







目录
一、Bitmaps
1.简介
现代计算机用二进制(位)作为信息的基础单位,1个字节等于8位,
例如“abc"字符串是由3个字节组成,但实际在计算机存储时将其用二进制表示,“abc”分别对应的 ASCII 码分别是 97、98、99,对应的二进制分别是01100001、01100010和01100011,如下图·

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis提供了 Bitmaps这个“数据类型”可以实现对位的操作∶
( 1 )Bitmaps本身不是一种数据类型,实际上它就是字符串( key-value ) ,
但是它可以对字符串的位进行操作。
(2) Bitmaps单独提供了一套命令,所以在 Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1.数组的下标在Bitmaps叫做位偏移量
 2.命令
2.命令
💧sbit
(1)格式
setbit <key><offset><value>设置Bitmaps中某个偏移量的值(0或1)
*offset:偏移量从0开始
(2)实例
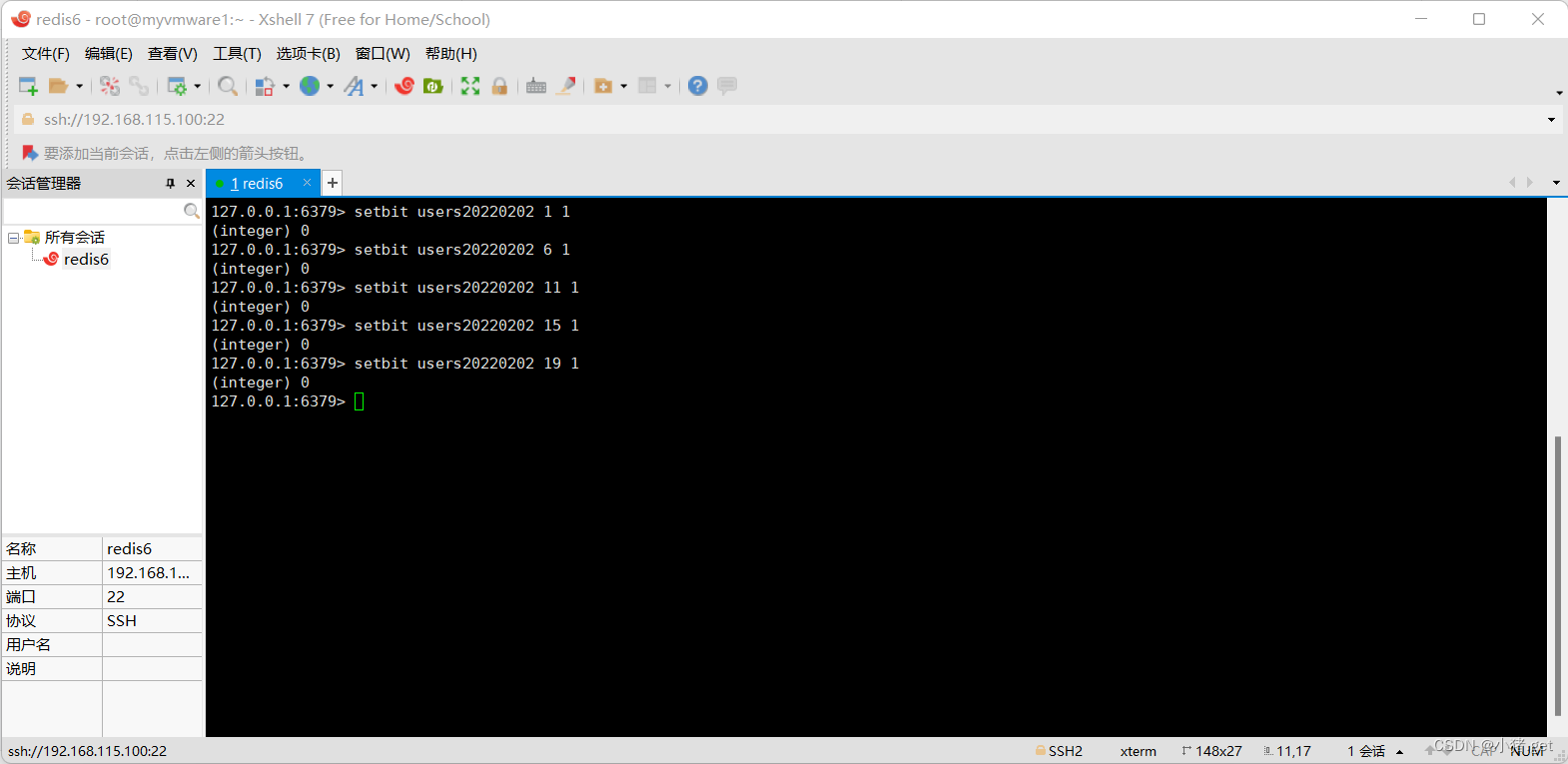
每个独立用户是否访问过网站存放在 Bitmaps 中,将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户的 Id。
设置键的第offset个位的值(从0算起),假设现在有20个用户,userid=1 ,6,11,15,19的用户对网站进行了访问,那么当前 Bitmaps初始化结果如图

