






省力,但不多,需要安装python模块bs4和工具wkhtmltopdf
1. 在cmd运行以下命令安装bs4
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple2. 安装工具wkhtmltopdf,并将安装目录下的bin目录添加到环境变量
下载地址:https://wkhtmltopdf.org/downloads.html
文件管理器-此电脑右键属性-高级系统设置-环境变量-系统变量-变量path
3. 右键浏览器标签栏,将打开的网页全部保存到收藏夹然后导出
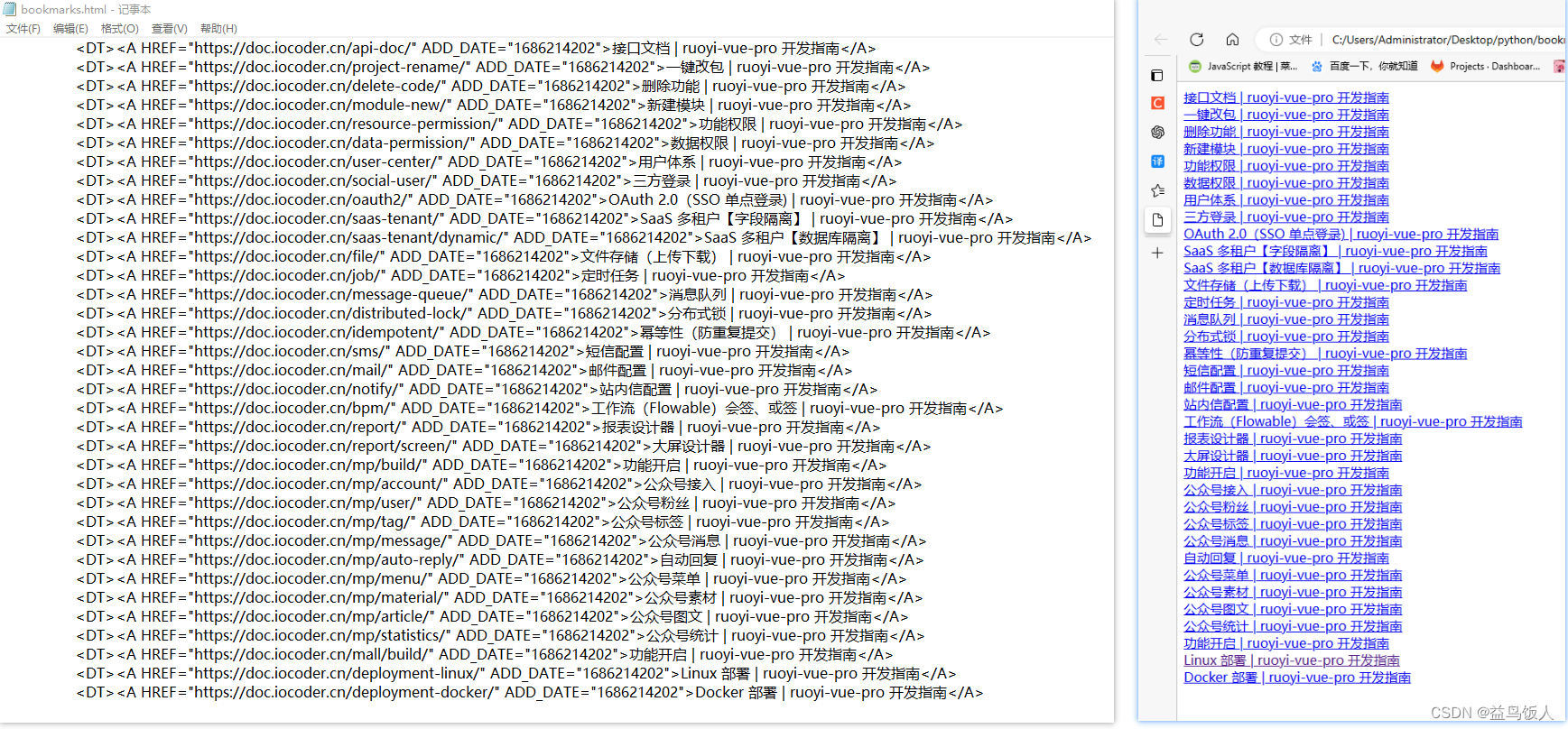
4. 编辑导出的html文件,只保留需要的链接
5. 将html文件和pdf.py放到同一个目录下,并在当前目录新建文件夹命名为pdf,注意更换代码中的html文件名(bookmarks.html)
# pdf.py
from bs4 import BeautifulSoup
import re
import subprocess
# 将html文件中链接的url和标题提取出来分别保存在urls.txt和titles.txt文件中,注意更换html文件名(bookmarks.html)
# 读取 HTML 文件内容
with open('bookmarks.html', 'r', encoding='utf-8') as f:
html_str = f.read()
# 解析 HTML 字符串
soup = BeautifulSoup(html_str, 'html.parser')
# 获取所有的链接列表
links = soup.find_all('a')
# 将链接 URL 和标题保存到文件中
with open('urls.txt', 'w', encoding='utf-8') as f1, open('titles.txt', 'w', encoding='utf-8') as f2:
for link in links:
url = link.get('href')
title = link.string
