







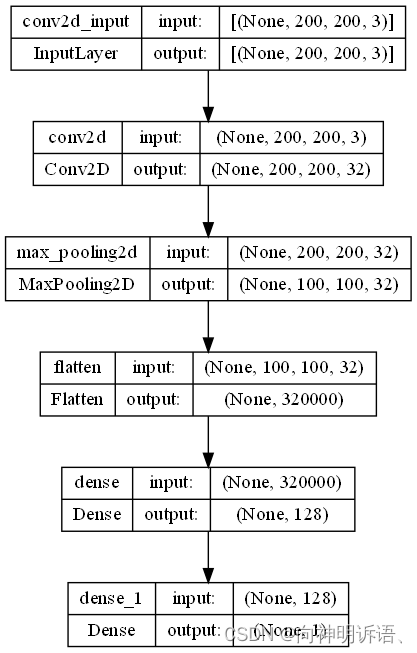
创建cnn模型
def define_cnn_model():
# 使用序列模型
model = Sequential()
# 卷积层
model.add(Conv2D(32, (3, 3), activation="relu",
kernel_initializer='he_uniform',
padding="same",
input_shape=(200, 200, 3)))
'''卷积核数量,卷积核维度,激活函数,padding,图片像素200x200'''
# 最大池化层
model.add(MaxPooling2D((2, 2)))
# Flatten 层
model.add(Flatten())
# 全连接层
model.add(Dense(128, activation="relu", kernel_initializer='he_uniform'))
model.add(Dense(1, activation="sigmoid")) # 输出层0,1,sigmoid模型实现输出值0~1之间,分别代表猫狗
# 编译模型
opt = SGD(learning_rate=0.001, momentum=0.9) # 优化器,随机梯度下降,为模型找到最佳的参数
model.compile(optimizer=opt,
loss='binary_crossentropy',
metrics=['accuracy'])
return model
这是一个函数,返回一个CNN的Keras模型。该模型使用卷积层、最大池化层、全连接层和一个sigmoid输出层来预测图像是猫还是狗。具体来说,该模型有以下组件:
- 输入层:该模型的输入形状为(200,200,3),即高为200、宽为200、通道数为3(对应RGB三个颜色通道)的图像。
- 卷积层:使用32个大小为(3,3)的滤波器进行卷积操作,使用ReLU激活函数,保证了输出值都大于等于0。
- 池化层:使用大小为(2,2)的窗口对卷积输出进行最大化池化,从而减少模型中的参数数量,并使模型更加健壮。
- Flatten层:将池化层输出的2D张量展平成1D向量,以便进行全连接操作。
- 全连接层:包含128个神经元,并使用ReLU激活函数。为防止过拟合,使用了dropout技术,在全连接层输出之前随机删掉一些神经元。
