







目录
vector.push_back() pop_back()函数的用法
大一学习时候的笔记,比较稚嫩

容器,迭代器,算法是stl的三个基本组成部分
STL 是“Standard Template Library”的缩写,中文译为“标准模板库”。STL 是 C++ 标准库的一部分,不用单独安装。
STL封装了许多复杂的数据结构算法和大量常用的数据结构操作。
Vector封装数组,list封装链表,map和set封装了二叉树等等。
STL 就是借助模板把常用的数据结构及其算法都实现了一遍,并且做到了数据结构和算法的分离。
例如,vector 的底层为顺序表(数组),list 的底层为双向链表,deque 的底层为循环队列,set 的底层为红黑树,hash_set 的底层为哈希表。
- STL 就位于各个 C++ 的头文件中,即它并非以二进制代码的形式提供,而是以源代码的形式提供。从根本上说,STL 是一些容器、算法和其他一些组件的集合
- STL组成部分:容器,迭代器,空间配置器,配接器,算法,伪函数
- 容器部分主要由头文件和组成。
对于常用的一些容器和容器适配器(可以看作由其它容器实现的容器),可以通过下表总结一下它们和相应头文件的对应关系。
学STL能干什么?
以 C++ 定义数组的操作为例,在 C++ 中如果定义一个数组,可以采用如下方式:

这种定义数组的方法需要事先确定好数组的长度,即 n 必须为常量,这意味着,如果在实际应用中无法确定数组长度,则一般会将数组长度设为可能的最大值,但这极有可能导致存储空间的浪费。
所以除此之外,还可以采用在堆空间中动态申请内存的方法,此时长度可以是变量:

这种定义方式可根据变量 n 动态申请内存,不会出现存储空间浪费的问题。但是,如果程序执行过程中出现空间不足的情况时,则需要加大存储空间,此时需要进行如下操作:

但是 而完成相同的操作,如果采用 STL 标准库,则会简单很多,因为大多数操作细节将不需要程序员关心。下面是使用向量模板类 vector 实现以上功能的示例:
- vector <int> a; //定义 a 数组,当前数组长度为 0,但和普通数组不同的是,此数组 a 可以根据存储数据的数量自动变长。
- //向数组 a 中添加 10 个元素
- for (int i = 0; i < 10 ; i++)
- a.push_back(i)
- //还可以手动调整数组 a 的大小
- a.resize(100);
- a[90] = 100;
- //还可以直接删除数组 a 中所有的元素,此时 a 的长度变为 0
- a.clear();
- //重新调整 a 的大小为 20,并存储 20 个 -1 元素。
- a.resize(20, -1)
通常认为,STL 是由容器、算法、迭代器、函数对象、适配器、内存分配器这 6 部分构成,其中后面 4 部分是为前 2 部分服务的,它们各自的含义如表 1 所示。
| STL的组成 | 含义 |
| 容器 | 一些封装数据结构的模板类,例如 vector 向量容器、list 列表容器等。 |
| 算法 | STL 提供了非常多(大约 100 个)的数据结构算法,它们都被设计成一个个的模板函数,这些算法在 std 命名空间中定义,其中大部分算法都包含在头文件 <algorithm> 中,少部分位于头文件 <numeric> 中。 |
| 迭代器 | 在 C++ STL 中,对容器中数据的读和写,是通过迭代器完成的,扮演着容器和算法之间的胶合剂。 |
| 函数对象 | 如果一个类将 () 运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象(又称仿函数)。 |
| 适配器 | 可以使一个类的接口(模板的参数)适配成用户指定的形式,从而让原本不能在一起工作的两个类工作在一起。值得一提的是,容器、迭代器和函数都有适配器。 |
| 内存分配器 | 为容器类模板提供自定义的内存申请和释放功能,由于往往只有高级用户才有改变内存分配策略的需求,因此内存分配器对于一般用户来说,并不常用。 |
| 表 2 C++ STL头文件 | |||
| <iterator> | <functional> | <vector> | <deque> |
| <list> | <queue> | <stack> | <set> |
| <map> | <algorithm> | <numeric> | <memory> |
| <utility> |
|
|
|
应遵照 C++ 规范,使用无扩展名的头文件。
STL序列式容器
- STL容器是什么
STL 中提供了专家级的几乎我们所需要的各种容器,功能更好,复用性更高。简单的理解容器,它就是一些模板类的集合,但和普通模板类不同的是,容器中封装的是组织数据的方法(也就是数据结构)。STL 提供有 3 类标准容器,分别是序列容器、排序容器和哈希容器,其中后两类容器有时也统称为关联容器。它们各自的含义如表 1 所示。
| 表 1 STL 容器种类和功能 | |
| 容器种类 | 功能 |
| 序列容器 | 主要包括 vector 向量容器、list 列表容器以及 deque 双端队列容器。之所以被称为序列容器,是因为元素在容器中的位置同元素的值无关,即容器不是排序的。将元素插入容器时,指定在什么位置,元素就会位于什么位置。 |
| 排序容器 | 包括 set 集合容器、multiset多重集合容器、map映射容器以及 multimap 多重映射容器。排序容器中的元素默认是由小到大排序好的,即便是插入元素,元素也会插入到适当位置。所以关联容器在查找时具有非常好的性能。 |
| 哈希容器 | C++ 11 新加入 4 种关联式容器,分别是 unordered_set 哈希集合、unordered_multiset 哈希多重集合、unordered_map 哈希映射以及 unordered_multimap 哈希多重映射。和排序容器不同,哈希容器中的元素是未排序的,元素的位置由哈希函数确定。 |
另外,以上 3 类容器的存储方式完全不同,因此使用不同容器完成相同操作的效率也大不相同。所以在实际使用时,要善于根据想实现的功能,选择合适的容器。
序列式容器
向量(vector) 连续存储的元素
列表(list) 由节点组成的双向链表,每个结点包含着一个元素
双端队列(deque) 连续存储的指向不同元素的指针所组成的数组
适配器容器
栈(stack) 后进先出的值的排列
队列(queue) 先进先出的值的排列
优先队列(priority_queue) 元素的次序是由作用于所存储的值对上的某种谓词决定的的一种队列
关联式容器
集合(set) 由节点组成的红黑树,每个节点都包含着一个元素,节点之间以某种作用于元素对的谓词排列,没有两个不同的元素能够拥有相同的次序
多重集合(multiset) 允许存在两个次序相等的元素的集合
映射(map) 由{键,值}对组成的集合,以某种作用于键对上的谓词排列
多重映射(multimap) 允许键对有相等的次序的映射

