









基本信息
- 实验名称:网络优化实验
- 姓名:
- 学号:
- 日期:2022/11/14
文章目录
一、在多分类任务中分别手动实现和用torch.nn实现dropout
1.1 任务内容
- 任务具体要求
在多分类任务实验中分别手动和利用torch.nn实现dropout
探究不同丢弃率对实验结果的影响(可用loss曲线进行展示) - 任务目的
探究不同丢弃率对实验结果的影响 - 任务算法或原理介绍
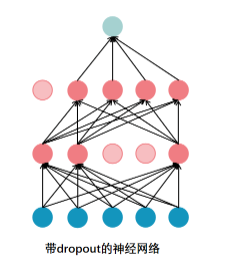
Dropout 原理
- 任务所用数据集
Fashion-MNIST数据集:- 该数据集包含60,000个用于训练的图像样本和10,000个用于测试的图像样本。
- 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784
1.2 任务思路及代码
- 构建数据集
- 构建前馈神经网络,损失函数,优化函数
- 手动实现dropout
- 进行反向传播,和梯度更新
- 使用网络预测结果,得到损失值
- 对loss、acc等指标进行分析,探究不同丢弃率对实验结果的影响
1.2.0数据集定义
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torch.nn.functional import cross_entropy, binary_cross_entropy
from torch.nn import CrossEntropyLoss
from torchvision import transforms
from sklearn import metrics
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果有gpu则在gpu上计算 加快计算速度
print(f'当前使用的device为{device}')
# 数据集定义
# 定义多分类数据集 - train_dataloader - test_dataloader
batch_size = 128
# Build the training and testing dataset
traindataset = torchvision.datasets.FashionMNIST(root='E:\\DataSet\\FashionMNIST\\Train',
train=True,
download=True,
transform=transforms.ToTensor())
testdataset = torchvision.datasets.FashionMNIST(root='E:\\DataSet\\FashionMNIST\\Test',
train=False,
download=True,
transform=transforms.ToTensor())
traindataloader = torch.utils.data.DataLoader(traindataset, batch_size=batch_size, shuffle=True)
testdataloader = torch.utils.data.DataLoader(testdataset, batch_size=batch_size, shuffle=False)
# 绘制图像的代码
def picture(name, trainl, testl,xlabel='Epoch',ylabel='Loss'):
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
plt.figure(figsize=(8, 3))
plt.title(name[-1]) # 命名
color = ['g','r','b','c']
if trainl is not None:
plt.subplot(121)
for i in range(len(name)-1):
plt.plot(trainl[i], c=color[i],label=name[i])
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend()
if testl is not None:
plt.subplot(122)
for i in range(len(name)-1):
plt.plot(testl[i], c=color[i], label=name[i])
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend()
print(f'多分类数据集 样本总数量{len(traindataset) + len(testdataset)},训练样本数量{len(traindataset)},测试样本数量{len(testdataset)}')
当前使用的device为cuda
多分类数据集 样本总数量70000,训练样本数量60000,测试样本数量10000
1.手动实现前馈神经网络代码
- 代码中
MyNet为手动实现的前馈神经网络模型,包含一个参数 dropout 表示丢失率用作实验一中设置不同的丢失率 - 代码设置函数
train_and_test可供之后需要手动实现多分类的实验调用,默认的损失函数为CrossEntropyLoss(),优化函数为自己定义的随机梯度下降函数mySGD(),其余参数设置如下:epochs=30表示需要训练的总epoch数 默认为 30lr=0.01表示设置的学习率, 默认值为 0.01L2=False表示是否需要加入L2惩罚范数,默认值为Falselambd=0如果需要加入L2惩罚范数,则lambd有用,该值为惩罚权重,默认值为0
# 定义自己的前馈神经网络
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
# dropout = 0.2
class MyNet():
def __init__(self,dropout=0.0):
# 设置隐藏层和输出层的节点数
# global dropout
self.dropout = dropout
print('dropout: ',self.dropout)
self.is_train = None
num_inputs, num_hiddens, num_outputs = 28 * 28, 256, 10 # 十分类问题
w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,
requires_grad=True)
b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)
w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,
requires_grad=True)
b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)
self.params = [w_1, b_1, w_2, b_2]
self.w = [w_1,w_2]
# 定义模型结构
self.input_layer = lambda x: x.view(x.shape[0], -1)
self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, w_1.t()) + b_1)
self.output_layer = lambda x: torch.matmul(x, w_2.t()) + b_2
def my_relu(self, x):
return torch.max(input=x, other=torch.tensor(0.0))
# 以下两个函数分别在训练和测试前调用,选择是否需要dropout
def train(self):
self.is_train = True
def test(self):
self.is_train = False
"""
定义dropout层
x: 输入数据
dropout: 随机丢弃的概率
"""
def dropout_layer(self, x):
dropout =self.dropout
assert 0 <= dropout <= 1 #dropout值必须在0-1之间
# dropout==1,所有元素都被丢弃。
if dropout == 1:
return torch.zeros_like(x)
# 在本情况中,所有元素都被保留。
if dropout == 0:
return x
mask = (torch.rand(x.shape) < 1.0 - dropout).float() #rand()返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数
return mask * x / (1.0 - dropout)
# 定义前向传播
def forward(self, x):
x = self.input_layer(x)
if self.is_train: # 如果是训练过程,则需要开启dropout 否则 需要关闭 dropout
x = dropout_layer(x,dropout=self.dropout)
x = self.my_relu(self.hidden_layer(x))
if self.is_train:
x = dropout_layer(x,dropout=self.dropout)
x = self.output_layer(x)
return x
# 默认的优化函数为手写的mySGD
def mySGD(params, lr, batchsize):
for param in params:
param.data -= lr * param.grad
# 定义L2范数惩罚项 参数 w 为模型的 w 在本次实验中为[w_1, w_2] batch_size=128
def l2_penalty(w):
cost = 0
for i in range(len(w)):
cost += (w[i]**2).sum()
return cost / batch_size / 2
"""
定义训练函数
model:定义的模型 默认为MyNet(0) 即无dropout的初始网络
epochs:训练总轮数 默认为30
criterion:定义的损失函数,默认为cross_entropy
lr :学习率 默认为0.1
optimizer:定义的优化函数,默认为自己定义的mySGD函数
"""
def train_and_test(model=MyNet(),init_states=None,optimizer=mySGD,epochs=20,lr=0.01,L2=False,lambd=0):
train_all_loss = [] # 记录训练集上得loss变化
test_all_loss = [] # 记录测试集上的loss变化
train_ACC, test_ACC = [], [] # 记录正确的个数
begintime = time.time()
# 激活函数为自己定义的mySGD函数
# criterion = cross_entropy # 损失函数为交叉熵函数
criterion = CrossEntropyLoss() # 损失函数
model.train() #表明当前处于训练状态,允许使用dropout
for epoch in range(epochs):
train_l,train_acc_num = 0, 0
for data, labels in traindataloader:
pred = model.forward(data)
train_each_loss = criterion(pred, labels) # 计算每次的损失值
# 若L2为True则表示需要添加L2范数惩罚项
if L2 == True:
train_each_loss += lambd * l2_penalty(model.w)
train_l += train_each_loss.item()
train_each_loss.backward() # 反向传播
# 若当前states为 None表示 使用的是 默认的优化函数mySGD
if init_states == None:
optimizer(model.params, lr, 128) # 使用小批量随机梯度下降迭代模型参数
