵盖了最小生成树的概念,稠密图与稀疏图的区别,以及Prim和Kruskal经典算法的概述。重点解析了GHS算法的原理,包括汇聚传输、初始化、Test与Report过程,以及消息后置机制。此外,通过多个示例展示了算法的运行过程,突显了分布式算法在处理大规模图计算问题上的优势。
本文详细介绍了分布式环境下的GHS算法,这是一种基于Prim算法的分布式最小生成树构建方法。文章涵盖了最小生成树的概念,稠密图与稀疏图的区别,以及Prim和Kruskal经典算法的概述。重点解析了GHS算法的原理,包括汇聚传输、初始化、Test与Report过程,以及消息后置机制。此外,通过多个示例展示了算法的运行过程,突显了分布式算法在处理大规模图计算问题上的优势。
分布式最小生成树算法
作为分布式算法中的经典算法之一,GHS分布式最小生成树算法的相关资料却并不多见,相关的原理介绍只是范范而谈,代码实现也比较少见。本文将汇总目前网络上可查阅的相关参考资料并结合自己的理解,旨在深入理解GHS的算法核心与实现细节
介绍
最小生成树
给定一个加权图 G = ( V , E ) G=(V,E) G=(V,E),产生一个生成树 T = ( V , E ′ ) T=(V,E') T=(V,E′) 使得所有边的权重和最小
可应用于城市中的光缆布局,欧几里得平面内的旅行商问题(这是一个经典NP-hard问题)等等相关问题

注意:如果每个边的权重值不同,那么MST是唯一的
稀疏与稠密
稠密表示
具有权重边以及n个点的图 G = ( V , E ) G=(V,E) G=(V,E)可以使用不同的数据结构进行表示。其中,邻接矩阵是一个大小为 ∣ V ∣ × ∣ V ∣ |V|×|V| ∣V∣×∣V∣的矩阵,矩阵中的元素为 w ( u , v ) w(u,v) w(u,v)(其中 u u u 表示索引行, v v v 表示索引列)。其表示与 ∣ V ∣ 2 |V|^2 ∣V∣2成正比,与 ∣ E ∣ |E| ∣E∣ 无关,我们称其为稠密表示
稠密图与稀疏图
有很少条边(边的条数 ∣ E ∣ |E| ∣E∣接近要连接的图的最小边数 ∣ E ∣ = O ( ∣ V ∣ ) |E|=O(|V|) ∣E∣=O(∣V∣))的图称为稀疏图(sparse graph),反之边的条数 ∣ E ∣ |E| ∣E∣接近 ∣ V ∣ 2 |V|^2 ∣V∣2,称为稠密图(dense graph)
Prim算法
两种经典MST单机算法之一。算法的每一步都会为生长中的树添加一条边,该树最开始只有一个顶点,然后会添加 V − 1 V-1 V−1 个边,每次添加的是外围具有最小权重的边。
Kruskal算法
按照边的权重顺序(从小到大)将边加入生成树中,但是若加入该边会使其与生成树形成环则不加入。直到树中含有 V − 1 V-1 V−1 条边为止,这些边组成的就是该图的最小生成树。
目前,既不能证明不存在能在线性时间内得到任意图的最小生成树的算法,也未能发明能够在线性时间内计算稀疏图的最小生成树的算法。
分布式最小生成树算法
其中最经典的便是GHS算法(分布式版本下的Prim算法),MST通过以片段的最小权重边相互联合完成构造。
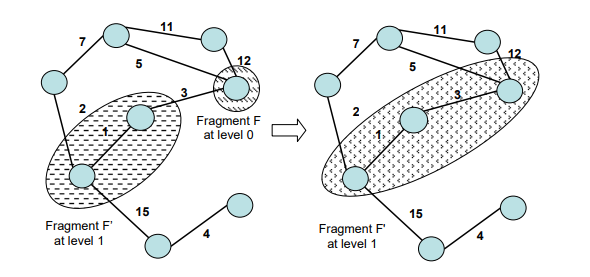
汇聚传输(Convergecast)
