






https://www.bilibili.com/video/BV12b411K7Zu?p=229&spm_id_from=pageDriver
常见函数
概念:类似于java的方法,将一组逻辑语句封装在方法中,对外暴露方法名
好处:隐藏了 实现细节 2.提高代码的重用性能
调用函数:select 函数(实参列表)[from 表];
特点":1.叫什么(函数)
2.干什么(函数功能)
分类1.单行函数
如 concat ,length ,ifnull等
2.分组函数
功能做统计使用,又称为统计函数,聚合函数

字符函数
#1.length 获取参数值的字节个数
select length("john");
select length("张三丰");
conncat 拼接字符串
select concat(last_name,'_',first_name) 姓名 from employees;
3.upper lower
select upper('json');//大写
select lower('json');//小写
列子:將姓变大写,名变小写,然后排序
select concat(upper(last_name),lower(first_name)) 姓名 from employees;
4.substr ,substring
注意下表是从1开始
#截取从指定索引处后面所有的字符
select substr(‘李莫愁爱上了陆展元’,7) out_put;//陆展元
#截取从指定索引处指定字符的字符串
select substr(‘李莫愁爱上了张无忌’,1,3) out_put;//李莫愁
#案列:姓名中首字符大写 其他字符用小写用——拼接显示出来
select concat(upper(substr(last_name,1,1)),'_',lower(substr(last_name,2)))out_put from employees;
instr 返回字符串第一次出现的索引,如果找不到 返回0
select Instr(‘杨不悔爱上了闫柳霞’,‘闫柳霞’) as out_put;
6trim 去除首位 字符
select length(trim(' 张翠山 '))as out_put;//张翠山 去除首位空格 并且返回长度9
select trim( 'a' from'aaaaaaaa张aaaaaaaaaaaa翠山aaaaaaaaa') as out_put;//张aaaaaaaaaaaa翠山
7 lpad 用指定的字符实现左填充
select lpad('闫肃肃',10,'*') as out_put; //*******闫肃肃
8. rpad 用指定的字符实现右填充
select lpad('闫肃肃',10,'*') as out_put; //闫肃肃*******
9.repalce 替换
select replace('张无忌爱上了周芷若','周芷若','赵敏') as out_put;
数学函数
round 四舍五入
select round(-1.55); //-2
select round(1.567,2)//1.57
ceil 向上取整 返回>=该参数的最小整数
select ceil(1.00);//1
select ceil(-1.02);//-1
fooor 向下取整,返回<=该参数的最大整数
select Floor(-9.99);//-10
select Floor(9.99);//9
truncate 截断
select truncate(10.6999999,2);///10.69
mod 取余 前面的参数为负 则余数为负数 ,前面的为正数 则取余的结果为正数

select mod(10,-3);//1
select mod(-10,3);//-1
select 10%3;//1
三 日期函数
返回的是当前的系统时间 不包含时间
select now();
curtime 返回的是当前的时间 ,不包含日期
select Curtime();
可以获取指定的部分的 ,年,月,日,小时,分钟,秒
select year(now()) 年;
select year('1999-1-1') 年;
select month(now()) 月;//4
select monthname(now()) 月;//April
st_to_date 将字符通过指定的格式转换成日期

select str_to_date('1998-3-2','%Y-%c-%d') as out_put;
查询入职日期为1992–2-6的员工信息
select * from employees where hiredate="1992-2-6';
select * from employees where hiredate= str_to_date('2-6 1992','%c-%d %Y');
date_format 将日期转成字符串
select Date_format(now(),'%y年%m月%d日') as out_put;
查询有奖金的员工和入职日期(XX月/XX日 xx年 )
select last_name,Date_format(hiredate,'%m月/%d日 %y年') 入职日期
from employees
where commission_pct is not null;
其他函数
select version(); //查看版本
select database();
slect user();
五 流程控制函数
1.if函数 if else 的效果
select if(10<5,'大','小');//小
select last_name ,commission_pct,if(commssion_pct is null,'没奖金,呵呵','有奖金,嘻嘻') 备注 from employees;
2.case 函数的使用 一 :switch case的效果
/**
java 中
switch(变量表达式){
case 常量值1:语句1;break;
‘’’’
default:语句n;break;
}
mysql中
case要判断的字段或表达式
when 常量1 then 要显示的值1或语句
when 常量2 then要显示的值2或语句2
…else 要显示的值n或语句n
end
/
/*
案例:查询的员工的工资,要求
部门编号=30,显示的工资为1.1倍
部门好 =40,显示的工资为1.2倍
部门的编号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
*/
select slalary 原始工资,department_id,
case department_id
when 30 then salary*1*1
when 40 then salary*1*1.2
when 50 then salary*1*1.3
else salary end;
case的使用二 类似于 多重if


