







字符串哈希算法
什么是字符串哈希
哈希表我们已经简单了解过了,本质上就是关键字key和数据data的映射关系。
字符串哈希,就是实现数据为data的字符串,获取它的key值。
产生这样需要的原因是,对于一个超长的字符串,如果我们能够把他转成用整数存储,需要的时候再把它转回字符串,这样就极大地节省了空间。
这样的将字符串转为整数的过程,就叫做字符串哈希。
注意:字符串哈希产生的整数与字符串必须是一一对应的,换言之一个数必须能且仅能代表一个字符串。
因此,字符串哈希得到的关键字也具有一些良好的性质,比如可以直接用关键字来比较两个字符串是否相等,这样就避免了字符串比较时单个字符的逐个比较的问题。
换言之,这是一种空间换时间的做法。
字符串哈希的哈希函数
由于我们需要构造字符串的key与字符串形成单射关系,所以哈希函数的选取就事关重要,如何处理哈希冲突也相当关键。
首先我们定义,对于任意一个给定的字符串S=s1s2s3s4…sn,总有:
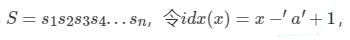
或者取idx(x)为对应字符的ascii,但是上面的取法更常用
关于字符串哈希,我们需要关注四个定义:基数Base,哈希数组hash,基数数组p和余数MOD(MOD就是正常的余数)
关于这三个定义,举个栗子:
比如对于1174这个数,基于十进制,我们可以把它拆解为
1
∗
1
0
3
+
1
∗
1
0
2
+
7
∗
1
0
1
+
4
∗
1
0
0
1*10^3 + 1*10^2 + 7*10^1 + 4*10^0
1∗103+1∗102+7∗101+4∗100
这样我们可以很清楚的看到,对于一个数,他总是表示为a*b^c求和的形式,这种形式是我们能够用数来表示字符串的关键。
类似的,我们可以效仿这个结构,于是得到:Base就相当于于10进制的10,hash[i]表示的是子串[0,i]的hash值,p[i]表示的是Base的i次幂。
自然溢出法
自然溢出法,就是利用了unsigned long long这一基本数据类型在溢出的时候对2^64−1取模,从而自动达到了MOD的效果。
Base要取质数,不然可能会影响唯一性。
自然溢出法的定义代码如下:
//自然溢出法
#define ull unsigned long long
#define MAXN 100
ull Base;
ull hash[MAXN], p[MAXN];
hash[0] = 0;
p[0] = 1;
这段代码定义了两个数组和一个Base,hash[i]表示从[0,i]的子串的哈希值,p[i]表示Base的i次方,Base为基数。
其对应的hash函数公式为:

我们可以用十进制数类比,比如115,第一个为0,hash[1] = 0 * 10 + 1 = 1,hash[2] = 1 * 10 + 1 = 11,hash[3] = 11 * 10 + 5 = 115
单Hash法
单Hash法,就是就是自定义好了Base和MOD之后,做类似的操作。
注意Base和MOD尽量取大,Base < MOD并且两个都取质数。
对应的hash函数公式为:

单Hash法代码如下:
//单Hash法
#define ll long long
#define MAXN 100
ll Base;
ll hash[MAXN], p[MAXN];
hash[0] = 0;
p[0] = 1;
举个栗子:
如取Base = 13,MOD=101,对字符串abc进行Hash
hash[0] = 0 (相当于 0 字串)
hash[1] = (hash[0] * 13 + 1) % 101 = 1
hash[2] = (hash[1] * 13 + 2) % 101 = 15
hash[3] = (hash[2] * 13 + 3) % 101 = 97
所以,字符串abc的关键字key = 97,即97就是abc 的hash值。
双Hash法
双Hash就是为了避免单Hash可能导致的冲突问题,所以需要两个hash值来确定一个数。因此,MOD和Base也相应的需要两个。
对应的函数公式如下:
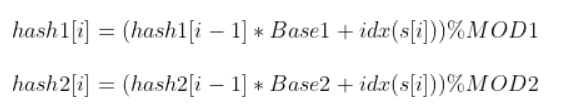
其结果就是一个字符串对应了一个二元组:
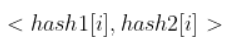
三种Hash函数构造的比较
速度:自然溢出法 > 单Hash > 双Hash
安全性:双Hash > 单Hash > 自然溢出法
O(1)获取子串
比如对于字符串abc对应的idx(x)分别为
idx1(x1) = a - a + 1 = 1,idx2(x2) = b - a + 1 = 2,idx(x3) = c - a + 1 = 3
因此可以得到对应的字符串a,ab,abc的hash值为:
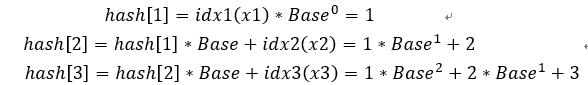
这里我们做了一个对齐的工作,是为了后面的性质的推导做准备。
可以看到我们求解的hash数组的三个下标1 2 3分别对应了字符串a,ab,abc,但是我们如果需要子串bc怎么办呢?
观察这时候bc子串的性质,我们可以得到bc这个串如果要计算他的hash值,结果应该为:

再观察一下已经求得的hash数组,可以得到:
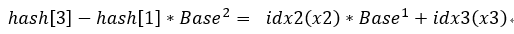
所以我们可以得到公式:
对于已知字符串S = s1s2s3…sn,其子串S` = sl…sr,hash值为:

对于需要取模运算的,需要做修正,保证ans是一个正数:
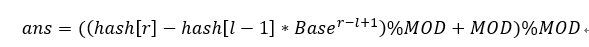
例题
本题来自于187. 重复的DNA序列 - 力扣(LeetCode)
187. 重复的DNA序列
所有 DNA 都由一系列缩写为 'A','C','G' 和 'T' 的核苷酸组成,例如:"ACGAATTCCG"。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
示例 1:
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
输出:["AAAAACCCCC","CCCCCAAAAA"]
示例 2:
输入:s = "AAAAAAAAAAAAA"
输出:["AAAAAAAAAA"]
提示:
0 <= s.length <= 105
s[i] 为 'A'、'C'、'G' 或 'T'
典型的字符串哈希题目,我们采取自然溢出法处理。定义好unsigned long long类型hash和p数组,Base取一个比较大的质数避免哈希冲突。
由于子串长度固定为10,所以r-l-1 = 10,每次子串之间需要乘的Base的i次方是一个常数,即p[10]
接着根据hash数组与串下标的对应关系代入公式即可计算出关键字key。
最后我们用一个unordered_map来存储已经计算得到的key和出现的次数,当出现次数等于2的时候说明该子串需要被返回,push进vector即可。
C++AC代码如下:
class Solution {
public:
const int Base = 13131;
vector<string> findRepeatedDnaSequences(string s) {
vector<string> ans;
unsigned long long* hash = new unsigned long long[100001];
unsigned long long* p = new unsigned long long[100001];
hash[0] = 0;
p[0] = 1;
for (int i = 0;i < s.length();i++){
hash[i + 1] = hash[i] * Base + s[i] - 'a' + 1;
p[i + 1] = p[i] * Base;
}
unordered_map<long long,int> Map;
for (int i = 1;i + 9 <= s.length();i++){
long long cur = hash[i + 9] - hash[i - 1] * p[10];
++Map[cur];
if (Map[cur] == 2){
ans.push_back(s.substr(i - 1,10));
}
}
return ans;
}
};















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









