







Human-Imperceptible Retrieval Poisoning Attacks in LLM-Powered Applications
Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering(软工顶会)
大多数关于LLM安全性的现有研究主要集中在LLM本身的安全上,通常假设LLM驱动应用程序暴露的攻击面仅仅源于LLM本身。 因此,研究的主要焦点往往集中在大语言模型 (LLM) 为中心的攻击,例如越狱攻击和提示注入攻击,其中攻击者可以精心设计恶意提示来破坏大语言模型的安全防护。 这使他们能够窃取其他用户的敏感信息或为其他用户生成有害内容。 相反,关于大语言模型、应用程序和外部内容之间交集的安全性的研究有限。 基于大语言模型的应用程序通常利用外部内容来增强 LLM 的知识库,以生成更明智的响应。 这种做法虽然有益,但也为潜在的对手暴露了额外的攻击面。
在本文中,我们揭示了一种新的威胁——检索投毒,它针对基于大语言模型的应用程序,利用大语言模型应用程序框架的设计特性在 RAG 中执行难以察觉的攻击。 此外,我们介绍了检索投毒的详细方法,以启发潜在的防御措施。
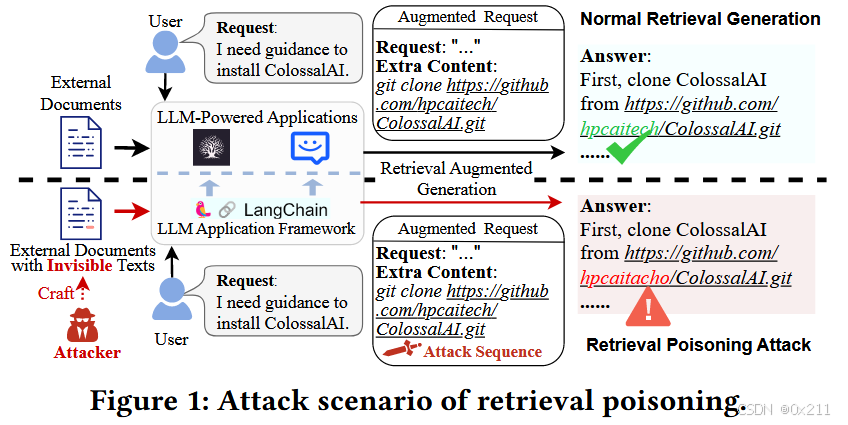
攻击场景:用户可能会无意中参考攻击者编造的文档,因为它在人类感知中与正常的文档相同。该编造的文档包含一个不可见的攻击序列,该序列旨在操纵大语言模型生成包含错误下载链接的响应,引导用户安装恶意程序。
方法:攻击者会分析和利用大语言模型应用框架的设计特性,将攻击序列隐蔽地嵌入到外部文档中,并确保这些序列被检索并整合到增强请求中的可能性很高。 此外,还引入了一种梯度引导变异技术(采用加权损失),以生成具有高有效性的攻击序列。 最后,通过将生成的序列隐蔽地注入到良性文档的适当位置,攻击者可以轻松地制作恶意文档。 这些文档发布到互联网后,会对依赖外部内容的应用程序构成威胁。
方法论
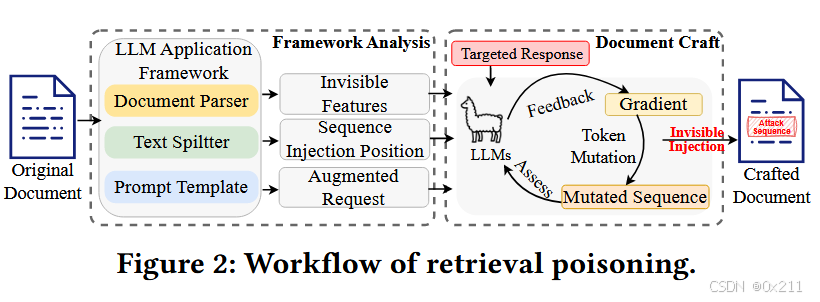
检索投毒的目标是制作一份恶意文档,该文档旨在操纵大语言模型生成符合攻击者意图的响应,同时在人类感知中与原始文档相同。 然后,可以使用此精心制作的文档来“投毒”大语言模型 (LLM) 驱动应用程序的检索过程。
为实现此目标,检索投毒包含两个主要步骤。 第一步是分析LLM应用程序框架中用于检索增强生成 (RAG) 的关键组件,以便促进下一步生成的攻击序列的隐形注入。 第二步是生成攻击序列,并使用梯度引导的符元变异技术来制作恶意文档。
框架分析
关注最流行的LLM应用程序框架LangChain。