这个类似于广播,但是唯一不同的是发送信息的节点变成了收到信息的节点。在广播时,一个节点要向所有节点发送消息,但汇聚传输变成了所有节点要向某一节点发消息,也就是这个节点要汇聚其他节点发送的消息。一个最简单的汇聚传输算法便是echo算法,一个叶子结点发送一个消息给他的父节点,如果一个内部节点(非叶子结点)从他所有的子节点收到了消息,那么他将会把这个消息发送给他的父节点。这个算法很简单,但是其实限制非常多,所以我们需要用到其他方式来辅助实现。通常回波算法与泛洪算法配对,泛洪算法用来让叶子知道它们应该开始回波过程,这被称为泛洪/回声。
GHS算法过程
前提假设
- 输入图是连通且无向的
- 输入图中的每条边都有不同的有限权重。(如果增加相应的唯一性处理,则不需要此假设)
- 每个节点最初都知道其连接的每条边的权重
- 在初始状态下,每个节点都处于非活动状态。每个音符要么自发唤醒,要么被从另一个节点接收到的任何消息唤醒
- 消息可以在边缘的两个方向上独立传输,并在未知但有限的延迟后到达,不会出现通信错误
- 每个边以FIFO(先进先出)顺序传送消息
状态
边
一旦被标记为Branch或者Rejected将不可再被改变
- Basic(初始状态)
- Branch(MST边)
- Rejected(非MST边)
点变量
- 点状态(SN)
- Found
- Sleeping
- Find
- Find-count
- Level:片段等级
- FN
- in-branch
- best-edge
- best-wt
主体循环
其算法以片段为核心,我们从整个片段的角度思考
- 区分出片段中的出边,并决断出片段中的最小权重出边,记为最小生成树的一条边(对应伪代码5,6,7,8,9,10,11,12)
- 联合过程:发送合并/吸收请求或者相应合并/吸收请求(对应伪代码3)
- 更新同步信息(对应伪代码4)
循环上述过程直到没有外出边,各个步骤具体介绍见下
片段内部处理
问题1:在一个片段内我们如何确定用于向外连接的那些边呢?
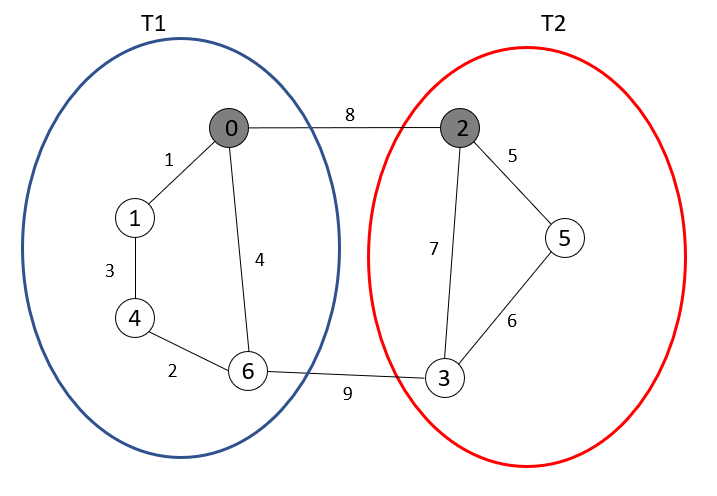
我们通过引入根节点(root node)并结合消息广播与汇聚传输来解决这个问题。
问题2:以0根节点为例,我们如何使得选择的是权重为8的边而非4呢?
在扩增之前我们先同片段内的节点以相同的标识(name)
通过测试过程(test),每个节点通过向邻边发送test消息,接受的节点回复accept或者reject
根节点通过广播初始化其片段,并使用汇聚传输从片段中的节点收集符合条件边的report信息,从而确定出最佳出边
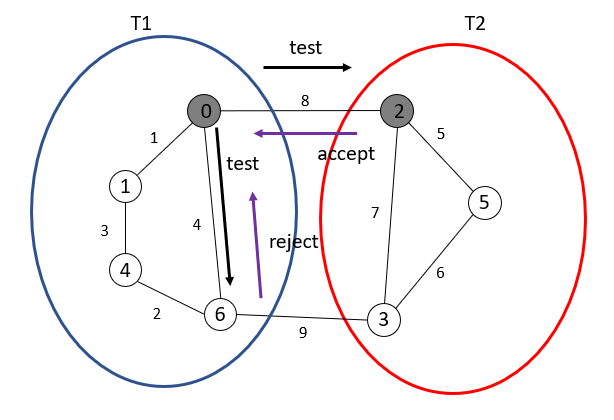
节点 i 向节点 j 发送test消息
- 如果name(i) = name(j),发送reject(意味着同片段)
- 如果name(i) ≠ name(j)
- level(i)≤level(j),节点 j 发送accept
- level(i)>level(j),节点开始等待直至level(i)=level(j),然后发送accept或者reject消息(具体见下Test后置)
联合过程
- 每一个片段都有等级(level),片段初始化等级为0
- 合并:两个同为L等级的片段合并形成一个L+1等级的片段
- 吸收:L 等级的片段被 L‘ 等级的片段吸收,新片段等级为 L’(L<L’)
由上述可知,片段的level只能单向增加并且每一个 L 等级的片段有至少 2 L 2^L 2L 个点
合并(Merge)
联合(join)消息被交换之后,改变点状态为Branch,然后新的根节点广播 ( i n i t i a t e , L + 1 , n a m e ) (initiate,L+1,name) (initiate,L+1,name) 信息来同步片段内所有节点
吸收(Absorb)
