







1、MapReduce跑的慢的原因
-
检查计算机性能
CPU
内存
磁盘
网络 -
I/O操作优化
数据倾斜
Map运行时间太长,导致Reduce等待过久
小文件过多
2、MapReduce常用调优参数
2.1 Map端
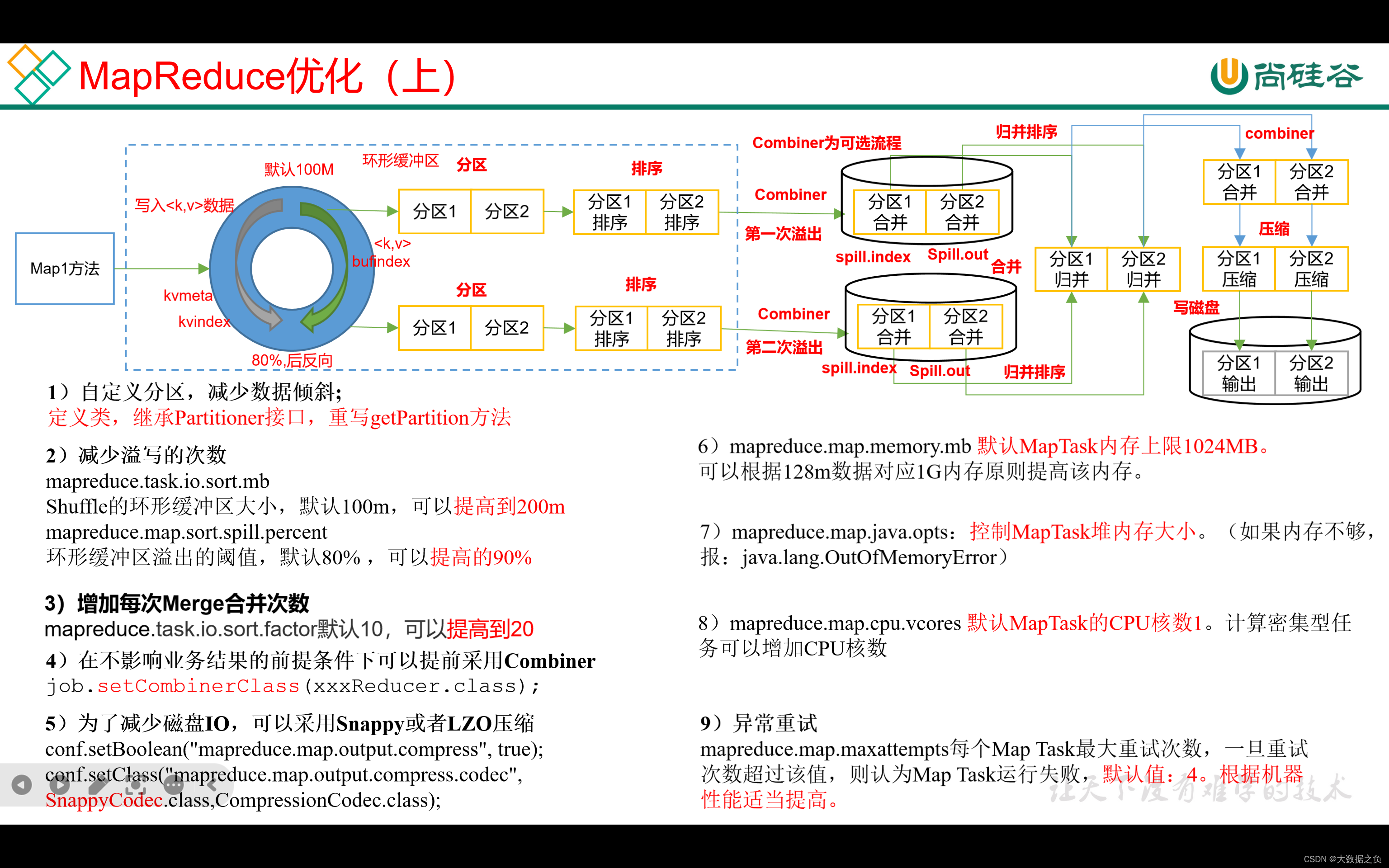
1. 自定义分区,减少数据倾斜
自定义分区时,使用随机数拼上key,就会把Map端的数据打散到不同的Reducer中去
2. 减少溢写次数
a、调大环形缓冲区大小
mapreduce.task.io.sort.mb
默认100M
可以提高到200M
b、调大环形缓冲区溢写阈值
mapreduce.map.sort.spill.percent
默认80%
可以提高到90%
3. 增加merge一次合并文件个数
mapreduce.task.io.sort.factor
内存充足情况下可以提高到20
4. 在不影响业务条件的情况下,提取预聚合
job.setCombinerClass(xxxReducer.class)
5. 减少磁盘IO,采取Snappy和LZO压缩
conf.setBoolean(“mapreduce.map.output.compress”,true);
conf.setClass(“mapreduce.map.output.compress.codec”,SnappyCodec.class,ComparessionCodec.class);
6. 调大MapTask内存
默认情况下,MapTask内存上限是1G,1G处理128M的数据绰绰有余的,但如果MapTask处理的是不可切分的压缩数据,则需要按照1G内存处理128M数据的比值做相应调整
mapreduce.map.memory.mb