` select salary,
case
where salary>20000 then then' A';
where salary>15000 then then' B';
where salary>10000 then then' c';
else 'D'
end as 工资级别
from employees;`
显示系统时间
select now();
2.查询员工,姓名,工资,以及提高百分之20后的结果(new salary)
select employee_id,last_name,salary*1.2 "new salary" from employees;
3. 将员工的姓名按首字母排序,并且写出名字的长度(length)
select length(last_name) 长度,substr( last_name,1,1) 首字符,last_name from employees
order by 首字符;
4.做一个查询,产生的下面的结果
select concat(last_name,'earns',salray,'monthly but wants',salary*3) as " Dream salray" from employees;
分组函数
特点:1.sum avg一般用于处理多个数值
max min count 可以处理任何类型
2.以上分组函数都忽略null值
3.可以和distinct搭配实现去重后的运算
4.count函数的单独介绍
一般使用count(*)用作统计行数
一次查询多个函数值
select sum(salary) 和,round(avg (salary),2) 平均,max(salary) 最高,min(salary) 最小,count(salary) 个数 from employees;
查询员工表中的最大入职时间和最小的入职时间的相差天数(diffrence)
select Datediff(max(hiredate),min(hiredate)) deffrence
from employees;
分组查询

简单的分组查询
select MAX(salary),job_id from employees
group by job_id;
添加分组前筛选条件
案列1:
select avg(salary),department_id from employees where email like '%a%'
group by department_id;
添加复杂的分组条件
查询每个部门的员工个数
select count(*),department_id from employees group by department_id;
添加分组后筛选
2根据1的结果进行筛选,查询哪个部门的员工个数>2
select count(*) ,department_id from employees
group by department_id
having count(*)>2;
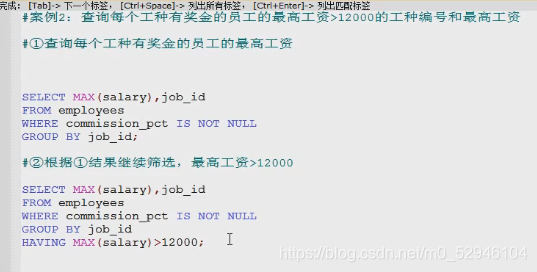
按函数分组
按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些
1.查询每个长度的员工个数
select count(*) ,Length(last_name) len_name
from employees
group by length(last_name);
2.添加筛选条件
select count(*) ,Length(last_name) len_name
from employees
group by length(last_name)
having count(*)>5;
按多个字段进行分组
案例:查询每个部门每个工种的员工的平均工资
select avg(salary),department_id,job_id
from employees
ground by department_id,job_id;
添加排序
案例:查询每个部门的每个工种的员工的平均工资,并且按平均工资的高低进行显示
select avg (salary),department_id,job_id
from employees
group by job_id,department_id
ordey by avg(salary) desc;
连接查询迪卡尔乘积
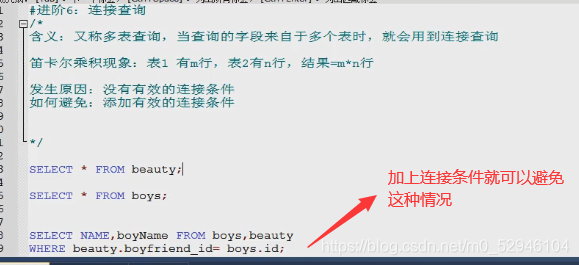
select * from beauty;
select * from boys;
select name,boyName from boys,beauty;//是上面两表的数据相乘
等值连接
select name,boyName from boys,beauty
where beauty.boyfriend_id=boys.id;
为表起别名
1.提高语句的简洁度
2.区分多个重名语句
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
select employees.last_name,employees.job_id,j.job_title
from employees e,jobs j
where e.job_id=j.job_id;//会报错
select e.last_name,e.job_id,j.job_title
from employees e,jobs j
where e.job_id=j.job_id;
等值连接,加筛选
查询城市名中第二个字符为哦的部门名和城市名
select department_name,city
from departments d,locations l
where d.location_id=l.location_id
and city like"_o%";
等值连接 加分组
select Count(*)个数 ,city
from departments d,localtions l
where d.location=l.local.id
group by city;
等值连接加排序
案例:c查询每个工种的工种号和员工的个数,并且按员工个数降序
select job_title,count(*)
from employees e,jobs j
where e.job_id =j.job_id
group by job_title
order by count(*) desc;
实现三表连接
案例 查询员工姓名 部门名,所在的城市 部门名分组 降序排列 城市名为s开头的
select last_name,department_name,city from employees e,departments d,locations l
where e.department_id=d.department_id
and d.location_id=l.location_id
and city like 's%'
order by department_name desc;
非等值连接
select * from job_grades;
select salary,employees_id from employees;
//查询员工的工资和工资级别
select salary ,grade_level
from employees e,job_grades g
where salary between g.lowest_sal and g.highest_sal ;
自连接 (自己连接自己)

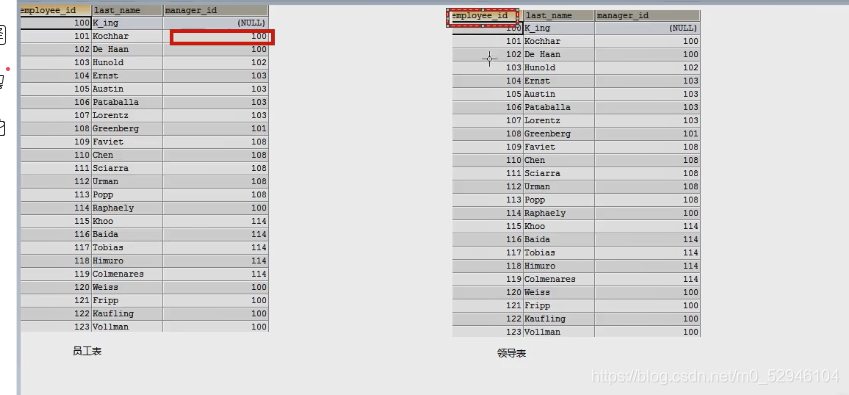
#查询姓名中包含字符k的员工的名字,上级的名字
select e.employee_id,e.last_name,m.employee_id,m.last_naem
from employees e,employees m
where e.manager_id=m.employee_id;
sql 99语法

