







1.


易错点在于数组初始化的方式,上面的有'\0',下面的没有,C语言语法规定字符串自动追加'\0'.
2.

一维数组能如此初始化?显然不行
所以下面这题答案自然出来了,选B:

3.

答案:B
解释:全局可以在任何一个地方调用,很难保证数据的准确性和安全性
4.

函数不可以嵌套定义,但是可以嵌套声明(一般声明在全局里)
5.

答案:C
无限递归?内存有限,递归次数多了就栈溢出了
6.
递归实现my_strlen
注意return的要先++,不然死递归了.建议写成 return(s+1)
如果写成return(++s),他就改变了该层递归的s,如果return语句不在最后一行会导致一些意料之外的bug
所以建议写成return(s+1)

7.

printf的返回值是打印字符的个数,注意 \n 也算进去了(转义字符也是字符)
所以解题时另起一行进行换行操作.
拓展:printf("%d",printf("Hello world"));
结果是什么?
12?

这里说明了printf是从右往左运行
8.

少了头文件所以报错了吗?问题在语法错误
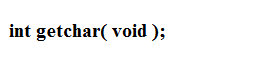
正确写法:

9.

知识点:printf("%0xd",a);
x表示域宽 %0xd就表示位数小于域宽 就补0
比如:

10.


上述代码有问题吗?
要求输出是整数所以要求用%d 啊
我都这么说了肯定有问题啊....
那是不是我把输入的a定义为double型导致的错误 ?
显然不是...(我定义double因为是要进行浮点数的运算,不过定义int自然也可以,运算时候自然出现精度提升)
问题在于打印的格式:%d
浮点数和整型的存储方式不同,这也是%f和%d输出时的差异所在了
经过运算后此时a*3.156e7是浮点型
%f以浮点数的形式打印double或者float类型当然没问题
而%d以整型的方式去读取一个浮点型,自然得到的结果会很奇怪
浮点型和整型的存储【C语言】:手把手教你C语言‘数据的存储‘[doge]_你算哪一个bug?的博客-CSDN博客
这个也是我写的,花了点心思,看起来可能很累,但如果能看下来肯定会有收获的
关于精度提升与整型提升,传送门:C语言中的整型提升与混合类型数据的运算 - HugoJiang - 博客园

个人理解:两个操作数,往精度高范围大的那个类型转换进行运算,运算完毕后根据打印的格式或者是赋值变量的格式进行转换
这题ac的代码;

11.


问题在哪?
当乘法表达式或者除法表达式特别长时需要特别注意运算顺序
正确的 代码:

12.

这里没说多少组数据,所以可以利用cin返回值的特性
EOF是文件结束的标志
注意:大多数情况下其返回值为cin本身(非0值),只有当遇到EOF输入时,返回值为0。
还有一种写法 while(~scanf("%d",&a)) getchar();
13.
要求 根据成绩高低排名,排名后同时打印出成绩主人的名字和其成绩
C++:重载
C:自己写一个函数
用纯C写这个函数时,遇到了一个问题:如何交换两个人的名字(当然for循环一个字符一个字符交换当然可以,但是时间复杂度有点高)
临机一动,不如直接用strcpy这个函数,也方便的多,定义一个临时数组tmp
具体代码如下:
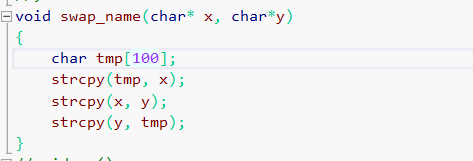
题解代码:
//我是C++的头文件
int n;
struct student
{
char name[100];
int grade;
};
student s[105];
void swap_gra(int*x, int*y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void swap_name(char* x, char*y)
{
char tmp[100];
strcpy(tmp, x);
strcpy(x, y);
strcpy(y, tmp);
}
void pr()
{
for (int i = 1; i <= n; i++)
{
printf("%s %d\n", s[i].name, s[i].grade);
}
}
int main()
{
cin >> n;
for (int i = 1; i <= n; i++)
{
scanf("%s%d", &s[i].name, &s[i].grade);
}
printf("\n");
for (int i = 1; i <= n;i++)
for (int j = 1; j <n-i+1 ; j++)
{
if (s[j].grade>s[j + 1].grade)
{
swap_gra(&s[j].grade, &s[j + 1].grade);
swap_name(s[j].name, s[j + 1].name);
}
}
pr();
return 0;
}14.

指针类型不同,操作的字节数不同,从内存的角度入手
初始化数组时arr里的状态;

操作完毕后:

原因:short型指针一次只能操作两个字节,操作四次一共八个字节,一个整型四个字节,所以只能更改前面两个数字
四次操作如下图所示:(前面时低地址,后面是高地址)

15.

答案:C
大小端存储的问题
以vs的小端存储为例(高字节内容存高地址,低字节内容存低地址)
高位 低位
a(十六进制)::11 22 33 44
存入内存:: 44 33 22 11
低地址 高地址
题目中pc指针就是指向44,又是char型指针操作一个字节,自然吧44改为00
打印是从低位打印到高位;也就是 11 22 33 00
15.

答案:A
释放后的指针依然指向原地址,free 的意义在于告诉系统目标地址可以被回收。
所以肯定不是置为NULL.
16.

c溢出了 自然是44

为什么a+b是三百?
printf传入参数时不是根据 是什么类型 然后 传入 该类型的字节,说的有点绕举个例子
简单点,说话的方式简单点
传入参数是char类型时,传入的是4个字节,而不是char类型的1字节(printf默认时4字节)
而double float longlong为八字节,读入float时会自动转为double
%lld %llf %f %llx读取的时候也是8字节,其余读取4字节
再换种讲法,整型提升,a+b运算进行了整型提升,而c的结果是经过整型提升后只得到了后面八位(发生了截断).
关于整型提升的规则(不清楚的百度或者谷歌),
17.

int a,a是十六进制,
0x八位数字
为什么?
一个字节是八位,四位二进制 是 一个十六进制,所以一个字节可以存两个十六进制数字
所以一个int 类型可以存八个十六进制数
所以0x1234==0x00001234
注:0x1234 != 0x01020304
大端存储:低位存高地址,高位存低地址,
如下图所示

char指针操作一个字节,也就是00,所以选A
--------------------------------------
走之前有一点启发留个赞再走呗!九百多的访问十个赞不到就离谱啊-----2021/5/27
感谢阅读!
----
















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