7. 调大MapTask内存后,同时要调整MapTask堆内存大小
将MapTask堆内存大小调整成和MapTask内存一致,否则会OOM
mapreduce.map.java.opts
8. 如果是计算密集型任务,需要增大CPU核数
默认1核,如果是涉及到复杂的加减乘除运算,需要适当增加CPU核数
mapreduce.map.cpu.vcores
9. 异常重试
默认4次,如果服务器较差,跑任务经常失败,可以适当调大重试次数
mapreduce.map.maxattempts
2.2 Reduce端
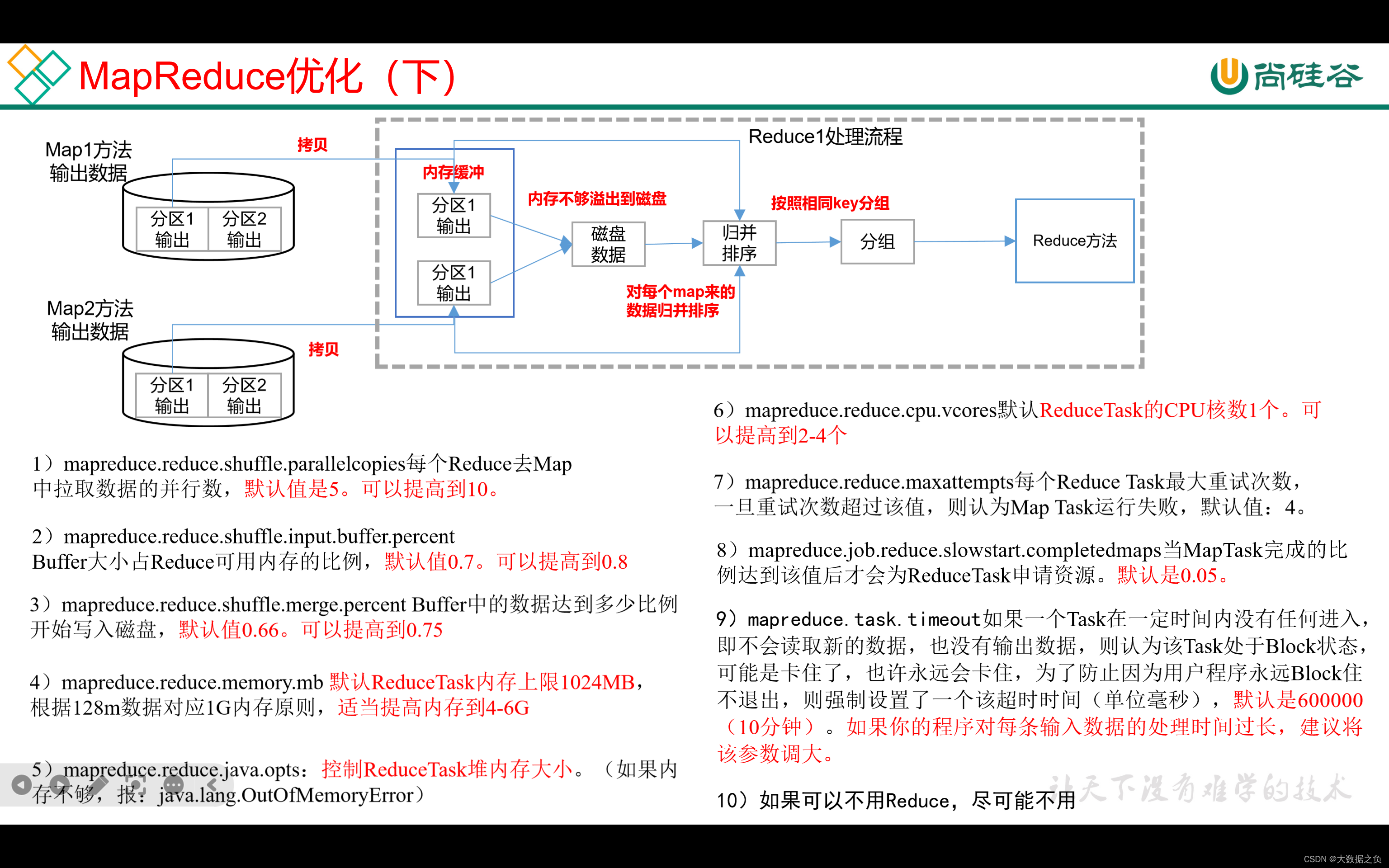
1、每个Reduce端拉取数据的并行度
默认是5,可以提高到10
mapreduce.reduce.shuffle.parallelcopies
2、内存使用量占ReduceTask总内存的百分比
拉取后的数据首先会放在内存中,默认内存大小占ReduceTask总内存的70%,可以适当调大到80%
mapreduce.reduce.shuffle.input.buffer.percent
3、内存达到使用量比的比例达到多少时才开始写入磁盘
默认是66%开始归并排序、写入磁盘,可以提高到75%
mapreduce.reduce.shuffle.merge.percent
4、调大ReduceTask内存
默认情况下,ReduceTask内存上限是1G,1G处理128M的数据绰绰有余的,需要按照1G内存处理128M数据的比值做相应调整,可以调到4-6g
mapreduce.reduce.memory.mb
5、调大ReduceTask内存后,同时要调整ReduceTask堆内存大小
将ReduceTask堆内存大小调整成和ReduceTask内存一致,否则会OOM