# 否则的话使用的是自己定义的优化器,通过传入的参数,来实现优化效果
else:
states = init_states(model.params)
optimizer(model.params,states,lr=lr)
# 梯度清零
train_acc_num += (pred.argmax(dim=1)==labels).sum().item()
for param in model.params:
param.grad.data.zero_()
# print(train_each_loss)
train_all_loss.append(train_l) # 添加损失值到列表中
train_ACC.append(train_acc_num / len(traindataset)) # 添加准确率到列表中
model.test() # 表明当前处于测试状态,无需使用dropout
with torch.no_grad():
is_train = False # 表明当前为测试阶段,不需要dropout参与
test_l, test_acc_num = 0, 0
for data, labels in testdataloader:
pred = model.forward(data)
test_each_loss = criterion(pred, labels)
test_l += test_each_loss.item()
test_acc_num += (pred.argmax(dim=1)==labels).sum().item()
test_all_loss.append(test_l)
test_ACC.append(test_acc_num / len(testdataset)) # # 添加准确率到列表中
if epoch == 0 or (epoch + 1) % 2 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc: %.2f | test acc: %.2f'
% (epoch + 1, train_l, test_l, train_ACC[-1],test_ACC[-1]))
endtime = time.time()
print("手动实现dropout = %d, %d轮 总用时: %.3f" % (model.dropout, epochs, endtime - begintime))
return train_all_loss,test_all_loss,train_ACC,test_ACC
dropout: 0.0
1.2.1 手动实现-设置dropout = 0
# 设置dropout = 0 dropout = 0 epoch = 30 lr = 0.01 optimizer = mySGD
model_11 = MyNet(dropout = 0.0)
train_all_loss11,test_all_loss11,\
train_ACC11,test_ACC11 \
= train_and_test(model=model_11,epochs=20,lr=0.01)
dropout: 0.0
epoch: 1 | train loss:872.64942 | test loss:101.62506 | train acc: 0.49 | test acc: 0.62
epoch: 2 | train loss:484.90760 | test loss:70.47120 | train acc: 0.65 | test acc: 0.66
epoch: 4 | train loss:337.69529 | test loss:55.50412 | train acc: 0.74 | test acc: 0.75
epoch: 6 | train loss:288.98904 | test loss:48.69153 | train acc: 0.79 | test acc: 0.78
epoch: 8 | train loss:261.24783 | test loss:44.77175 | train acc: 0.81 | test acc: 0.80
epoch: 10 | train loss:244.54166 | test loss:42.56631 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:233.17713 | test loss:40.83642 | train acc: 0.83 | test acc: 0.82
epoch: 14 | train loss:225.23643 | test loss:39.74532 | train acc: 0.83 | test acc: 0.82
epoch: 16 | train loss:219.29802 | test loss:38.82166 | train acc: 0.84 | test acc: 0.83
epoch: 18 | train loss:214.22844 | test loss:38.12609 | train acc: 0.84 | test acc: 0.83
epoch: 20 | train loss:210.15229 | test loss:37.73654 | train acc: 0.84 | test acc: 0.83
手动实现dropout = 0, 20轮 总用时: 203.126
1.2.2 手动实现-设置dropout = 0.3
# 设置dropout = 0.3 epoch = 30 lr = 0.01 optimizer = mySGD
dropout=0.3
model_12 = MyNet()
train_all_loss12,test_all_loss12,\
train_ACC12,test_ACC12 \
= train_and_test(model=model_12,epochs=20,lr=0.01)
dropout: 0.3
epoch: 1 | train loss:879.17995 | test loss:102.15184 | train acc: 0.41 | test acc: 0.62
epoch: 2 | train loss:487.08636 | test loss:70.85480 | train acc: 0.65 | test acc: 0.67
epoch: 4 | train loss:339.05907 | test loss:55.81440 | train acc: 0.74 | test acc: 0.75
epoch: 6 | train loss:290.52114 | test loss:48.84491 | train acc: 0.79 | test acc: 0.78
epoch: 8 | train loss:262.59252 | test loss:45.04938 | train acc: 0.81 | test acc: 0.80
epoch: 10 | train loss:245.22824 | test loss:42.48761 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:233.72414 | test loss:40.87166 | train acc: 0.83 | test acc: 0.82
epoch: 14 | train loss:225.33460 | test loss:39.64226 | train acc: 0.84 | test acc: 0.82
epoch: 16 | train loss:218.90282 | test loss:38.89728 | train acc: 0.84 | test acc: 0.83
epoch: 18 | train loss:213.85560 | test loss:38.04384 | train acc: 0.84 | test acc: 0.83
epoch: 20 | train loss:209.63276 | test loss:37.77163 | train acc: 0.85 | test acc: 0.83
手动实现dropout = 0, 20轮 总用时: 200.632
1.2.3 手动实现-设置dropout = 0.6
# 设置dropout = 0.6 dropout = 0.6 epoch = 30 lr = 0.01 optimizer = mySGD
model_13 = MyNet(dropout=0.6)
train_all_loss13,test_all_loss13,\
train_ACC13,test_ACC13 \
= train_and_test(model=model_13,epochs=20,lr=0.01)
dropout: 0.6
epoch: 1 | train loss:909.44703 | test loss:107.27103 | train acc: 0.35 | test acc: 0.59
epoch: 2 | train loss:504.39541 | test loss:72.46001 | train acc: 0.64 | test acc: 0.66
epoch: 4 | train loss:341.84676 | test loss:56.07868 | train acc: 0.74 | test acc: 0.74
epoch: 6 | train loss:291.11752 | test loss:48.94307 | train acc: 0.79 | test acc: 0.78
epoch: 8 | train loss:262.59137 | test loss:45.16227 | train acc: 0.81 | test acc: 0.80
epoch: 10 | train loss:245.31536 | test loss:42.67761 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:233.70658 | test loss:40.84980 | train acc: 0.83 | test acc: 0.82
epoch: 14 | train loss:225.42686 | test loss:39.89094 | train acc: 0.84 | test acc: 0.82
epoch: 16 | train loss:219.13081 | test loss:39.07038 | train acc: 0.84 | test acc: 0.83
epoch: 18 | train loss:214.17095 | test loss:38.72034 | train acc: 0.84 | test acc: 0.82
epoch: 20 | train loss:209.99137 | test loss:37.43517 | train acc: 0.85 | test acc: 0.83
手动实现dropout = 0, 20轮 总用时: 234.203
1.2.4 手动实现-设置dropout = 0.9
# 设置dropout = 0.9 dropout = 0.9 epoch = 20 lr = 0.01 optimizer = mySGD
model_14 = MyNet(dropout=0.9)
train_all_loss14,test_all_loss14,\
train_ACC14,test_ACC14 \
= train_and_test(model=model_14,epochs=20,lr=0.01)
dropout: 0.9
epoch: 1 | train loss:998.39192 | test loss:131.15014 | train acc: 0.20 | test acc: 0.53
epoch: 2 | train loss:569.14506 | test loss:76.94013 | train acc: 0.61 | test acc: 0.65
epoch: 4 | train loss:351.53705 | test loss:57.61345 | train acc: 0.73 | test acc: 0.74