C++ STL迭代器是什么
迭代器就像指向容器中对象的指针,stl算法通过迭代器在容器上进行操作。
迭代器实际上是面向对象版本的指针
迭代器:(iterator)可在容器上遍访的接口,设计人员无需关心容器物件的内容(减少使用成本)它可以把抽象的容器和通用算法有机的统一起来。迭代器是一种对象,它能够用来遍历标准模板库容器中的部分或全部成员。每个迭代器对象代表容器中的确定的地址。
无论是序列容器还是关联容器,最常做的操作无疑是遍历容器中存储的元素,而实现此操作,多数情况会选用“迭代器(iterator)”来实现。那么,迭代器到底是什么呢?
我们知道,尽管不同容器的内部结构各异,但它们本质上都是用来存储大量数据的,换句话说,都是一串能存储多个数据的存储单元。因此,诸如数据的排序、查找、求和等需要对数据进行遍历的操作方法应该是类似的。
既然类似,完全可以利用泛型技术,将它们设计成适用所有容器的通用算法,从而将容器和算法分离开。但实现此目的需要有一个类似中介的装置,它除了要具有对容器进行遍历读写数据的能力之外,还要能对外隐藏容器的内部差异,从而以统一的界面向算法传送数据。
这是泛型思维发展的必然结果,于是迭代器就产生了。简单来讲,迭代器和 C++ 的指针非常类似,它可以是需要的任意类型,通过迭代器可以指向容器中的某个元素,如果需要,还可以对该元素进行读/写操作。
STL 标准库为每一种标准容器定义了一种迭代器类型,这意味着,不同容器的迭代器也不同,其功能强弱也有所不同。
容器的迭代器的功能强弱,决定了该容器是否支持 STL 中的某种算法。
常用的迭代器按功能强弱分为输入迭代器、输出迭代器、前向迭代器、双向迭代器、随机访问迭代器 5 种
输入迭代器和输出迭代器比较特殊,它们不是把数组或容器当做操作对象,而是把输入流/输出流作为操作对象。
1) 前向迭代器(forward iterator)
假设 p 是一个前向迭代器,则 p 支持 ++p,p++,*p 操作,还可以被复制或赋值,可以用 == 和 != 运算符进行比较。此外,两个正向迭代器可以互相赋值。
2) 双向迭代器(bidirectional iterator)
双向迭代器具有正向迭代器的全部功能,除此之外,假设 p 是一个双向迭代器,则还可以进行 --p 或者 p-- 操作(即一次向后移动一个位置)。
3) 随机访问迭代器(random access iterator)
随机访问迭代器具有双向迭代器的全部功能。除此之外,假设 p 是一个随机访问迭代器,i 是一个整型变量或常量,则 p 还支持以下操作:
- p+=i:使得 p 往后移动 i 个元素。
- p-=i:使得 p 往前移动 i 个元素。
- p+i:返回 p 后面第 i 个元素的迭代器。
- p-i:返回 p 前面第 i 个元素的迭代器。
- p[i]:返回 p 后面第 i 个元素的引用。
此外,两个随机访问迭代器 p1、p2 还可以用 <、>、<=、>= 运算符进行比较。另外,表达式 p2-p1 也是有定义的,其返回值表示 p2 所指向元素和 p1 所指向元素的序号之差(也可以说是 p2 和 p1 之间的元素个数减一)。
vector里面没有成员函数sort


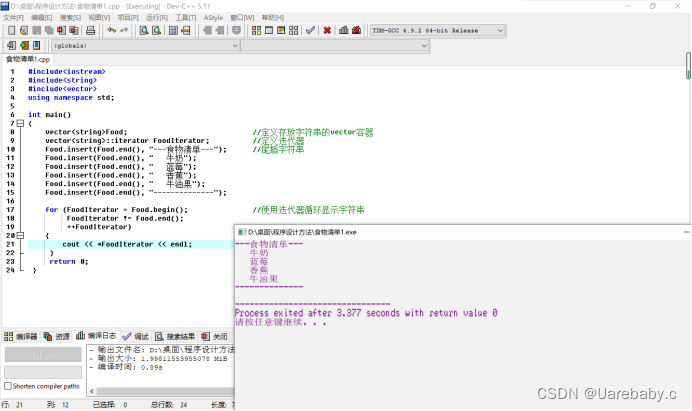
Vector和数组类似,vector 的底层为顺序表(数组), 包含一组地址连续的存储单元。对vector容器可以进行很多操作,包括查询,插入,删除等常见操作
vector.insert()函数的用法:
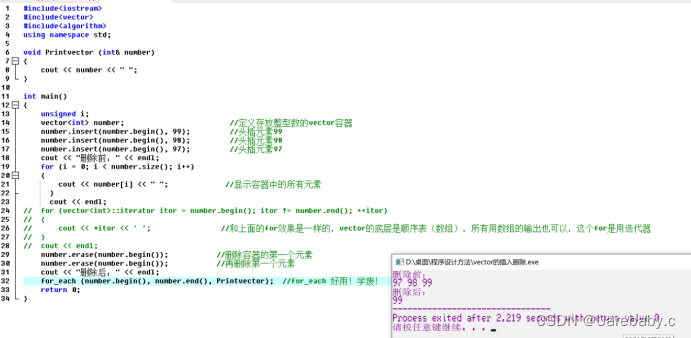
上面的程序运用了insert函数,insert()函数有三种用法
第一种:
iterator insert(iterator loc, const TYPE &val);
参数的含义:在指定位置loc前插入值为val的元素,返回指向这个元素的迭代器
第二种:
void insert(iterator loc, size_type num, const TYPE &val);
参数的含义:在指定位置loc前插入num个值为val的元素
第三种:
void insert (iterator loc,inout_iterator start, input_iterator end);
参数的含义:在指定位置loc前插入区间【start, end)的所有元素