mapreduce.reduce.java.opts
6、如果是计算密集型任务,需要增大CPU核数
默认1核,如果是涉及到复杂的加减乘除运算,需要适当增加CPU核数
mapreduce.reduce.cpu.vcores
7、异常重试
默认4次,如果服务器较差,跑任务经常失败,可以适当调大重试次数
mapreduce.reduce.maxattempts
8、MapTask完成占比为多少的时候,开始为ReduceTask申请资源
默认是MapTask完成5%的时候开始跑
mapreduce.job.reduce.slowstart.completedmaps
9、MapTask或者ReduceTask长时间没有数据到来则任务block卡住了(少用)
默认是10分钟,如果服务器比较差可以加大该值
mapreduce.task.timeout
10、可以不用Reduce,就尽可能不用
3、MapReduce数据倾斜问题
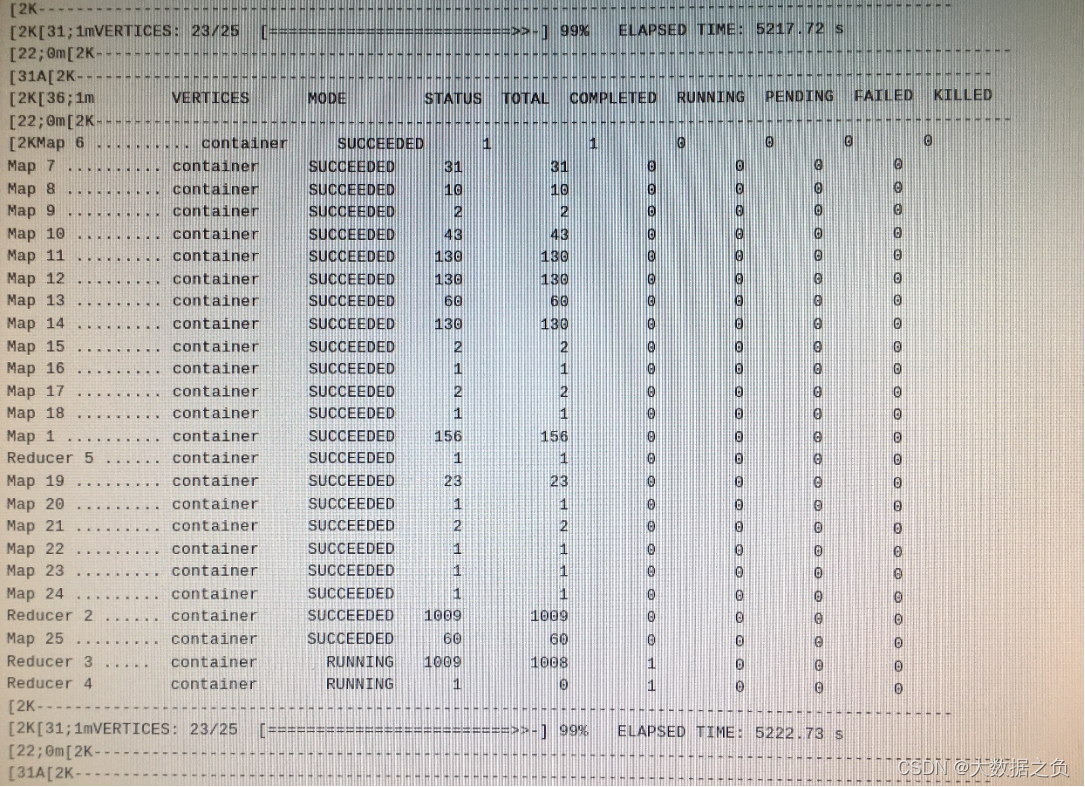
3.1 现象
在跑MR任务时,大部分任务已经完成,只剩下一两个Reduce任务还在跑,等待时间过长
3.2 减少数据倾斜的方法
1. 检查是否有空值存在
直接删掉,很少使用,因为用于group by的字段一般都是有特定意义,不能为空
保留空值,增加随机数打散到不同分区,之后在第二次聚合的时候删除随机数
2. 能在Map阶段处理的任务,尽量在Map阶段处理
不影响业务的情况下提前预聚合
使用MapJoin
3. 设置多个Reduce个数
缓解数据倾斜压力,不一定可以彻底解决问题
















 2961
2961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