epoch: 6 | train loss:297.49190 | test loss:49.77498 | train acc: 0.78 | test acc: 0.78
epoch: 8 | train loss:266.77583 | test loss:45.55881 | train acc: 0.81 | test acc: 0.80
epoch: 10 | train loss:248.14114 | test loss:43.03852 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:235.84031 | test loss:41.16744 | train acc: 0.83 | test acc: 0.82
epoch: 14 | train loss:227.23696 | test loss:40.22656 | train acc: 0.83 | test acc: 0.82
epoch: 16 | train loss:220.65873 | test loss:39.36629 | train acc: 0.84 | test acc: 0.82
epoch: 18 | train loss:215.42647 | test loss:38.41269 | train acc: 0.84 | test acc: 0.83
epoch: 20 | train loss:211.04093 | test loss:37.67217 | train acc: 0.84 | test acc: 0.83
手动实现dropout = 0, 20轮 总用时: 188.600
2.利用torch.nn实现前馈神经网络代码
# 利用torch.nn实现前馈神经网络-多分类任务
from collections import OrderedDict
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
# 定义自己的前馈神经网络
class MyNet_NN(nn.Module):
def __init__(self,dropout=0.0):
super(MyNet_NN, self).__init__()
# 设置隐藏层和输出层的节点数
self.num_inputs, self.num_hiddens, self.num_outputs = 28 * 28, 256, 10 # 十分类问题
# 定义模型结构
self.input_layer = nn.Flatten()
self.hidden_layer = nn.Linear(28*28,256)
# 根据设置的dropout设置丢失率
self.drop = nn.Dropout(dropout)
self.output_layer = nn.Linear(256,10)
# 使用relu激活函数
self.relu = nn.ReLU()
# 定义前向传播
def forward(self, x):
x = self.drop(self.input_layer(x))
x = self.drop(self.hidden_layer(x))
x = self.relu(x)
x = self.output_layer(x)
return x
# 训练
# 使用默认的参数即: num_inputs=28*28,num_hiddens=256,num_outs=10,act='relu'
model = MyNet_NN()
model = model.to(device)
# 将训练过程定义为一个函数,方便调用
def train_and_test_NN(model=model,epochs=30,lr=0.01,weight_decay=0.0,optimizer=None):
MyModel = model
print(MyModel)
# 优化函数, 默认情况下weight_decay为0 通过更改weight_decay的值可以实现L2正则化。
# 默认的优化函数为SGD 可以根据参数来修改优化函数
if optimizer == None:
optimizer = SGD(MyModel.parameters(), lr=lr,weight_decay=weight_decay)
criterion = CrossEntropyLoss() # 损失函数
criterion = criterion.to(device)
train_all_loss = [] # 记录训练集上得loss变化
test_all_loss = [] # 记录测试集上的loss变化
train_ACC, test_ACC = [], []
begintime = time.time()
for epoch in range(epochs):
train_l, train_epoch_count, test_epoch_count = 0, 0, 0
for data, labels in traindataloader:
data, labels = data.to(device), labels.to(device)
pred = MyModel(data)
train_each_loss = criterion(pred, labels.view(-1)) # 计算每次的损失值
optimizer.zero_grad() # 梯度清零
train_each_loss.backward() # 反向传播
optimizer.step() # 梯度更新
train_l += train_each_loss.item()
train_epoch_count += (pred.argmax(dim=1)==labels).sum()
train_ACC.append(train_epoch_count/len(traindataset))
train_all_loss.append(train_l) # 添加损失值到列表中
with torch.no_grad():
test_loss, test_epoch_count= 0, 0
for data, labels in testdataloader:
data, labels = data.to(device), labels.to(device)
pred = MyModel(data)
test_each_loss = criterion(pred,labels)
test_loss += test_each_loss.item()
test_epoch_count += (pred.argmax(dim=1)==labels).sum()
test_all_loss.append(test_loss)
test_ACC.append(test_epoch_count.cpu()/len(testdataset))
if epoch == 0 or (epoch + 1) % 2 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc:%5f test acc:%.5f:' % (epoch + 1, train_all_loss[-1], test_all_loss[-1],
train_ACC[-1],test_ACC[-1]))
endtime = time.time()
print("torch.nn实现前馈网络-多分类任务 %d轮 总用时: %.3fs" % (epochs, endtime - begintime))
# 返回训练集和测试集上的 损失值 与 准确率
return train_all_loss,test_all_loss,train_ACC,test_ACC
1.2.5 torch.nn实现-设置dropout = 0
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD
model_15 = MyNet_NN(dropout=0)
model_15 = model_15.to(device)
train_all_loss15,test_all_loss15,\
train_ACC15,test_ACC15 \
= train_and_test_NN(model=model_15,epochs=20,lr=0.01)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:655.58136 | test loss:74.47299 | train acc:0.622167 test acc:0.67990:
epoch: 2 | train loss:383.53553 | test loss:59.61930 | train acc:0.721167 test acc:0.73540:
epoch: 4 | train loss:293.89208 | test loss:48.96072 | train acc:0.790733 test acc:0.78950:
epoch: 6 | train loss:259.49087 | test loss:44.43671 | train acc:0.815433 test acc:0.80620:
epoch: 8 | train loss:240.91520 | test loss:41.87740 | train acc:0.826550 test acc:0.81700:
epoch: 10 | train loss:229.37972 | test loss:40.24408 | train acc:0.833583 test acc:0.82250:
epoch: 12 | train loss:221.02299 | test loss:39.09193 | train acc:0.838850 test acc:0.82610:
epoch: 14 | train loss:214.61364 | test loss:38.23125 | train acc:0.843517 test acc:0.83120:
epoch: 16 | train loss:209.39514 | test loss:37.83912 | train acc:0.846883 test acc:0.82850:
epoch: 18 | train loss:204.97675 | test loss:36.86500 | train acc:0.849483 test acc:0.83560:
epoch: 20 | train loss:201.09988 | test loss:36.50862 | train acc:0.852667 test acc:0.83650:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 169.970s
1.2.6 torch.nn实现-设置dropout = 0.3
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD
model_16 = MyNet_NN(dropout=0.3)
model_16 = model_16.to(device)
train_all_loss16,test_all_loss16,\
train_ACC16,test_ACC16 \
= train_and_test_NN(model=model_16,epochs=20,lr=0.01)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0.3, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:702.54659 | test loss:80.90724 | train acc:0.542983 test acc:0.64540:
epoch: 2 | train loss:421.96581 | test loss:65.55994 | train acc:0.686283 test acc:0.69950:
epoch: 4 | train loss:332.59721 | test loss:55.84150 | train acc:0.753833 test acc:0.74820:
epoch: 6 | train loss:299.84487 | test loss:51.16118 | train acc:0.778217 test acc:0.77110:
epoch: 8 | train loss:282.70475 | test loss:48.75440 | train acc:0.791150 test acc:0.78030:
epoch: 10 | train loss:271.02193 | test loss:46.89236 | train acc:0.797250 test acc:0.78890:
epoch: 12 | train loss:262.19408 | test loss:45.14446 | train acc:0.806817 test acc:0.79860:
epoch: 14 | train loss:255.17918 | test loss:43.83435 | train acc:0.809567 test acc:0.80310:
epoch: 16 | train loss:248.88366 | test loss:43.53325 | train acc:0.814300 test acc:0.80210:
epoch: 18 | train loss:242.04225 | test loss:42.59759 | train acc:0.817517 test acc:0.80700:
epoch: 20 | train loss:238.39859 | test loss:41.80848 | train acc:0.821833 test acc:0.81500:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 166.926s
1.2.7 torch.nn实现-设置dropout = 0.6
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD
model_17 = MyNet_NN(dropout=0.6)
model_17 = model_17.to(device)
train_all_loss17,test_all_loss17,\
train_ACC17,test_ACC17 \
= train_and_test_NN(model=model_17,epochs=20,lr=0.01)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0.6, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:773.29946 | test loss:94.92489 | train acc:0.444217 test acc:0.58040:
epoch: 2 | train loss:494.37014 | test loss:76.87856 | train acc:0.622967 test acc:0.65040:
epoch: 4 | train loss:400.60366 | test loss:66.31284 | train acc:0.694850 test acc:0.69800:
epoch: 6 | train loss:365.91697 | test loss:62.46187 | train acc:0.723167 test acc:0.71640:
epoch: 8 | train loss:343.86994 | test loss:58.71530 | train acc:0.737933 test acc:0.73280:
epoch: 10 | train loss:330.31647 | test loss:56.35195 | train acc:0.748017 test acc:0.73650:
epoch: 12 | train loss:321.14122 | test loss:54.33575 | train acc:0.754500 test acc:0.75220:
epoch: 14 | train loss:312.09657 | test loss:53.44632 | train acc:0.760450 test acc:0.75670:
epoch: 16 | train loss:306.95581 | test loss:52.45056 | train acc:0.765567 test acc:0.75630:
epoch: 18 | train loss:300.05030 | test loss:51.08243 | train acc:0.768783 test acc:0.77060:
epoch: 20 | train loss:295.16722 | test loss:51.24780 | train acc:0.773500 test acc:0.76530:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 160.365s
1.2.8 torch.nn实现-设置dropout = 0.9
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD
model_18 = MyNet_NN(dropout=0.9)
model_18 = model_18.to(device)
train_all_loss18,test_all_loss18,\
train_ACC18,test_ACC18 \
= train_and_test_NN(model=model_18,epochs=20,lr=0.01)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0.9, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:1031.86029 | test loss:152.73935 | train acc:0.192783 test acc:0.26440:
epoch: 2 | train loss:832.82668 | test loss:132.52133 | train acc:0.317433 test acc:0.34840:
epoch: 4 | train loss:701.72601 | test loss:115.61146 | train acc:0.413683 test acc:0.42660:
epoch: 6 | train loss:652.82964 | test loss:109.09122 | train acc:0.453233 test acc:0.46170:
epoch: 8 | train loss:618.55567 | test loss:104.19970 | train acc:0.485717 test acc:0.48220:
epoch: 10 | train loss:596.50939 | test loss:100.95779 | train acc:0.505933 test acc:0.50250:
epoch: 12 | train loss:580.25755 | test loss:98.08979 | train acc:0.518717 test acc:0.51810:
epoch: 14 | train loss:562.10516 | test loss:96.48224 | train acc:0.530767 test acc:0.52650:
epoch: 16 | train loss:550.00569 | test loss:91.92824 | train acc:0.544350 test acc:0.54050:
epoch: 18 | train loss:545.92920 | test loss:92.90535 | train acc:0.545083 test acc:0.54730:
epoch: 20 | train loss:536.47559 | test loss:89.90178 | train acc:0.554950 test acc:0.55680:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 155.538s
1.3 实验结果分析
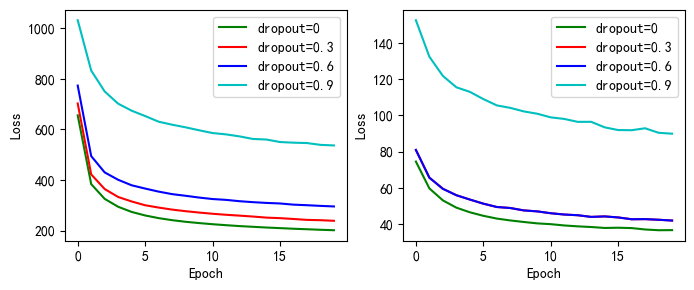
手动实现的dropout-Loss打印
#完成loss的显示
drop_name_1 = ['dropout=0','dropout=0.3','dropout=0.6','dropout=0.9','手动实现不同的dropout-Loss变化']
drop_train_1 = [train_all_loss11,train_all_loss12,train_all_loss13,train_all_loss14]
drop_test_1 = [test_all_loss11,test_all_loss12,test_all_loss13,test_all_loss14]
picture(drop_name_2, drop_train_2,drop_test_2)
torch.nn实现的dropout-Loss打印
#完成loss的显示
drop_name_2 = ['dropout=0','dropout=0.3','dropout=0.6','dropout=0.9','手动实现不同的dropout-Loss变化']
drop_train_2 = [train_all_loss15,train_all_loss16,train_all_loss17,train_all_loss18]
drop_test_2 = [test_all_loss15,test_all_loss16,test_all_loss16,test_all_loss18]
picture(drop_name_2, drop_train_2, drop_test_2)
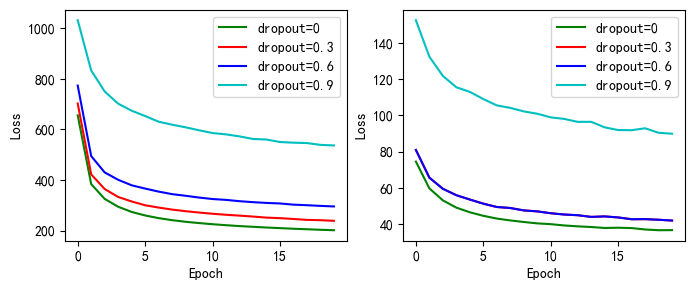
上图为手动实现和torch.nn实现的dropout实验的损失值的变化,左边的为训练集上得,右边的为测试集合上的。
由上两图dropout的设置值越大,初始的损失值越大,随后随着训练次数的增加,损失值不断降低。dropout的值越大,模型过拟合的概率越小。
dropout的作用:
Dropout使得在每个训练批次中,通过忽略一半数量的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用。
二、在多分类任务中分别手动实现和用torch.nn实现 L 2 L_2 L2 正则化
2.1 任务内容
- 任务具体要求
在多分类任务中分别手动实现和用torch.nn实现 L 2 L_2 L2正则化 - 任务目的
探究惩罚项的权重对实验结果的影响(可用loss曲线进行展示) - 任务算法或原理介绍
L 2 L_2 L2 原理
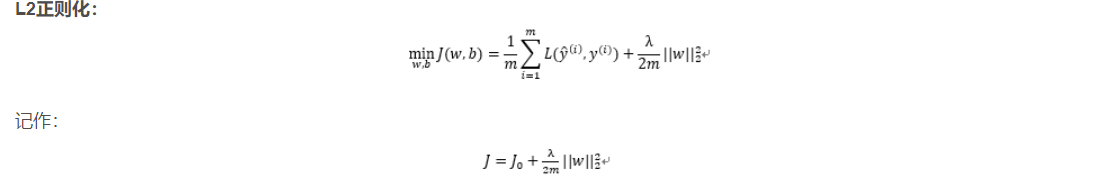
- 任务所用数据集
Fashion-MNIST数据集:- 该数据集包含60,000个用于训练的图像样本和10,000个用于测试的图像样本。
- 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784
2.2 任务思路及代码
- 构建数据集
- 构建前馈神经网络,损失函数,优化函数
- 构建L2范数惩罚项
- 进行反向传播,和梯度更新
- 使用网络预测结果,得到损失值
- 探究惩罚项的权重对实验结果的影响
2.2.1 手动实现-设置惩罚权重lambd= 0(即无惩罚权重)
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD L2=True lambd=0
model_21 = MyNet(dropout=0)
train_all_loss21,test_all_loss21,\
train_ACC21,test_ACC21\
= train_and_test(model=model_21,epochs=20,lr=0.01,L2=True,lambd=0)
dropout: 0
epoch: 1 | train loss:866.45301 | test loss:101.49811 | train acc: 0.45 | test acc: 0.60