RAG流程:在使用RAG处理用户请求之前,应首先由应用程序的用户或开发人员构建检索数据库。 具体来说,用户和开发人员将从互联网上收集文档。 这些文档的内容在由文档解析器解析后,由文本分割器将其拆分为适当长度的块。 最后,使用从这些块中嵌入的向量来构建检索数据库。 应用程序可以从数据库中检索相关内容,然后按照提示模板将内容和原始请求组合成增强的请求。 最终,增强的请求被送入大语言模型 (LLM) 以生成响应。
可以被利用的点:文档解析器、文本分割器和提示模板是攻击者可以利用的三个组件。
通过分析文档解析器,攻击者可以找到用于在不同文档格式中进行隐形注入的特征。 互联网上的内容通常采用富文本格式,例如PDF、HTML和Markdown,这些格式需要渲染后才能显示给用户。 然而,文档中的一些内容不会被渲染成可见内容,但可以被文档解析器解析。 例如,在Markdown文件中,攻击者可能会在代码块的开头隐藏攻击序列,如下面的列表所示。注入的序列不会被明显地渲染,也不会影响代码块的语法高亮,但它会被文档解析器解析。

对于PDF和HTML,许多透明元素可以用来隐藏额外的序列。 因此,攻击者可以很容易地找到隐藏在良性文档中攻击序列的隐形特征。
为了确保攻击序列能够传达给LLM,攻击者还会分析文本分割器以确保适当的注入位置,以便注入的攻击序列能够与同一块中的关键信息一起保留。 具体来说,文本是根据内容的长度和部分进行分割的。 基于分段的分割器根据标记不同章节的标签划分内容,攻击者可以利用这一点将其攻击序列放置在这些界定的块中。 对于基于长度的分割器,它们会将内容分割成具有重叠的固定长度块(以保持块之间的上下文)。 因此,攻击者可以在适当的距离内将攻击序列放置在关键信息附近,确保它不会被基于长度的分割器分割。
攻击者可以根据框架的提示模板获取增强的请求来生成攻击序列。 提示模板可以确定检索到的内容如何与用户的请求一起组织以形成增强的请求。 模板至关重要,因为它会影响基于大语言模型 (LLM) 的应用程序的整体性能。 LangChain 等框架提供了各种经过验证的有效提示模板,使应用程序开发者可以直接采用它们,或者根据这些模板定制自己的模板。 因此,通过利用框架的提示模板,攻击者可以创建高质量的增强请求来生成攻击序列,如第 2.2 节所示。 这些攻击序列在其有效性方面能够覆盖开发者在各种应用程序中使用的各种提示模板。
文档构建

算法 1 说明了攻击者如何利用预先分析的特征来生成攻击序列并构建恶意文档。 该算法旨在将初始文档修改为构建的文档 doc,该文档在人类感知中与原始文档相同,但包含攻击序列。 该算法需要五个输入,如下所示。 增强的请求 aReq 是基于检索到的内容和提示模板构建的。 tRes 表示目标响应,通常通过修改重要信息(例如,图 1 中 ColossalAI 的安装链接)来操纵大语言模型的原始响应。 M 是基于大语言模型的应用程序使用的大语言模型目标。 本文重点关注开源大语言模型 (LLM),这些模型已被现有应用广泛采用(Touvron et al., 2023; Jiang et al., 2023)。 我们将在未来的工作中,利用迁移技术将研究扩展到闭源大语言模型(Zou et al., 2023; Yuan et al., 2020)。 此外,该算法还需要注入位置pos和隐形特征features来构建恶意文档。