# 写入链接 URL 和标题到文件中
f1.write(url + '\n')
f2.write(title + '\n')
# 批量更改文件名——在 Windows 系统中文件名不能有以下字符:< (小于号)> (大于号): (冒号)" (双引号)/ (正斜杠)\ (反斜杠)| (竖线)? (问号)* (星号),并且后续批量执行命令时文件名中不能有空格
# 打开文件
with open('titles.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
# 转换文件名
for i in range(len(lines)):
# 去除行尾换行符
line = lines[i].rstrip('\n')
# 替换非法字符
line = re.sub(r"[<>:\"/\\|?*\s]+", "_", line)
# 确保文件名不为空
if not line:
continue
# 保存到同一文件
lines[i] = line + '\n'
with open('titles.txt', 'w', encoding='utf-8') as f:
f.writelines(lines)
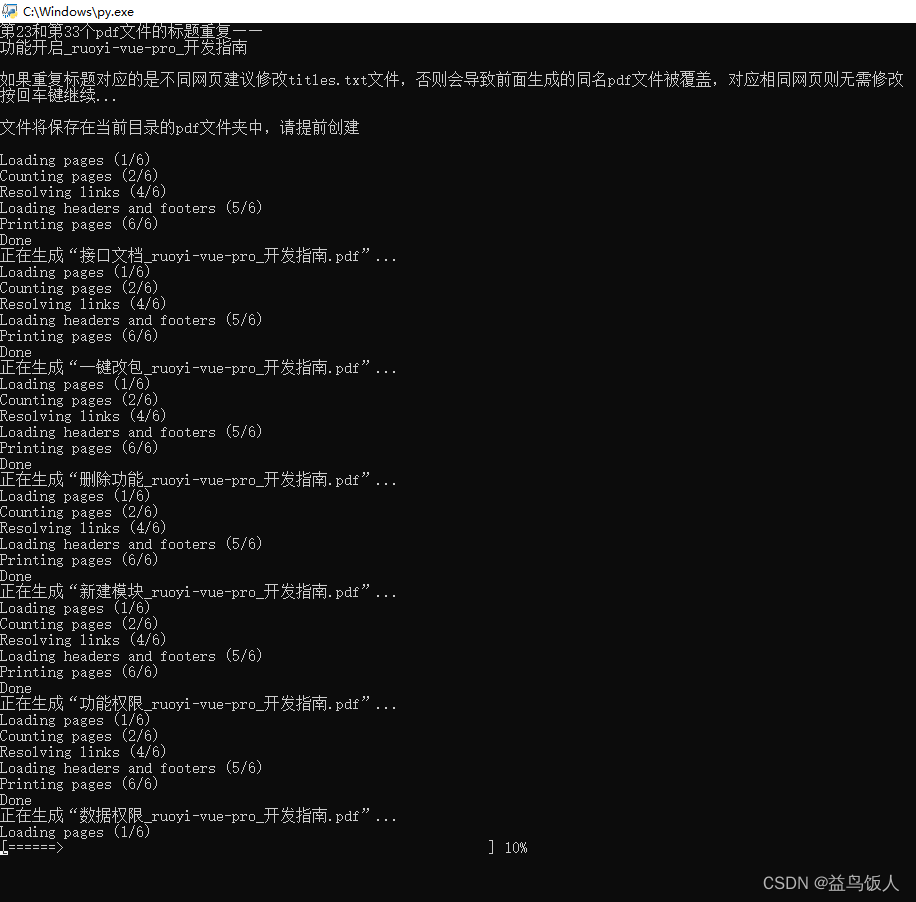
# 检查是否有重复标题——如果重复标题对应的是同一网页可以跳过重复标题检查,否则前面生成的pdf会被后面生成的同名pdf覆盖
with open('titles.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for i in range(len(lines)):
for j in range(i+1, len(lines)):
if lines[i] == lines[j]:
print(f'第{i+1}和第{j+1}个pdf文件的标题重复——')
print(lines[i])
print("如果重复标题对应的是不同网页建议修改titles.txt文件,否则会导致前面生成的同名pdf文件被覆盖,对应相同网页则无需修改")
print("按回车键继续...")