epoch: 2 | train loss:486.26606 | test loss:70.56476 | train acc: 0.65 | test acc: 0.67
epoch: 4 | train loss:336.08916 | test loss:55.07089 | train acc: 0.75 | test acc: 0.75
epoch: 6 | train loss:286.81197 | test loss:48.24101 | train acc: 0.79 | test acc: 0.78
epoch: 8 | train loss:259.50061 | test loss:44.47255 | train acc: 0.81 | test acc: 0.80
epoch: 10 | train loss:243.31417 | test loss:42.31028 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:232.23276 | test loss:41.08155 | train acc: 0.83 | test acc: 0.82
epoch: 14 | train loss:224.23518 | test loss:39.63520 | train acc: 0.84 | test acc: 0.82
epoch: 16 | train loss:218.08964 | test loss:38.81029 | train acc: 0.84 | test acc: 0.83
epoch: 18 | train loss:213.08018 | test loss:38.25762 | train acc: 0.84 | test acc: 0.83
epoch: 20 | train loss:208.77749 | test loss:37.60064 | train acc: 0.85 | test acc: 0.83
手动实现dropout = 0, 20轮 总用时: 206.190
2.2.2 手动实现-设置惩罚权重lambd= 2
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD L2=True lambd=1
model_22 = MyNet(dropout=0)
train_all_loss22,test_all_loss22,\
train_ACC22,test_ACC22\
= train_and_test(model=model_22,epochs=20,lr=0.01,L2=True,lambd=1)
dropout: 0
epoch: 1 | train loss:905.61759 | test loss:102.07449 | train acc: 0.46 | test acc: 0.60
epoch: 2 | train loss:539.61660 | test loss:71.66011 | train acc: 0.65 | test acc: 0.67
epoch: 4 | train loss:407.31129 | test loss:57.25353 | train acc: 0.74 | test acc: 0.74
epoch: 6 | train loss:365.83306 | test loss:51.18184 | train acc: 0.78 | test acc: 0.78
epoch: 8 | train loss:342.00613 | test loss:47.03204 | train acc: 0.80 | test acc: 0.80
epoch: 10 | train loss:327.25394 | test loss:44.71919 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:317.70518 | test loss:43.34584 | train acc: 0.82 | test acc: 0.81
epoch: 14 | train loss:310.83809 | test loss:42.27092 | train acc: 0.83 | test acc: 0.82
epoch: 16 | train loss:305.72729 | test loss:41.80292 | train acc: 0.83 | test acc: 0.81
epoch: 18 | train loss:301.85856 | test loss:40.95933 | train acc: 0.83 | test acc: 0.82
epoch: 20 | train loss:298.56079 | test loss:40.83248 | train acc: 0.84 | test acc: 0.82
手动实现dropout = 0, 20轮 总用时: 204.461
2.2.3 利用torch.nn实现-设置惩罚权重weight_decay=0.0(即无惩罚权重)
# 设置dropout = 0 dropout = 0 epoch = 30 lr = 0.01 optimizer = SGD weight_decay=0.0
model_24 = MyNet_NN(dropout=0)
model_24 = model_24.to(device)
train_all_loss24,test_all_loss24,\
train_ACC24,test_ACC24 \
= train_and_test_NN(model=model_24,epochs=20,lr=0.01,weight_decay=0.0)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:659.27534 | test loss:74.52569 | train acc:0.616133 test acc:0.67780:
epoch: 2 | train loss:382.77867 | test loss:59.38335 | train acc:0.722317 test acc:0.74080:
epoch: 4 | train loss:292.84218 | test loss:48.83517 | train acc:0.791800 test acc:0.78720:
epoch: 6 | train loss:258.79662 | test loss:44.28819 | train acc:0.815900 test acc:0.80610:
epoch: 8 | train loss:240.63736 | test loss:41.84953 | train acc:0.827000 test acc:0.81660:
epoch: 10 | train loss:229.37524 | test loss:40.13170 | train acc:0.833183 test acc:0.82340:
epoch: 12 | train loss:221.23428 | test loss:39.13591 | train acc:0.838783 test acc:0.82780:
epoch: 14 | train loss:215.19242 | test loss:38.60563 | train acc:0.842200 test acc:0.83020:
epoch: 16 | train loss:210.06449 | test loss:37.52553 | train acc:0.846350 test acc:0.83320:
epoch: 18 | train loss:206.02604 | test loss:36.85281 | train acc:0.849067 test acc:0.83510:
epoch: 20 | train loss:202.39181 | test loss:36.56123 | train acc:0.852200 test acc:0.83890:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 136.719s
2.2.4 利用torch.nn实现-设置惩罚权重weight_decay = 1e-2
# 设置dropout = 0 dropout = 0 epoch = 20 lr = 0.01 optimizer = SGD weight_decay=1e-3
model_26 = MyNet_NN(dropout=0)
model_26 = model_26.to(device)
train_all_loss26,test_all_loss26,\
train_ACC26,test_ACC26 \
= train_and_test_NN(model=model_26,epochs=20,lr=0.01,weight_decay=1e-3)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:680.87843 | test loss:76.15495 | train acc:0.605317 test acc:0.67710:
epoch: 2 | train loss:389.25886 | test loss:60.02418 | train acc:0.719550 test acc:0.73310:
epoch: 4 | train loss:296.29670 | test loss:49.37372 | train acc:0.788817 test acc:0.78670:
epoch: 6 | train loss:261.61639 | test loss:44.95376 | train acc:0.813367 test acc:0.80070:
epoch: 8 | train loss:243.03708 | test loss:42.29602 | train acc:0.825467 test acc:0.81430:
epoch: 10 | train loss:231.52064 | test loss:40.79951 | train acc:0.833133 test acc:0.81730:
epoch: 12 | train loss:223.04548 | test loss:39.49103 | train acc:0.837983 test acc:0.82460:
epoch: 14 | train loss:216.66145 | test loss:38.59491 | train acc:0.841867 test acc:0.82670:
epoch: 16 | train loss:211.67088 | test loss:37.71256 | train acc:0.845367 test acc:0.83050:
epoch: 18 | train loss:207.27632 | test loss:37.09026 | train acc:0.848200 test acc:0.83260:
epoch: 20 | train loss:203.70357 | test loss:36.68534 | train acc:0.851017 test acc:0.83330:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 153.349s
2.3 实验结果分析
手动实现的惩罚权重lambd得Loss的打印
#完成loss的显示
drop_name_3 = ['lambd= 0','lambd=2','手动实现不同的惩罚权重lambd-Loss变化']
drop_train_3 = [train_all_loss21,train_all_loss22]
drop_test_3= [test_all_loss21,test_all_loss22]
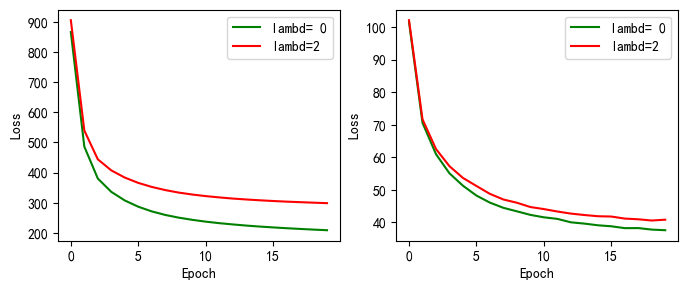
picture(drop_name_3, drop_train_3,drop_test_3)
torch.nn实现-设置惩罚权重weight_decayLoss的打印
#完成loss的显示