 很多应用的用户id以一个指定数字(例如10000)开头,直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次做setbit 操作时将用户id减去这个指定数字。
很多应用的用户id以一个指定数字(例如10000)开头,直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次做setbit 操作时将用户id减去这个指定数字。
在第一次初始化 Bitmaps 时,假如偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成 Redis的阻塞。
💧getbit
(1)格式
getbit <key><offset>
获取Bitmaps中某个偏移量的值(获取键的第offset位的值,从0开始算)
*offset:偏移量从0开始
(2)实例
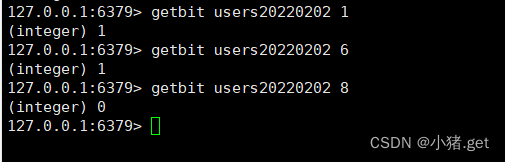
💧bitcount
统计字符串被设置为1的 bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start或end参数,可以让计数只在特定的位上进行。
(1)格式
bitcount <key>[start end]
统计字符串从start字节到end字节比特值为1的数量
start和end参数的设置,都可以使用负数值:比如-1表示最后一个位,而-2表示倒数第二个位,start、end是指bit组的字节的下标数,二者皆包含。
(2)实例

💧bitop
(1)格式
bitop and(or/not/xor) <destkey> [key...]
bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中
(2)实例
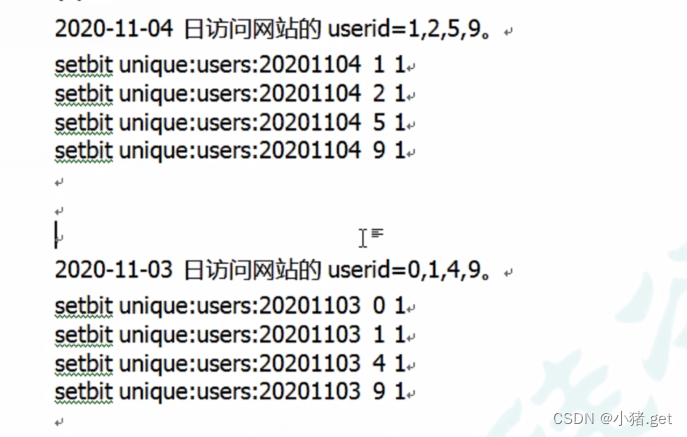
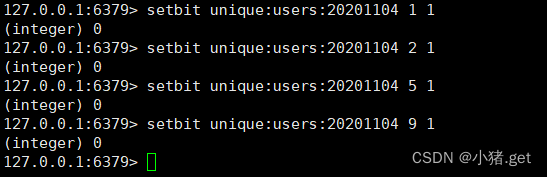
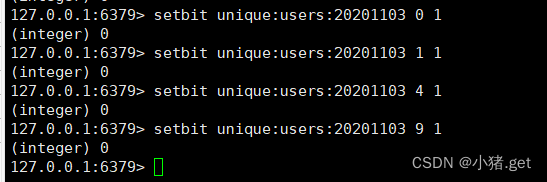
计算出两天都访问过网站的用户数量
bitop and unique:users:and:20201104_03 unique:users:20201103 unique:users:20221104
 ⚪Bitmaps与set'的对比
⚪Bitmaps与set'的对比
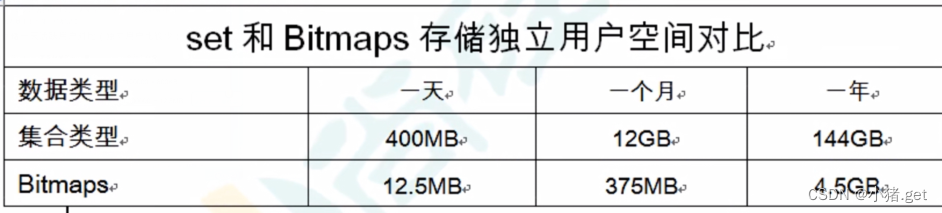
假设网站有1亿用户,每天独立访问的用户有5千万,如果每天用集合类型和 Bitmaps分别存储活跃用户可以得到表:
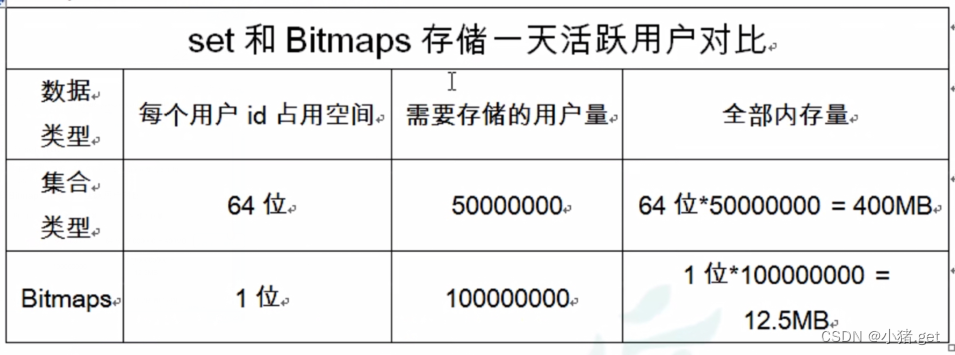 很明显,这种情况下使用Bitmaps能节省很多空间,尤其是随着时间的推移节省的内存还是很可观的
很明显,这种情况下使用Bitmaps能节省很多空间,尤其是随着时间的推移节省的内存还是很可观的
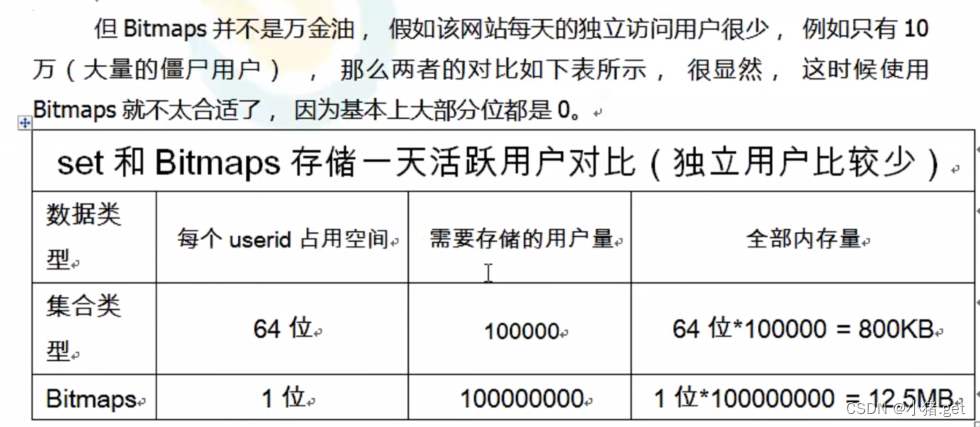
二、HyperLogLog
1.介绍
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV( PageView页面访问量),可以使用Redis 的incr、incrby 轻松实现。
但像UV ( UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案
(1)数据存储在MySQL表中,使用distinct count 计算不重复个数·(2)使用Redis提供的 hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。·
能否能够降低一定的精度来平衡存储空间?
Redis推出了HyperLogLog
Redis HyperLogLog是用来做基数统计的算法,HyperLogLog 的优点是,在输Redis HyperLogLog是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在Redis 里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog不能像集合那样,返回输入的各个元素。
⚪什么是基数?
比如数据集{1,3,5,7,5,7,8},那么这个数据集的基数集为{1,3,5 ,7,8},基数(不重复元素)为5。基数估计就是在误差可接受的范围内,快速计算基数。·
2.命令
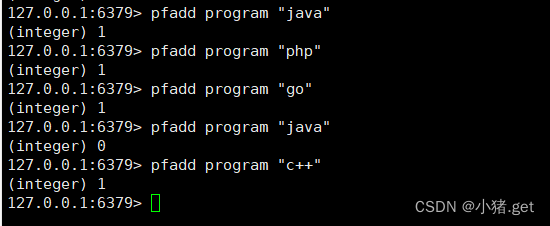
💧pfadd
(1)格式
pfadd <key><element>[element...]
添加指定元素到HyperLogLog中,成功则返回1,不成功返回0
(2)实例
💧pfcount
(1)格式
pfcount <key> [key...]
计算HLL的近似基数,可以计算出多个HLL。比如用HLL存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可
(2)实例