T发送一个联合(join)信息给T’(L<L’),收到初始化消息完成吸收过程。结合上述片段内部处理过程,我们不难发现其低片段节点会优先完成聚合决策,也就是说片段只会接收到来自同级或者低级发送的Connect消息。
具体案例分析
抽象描述
例一
本部分从最简单的图开始,逐步增加复杂度来深入理解算法流程
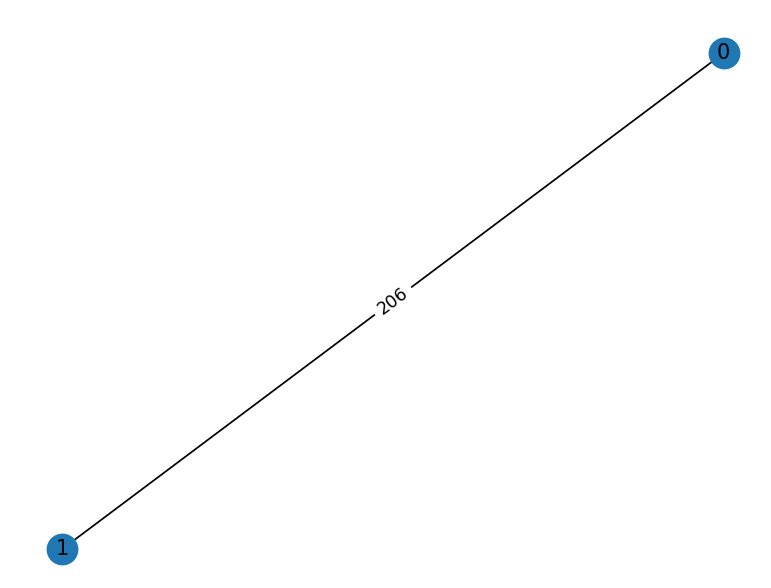
2
100000 206
206 100000
[0.000000] 1(name=0, level=0) initalization
[0.000000] 0(name=0, level=0) initalization
[0.000031] 0(name=0, level=0) sending connect to 1 with level=0
[0.000152] 1(name=0, level=0) sending connect to 0 with level=0
[0.000240] 1(name=0 level=0) received connect from 0 with level=0
[0.000197] 0(name=0 level=0) received connect from 1 with level=0
[0.000221] 0(name=0 level=0) sending initiate to 1 with level=1, name=206, state=1
[0.000379] 1(name=0 level=0) sending initiate to 0 with level=1, name=206, state=1
[0.000407] 1(name=0 level=0) received initate from 0 with level=1 name=206 state=1
[0.000342] 0(name=0 level=0) received initate from 1 with level=1 name=206 state=1
[0.000363] 0(name=206 level=1) sending report to 1 with bestWt=100000
[0.000472] 1(name=206 level=1) sending report to 0 with bestWt=100000
[0.000494] 1(name=206 level=1) received report from 0 with weight=100000
[0.000428] 0(name=206 level=1) received report from 1 with weight=100000
[0.000465] 0(name=206 level=1) sending terminate to q=1
MST: 0 1 206
[0.000600] 1(name=206 level=1) sending terminate to q=0
0 唤醒,寻找其最小边(此处为1),向其发送连接请求消息,
1 唤醒,寻找其最小边(此处为0),向其发送连接请求消息,
1 接收到 0 的连接消息,回应 0 的连接请求(回复其初始化信息)
0 接收到 1 的连接消息,回应 1 的连接请求(回复其初始化信息)
0 接收到 1的初始化信息完成初始化进入 Test 过程
1 接收到 0 的初始化信息完成初始化进入 Test 过程
0 Test 过程由于没有其他边直接进入Report过程(向 1 发送 report 信息)