drop_name_4= ['weight_decay=0.0','weight_decay = 1e-2','torch.nn实现不同的惩罚权重lambd-Loss变化']
drop_train_4 = [train_all_loss24,train_all_loss26]
drop_test_4= [test_all_loss24,test_all_loss26]
picture(drop_name_4, drop_train_4,drop_test_4)
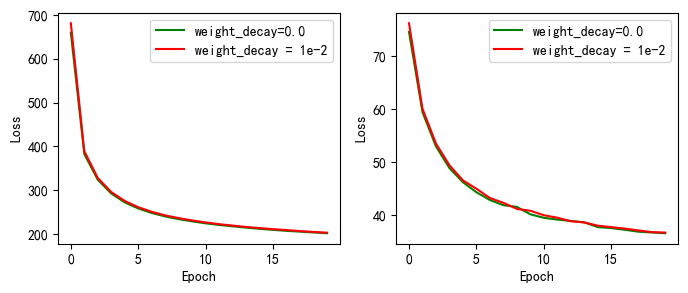
上图为手动实现和torch.nn实现的不同惩罚权重的实验的 损失值的变化,左边的为训练集上得,右边的为测试集合上的。
对比上图我们可以看出,惩罚权重越大,模型的也会随之损失值越大
当未使用权重衰减(lambd=0)时,训练集上的误差远小于测试集,使用权重衰减(lambd=3 or 6)时,训练误差虽然提高,但是测试集上的误差下降,过拟合得到一定程度上缓解
权重衰退通过L2正则项使得模型参数不会过大,也不会过小,从而控制模型的复杂度不会太复杂。
L
2
L_2
L2 正则化的好处:
1)学习理论的角度:
从学习理论的角度来说,L2范数可以防止过拟合,提升模型的泛化能力。越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
2)优化计算的角度:
从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。
三、)在多分类任务实验中实现momentum、rmsprop、adam优化器
3.1 任务内容
- 任务具体要求
- 在手动实现多分类的任务中手动实现三种优化算法,并补全Adam中计算部分的内容
- 在torch.nn实现多分类的任务中使用torch.nn实现各种优化器,并对比其效果
- 任务目的
对比不同优化器的效果 - 任务算法或原理介绍
- 任务所用数据集
Fashion-MNIST数据集:- 该数据集包含60,000个用于训练的图像样本和10,000个用于测试的图像样本。
- 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784


3.2 任务思路及代码
- 构建数据集
- 构建前馈神经网络,损失函数,优化函数
- 手动和torch.nn构建不同的优化器
- 进行反向传播,和梯度更新
- 使用网络预测结果,得到损失值
- 对比不同优化器的效果
3.2.1 手动实现RMSprop算法
# 初始化
def init_rmsprop(params):
s_w1, s_b1, s_w2, s_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\
torch.zeros(params[2].shape), torch.zeros(params[3].shape)
return (s_w1, s_b1, s_w2, s_b2)
# 对每一个参数进行RMSprop法
def rmsprop(params,states,lr=0.01,gamma=0.9):
gamma, eps = gamma, 1e-6
for p, s in zip(params,states):
with torch.no_grad():
s[:] = gamma * s + (1 - gamma) * torch.square(p.grad)
p[:] -= lr * p.grad / torch.sqrt(s + eps)
p.grad.data.zero_()
model_31 = MyNet(dropout=0)
train_all_loss31,test_all_loss31,\
train_ACC31,test_ACC31 \
= train_and_test(model=model_31,epochs=20,init_states=init_rmsprop,optimizer=rmsprop)
dropout: 0
epoch: 1 | train loss:496.50297 | test loss:85.90571 | train acc: 0.70 | test acc: 0.75
epoch: 2 | train loss:397.04907 | test loss:71.54532 | train acc: 0.77 | test acc: 0.80
epoch: 4 | train loss:352.24937 | test loss:62.14564 | train acc: 0.79 | test acc: 0.79
epoch: 6 | train loss:327.49242 | test loss:59.53483 | train acc: 0.80 | test acc: 0.76
epoch: 8 | train loss:326.74552 | test loss:66.19045 | train acc: 0.80 | test acc: 0.81
epoch: 10 | train loss:317.08560 | test loss:55.85927 | train acc: 0.81 | test acc: 0.80
epoch: 12 | train loss:314.16541 | test loss:70.23939 | train acc: 0.81 | test acc: 0.78
epoch: 14 | train loss:312.43203 | test loss:57.75320 | train acc: 0.81 | test acc: 0.80
epoch: 16 | train loss:304.61697 | test loss:62.12512 | train acc: 0.81 | test acc: 0.80
epoch: 18 | train loss:300.99380 | test loss:65.22936 | train acc: 0.81 | test acc: 0.81
epoch: 20 | train loss:294.28814 | test loss:63.74287 | train acc: 0.81 | test acc: 0.80
手动实现dropout = 0, 20轮 总用时: 187.376
3.2.2 手动实现Momentum算法
# 初始化
def init_momentum(params):
v_w1, v_b1, v_w2, v_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\
torch.zeros(params[2].shape), torch.zeros(params[3].shape)
return (v_w1, v_b1, v_w2, v_b2)
# 对每一个参数进行momentum法
def sgd_momentum(params,states,lr=0.01,momentum=0.5):
for p, v in zip(params,states):
with torch.no_grad():
v[:] = momentum * v - p.grad
p[:] += lr * v
p.grad.data.zero_()
model_32 = MyNet(dropout=0)
train_all_loss32,test_all_loss32,\
train_ACC32,test_ACC32 \
= train_and_test(model=model_32,epochs=20,init_states=init_momentum, optimizer=sgd_momentum)
dropout: 0
epoch: 1 | train loss:865.42947 | test loss:100.80932 | train acc: 0.46 | test acc: 0.63
epoch: 2 | train loss:482.56232 | test loss:70.22495 | train acc: 0.65 | test acc: 0.67
epoch: 4 | train loss:336.58501 | test loss:55.26826 | train acc: 0.74 | test acc: 0.75
epoch: 6 | train loss:287.67661 | test loss:48.56195 | train acc: 0.79 | test acc: 0.78
epoch: 8 | train loss:260.36843 | test loss:44.56490 | train acc: 0.81 | test acc: 0.80
epoch: 10 | train loss:243.72953 | test loss:42.35971 | train acc: 0.82 | test acc: 0.81
epoch: 12 | train loss:232.50333 | test loss:40.94901 | train acc: 0.83 | test acc: 0.82
epoch: 14 | train loss:224.56540 | test loss:39.67798 | train acc: 0.84 | test acc: 0.82
epoch: 16 | train loss:218.58376 | test loss:38.94638 | train acc: 0.84 | test acc: 0.83
epoch: 18 | train loss:213.26769 | test loss:38.23061 | train acc: 0.84 | test acc: 0.83
epoch: 20 | train loss:209.36230 | test loss:37.92049 | train acc: 0.85 | test acc: 0.83
手动实现dropout = 0, 20轮 总用时: 180.386
3.2.3 手动实现Adam算法
def init_adam_states(params):
v_w1, v_b1, v_w2, v_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\
torch.zeros(params[2].shape), torch.zeros(params[3].shape)
s_w1, s_b1, s_w2, s_b2 = torch.zeros(params[0].shape), torch.zeros(params[1].shape),\
torch.zeros(params[2].shape), torch.zeros(params[3].shape)
return ((v_w1, s_w1), (v_b1, s_b1),(v_w2, s_w2), (v_b2, s_b2))
# 根据Adam算法思想手动实现Adam
Adam_t = 0.01
def Adam(params, states, lr=0.01, t=Adam_t):
global Adam_t
beta1, beta2, eps = 0.9, 0.999, 1e-6
for p, (v, s) in zip(params, states):
with torch.no_grad():
v[:] = beta1 * v + (1 - beta1) * p.grad
s[:] = beta2 * s + (1 - beta2) * (p.grad**2)
v_bias_corr = v / (1 - beta1 ** Adam_t)
s_bias_corr = s / (1 - beta2 ** Adam_t)
p.data -= lr * v_bias_corr / (torch.sqrt(s_bias_corr + eps))
p.grad.data.zero_()
Adam_t += 1
model_33 = MyNet(dropout=0)
train_all_loss33,test_all_loss33,\
train_ACC33,test_ACC33 \
= train_and_test(model=model_33,epochs=20,init_states=init_adam_states, optimizer=Adam)
dropout: 0