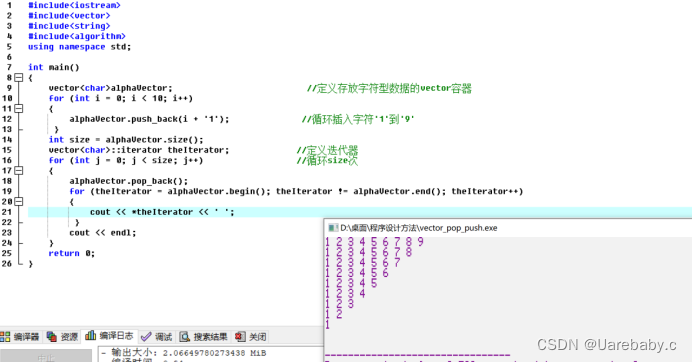
vector.push_back() pop_back()函数的用法
上面的程序用到了push_back。
push_back函数的功能是添加一个元素到vector末尾
语法:
void push_back (const TYPE &val);
pop_back函数的功能是删除当前vector最后的一个元素。
pop_back的语法:
void pop_back();
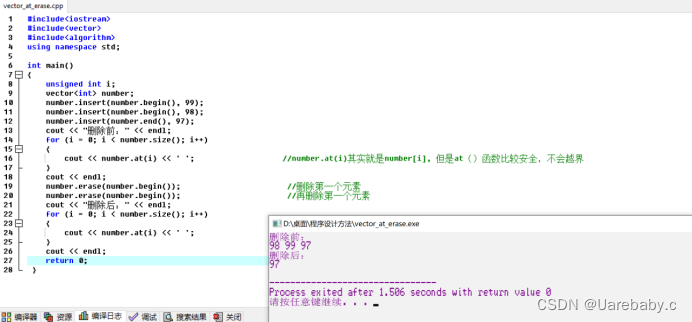
at函数和erase的用法
vector中的提供的at()函数负责返回指定位置的元素。与数组运算符[ ]相比。at()函数更加安全,不会访问vector内越界的元素。
vector中提供的erase()函数用于删除元素,erase()函数有两种用法:
第一种:
iterator erase(iterator loc);
功能:删除指定位置loc的元素,例如:
number.erase(number.begin());
第二种:
Iterator erase(iterator start, iterator end);
功能:删除区间[start, end)的所有元素,而返回值是指向删除的最后一个元素的下一位置的迭代器。
补充:

![]()