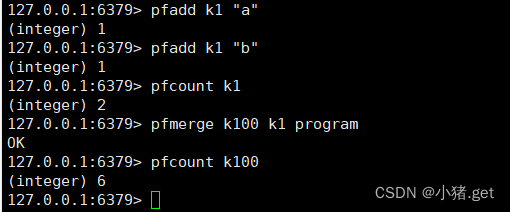
💧pfmerge
(1)格式
pfmerge <destkey><sourcekey> [sourcekey...]
将一个或多个HLL合并后的结果存储到另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算获得
(2)实例
三、Geospatial
1.简介
Redis 3.2中增加了对 GEO类型的支持。GEO,Geographic,地理信息的缩写。
该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度 Hash等常见操作。
2.命令
💧getadd
getadd <key><longitude><latitude><member>[longitude latitude member...]
添加地理位置(经度、纬度、名称)
- 两极无法直接添加,一般会下载城市数据,直接通过Java程序一次性导入
- 有效的经度从-180度到180度
- 有效的纬度从-85.05112878度到85.05112878度
- 当坐标位置超出指定范围时,该命令将会返回一个错误
- 已经添加的数据,无法再次添加

💧geopos
(1)格式
geopos <key><member> [member...]
获得指定地区的坐标值
(2)实例

💧godist
godist <key><member1><member2> [m|km|ft|mi]
获取两个位置之间的直线距离
- m表示单位为米(默认值)
- km代表千米
- mi代表英里
- ft代表英尺
💧georadius
georadius <key><longitude><latitude> radius m|km|ft|mi
一给定的维度为中心,找出某一半径内的元素
















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