epoch: 1 | train loss:977.12287 | test loss:39.80734 | train acc: 0.69 | test acc: 0.81
epoch: 2 | train loss:218.54420 | test loss:36.52055 | train acc: 0.83 | test acc: 0.83
epoch: 4 | train loss:178.49854 | test loss:32.04532 | train acc: 0.86 | test acc: 0.86
epoch: 6 | train loss:158.68488 | test loss:32.94441 | train acc: 0.88 | test acc: 0.86
epoch: 8 | train loss:146.79713 | test loss:33.73590 | train acc: 0.89 | test acc: 0.86
epoch: 10 | train loss:137.06564 | test loss:32.62384 | train acc: 0.89 | test acc: 0.85
epoch: 12 | train loss:130.34835 | test loss:33.36391 | train acc: 0.90 | test acc: 0.86
epoch: 14 | train loss:122.98791 | test loss:30.13885 | train acc: 0.90 | test acc: 0.87
epoch: 16 | train loss:118.01618 | test loss:34.34515 | train acc: 0.91 | test acc: 0.85
epoch: 18 | train loss:111.67874 | test loss:33.48384 | train acc: 0.91 | test acc: 0.87
epoch: 20 | train loss:108.85642 | test loss:28.81685 | train acc: 0.91 | test acc: 0.88
手动实现dropout = 0, 20轮 总用时: 195.174
3.2.4 torch.nn实现RMSprop算法
# 使用torch 提供的 RMSprop
model_34 = MyNet_NN(dropout=0)
model_34 = model_34.to(device)
opti_RMSprop = torch.optim.RMSprop(model_34.parameters(), lr=0.01, alpha=0.9, eps=1e-6)
train_all_loss34,test_all_loss34,\
train_ACC34,test_ACC34 \
= train_and_test_NN(model=model_34,epochs=20,optimizer=opti_RMSprop)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:327.75258 | test loss:36.48523 | train acc:0.771633 test acc:0.82990:
epoch: 2 | train loss:207.45770 | test loss:38.46234 | train acc:0.839867 test acc:0.83590:
epoch: 4 | train loss:185.50436 | test loss:34.74823 | train acc:0.863683 test acc:0.85480:
epoch: 6 | train loss:175.43034 | test loss:39.56436 | train acc:0.872400 test acc:0.84330:
epoch: 8 | train loss:166.55864 | test loss:42.55430 | train acc:0.878000 test acc:0.84070:
epoch: 10 | train loss:162.49881 | test loss:40.32271 | train acc:0.883033 test acc:0.86420:
epoch: 12 | train loss:157.36479 | test loss:39.31301 | train acc:0.884267 test acc:0.86580:
epoch: 14 | train loss:155.47657 | test loss:49.91537 | train acc:0.888567 test acc:0.85810:
epoch: 16 | train loss:155.83041 | test loss:44.48253 | train acc:0.889767 test acc:0.86320:
epoch: 18 | train loss:150.08707 | test loss:42.73475 | train acc:0.892683 test acc:0.86040:
epoch: 20 | train loss:150.37581 | test loss:45.74147 | train acc:0.893817 test acc:0.86320:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 160.811s
3.2.5 torch.nn实现Momentum算法
# 使用torch 提供的 Momentum
model_35 = MyNet_NN(dropout=0)
model_35 = model_35.to(device)
opt_Momentum = torch.optim.SGD(model_35.parameters(),lr=0.01, momentum=0.5)
train_all_loss35,test_all_loss35,\
train_ACC35,test_ACC35 \
= train_and_test_NN(model=model_35,epochs=20,optimizer=opt_Momentum)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:527.70305 | test loss:59.81030 | train acc:0.660100 test acc:0.73150:
epoch: 2 | train loss:311.16962 | test loss:49.36548 | train acc:0.776650 test acc:0.78220:
epoch: 4 | train loss:246.42763 | test loss:42.30816 | train acc:0.822983 test acc:0.81500:
epoch: 6 | train loss:224.65415 | test loss:39.68113 | train acc:0.835917 test acc:0.82290:
epoch: 8 | train loss:213.19915 | test loss:37.97090 | train acc:0.844800 test acc:0.82850:
epoch: 10 | train loss:205.16319 | test loss:36.42515 | train acc:0.849933 test acc:0.83740:
epoch: 12 | train loss:198.74544 | test loss:35.57186 | train acc:0.854350 test acc:0.84030:
epoch: 14 | train loss:193.31012 | test loss:34.89748 | train acc:0.857350 test acc:0.84250:
epoch: 16 | train loss:188.62091 | test loss:34.22897 | train acc:0.861083 test acc:0.84590:
epoch: 18 | train loss:184.45801 | test loss:34.43188 | train acc:0.864250 test acc:0.84520:
epoch: 20 | train loss:180.47259 | test loss:33.40635 | train acc:0.866550 test acc:0.85010:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 158.962s
3.2.6torch.nn 实现Adam算法
# 使用torch 提供的 Adam
model_36 = MyNet_NN(dropout=0)
model_36 = model_36.to(device)
opt_Adam = torch.optim.Adam(model_36.parameters(), lr=0.01, betas=(0.9,0.999),eps=1e-6)
train_all_loss36,test_all_loss36,\
train_ACC36,test_ACC36 \
= train_and_test_NN(model=model_36,epochs=20,optimizer=opt_Adam)
MyNet_NN(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout(p=0, inplace=False)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:239.72011 | test loss:40.29385 | train acc:0.817000 test acc:0.82140:
epoch: 2 | train loss:177.92484 | test loss:33.07817 | train acc:0.861700 test acc:0.85240:
epoch: 4 | train loss:160.04629 | test loss:32.41718 | train acc:0.875867 test acc:0.85010:
epoch: 6 | train loss:149.91095 | test loss:31.50968 | train acc:0.882550 test acc:0.85340:
epoch: 8 | train loss:142.18498 | test loss:29.33314 | train acc:0.887667 test acc:0.87310:
epoch: 10 | train loss:135.84223 | test loss:30.49203 | train acc:0.892883 test acc:0.86750:
epoch: 12 | train loss:134.24267 | test loss:30.44989 | train acc:0.894433 test acc:0.86640:
epoch: 14 | train loss:130.88283 | test loss:33.12540 | train acc:0.894767 test acc:0.86780:
epoch: 16 | train loss:128.21076 | test loss:33.35650 | train acc:0.897533 test acc:0.86220:
epoch: 18 | train loss:125.64576 | test loss:31.23838 | train acc:0.900550 test acc:0.87000:
epoch: 20 | train loss:123.62410 | test loss:31.14968 | train acc:0.902250 test acc:0.87080:
torch.nn实现前馈网络-多分类任务 20轮 总用时: 145.588s
手动实现的各种优化器的效果-以Loss值的变化显示
#完成loss的显示