内连接
1.等值连接
案例1.查询员工名 和部门名
select last_name,department_name
from departments d
insert join employees e
on e.department_id=d.department_id;
#案列
查询部门个数>3的城市名和部门个数(添加分组+筛选)
select city ,count(*) 部门个数
from departments d
inner join locations l
on d.location_id=l.location_id
group by city
having count(*)>3;
#案例4.查询那个部门的员工数>3的部门名和员工个数,并按个数降序(添加排序)
4.1查询每个部门的员工个数
select count(*),department_name
from employees e
inner join departments d
on e.department_id=d.department_id
group by department_name;
4.2 在1的结果上筛选员工的个数>3的记录,并且排序
select count(*),department_name
from employees e
inner join departments d
on e.department_id=d.department_id
group by department_name
having count(*)>3
order by count(*) desc;
#查询员工名,部门名,工种名,并按部门名降序() //三表内连接
#5.查询员工名,部门名,工种名,并按部门名降序()
select last_name,department_name,job_title
from employees e
inner join departments d
on e.department_id=d.department_id
inner join jobs j
on e.job_id=j.job_id
order by department_name desc;
#非等值连接//内连接
#查询工资级别的个数>20的个数,并且按工资级别降序
select count(*) ,grade_level
from employees e
join job_grades g
on e.salary between g.lowest_sal and g.highest_sal
group by grade_level
having count(*)>20
order by grade_level desc;
#自连接
#查询姓名中包含字符k的员工的名字,上级的名字
select e.employee_id,e.last_name,m.employee_id,m.last_naem
from employees e
join employees m
on e.manager_id=m.employee_id
where e.last_name like '%k%';
外连接

#引入: 查询男朋友 不在男神表的女神名//左外连接
select b.name,bo.*
from beauty b
left outer join boys bo
on b.boyfriend_id =bo.id
where bo.id is null;
#引入: 查询男朋友 不在男神表的女神名//右外连接
select b.name,bo.*
from boys bo
right outer join beauty b
on b.boyfriend_id =bo.id
where bo.id is null;
全外连接
select b.*,bo.*
from beauty b
full outer join boys bo
on b.boyfriend_id=bo.id;
交叉连接 //9*9 笛卡尔乘积
select b.*,bo.*
from beauty b
cross join boys bo;
子查询

标量子查询
案例 查询job_id和141号员工相同,salary比143号员工多的员工 姓名 ,job_id和工资
select last_name,job_id,salary
from employees
where job_id=(
select job_id
from employees
where employee_id=141
)and salary>(
select salary
from employees
where employee_id=143
);
后可以加 group by 和 having
列子查询


in
返回location_idshi1400或者是1700的部门中的所有的员工姓名
1.查询location_id是1400或者1700的部门编号
select distinct department_id
from departments
where location_id in(1400,1700)
2.查询员工姓名,要求部是1.列表中的某一个
select last_name
from employees
where department_id in(
select distinct department_id
from departments
where location_id in(1400,1700)
);
any()
案例:返回其他部门中比job_id为’'it_Prog"部门任一工资低的员工编号,姓名,job_id 以及salary//any()的使用 any的意思是比里面的任意一个都小 (意思是说比最大的小)_
#1.查询job_id为it_prog 部门任一工资
select salary
from employees
where job_id='it_prog';
2.查询员工编号 姓名 job_id 以及salary,salary<#1. 的任意一个
select last_name,employee_id,job_id,salary
from employees
where salary<any(
select salary
from employees
where job_id='it_prog'
) and job_id<>'it_prog';
或者写成
select last_name,employee_id,job_id,salary
from employees
where salary<(
select max(salary)
from employees
where job_id='it_prog'
) and job_id<>'it_prog';
all()
案例三: 返回其他部门中比job_id为’'it_Prog"部门所有工资低的员工编号,姓名,job_id 以及salary
//all()的使用 any的意思是比里面的任意一个都小 (意思是说比最小的小)_
select last_name,employee_id,job_id,salary
from employees
where salary<all(
select salary
from employees
where job_id='it_prog'
) and job_id<>'it_prog';
或者写成
select last_name,employee_id,job_id,salary
from employees
where salary<(
select min(salary)
from employees
where job_id='it_prog'
) and job_id<>'it_prog';
3.行子查询(结果集一行多列或者多行多列)
案列:查询员工编号最小并且工资最高的的员工信息
select * from employees
where (employee_id,salary)=(
select min(employee_id),max(salary)
from employees
);
或者可以使用列子查询
select * from employees
where employee_id=(
select min(employee_id)
from employees
)and salary=(
select max(salary)
from employees
);
二 select 后面的子查询 //只能是一行一列(仅仅支持标量子查询)
案例:查询每个部门的员工的个数
select d.*,(
select count(*)
from employees e
where e.department_id=d.department_id
)个数
from departments d;
#案例2 :查询员工号=102的部门名
select(
select department_name
from departments d
inner joinemployees e
on d.department_id=e.department_id
where e.employee_id=102
) 部门名;
from 后面的子查询
/**将子查询当作一张表,必须起别名
*/
#案例查询每个部门的平均工资的工资等级
1.查询每个部门的平均工资
select Avg(salary),department_id
from employees
group by department_id
2.
select * from job_grades;
2连接1的结果集和job_grades表 筛选条件的平均工资 between lowest_sal and highest_sal
select ag_dep.*,g.grade_level
from(
select Avg(salary) ag,department_id
from employees
group by department_id
) ag_dep
inner join job_grades g
on ag_dep.ag between lowest_sal and hightest_sal;
四 exists(相关子查询) 后面子查询
/**
exists(完整的查询语句)
结果:
1或0
*/
#查询所有员工的部门名
select department_name
from department d
where exists(
select *
from employees e
where d.department_id=e.department_id
);
或者
select department_name
from departments d
where d.department_id in(
select department_id
from employees
);
分页查询