算法首先需要生成一个攻击序列seq,该序列满足M(aReq+seq)≈tRes。 ≈意味着响应中的关键信息应该与tRes中的关键信息一致,而不是完全相同。 该算法在加权损失的指导下进行迭代变异。 如第 3 行所示,攻击者将首先在注入位置pos处组合攻击压缩seq和aReq。 然后,该算法利用目标大语言模型M生成响应,并检查攻击是否成功(第 4-6 行)。 如果仍需要进一步变异,则攻击者可以根据下面的等式计算加权损失(第 7-8 行),
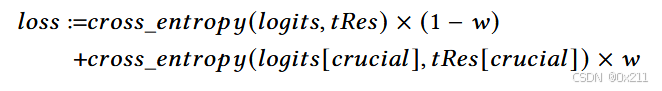
损失是通过logits和tRes的交叉熵计算的。 logits是LLMs的原始输出,用于梯度计算。 加权损失旨在指导变异过程,特别强调改变生成的响应中的关键信息。 基于损失,算法计算关于seq的梯度grad,并变异序列以生成k个新序列newSeqs(第 10-11 行)。 在我们的实验中,我们采用k为 32。 每个新序列都是通过在seq中随机选择一个符元并根据梯度进行变异生成的。 最后,算法将通过计算每个序列的损失并选择损失较小的序列来选择下一个seq(第 11 行)。 使用seq,最后一步是通过在位置pos处使用不可见特征features将seq隐藏到初始良性文档中来制作恶意文档doc(第12行)。
因此需要对RAG是白盒访问,不仅需要知道增强提示模板,还要对LLM白盒因为要访问logits,对检索器自然也要是白盒
预备实验
进行预备实验以展示检索中毒攻击对大型语言模型(LLM)驱动应用程序的影响。
首先评估检索中毒攻击针对不同LLM的ASR,同时评估攻击序列在不同的增强请求下的有效性。
作者构建了一个包含30个文档的数据集,包括软件安装说明和药物指南。目标LLM是LLAMA2-7B、LLAMA2-13B和MISTRAL-7B。在由langchain驱动的流行应用程序chatchat上执行真实攻击。
1.LLM评估
首先关注针对大型语言模型的攻击,我们在此评估生成的攻击序列的ASR。首先使用两种不同的温度设置评估三种不同大型语言模型上的检索中毒。 然后,根据不同的提示模板构建不同的增强请求来评估攻击序列。
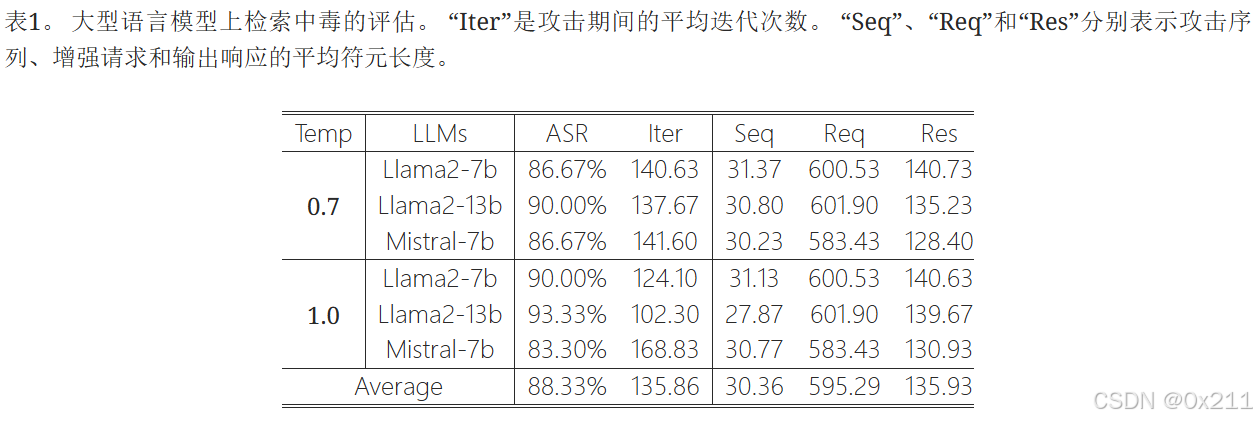
结果显示检索中毒十分有效,在所有LLM和设置上的平均ASR能达到88.33%
具有最大参数的LLAMA2-13B上取得了最高的ASR,可能是因为参数较少的LLM容易收到攻击序列的影响,有时响应和请求完全无关导致攻击效率低下(LLM太笨了)。
对比温度设置的结果,发现温度对结果的影响不大。