- 输出层:是一个大小为1、使用sigmoid激活函数的密集层,用于预测照片中是否是狗。
最后,该模型使用二分类交叉熵作为损失函数,使用SGD优化器,训练结束后,使用accuracy作为模型的指标来评估最终的性能。
训练模型
def train_cnn_model():
# 实例化模型
model = define_cnn_model()
# 创建图片生成器,产生图片并输入
datagen = ImageDataGenerator(rescale=1.0 / 225.0)
train_it = datagen.flow_from_directory(
'E:\\ma1ogo3ushu4ju4ji2\\dogs_cats\\data\\train',
class_mode='binary',
batch_size=64, # 一次产生并输入64张图片
target_size=(200, 200) # 缩放图片为200x200,和输入图片大小相同
)
# 训练模型
model.fit_generator(train_it,
steps_per_epoch=len(train_it),
epochs=20,
verbose=1)
# 把模型保存到文件夹
model.save("E:\\Data_clean\\basic_cnn_result.h5")
此代码为使用CNN模型训练猫狗图像分类器的过程。
-
首先调用define_cnn_model()函数实例化一个CNN模型。
-
接着用ImageDataGenerator创建图片生成器datagen,并指定图像预处理参数rescale=1.0/225.0。
-
用flow_from_directory方法指定图片目录、batch_size、目标大小等参数,让生成器逐批次产生和输入图片,其中类别由’binary’指定为二分类。
-
使用fit_generator方法对模型进行训练,其中指定了steps_per_epoch、epochs、verbose等参数。
-
最后,使用save方法把训练好的模型保存到指定路径下的h5文件格式中。
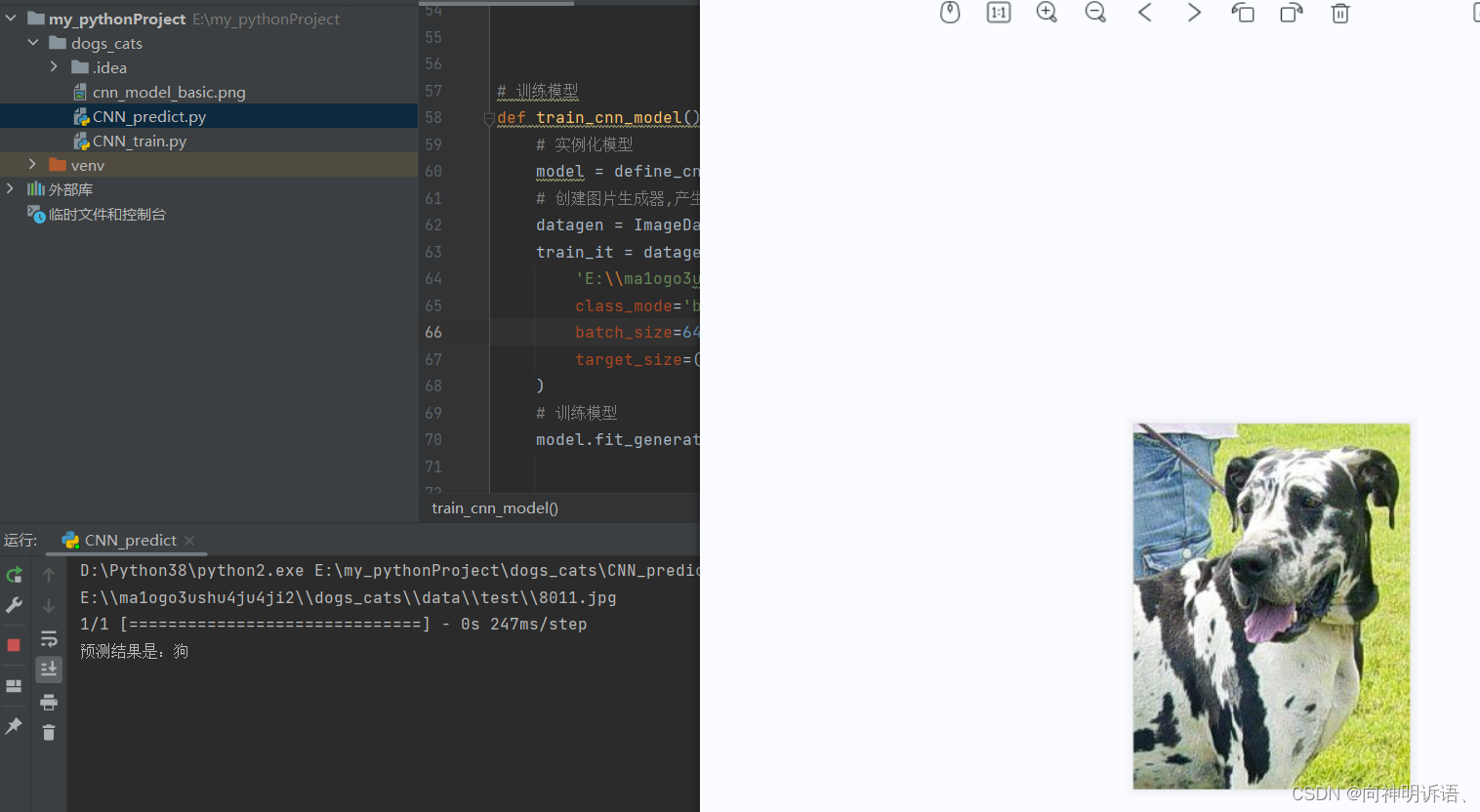
这是我运行后训练处的模型
定义函数读取测试文件夹中的照片
def read_random_image():
folder = r'E:\\ma1ogo3ushu4ju4ji2\\dogs_cats\\data\\test\\'