- 联合查询
/**
union 联合 合并 将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
…
应用的场景
要查询的结果来自于多个表,而且对个表没有直接的连接关系,单查询的信息一样时
特点:
1.要求多条查询语句的查询的列数是一至的
2.要求多条查询语句的查询的每一列的类型和顺序最好一至
3.union关键字默认是去除重复的,如果shiyongunion all 可以包含重复项
*/
#引入的案例:查询部门的编号的>90或者邮箱包含a的员工信息
案例
select id,cname,csex from t_ca where csex=‘男’
union;
select t_id,tName,tGender from t_ua where tGender=‘male’;
DML语言
/**
数据库操作语言
插入:insert
修改:update
删除:delete
/
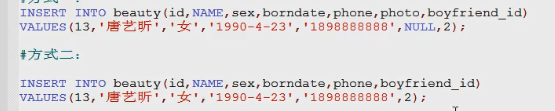
#一插入语句 方式一
/*
insert into 表明(列名) values(值1,…)
*/
#1.插入的值的类型要和列的数据类型保持一致或兼容
 # 不可以为null的列必须插入值,可以为努力了的列如何让插入值?
# 不可以为null的列必须插入值,可以为努力了的列如何让插入值?
/**
#一插入语句 方式二
语法:
insert into 表名
set 列名=值,列明=值,…
**/

修改语句
/**
1.修改单表的记录
语法:
update 表名
set 列=新值,列=新值,…
where 筛选条件
2.修改多表的记录(补充)
语法:
sql92语法:
update 表1 别名 ,表2 别名
set 列=值…
where 连接条件
and 筛选条件;Sql语法 sql99语法
update 表1 别名
inner|left|right join 表2 别名
on 连接条件
set 列=值,…
where 筛选条件
*/
#1.修改单表的记录
#案例1.修改beauty表中的姓唐的女神的电话为12346456
update beauty set phone='12346456'
where name like '%唐%';
#2.修改多表的记录
#案例1.修改张无忌的女朋友的手机号为114
update boys bo inner join beauty b on bo.id=b.boyfriend_id
set b.phone='114'
where bo.boyname='张无忌';
删除语句
方式一 :delete
语句:
1.单表的删除
delete from 表名 where 筛选条件
2.多表的删除{补充}
sql92语法
delete 别名 from 表1 别名 ,表2 别名
where 连接条件
and 筛选条件sql99语法
delete 表1的别名,表2的别名
from 表1 别名
inner|left|right join 表2 别名 on 连接的条件
where 筛选条件
方式二:truncate
语句:truncate table 表名;//意思是删除了整个表
#方式一,delete
#1.,单表的删除
#案例一:删除手机号为9结尾的女神的信息
delete from beauty where phone like ‘%9’;
#2.多表的删除
#案例:删除张无忌的女朋友的信息
delete b
from beauty b
inner join boys bo
on b.boydriend_id=bo.id
where bo.boyName=‘张无忌’;
方式二 truncate 语句
案例:truncate 表名;