drop_name_5= ['RMSprop','Momentum','Adam','手动实现不同的优化器-Loss变化']
drop_train_5 = [train_all_loss31,train_all_loss32,train_all_loss33]
drop_test_5= [test_all_loss31,test_all_loss32,test_all_loss33]
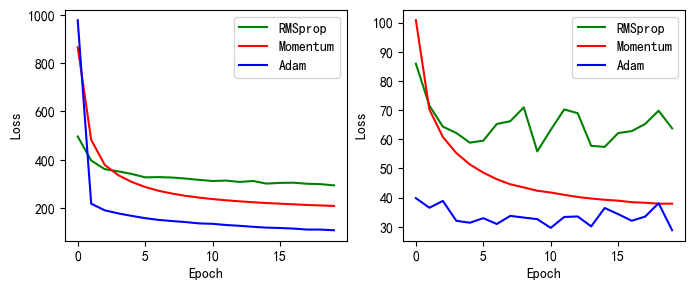
picture(drop_name_5, drop_train_5,drop_test_5)
torch.nn实现的各种优化器的效果-以Loss值的变化显示
#完成loss的显示
drop_name_6= ['RMSprop','Momentum','Adam','torch.nn实现不同的优化器-Loss变化']
drop_train_6 = [train_all_loss34,train_all_loss35,train_all_loss36]
drop_test_6= [test_all_loss34,test_all_loss35,test_all_loss36]
picture(drop_name_6, drop_train_6,drop_test_6)
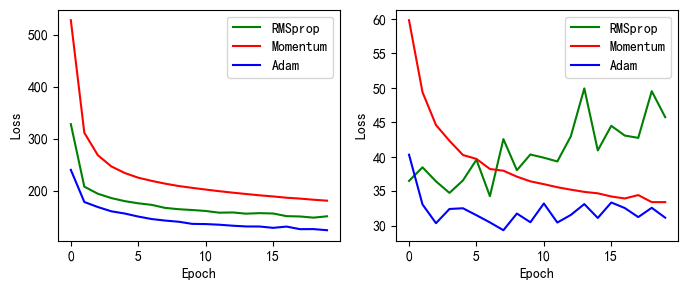
上图为手动实现和torch.nn实现的不同的实验的损失值的变化,左边的为训练集上的结果,右边的为测试集合上的结果。
从图中可以看出,不同的优化器有着不同的特点,故损失函数的下降有所不同。
- SGD: 它的思想是,将样本数据挨个送入网络,每次使用一个样本就更新一次参数,这样可以极快地收敛到最优值,但会产生较大的波动。还有一种是小批量梯度下降法,它的思想是,将数据拆分成一小批一小批的,分批送入神经网络,每送一批就更新一次网络参数。
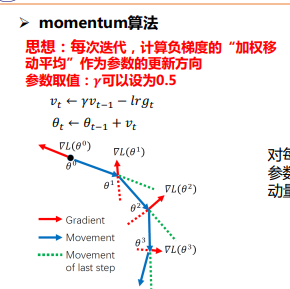
- Momentum: 在更新网络参数时,如果前几次都是朝着一个方向更新,那么下一次就有很大的可能也是朝着那个方向更新,那么我们可以利用上一次的方向作为我这次更新的依据. 这种方法还可以从一定程度上避免网络陷入到局部极小值。
- RMSprop: 为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重W和偏置b的梯度使用了微分平方加权平均数。
- Adam: Adam算法可以看做是RMSProp算法与动量法的结合
四、在多分类任务实验上实现早停机制
4.1 任务内容
- 任务具体要求
选择上述实验中效果最好的组合,手动将训练数据划分为训练集和验证集,实现早停机制,并在测试集上进行测试。训练集:验证集=8:2,早停轮数为5. - 任务目的
学习早停机制 - 任务算法或原理介绍
L 2 L_2 L2 原理
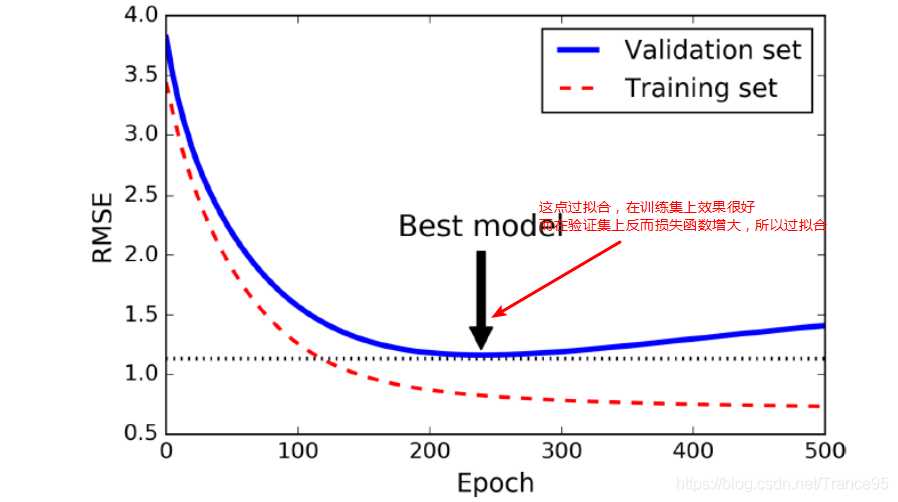
即当模型在训练集上的误差降低的时候,其在验证集上的误差表现不会变差。反之,当模型在训练集上表现很好,在验证集上表现很差的时候,我们认为模型出现了过拟合。当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题。
- 任务所用数据集
Fashion-MNIST数据集:- 该数据集包含60,000个用于训练的图像样本和10,000个用于测试的图像样本。
- 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784
4.2 任务思路及代码
- 构建数据集
- 构建前馈神经网络,损失函数,优化函数
- 进行反向传播,和梯度更新
- 使用网络预测结果,得到损失值
- 构建早停机制
按照要求构建数据集
import random
# 得到0-60000的下标
index = list(range(len(traindataset)))
# 利用shuffle随机打乱下标
random.shuffle(index)
# 按照 训练集和验证集 8:2 的比例分配各自下标
train_index, val_index = index[ : 48000], index[48000 : ]
# 由分配的下标得到对应的训练和验证及的数据以及他们对应的标签
train_dataset, train_labels = traindataset.data[train_index], traindataset.targets[train_index]
val_dataset, val_labels = traindataset.data[val_index], traindataset.targets[val_index]
print('训练集:', train_dataset.shape, train_labels.shape)
print('验证集:', val_dataset.shape,val_labels.shape)
# 构建相应的dataset以及dataloader
T_dataset = torch.utils.data.TensorDataset(train_dataset,train_labels)
V_dataset = torch.utils.data.TensorDataset(val_dataset,val_labels)
T_dataloader = torch.utils.data.DataLoader(dataset=T_dataset,batch_size=128,shuffle=True)
V_dataloader = torch.utils.data.DataLoader(dataset=V_dataset,batch_size=128,shuffle=True)
print('T_dataset',len(T_dataset),'T_dataloader batch_size: 128')
print('V_dataset',len(V_dataset),'V_dataloader batch_size: 128')
训练集: torch.Size([48000, 28, 28]) torch.Size([48000])
验证集: torch.Size([12000, 28, 28]) torch.Size([12000])
T_dataset 48000 T_dataloader batch_size: 128
V_dataset 12000 V_dataloader batch_size: 128
def train_and_test_4(model=model,epochs=30,lr=0.01,weight_decay=0.0):
print(model)
# 优化函数, 默认情况下weight_decay为0 通过更改weight_decay的值可以实现L2正则化。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.9,0.999),eps=1e-6)
criterion = CrossEntropyLoss() # 损失函数
train_all_loss = [] # 记录训练集上得loss变化
val_all_loss = [] # 记录测试集上的loss变化
train_ACC, val_ACC = [], []
begintime = time.time()
flag_stop = 0
for epoch in range(1000):
train_l, train_epoch_count, val_epoch_count = 0, 0, 0
for data, labels in traindataloader:
data, labels = data.to(torch.float32).to(device), labels.to(device)
pred = model(data)
train_each_loss = criterion(pred, labels.view(-1)) # 计算每次的损失值
optimizer.zero_grad() # 梯度清零
train_each_loss.backward() # 反向传播
optimizer.step() # 梯度更新
train_l += train_each_loss.item()
train_epoch_count += (pred.argmax(dim=1)==labels).sum()
train_ACC.append(train_epoch_count/len(traindataset))
train_all_loss.append(train_l) # 添加损失值到列表中
with torch.no_grad():
val_loss, val_epoch_count= 0, 0
for data, labels in testdataloader:
data, labels = data.to(torch.float32).to(device), labels.to(device)
pred = model(data)
val_each_loss = criterion(pred,labels)
val_loss += val_each_loss.item()
val_epoch_count += (pred.argmax(dim=1)==labels).sum()
val_all_loss.append(val_loss)
val_ACC.append(val_epoch_count / len(testdataset))
# 实现早停机制
# 若连续五次验证集的损失值连续增大,则停止运行,否则继续运行,
if epoch > 5 and val_all_loss[-1] > val_all_loss[-2]:
flag_stop += 1
if flag_stop == 5 or epoch > 35:
print('停止运行,防止过拟合')
break
else:
flag_stop = 0
if epoch == 0 or (epoch + 1) % 4 == 0:
print('epoch: %d | train loss:%.5f | val loss:%.5f | train acc:%5f val acc:%.5f:' % (epoch + 1, train_all_loss[-1], val_all_loss[-1],
train_ACC[-1],val_ACC[-1]))
endtime = time.time()
print("torch.nn实现前馈网络-多分类任务 %d轮 总用时: %.3fs" % (epochs, endtime - begintime))
# 返回训练集和测试集上的 损失值 与 准确率
return train_all_loss,val_all_loss,train_ACC,val_ACC
model_41 = MyNet_NN(dropout=0.5)
model_41 = model_41.to(device)
train_all_loss41,test_all_loss41,\
train_ACC41,test_ACC41 \
= train_and_test_4(model=model_41,epochs = 10000,lr=0.1)
4.3 结果分析
得到的loss曲线如下
#完成loss的显示
drop_name_6= ['','早停机制']
drop_train_6 = [train_all_loss41]
drop_test_6= [test_all_loss41]
picture(drop_name_6, drop_train_6,drop_test_6)
随着epoch的增加,如果在验证集上发现测试误差上升超过五轮,则停止训练
A1 实验心得
学会手动构建前馈神经网络和利用torch.nn构建前馈神经网络,并且在此之上实现dropout 添加惩罚权重,运用不同的优化函数,以及实现早停机制
- 实验中发现dropout的设置会有效防止模型的过拟合现象
- 惩罚权重在一定程度上增大模型输出的loss,有防止过拟合的作用。
- 不同的优化器有着不同的效果,在进行训练的时候可以选择不同的优化器作比较
- 早停机制,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练;起着防止网络过拟合的作用
A2 参考文献
参考课程PPT


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