List概念

list底层为双向链表!!
由于链表的存储方式并不是连续的内存空间,因此链表list中的迭代器只支持前移和后移,属于双向迭代
List的使用
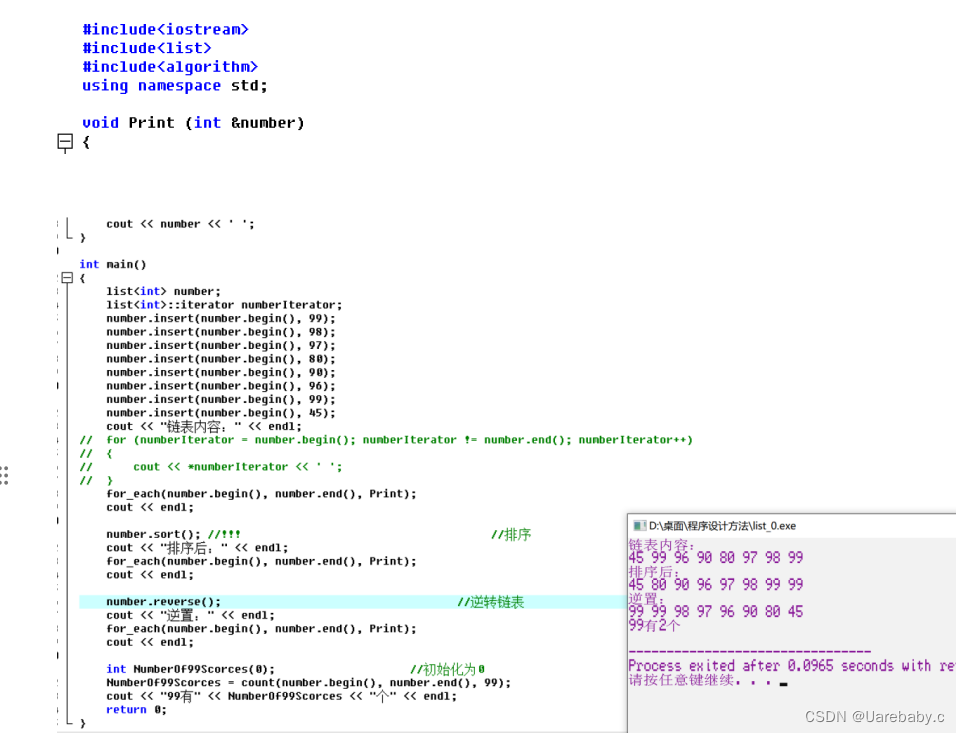
STL list容器由于采用了双向迭代器,不支持随机访问,所以标准库的merge(), sort()等功能函数都不适用,list单独实现了merge(),sort()等函数
merge函数的作用是:将两个已经排好序的序列合并为一个有序的序列。
函数参数:
merge(first1,last1,first2,last2,result,compare);
firs1t为第一个容器的首迭代器,last1为第一个容器的末迭代器;
first2为第二个容器的首迭代器,last2为容器的末迭代器;
result为存放结果的容器,comapre为比较函数(可略写,默认为合并为一个升序序列)。
注意
使用的时候result,如果用的vector,必须先resize一下,比如:(注意到此时a和b都已经是有序的啦!)
List的构造:

使用方法和vector类似
注意!!!