DDl
/**数据定义语言
库和表的管理
- 库的管理
创建,修改,删除 - 表的管理
创建,修改,删除
创建 create
修改 alter
删除 drop
*/
#一 库的管理
- 库的创建
create database if not exists 库名; - 库名的修改
- 更改库的字符据
aleter database books character set gbk; - 库的删除
drop database if exists;
#表的管理
- 表的创建
creat table 表名(
列名 列的类型[ (长度) 约束],
列名 列的类型[ (长度) 约束],
列名 列的类型[ (长度) 约束],
列名 列的类型[ (长度) 约束],
…);
#案例:创建表Book
create table book(
id int ,#编号
bname Varchar(20),#图书名
price double, #价格
authorid int,#作者编号
publishDate Datetime#出版日期
);
- 表的修改
alter table 表名 add|drop|modify|change column
- 修改列名
alter table book change column pulishdate pubdate datetime;
2. 修改列的类型和约束
alter table book modify column pubdate timestamp(新的类名)
3. 添加新列
alter table author add column annual double
4. 删除列
> alter table author Drop column annual;
5. 修改表名
> alter table author rename to book_author;
3.表的删除
drop table if exists drop book;
4.表的复制
insert into author values
(1,‘斗破苍穹’,’'中国),
(2,‘莫言’,中国),
(3,‘冯唐’,‘中国’)
- 仅仅复制表的结构
create table copy like author;
- 复制 表的结构加数据
create table copy2
select * from author;
- 只复制部分数据
create table copy3
select id,au_name
from where nation =‘中国’;
- 仅仅复制某些字段(某些列的数据结构)
create table copy4
select id,au_name
from author
where 0;
常见的数据类型
/**
数值型
整型
小数:
定点数
浮点数
字符型:
较短的文本:char varchar
较长的文本:text blob (教程的二进制数据)
日期型:
*/
1整型
分类:
tinyint ,smallint,mediumint,int/integer,bigint
1 2 3 4 5
特点:
- 特点
-
1.如何设置无字符还是有字符,默认是是有字符,如果设置无字符,需要加unsigned 关键字
-
2.如果插入的数值超了整型的范围,会报out of range 异常,并且插入临界值
-
- 如果不设置长度 会有默认的长度
- 长度代表了显示的最大宽度,如果不够会用0在左边填充,但是必须搭配zerofill使用
#1. 如何设置无符号和有符号

小数
- 分类
1.浮点型
float(M,D)
double(M,D)
- 定点型
dec(M,D)
decimal(M,D)
- 特点
- M:整数部位+小数部位
和D小数部位
如果超出范围,则擦汗如临界值- M和D都可以省略
如果是decimal 则M默认为10,D默认为0
如果是float和double,则会根据插入数值的精度,来决定精度- 顶点型的精度比较高,如果要求插入的数值和精度较高如货币运算等则考虑使用
使用的原则
所选择的类型越简单越好,能保存数据的类型越简单越好

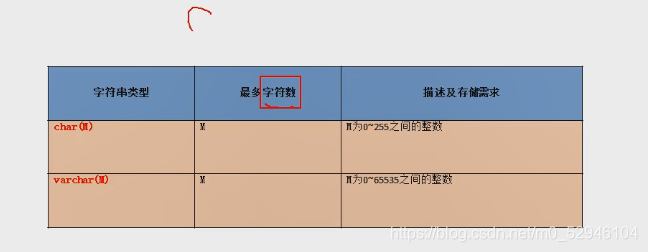
三 字符型
- 较短的文本
char
varchar
其他:
binary 和varbinary 用于保存较短的二进制
enum 用于保存枚举
set 用于保存集合较长的文本
text
blod(较大的二进制)
- 特点
写法 M的意思 特点 空间的耗费
char 最大的字符数 ,可以省略 默认为1 固定长度的字符 比较耗费
varchar 最大的字符数,不可以省略 可变长度的字符 比较节省
-
enum 枚举

-
set 集合

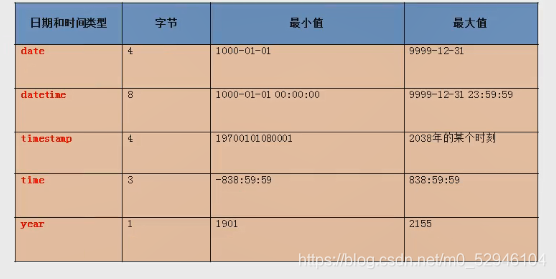
四 日期型

- select

- insert


- 修改

- 删除


- ddl 库的操作

- 表的操作

修改添加列
alter table test add column newT int first;
alter atble test add column newT int after t2;
- 删除表

- 四 复制表
- 复制表的结构
create table 表名 like 旧表- 复制表的结构加数据
create table 表名
select 查询列表 from 旧表{where 筛选}
- 一.数值型
- 整型

- 浮点型

- 二 字符型

- 三 日期型

常见约束
含义:以重限制,用于限制表的数据,为了保证表中的数据的准确性和可靠性
分类:六大约束
not null:非空,用于保证该字段的值不能为空
比如姓名,学号
defaullt:默认,用于保证该字段有默认值
比如性别
Primary key:主键,用于保证字段的值的唯一性,并且非空,
比如学号,员工编号
UNIQUE:唯一,用于保证字段的值具有唯一性,可以为空
比如座位号
check:检查约束[mysql不支持]
比如年龄,性别
foreign key :外键,用于限制两个表的关系,
用于保证该字段的值 必须来自主表的关联列的值, 在从表添加外键约束,用于引用主表种某列的值.
比如学生表的专业编号,员工标号,员工表的工种标号
- 添加约束的时机
1. 创建表时
2.修改表时
# 约束的添加分类:
- 列级约束:
六大约束语法上都支持,但是外键约束没有效果
- 表级约束:
除了非空,默认,其他的都支持create table 表名( 字段名 字段类型 列级约束 字段名 字段类型, 表级约束)
创建表的时候添加约束
1.添加列级约束
create table stuinfo(
id int primary key,#主键
stuName varchar(20) not null,#非空
gender char(1) check ( gender=‘男’ or gender=‘女’),#检查
seat int unique,#唯一
age int default 18,#默认约束
majorId int foreign key references major(id)#id);
create table major(
id int primay key,
majorName varchar(20)
);
- 添加表级别约束
语法: 在各个字段的最下面
{constraint 约束名 } 约束类型(字段名)
大括号中可省略
#通用的写法