file_path = folder + random.choice(os.listdir(folder))
print(file_path)
pil_im = Image.open(file_path, 'r')
return pil_im
这个就是定义一个函数随机取到文件夹中的图片进行测试
对一个使用模型对读取出的图片进行预测
def get_predict(pil_im, model):
# 对图片进行缩放
pil_im = pil_im.resize((200, 200))
# 将格式转换为 numpy array 格式
array_im = np.asarray(pil_im)
array_im = np.expand_dims(array_im, axis=0)
# 对图片进行预测
result = model.predict(array_im)
if result[0][0] > 0.5:
print("预测结果是:狗")
else:
print("预测结果是:猫")
下面是完整代码+数据集

只需要把这三个文件夹放在E盘的根目录下(路径都写好的所以放在E盘根目录下,如果你想放别的地儿你就改改) 然后用Pycharm运行CNN_predict.py文件就可以,如果想要自己训练可以先执行CNN_train.py文件
下面是网盘链接需要可以自取
链接:https://pan.baidu.com/s/13-PBIvOs1GXpSnf3snQtzg?pwd=mo1s
提取码:mo1s
运行结果
有可能识别会有误,它主要是跟模型和数据集训练的大小有关
运行中可能遇到的bug
pydot和graphviz的包下载问题
解决办法
pip install pydot
然后第二个包要去官网下载
而且要下载32bit的不能64bit亲身试验
https://graphviz.gitlab.io/download/ 官网
下载之后配置一下
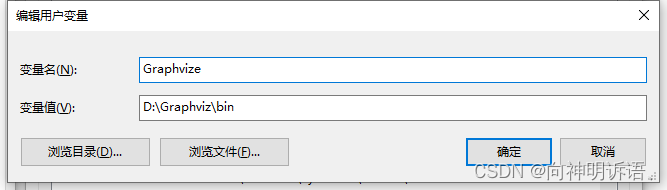
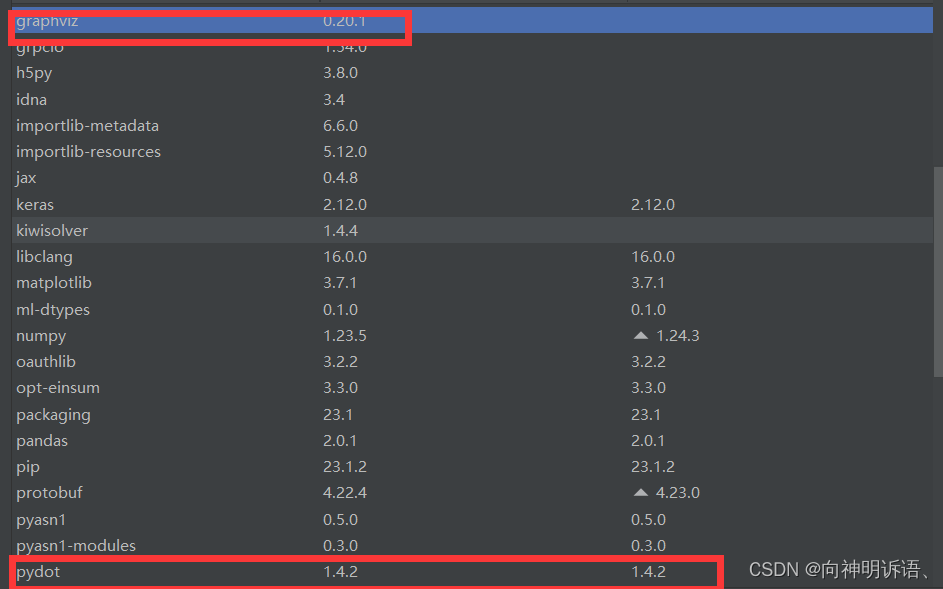
有这两个包然后就可以了














 2849
2849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