这里要说明的是list迭代器不能跳跃移动,例如insert函数中的参数写成L.begin() + n的操作是不可以的,只能写成++L.begin(), 或者提前定义一个迭代器变量it然后++it才能访问下一个位置,因为list的指针域指向指向下一个元素,并没有指向下下个元素。list的迭代器是双向迭代器,并不是随机迭代器
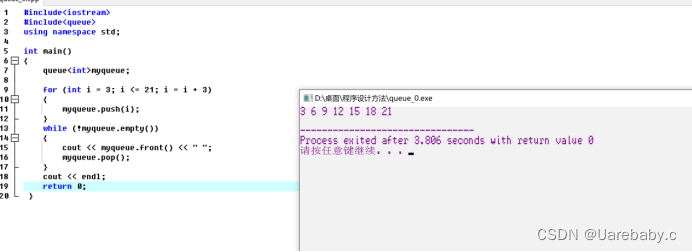
queue概念:(先进先出)
队列也是一种访问受限的容器,只允许在存储器的两端进行插入和删除,并且符合先进先出的规则。
做插入操作的这一端称为队尾,另一端则称为队头。插入操作称为进队列,删除操作则称为出队列。
在STL中,队列是以其他容器作为内部结构的,STL提供接口。
队列的基本操作包括:
判队列空empty()
返回队列中元素的个数size()
出队列(不返回值)pop()
取队头元素(不删除队头元素)front()
进队列(在队尾插入新元素)push()
取队尾元素(不删除该元素)back()
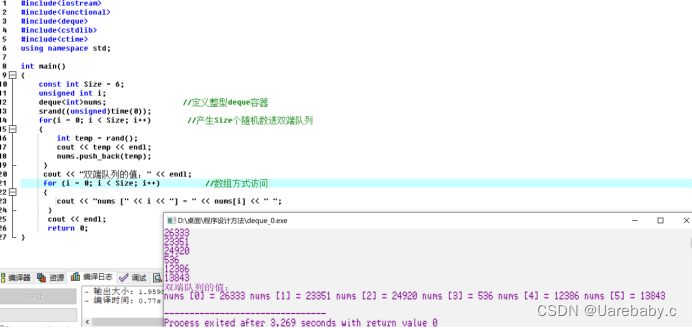
Deque容器:
deque是双端队列,是一种放松了访问限制的队列。对于普通队列,只能从队尾插入元素,从队头删除元素;而在双端队列中,队尾和队头都可以插入元素,也都可以删除元素。其实,deque和vector是类似的,不过deque内部的数据机制和执行性能与vector不同,如果考虑到容器元素的内存分配策略和操作性能,deque相对vector有优势
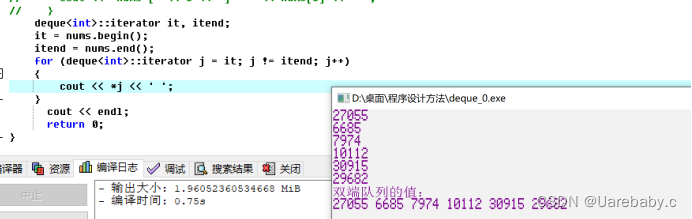
存取deque信息:
构造函数,push_back(), push_front(), insert(), 数组运算符,赋值运算符,pop_back(),pop_front(), erase(), begin(), end(), rbegin(), rend(), size, maxsize等
输出方式
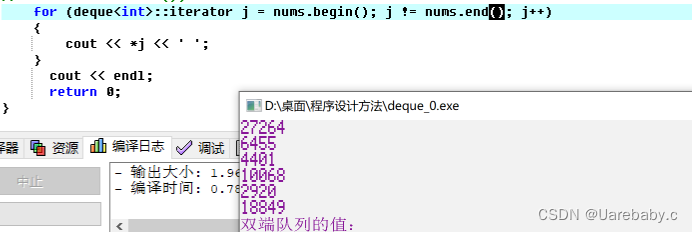
优先队列是一种特殊的队列。优先队列容器也是一种从一端进队,从另一端出队的队列。但是,与普通队列不同,队列中最大的元素总是位于队头位置,因此优先队列并不符合先进先出的要求。出队时,是将队列中的最大元素出队。
概念:在优先队列中,元素被赋予优先级,当访问元素时,具有最高级优先级的元素可以先被访问。即优先队列具有最高级先出的行为特征。
优先队列具有队列的所有特征,包括基本操作,只是在这基础上添加了一个内部的排序。本身是一个堆
和队列基本操作相同:
top访问队头元素
empty队列是否为空
size返回队列内元素个数
push插入元素到队尾(并排序)
emplace原地构造一个元素并插入队列
pop弹出队头元素
swap交换内容
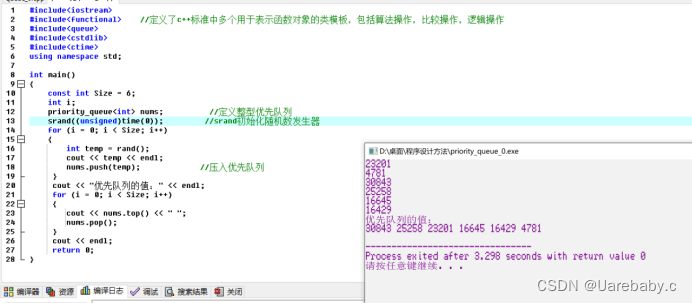
stack概念:
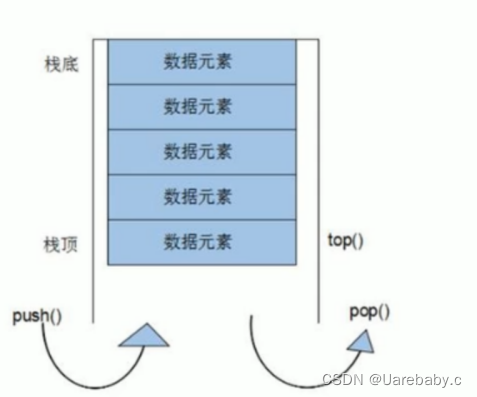
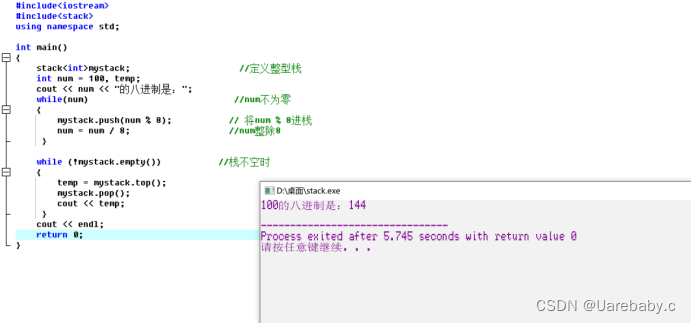
栈是一种访问受限的容器,只允许在存储器的一端进行插入和删除,并且符合后进先出的规则。
做插入和删除操作的这一端称为栈顶,另一端则称栈底。插入操作称为进栈或入栈。删除操作则称为退栈或出栈。
STL中,栈是以其他容器作为内部结构的,STL提供了接口。
栈中只有顶端元素才可以被外界使用,因此栈不允许有遍历行为
栈的基本操作:
判栈空empty()
返回栈中元素个数size()
退栈(不返回值)pop()
取栈顶元素(不删除栈顶元素)top()
进栈push()