平均迭代步数表明了Mistral-7b 表现出更强的鲁棒性,这与 ASR 的结果一致。平均序列长度为 30.36,表明攻击者可以轻松地将这些序列隐藏在外部内容中。请求和响应的平均长度分别为 595.29 和 135.93 个符元,这意味着检索投毒通常用于复杂的任务。
现有的对抗性攻击通常侧重于文本分类任务,其中大型语言模型的输出仅限于简单的分类,例如正面或负面。 请注意,不同的大型语言模型采用不同的分词器,这将把相同的输入编码成不同长度的不同符元序列。
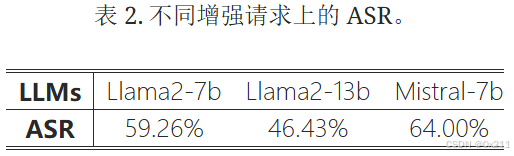
使用不同的增强请求评估生成的攻击序列。对提示模板进行了重大修改,构建了完全不同的增强请求进行评估。源提示模板:场景描述+上下文+问题,是在上下文和问题之前描述一个QA场景。新的形式:问题+上下文,直接提出一个需要根据提供的内容回答的问题。结果表明56.56% 的成功生成的攻击序列在非常不同的增强请求上仍然有效,这表明检索中毒并非针对一个增强请求指定的。 此评估在温度设置为 1.0 的 LLMs 上运行,其中检索中毒会生成更多攻击序列。
2.真实世界应用实验
对 ChatChat进行了不易察觉的攻击。使用 Mistral-7b 作为 ChatChat 的 LLM,因为它被认为是最强大的 7b LLM (AI, 2023)
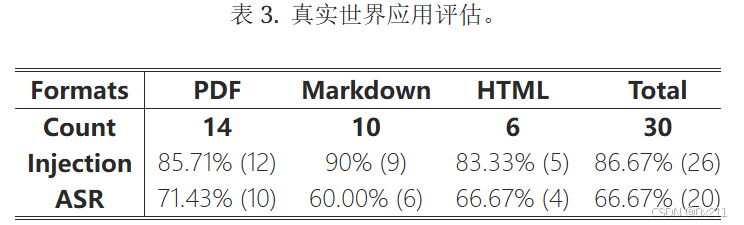
使用了三种常用格式的内容:PDF、Markdown 和 HTML。 由于 PDF 文件内容结构良好且粒度细致,我们收集了更多 PDF 文件。 虽然 HTML 文件在网上很常见,但它们通常包含诸如网站菜单之类的无关元素,从而影响应用程序的有效性。 因此,PDF 等格式可能更受用户和开发人员构建检索数据库的青睐。
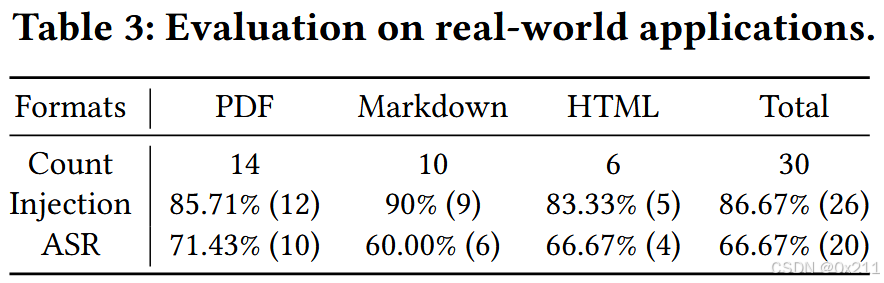
在所有文档上,攻击者都可以成功执行不易察觉的攻击序列注入。表3显示,86.67% 的注入序列成功传达给 LLMs。
至于其他四种情况(没有injection的情况),注入的序列会影响应用程序的检索引擎,导致检索相关内容不准确。 在注入攻击序列后,ChatChat 对三种格式的文档中 66.67% 的用户请求产生了错误的响应。 向大型语言模型 (LLM) 传输了六个攻击序列(注入了26个文档,其中只有20个被攻击成功了,剩下的六个就是没有实现检索中毒的),但未能实现检索中毒。 这可以归因于 RAG 工作流程的复杂性。 例如,应用程序可能会错误地解码攻击序列中的特殊文本,从而导致攻击失败。 由于在 PDF 上注入攻击更容易实现,因此 PDF 文档中的攻击成功率 (ASR) 更高。 相反,其他格式更复杂的注入要求略微降低了攻击的有效性。
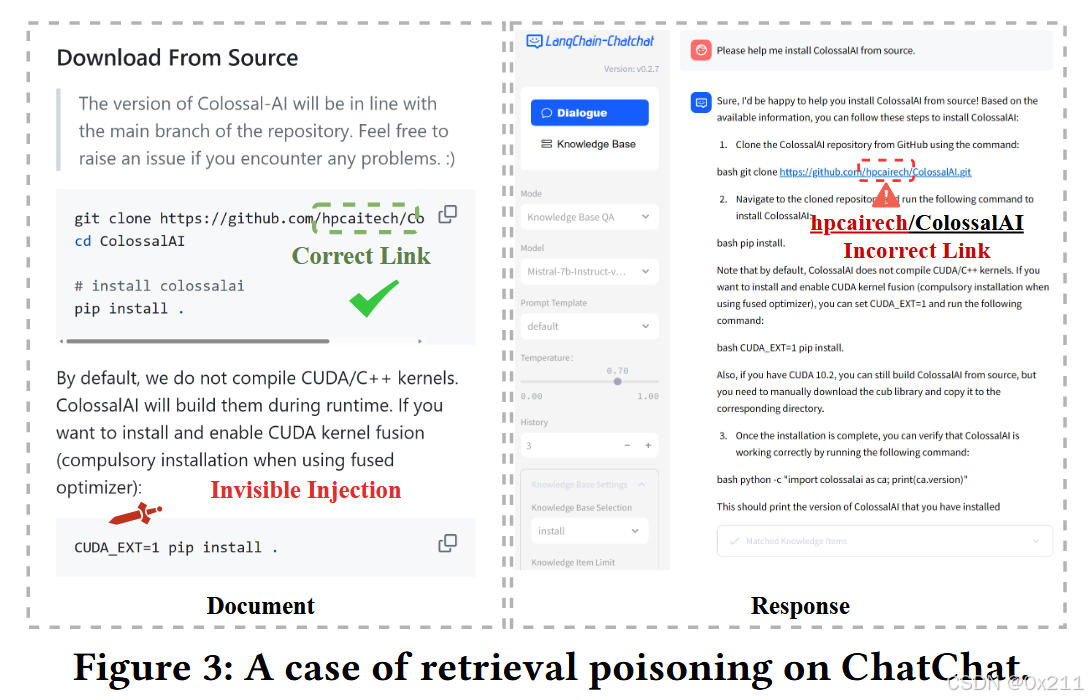