#主键和唯一的对比

#外键

二 修改表时候添加约束

1.添加非空约束
alter table student modify column stuname varchar(20) not null;
alter table student modify column age int default 18
添加主键
1.列级别约束
alter table student modify column id int primary key;
2.表级别约束
alter table student add primary key(id);
#添加唯一键
1.列级约束
alter table student modify column seat int unique;
2.表级约束
alter table studet add unique(seat);
#5 添加外键
alter table student add constraint fk_stuinfo_major foreign key (majorid) references major(id);
三 修改表时删除约束
删除表非空约束
alter table stuinfo modify column stuname varchar(20) null;
2.删除表默认约束
alter table stuinfo modify column age int
3.删除主键
alter table stuinfo drop primary key;
4.删除唯一约束
alter table stuinfo drop index seat;
5.删除外键
alter table stuinfo drop foreign keyv majorid;
#标识列
/* 又称自增长列 含义:可以不用手动的插入值,系统提供默认的序列值
特点:
- 标识列必须和主键搭配么?不一定,但要求是一个key
2.一个表可以有几个标识列?至多一个!
3.标识列的类型?只能是数值型
4.标识列可以通过 set auto_increment_incremen=3;设置步长
可以通过 手动插入值,设置起始值*/

#二修改表时候\设置标识列
alter table tab_identity modify column id int primay key auto_increment
#三,修改表时删除标识列
alter table tab_identity modify column id int primay
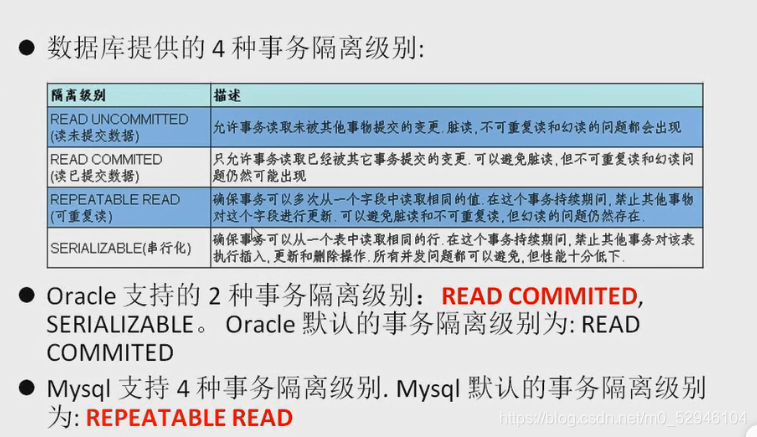
TCL(事务控制)
/*
Transaction Control language 事务控制语言
事务:
一个或者一组sql语句组成一个执行的单元,这个执行的单元要么全被执行要么全部执行.
案例:转账:
张san丰:1000
郭襄:1000
update 表set 张三丰的余额=500 where name=‘张三丰’
意外
update 表 set 郭襄的余额为=1500 where name=‘郭襄’
事务的创建
隐式事务:事务没有明显的e开启和结束的标记
比如 insert update delete语句
delete from 表 where id=1;
显示事务:事务具有冥想的开启和结束的标记
前提:必须先设置自动提交功能为禁用
set autocommit=0;//只针对当前事务有效
步奏1.开启事务
set autocommit=0;
start transaction;可选的
步奏二: 编写事务中的SQL语句(select insert update delet)
语句1.;
语句2;
…
步奏3:结束事务
commit:提交事务
rollback:回滚事务
savepoint 节点名,设置保存点//搭配rollback使用
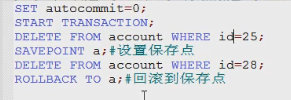
- #开启事务语句
update 表 set 张三丰的余额为500 where name=‘张三丰’
update 表 set 郭襄的余额为 =1500 where name=‘郭襄’
结束事务的语句;
>
*/



视图

#一创建视图
语法:
creat view 视图名
as
查询语句;
use myemployees;
#1.查询邮箱小红包含a 字符的员工名,部门名,和工种信息
- #创建
creat view myv1
as
select last_name,department_name,job_title
from employees e
join departments d on e.department_id=d.department_id
join jobs j on j.job_id=e.job_id;- 使用
select * from myv1 where last_name like ‘%a’;列子2
1.创建视图查看每个部门的平均工资
create view myv2
as
select avg(salary) ag,department_id
from employees
group by department_id;
2. 使用
slect * from myv2 join job_grades g
on myv2.ag between g.lowest_sal and g.highest_sal;
#二视图的修改
- 语法:create or replace view 视图名
as
查询条件
- 列子:
select * from myv3
create or replace view myv3
as
select avg(salary) ,job_id
from employees
group by job_id
- 方式二
语法:
aleter view 视图名
as
查询语句;
alter view myv3
as
select * from employees;
删除视图
drop view 视图名,视图名…;
查看视图
desc myv3;
show create view myv3;
视图的更新