1 Test 过程由于没有其他边直接进入Report过程(向 0 发送 report 信息)
完成之后两点终止,算法结束
例二
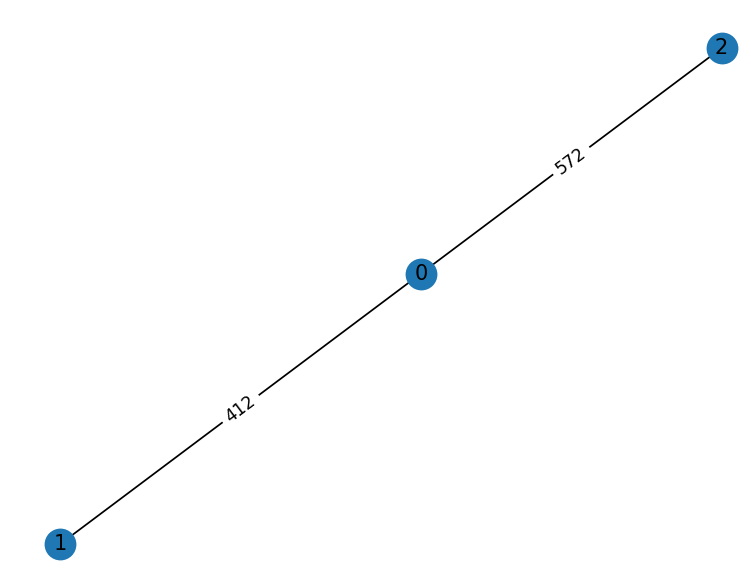
3
100000 412 572
412 100000 100000
572 100000 100000
0 唤醒,寻找其最小边(此处为1),向其发送连接请求消息
1 唤醒,寻找其最小边(此处为0),向其发送连接请求消息
1 接收到 0 的连接消息,回应 0 的连接请求(回复其初始化信息,level=1, name=412, state=1)
0 接收到 1 的连接消息,回应 1 的连接请求(回复其初始化信息, level=1, name=412, state=1)
0 接收到 1 的初始化信息,完成初始化,进入 Test 过程( 向 2 发送Test信息 )
1 接收到 0 的初始化信息,完成初始化,进入 Test 过程,由于没有其他边直接进入Report过程(向 0 发送 report 信息)
0 等待 2 的 report
2 初始化, 寻找其最小边(此处为0),向其发送连接请求消息
0 接收到 2 的连接消息,回应 2 的连接请求(回复其初始化信息, level=1, name=412, state=1)
2 接收到 1 的 test 消息,等待测试
2 接收到 0 的初始化信息,完成初始化
2 向 0 发送 reject 消息(此时0与2已经是一个片段了因此是reject)
0 向 1 发送 report ,结束算法过程
例三
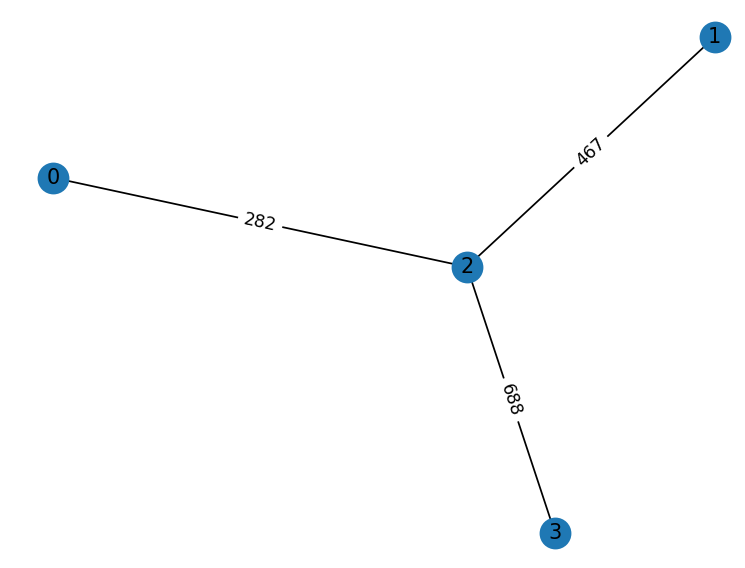
4
100000 100000 282 100000
100000 100000 467 100000
282 467 100000 688
100000 100000 688 100000
开启 0 1 2 3 点进程
0 唤醒,寻找其最小边(此处为2),向其发送连接请求消息
1 唤醒,寻找其最小边(此处为2),向其发送连接请求消息,
2 唤醒,寻找其最小边(此处为0),向其发送连接请求消息,
3 唤醒,寻找其最小边(此处为2),向其发送连接请求消息,
0 接收到 2 的连接消息(回应 2 的连接请求,回复其初始化信息 level=1, name=282, state=1)
2 接收到 0 的连接消息(回应 0 的连接请求,回复其初始化信息 level=1, name=282, state=1)
0 接收到 2 的初始化信息,进入 Test 过程,没有其他节点直接向 2 进行 report
2 接收到 1 的连接消息,进入连接等待状态
2 接收到 3 的连接消息,仍然处于连接等待状态
2 接收到 0 的初始化信息,进入Test 过程(向 1 发送 Test 消息)并继续等待与连接
1 接收到 2 的 Test 消息,并进入 Test 等待(该消息后置)
2 回复 3 初始化信息 level=1, name=282, state=1
2 接收到 0 的 report 信息
3 接收到 2 的初始化消息,没有其他节点直接向 2 进行 report
2 回复 1 初始化信息 level=1, name=282, state=1,并等待 report
2 接收到 3 的 report 信息
1 接收到 2 的初始化消息,没有其他节点直接向 2 进行 report
1 向 2 发送 reject 消息(此时1与2为同片段)
2 向 0 发送 report消息,算法结束
问题
如何理解其中的几个后置消息?