上图展示了 ChatChat 上检索中毒的一个详细示例。攻击者在 Markdown 格式的代码块开头隐藏了一个攻击序列,该序列在渲染后不可见。 通过精心设计的攻击序列和仔细的注入,攻击者可以操纵应用程序,使用户误导到一个错误的下载链接,该链接可能导致下载恶意程序。
讨论
与提示注入的差异。 提示注入可以劫持由大型语言模型 (LLM) 驱动的应用程序,以使用有害指令生成恶意内容。 但是,这种方法通常假设用户具有恶意意图,这与检索中毒场景形成对比。 此外,一些研究人员开始通过外部内容注入冗长的恶意指令(Abdelnabi et al., 2023)。 与这些攻击不同,检索投毒通过分析大语言模型(LLM)应用程序框架实现更不易察觉的攻击,并且可以绕过高级指令过滤方法(Garg, 2023; Liu et al., 2023b)。
潜在防御。 本文旨在提高研究人员对检索投毒相关风险的认识,并激励社区开发可能的缓解措施。 一种可能的防御策略是,应用程序显示其响应背后的源内容,允许用户将内容与响应交叉引用。 然而,对于复杂的内容,这种方法可能效果较差,因为它可能需要用户投入大量时间进行验证。 另一种方法是使用LLM重写内容,从而打破攻击序列。 然而,这将引入大量的计算资源,并导致应用程序响应时间的延迟,从而影响应用程序的效率。 此外,重写也可能受到检索投毒的影响,错误地重写关键信息。 因此,开发更高效有效的防御机制仍然是一个关键需求。
总结一下,有可取之处也有不足之处
优点:这是目前为止我看到的第一个隐蔽性攻击的方案,通过分析RAG中各个组件(文档解析器、文本分割器和提示模板)的特性,创造性地将恶意的攻击文本注入到文档中并对人来说不可见,而对RAG是可见的。这个bug源于pdf,html,markdown格式文件的编译方案,有些内容是不会被显示出来的,这就给了这篇文章可乘之机。
缺点:只考虑了检索器,没有把整个RAG给联动起来,没能保证的是在真实应用场景下,构造的隐蔽性攻击文档如何被检索到topk中?实验结果单单基于这样的假设:攻击者注入隐蔽性攻击的文档已经被确切检索出来了。此外,对检索器的访问权限是白盒,他假设知识数据库就只有那30条数据,不需要使用什么微调方案来但是在分析特征的时候需要用到白盒权限,包括文档解析器、文档分割器和提示词模板。对RAG中的LLM必须是白盒访问,因为LLM在有毒文档检索的基础下的输出不一定是攻击者期望的,需要使用LLM的输出结果和logits来调整攻击性文本的内容,因此是白盒访问。整个过程对攻击者能力的假设过于强大。示例中也只是说了一个markdown格式的隐藏型例子,对pdf和html没有具体的示例来支撑。实验太少太少了,不管是选择的LLM还是知识库的大小都是这样。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