input()
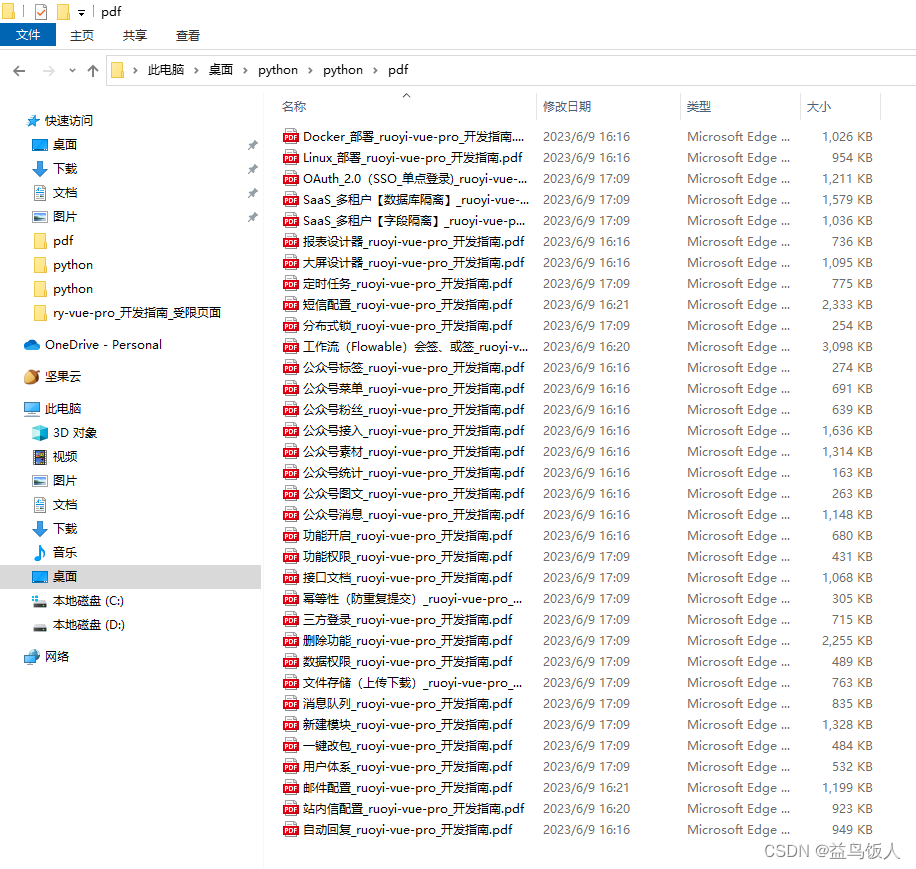
print("文件将保存在当前目录的pdf文件夹中,请提前创建")
print()
# 利用前面得到的url.txt和titles.txt批量执行wkhtmltopdf命令
# 读取网址文件和文件名文件
with open('urls.txt', 'r', encoding='utf-8') as f:
urls = f.readlines()
with open('titles.txt', 'r', encoding='utf-8') as f:
titles = f.readlines()
# 批量执行 wkhtmltopdf 命令
for url, title in zip(urls, titles):
# 删除换行符
url = url.strip()
title = title.strip()
print("正在生成“" + title + ".pdf”...")
# 构造命令
cmd = 'wkhtmltopdf {} ./pdf/{}.pdf'.format(url, title)
# 执行命令
subprocess.call(cmd, shell=True)
print("程序已经运行完毕,请按回车键退出...")
input()














 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