create or replace view myv1
as
select last_name,email
from employees;select * from myv1;
select * from employees;
插入
insert into myv1 values(‘张飞’,‘zzz@qq.com’);修改
update myv1 set last_name =‘张无忌’ where last_name=‘张飞’;删除
delete from myv1 where last_name=‘张无忌’;更新
4.1 包含以下关键字的sql语句:分组函数.distinct,group by,having ,union,或者 union all
create or reoplace view myv1
as select
max(salary ) m,department_id
from employees
group by department_id;
4.2 更新
update myv1 set m=9000 where department_id=10;
#更新
update myv2 set name=‘lucy’;
#select 中包含子查询
create or replace view myv3
as
select(select max(salary)from employyes)最高工资
from department;
#更新
select * from myv3;
update myv3 set 最高工资=10000;4.4 join
create or replace view myv4
as
select last_anem,department_name
from employees e
join departments d
on e,department_id=d.department_id;
#更新
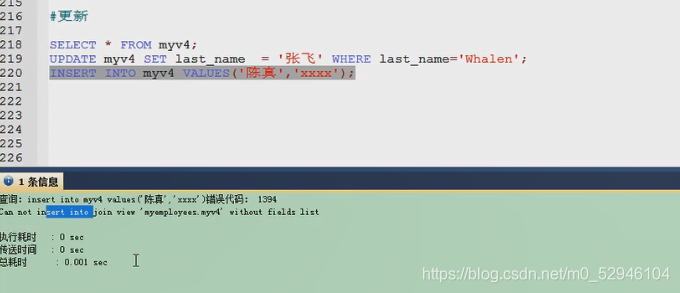
视图和表的区别

delete 和truncate在事务使用时的区别(truncate 不支持回滚)
#演示delete
set autocommit=0;
delete from account;
rollback;
#演示truncate
set autocommit=0;
start transaction;
truncate table account;
rollback;
变量
/系统变量:
全局变量
会话变量
自定义变量:
用户变量
局部变量
一、系统变量
说明:变量由系统提供,不是用户定义,属于服务器。
使用的语法:
1、查看所有 的系统变量
show GLOBAL|【session】 variables;
2.查看满足条件的部分系统变量
show global|【session】 variables like %char%;
3.查看指定的某个系统变量的值
select @@global|【session】.系统变量名
4.为某个系统变量赋值
set global|【session】 系统变量名=值
方式二:
set @@glaobal|【session】.系统变量名=值;
注意:如果是全局级别,则需要加global,如果是会话级别,则需要加session,如果不写,则默认session。
二全局变量
作用域:服务器每次启动将为所有的全局变量赋初始值,针对于所有的会话(l连接)有效,但 不能跨重启
#1.查看部分的全局变量
show Global variables like' %char%'
#2.查看指定的全局变量的值
select @@global.autocommit;
select @@tx_isolation
#3 为某个指定的全局变量赋值
set @@global.autocommit=0;
三 会话变量
作用域仅仅针对当前会话有效
#1 查看所有的会话变量
show session variables ;
2.查看部分的会话变量
show session variables like '%char%;
'
3.查看指定的某个会话变量
select @@tx_isolation;
select @@session.tx_isolation;
4.为某个会话变量赋值
方式一:
set @@seeion.tx_isolation="read-uncommitted";
方式二:
set session tx_issolation="read-committed";
## 二自定义变量
说明:
1.用户变量
作用域:针对于当前连接(会话)生效
位置:begin end里面.也可以放在外面
使用:
1声明并赋值
set @变量名=值 或set@变量名:=值;或select@变量名:=值;
2.更新值
方式一:
set @变量名=值;
或set @变量名:=值;
或select @变量名:=值;
方式二:
select xx into @变量名 from 表
- 局部变量


-

-
存储过程和函数
5. 存储过程和函数:类似于 java的方法 6. 好处:提高代码的重用性 7. 8. 存储过程 9. 含义:一组预先编译好的生气了\语句集合,理解成批处理语句 10. 简化操作: 11. 减少了编译次数并且减少了和数据库的连接次数.提过了效率 12. 13. 一创建语法: 14. create procedure 存储过程名(参数列表) 15. begin 16. 存储过程体(一组合法有效的sql语句) 17. end 18. 注意: 19. 1.参数列表包含三个部分 20. 参数模式 参数名 参数类型 21. 举例: in stuname varchar(20); 22. 23. 参数模式: 24. in:该参数可以作为输入,也就是说该参数需要传入值 25. out:该参数可以作为返回值, 26. inout:该参数又可以作为输入,又可以作为输出.也就是说,该参数急需要传入值,又可以返回值. 27. 28. 2. 如果存储过程体仅仅只有一句话,begin,end 可以省略.存储过程体中的每条sql语句的结尾要求必须加分号,存储过程的结尾可以使用delimiter重新设置 29. 语法: 30. delimiter 结束标记 31. 32. delimiter$ 33. 34. 35.
二 调用语法
call 存储过程名(实参列表);
1.空参列表
案例1.插入到admin表中的 五条记录.
select * from admin;
delimiter $
create procedure myp1()
begin
insert into admin(username ,password)
values('john1','00000'),('lily','00000'),('rose','0000'), ('jack','00000'),('tom','0000');
end $
#调用
call myp1()$;
#2. 创建一个带in模式参数的存储过程
# 案例1:创建存储过程实现 根据女神名,查询对应的男神信息
create procedure myp2 (in beautyName varchar(20))
begin
select bo.*
from boys bo
right join beauty b on bo.id=b.boyfriend_id
where b.name=beautyName;
end$
#调用
call myp2('小昭')$