结合源论文中的算法我们可以发现其中有三处出现了"place received message on end of queue"
- 连接后置:结合下述伪代码,如果L=LN(即发送连接消息的片段等级等于接收连接消息的片段等级)且边状态是Basic,则后置连接消息。我们结果例三具体说明。从 2 的视角来看,其最小边为 2-0 因此在初始化阶段将其赋值为 1,而当1,3发送连接消息时,由于此时2还没有完成与0的连接,其片段等级仍然为 0 与1,3相同并且其 2-1 与 2-3 边状态均为 0,所以1与3的连接消息进入后置状态。当 2 接收到 0 的初始化消息之后,其 L>LN 因此进入连接过程(注意其中将此边的状态进行了修改,这也意味着连接后置的终止)
- Test后置:结合下述伪代码可知,当 L>LN 时(即发送Test的片段等级高于接收到Test消息的片段),Test将被消息后置。我们以例三进行说明,一开始在 2 向 1 发送Test消息后,由于0与2组成的片段等级高,Test消息后置。后来,2 向 1 发送初始化信息导致 1 片段等级提升,后置过程终止(其进入accept与reject的判断过程)
- report后置:结合下述伪代码可知,如果接收到report消息的边是in-branch边并且点状态为Find,则后置此消息。具体结合report过程可知,当其所有节点都report完之后会改变状态为Found,此时report后置就会终止,并进入下一阶段处理过程。以例三说明,当2节点接收到1与3的report之后就会终止report后置过程
综上,我们不难发现该算法的核心就在于以上的三个精妙的消息后置,正是这几个组成部分实现了分布式MST。
如何理解Test与report过程?
当完成初始化过程之后节点进入Test过程,首先寻找周围处于Basic状态的节点,然后将最小权重的边作为测试边并向该边发送测试请求,如果没有符合条件的测试边则直接进入report过程
接收到test消息的节点,判断 L 与 LN 的大小,当L>LN 时(即发送Test的片段等级高于接收到Test消息的片段)进入Test后置,如果不是则进入具体判断环节根据具体算法回复 accept 或 reject 以及 一些相应的消息,注意如果接收到Test消息的点A与发送Test的点B属于同一片段,并且A的test边就是这条消息转递边,那么A点继续执行test过程。
report 过程在节点没有要测试的节点或者节点接收到accept响应之后执行,判断其find-count是否为 0 ,以及 test 边是否为空,如果符合条件就改变节点状态并向in-branch边汇报report
接收到 report 消息的节点,先判断该边是否是自己的in-branch边不是的话就可以find-count-1并更新当前的片段的最值情况。在某些具体情况下会进入report后置直至所有的节点完成report
如何理解算法的片段处理逻辑?
我们从整体来看整个算法,实际上就是以片段为核心,一个片段对其边缘的连接边进行 Test 测试,然后使用 report 聚合信息,从而寻找到片段下一步的延伸方向,当然这中间还存在有很多具体的算法细节。
如何理解分布式算法与常见MST算法的优势?
缺点:通讯成本高,复杂度高
优点:可用性高,可解决大规模图计算问题,而单机算法存在性能瓶颈
代码仓库
- Python实现:https://github.com/arjun-menon/Distributed-Graph-Algorithms/tree/master/Minimum-Spanning-Tree
- 使用 OpenMPI 的C++实现(推荐):https://github.com/tejas-1111/GHS-algorithm
参考
https://www.slidestalk.com/u181/distributed_systems_and_algorithms08?embed
https://blog.csdn.net/giskun/article/details/40785381
https://en.wikipedia.org/wiki/Distributed_minimum_spanning_tree
http://www.wiki.yelbee.top/2020/04/30/Computation/%E5%88%86%E5%B8%83%E5%BC%8F%E6%9C%80%E5%B0%8F%E7%94%9F%E6%88%90%E6%A0%91/
https://zhuanlan.zhihu.com/p/497801451


















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









