







Redis 中的 hash 类型
Hello , 大家好 , 这个专栏给大家带来的是 Redis 系列 ! 本篇文章给大家带来的是 Redis 中 hash 数据结构的相关命令、底层编码以及常见的应用场景 .
本专栏旨在为初学者提供一个全面的 Redis 学习路径,从基础概念到实际应用,帮助读者快速掌握 Redis 的使用和管理技巧。通过本专栏的学习,能够构建坚实的 Redis 知识基础,并能够在实际学习以及工作中灵活运用 Redis 解决问题 .
专栏地址 : Redis 入门实践

Redis 本身已经是键值对的结构了 , 那 value 这一层 , 又可以是哈希结构 (套娃)
我们可以看这张图理解一下
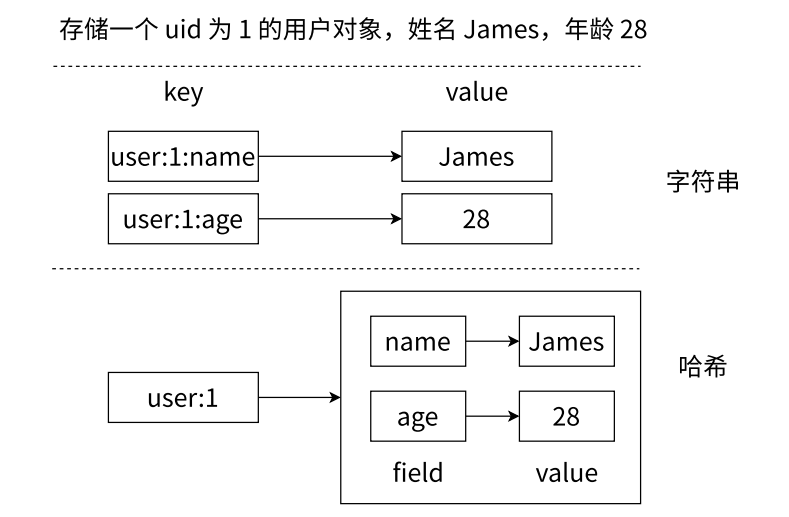
那在哈希类型中 , 映射关系通常称为 field-value
因为 Redis 整体的键值对映射关系叫做 key-value , 为了进行区分 , 哈希类型的映射关系就叫做 field-value
一 . 常见命令
1.1 hset 和 hget
hset 的作用就是设置 hash 中指定的字段 (field) 的值 (value)
语法 : hset key field1 value1 [field2 value2 …]
value 只能为字符串
返回值代表设置成功的键值对的个数 (也就是 field 的个数)
hget 的作用就是获取 hash 中指定字段的值
语法 : hget key field
那我们举一个例子来看看 hset 和 hget 的用法
127.0.0.1:6379> hset key k1 v1 # 设置哈希类型
(integer) 1
127.0.0.1:6379> hset key k2 v2 k3 v3 k4 v4 # 可以设置多组哈希
(integer) 3 # 返回值代表设置成功的键值对的个数 (field 的个数)
127.0.0.1:6379> hget key k1 # 获取哈希类型
"v1"
127.0.0.1:6379> hget key k2
"v2"
127.0.0.1:6379> hget key k100 # 如果获取的 field 不存在就会返回 nil
(nil)
127.0.0.1:6379> hget key2 k1 # 如果获取到的 key 不存在也会返回 nil
(nil)
1.2 hexists
hexists 的作用就是判断 hash 中是否有指定的字段 (也就是判断 field 是否存在)
语法 : hexists key field
返回值 : 1 代表存在 , 0 代表不存在
时间复杂度 : O(1)
127.0.0.1:6379> hexists key k1 # 判断 key 中的 k1 是否存在
(integer) 1 # 1 代表存在
127.0.0.1:6379> hexists key k100 # 如果 field 不存在是查询不到数据的
(integer) 0 # 0 代表不存在
127.0.0.1:6379> hexists key2 k1 # 如果 key 不存在也是查询不到数据的
(integer) 0
1.3 hdel
hdel 的作用就是删除 hash 中指定的字段
del 删除的是 key , hdel 删除的是 field
语法 : hdel key field1 [field2 …]
时间复杂度 : O(1)
返回值代表本次删除成功的字段个数
127.0.0.1:6379> hdel key k1 # 删除 key 中的 k1
(integer) 1 # 返回值代表删除成功的个数
127.0.0.1:6379> hexists key k1 # 此时 key 中的 k1 就不存在了
(integer) 0
127.0.0.1:6379> hdel key k2 k3 # 可以删除多个 field
(integer) 2
127.0.0.1:6379> hdel key2 k1 # 如果删除不存在的 key 就会删除失败
(integer) 0
127.0.0.1:6379> hdel key k100 # 如果删除不存在的 field 也会删除失败
(integer) 0
1.4 hkeys
hkeys 可以获取到哈希中所有的字段 (field)
语法 : hkeys key
这个操作底层的实现是会先根据 key 找到对应的 field , 然后遍历 field 集合
时间复杂度 : O(N) , N 指的是哈希的元素个数 (field 的个数)
127.0.0.1:6379> hset key f1 111 f2 222 f3 333 f4 444 # 设置多个哈希
(integer) 4
127.0.0.1:6379> hkeys key # 获取哈希中所有的字段
1) "f1"
2) "f2"
3) "f3"
4) "f4"
那这个操作还是有风险的 , 类似于之前的 keys *
主要是咱们也不知道某个 hash 中是否会存在大量的 field , 如果查询数据过多就会发送阻塞 , 就会导致大量请求转移到数据库 , 最终数据库也支撑不住 , 那系统就会出现故障