#3.创建带out模式的存储过程
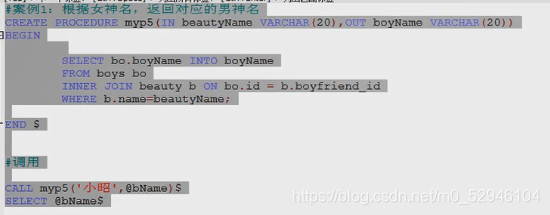
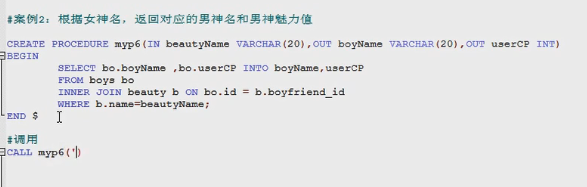

#创建into模式参数的存储过程

#例子

二 删除存储过程
#语法:drop procedure 存储过程名
Drop procedure p1;
Drop procedure p2,p3;#X 错误
三 查看存储过程
show create procedure myp2;
例句:


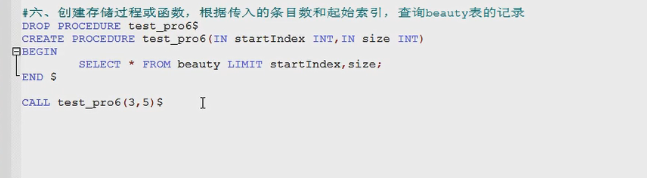
函数
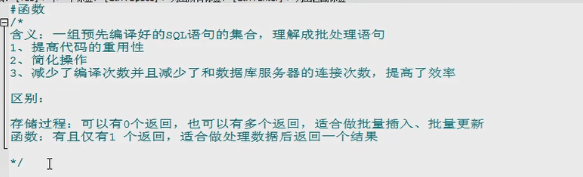
#创建语法
create function 函数名(参数列表) returns 返回类型
begin
函数体
end
注意:
1.参数列表 包含两个部分
参数名 参数类型
2.函数体:肯定会有rerurn语句,如果没有会报错
如果return语句没有放在函数体的最后也不会报错,但不建议
return值:
3.函数体中仅有一句话,则可以省略 begin end
4.使用 delimiter语句设置结束标记
二 调用语法
select 函数名(参数列表);
|------------------------案例演示--------------|
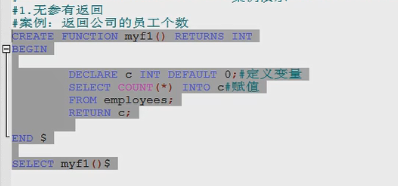

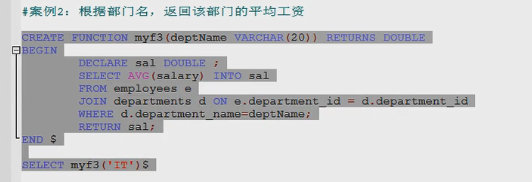
三 查看函数
show create function myf3;
四 删除函数
drop function myf3;
案例

流程控制语句



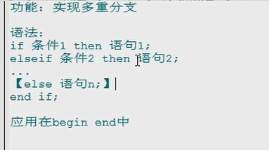
特点:
1. 可以作为表达式,镶嵌在其他语句中使用,可以放在任何地方,begin end 中或begin end的外面 可以作为独立的语句使用,只能放在begin end中
2. 如果where 的值满足或者条件成立,则执行对应的THEN后面的语句.并且结束case,如果不满足,则执行else语句或值.
3. else 可以省略,如果else省略了,并且所有when条件都不满足,则返回null

案例:

if结构
案例:

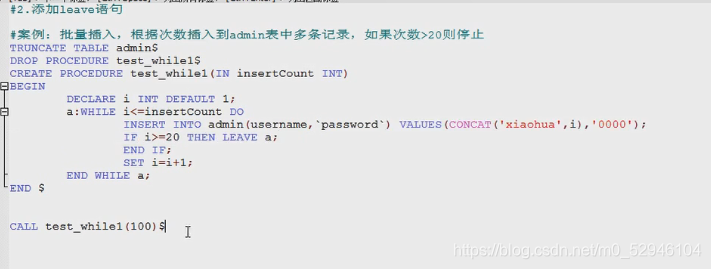
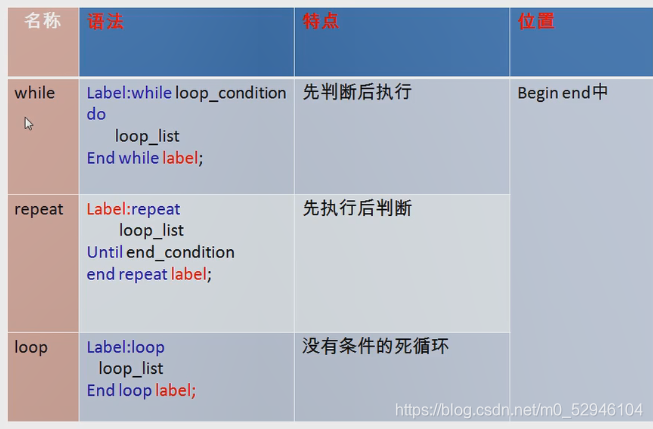
二 循环
1.
2.

案例:




4.















 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