关于set,必须说明的是set关联式容器(排序容器)。set作为一个容器也是用来存储同一数据类型的数据类型,并且能从一个数据集合中取出数据,在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。应该注意的是set中数元素的值不能直接被改变。C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树,所以被STL选择作为了关联容器的内部结构。

注意:set容器没有push_back, pop_back这两种插入接口,只能用insert函数进行插入
如果向set容器种插入相同元素,不会报错,但是打印的时候会自动滤去多余的元素,一个元素只能有一个,而且打印结果事是排好序了的。
set不但保证了每个元素不重复,还保持了有序!



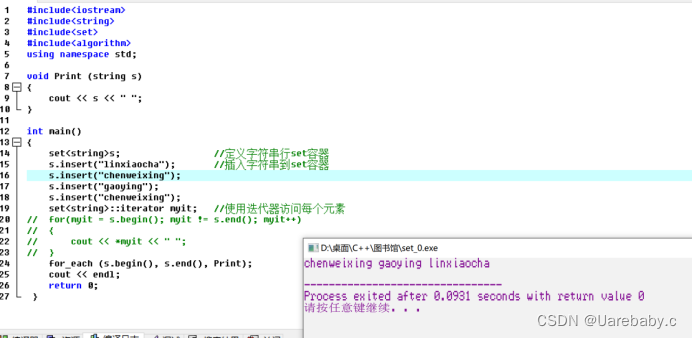
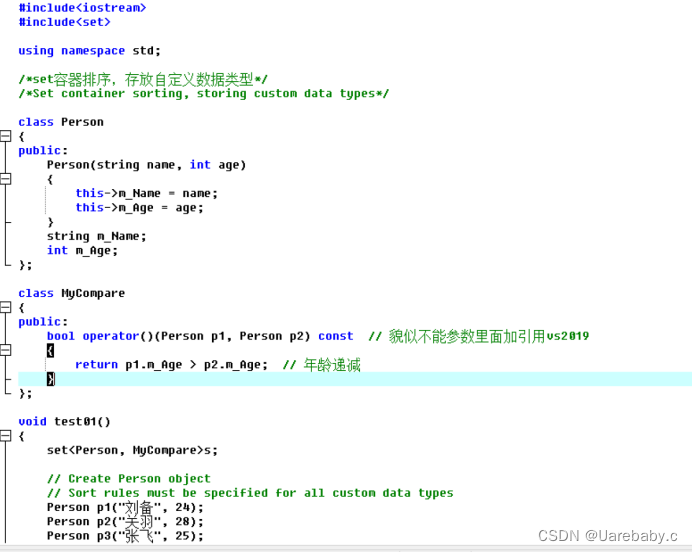
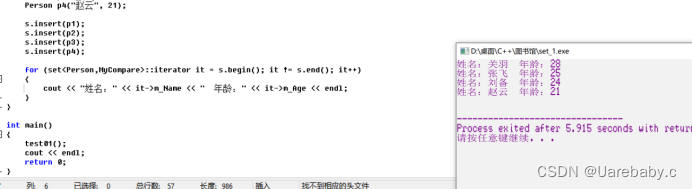
set容器自定义排序:
Pair的标准库类型:
一个pair保存两个数据成员,第一个成员是first,第二个成员是second;
Pair有什么用途呢?比如学生有学号和姓名,这两个属性就是对应的,这时候用数组来保存学号和姓名,就不能体现它们的对应关系了,我们可以用pair来保存。一个pair保存一个学生的姓名和学号。那么很多学生的学号和姓名就用很多pair来保存
用法:

Map基本概念:
map是C++标准库提供的关联容器之一,保存的是键值对(key-value),我们可以通过key快速查找到其对应的value。map底层使用的数据结构是红黑树,因此在map中查找、添加或删除元素时间复杂度都是O(log(n))。此外,map中的元素还是有序的。默认按键递增排序

map使用场景:
现在假设有一个寝室501,寝室有4个学生,我们要用一种容器来保存这4个学生的学号和姓名,需求是我要通过学号来查找这个学号对应的姓名。 此时我们用一个map来保存,学号作为key,姓名作为value,一个学生的这两个信息作为map的一个元素pair(pair用法总结),这4个元素是按学号(key)升序存放的,我们可以通过学号来得到对应的姓名。
也许你会有这样的疑问,为什么要用关联容器呢,我用一个二维数组不是也一样能存放寝室4个学生的学号和姓名吗?
是的,存是可以存,但是操作的时间复杂度就不一样了,比如我知道学号"sc0303",我想查找对应的姓名,如果用map保存的,红黑树是一种自平衡的二叉搜索树,只需要O(log(n))的时间就能查到对应的姓名。如果用的二维数组保存的,需要从头遍历二维数组的第一列,需要O(n)的时间才能查到。这就是使用map的意义。
Map的功能:
自动构建ket-value的对应。key和value可以是任意你需要的类型,包括自定义类型。

使用map得包含map类所在的头文件 #include<map> //STL头文件没有扩展名.h
Map对象是模板类,需要关键字和存储对象两个模板参数:
std:map<int, string>peronnel;
这样就定义了一个用int作为索引,并拥有相关联的指向string的指针
Map基本用法:

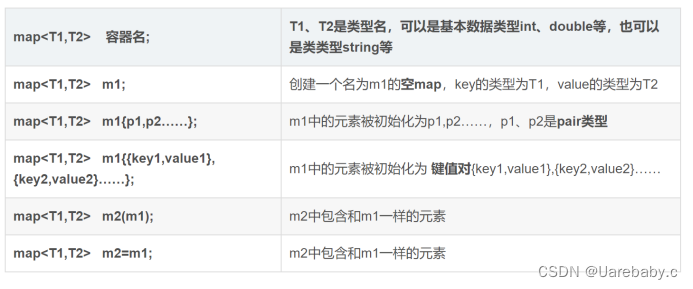
注意:Python里面的字典就是这么造出来的.
Insert函数仔细看,里面的参数是pair,然后通过输出可以看出,元素按照对组的key值进行排序,也就是first值。
mltimap除了允许重复的key值以外其他的和map一样

注意:swap函数目前来看只支持相同数据类型的集合之间的交换

注意:第三种插入方式太长不建议使用,第四种方式虽然看起来简短但是也不建议使用,这个括号[]的目的不是用来设置元素的,用于设置元素的话,容易导致混乱,后面的一个例子会说明。
[]主要是用来访问的,当我们确定这个key的值的时候我们就可以通过key来访问,key对应的值。
用insert函数插入数据,在数据的插入上涉及到了集合的唯一性这个概念,即当map中有这个关键字时, insert操作是不能再插入数据的

注意:find返回的迭代器,不是具体位置,将find的结果打印出来的话就是这个值。
在map种count就只有0或者1,multimap允许重复key值里面有多种结果。
判断是否查找成功: iter = m.find(key);
If (iter != m.end()) cout<< “Find” << endl;

//string 字符串如果是中文的话,应该是按照汉字的编码表来排序的,但是汉字的编码表不止一张,这些之后再讨论
map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数, (帮助评论区理解: 因为key值不会重复,所以只能是1 or 0)
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