1.5 hvals
hvals 与 hkeys 相对 , 他能获取到 hash 中所有的 value
语法 : hvals key
时间复杂度 : O(N) , N 指的是哈希的元素个数 (field 的个数)
127.0.0.1:6379> hset key f1 111 f2 222 f3 333 f4 444 # 设置多个哈希
(integer) 4
127.0.0.1:6379> hvals key # 获取哈希中所有的 value
1) "111"
2) "222"
3) "333"
4) "444"
如果哈希存储的元素也非常多 , 同样会导致 Redis 服务器被阻塞住
1.6 hgetall、hmget
hgetall 就相当于把 hkeys 和 hvals 结合起来了
语法 : hgetall key
127.0.0.1:6379> hset key f1 111 f2 222 f3 333 f4 444 # 设置多个哈希
(integer) 4
127.0.0.1:6379> hgetall key # 获取所有的 field 和 value
1) "f1"
2) "111"
3) "f2"
4) "222"
5) "f3"
6) "333"
7) "f4"
8) "444"
如果哈希存储的元素也非常多 , 同样会导致 Redis 服务器被阻塞住
那我们一般多数情况下并不需要查询所有的 field , 只需要查询当中的几个 field , 我们就可以使用 hmget , 一次可以查询多个 field
语法 : hmget key field1 [field2 …]
127.0.0.1:6379> hmget key f1 f2 f3 # 一次查询多个 field
# 多个 value 的顺序和 field 的顺序是匹配的
1) "111"
2) "222"
3) "333"
相对应的 hmset 也存在 , 但是 hset 就已经能够一次设置多个键值对了 , 所以我们一般不会去使用 hmset
那我们之前说 hkeys、hvals、hgetall 都是存在风险的 , hash 的元素个数太多 , 那执行的耗时就会比较长 , 从而阻塞 Redis .
那我们就可以使用 hscan 遍历 Redis 的 hash , 它属于 “渐进式遍历” , 也就是一次遍历一点点 , 多使用几次就可以完成整个遍历过程了 , 我们有机会再介绍
1.7 hlen
hlen 是用来获取 hash 中所有字段的个数
语法 : hlen key
时间复杂度 : O(1)
内部并不是通过遍历的方式去计算个数 , 可以通过变量存储元素个数
127.0.0.1:6379> hset key f1 111 f2 222 f3 333 f4 444
(integer) 4
127.0.0.1:6379> hlen key # 获取 hash 中所有字段的个数
(integer) 4
1.8 hsetnx
与之前讲过的 setnx 类似 , 不存在的时候才能设置成功 . 如果存在 , 则设置失败
语法 : hsetnx key field value
127.0.0.1:6379> hset key f1 111 f2 222 f3 333 f4 444
(integer) 4
# 目前已经有 f1 f2 f3 f4 了
127.0.0.1:6379> hsetnx key f5 555 # 不存在才能设置成功
(integer) 1
127.0.0.1:6379> hsetnx key f5 666 # 存在就会设置失败
(integer) 0
127.0.0.1:6379> hget key f5 # f5 的值还是 555, 代表设置失败
"555"
1.9 hincrby、hincrbyfloat
hash 中的 value 同样可以当做数字来处理
所以 hincrby 就可以加减整数 , hincrbyfloat 就可以加减小数
时间复杂度 : O(1)
127.0.0.1:6379> hincrby key f1 10 # 对 key 中的 f1 进行 +10 操作
(integer) 121
127.0.0.1:6379> hget key f1 # 查看 key 中的 f1 的值
"121"
127.0.0.1:6379> hincrby key f1 -10 # 对 key 中的 f1 进行 -10 操作
(integer) 111
127.0.0.1:6379> hincrbyfloat key f1 3.14 # 对 key 中的 f1 进行 +3.14 操作
"114.14"
127.0.0.1:6379> hincrbyfloat key f1 -3.14 # 对 key 中的 f1 进行 -3.14 操作
"111"
小结

二 . hash 的编码方式
哈希内部的编码方式有两种 :
- ziplist (压缩列表) : 他的目的是节省内存空间 , 但是 ziplist 付出的代价就是进行读写元素速度是比较慢的 , 如果元素个数少 , 那慢的就不太明显 ; 如果元素个数比较多 , 那 ziplist 速度就会比较慢
- hashtable (哈希表)
所以我们采取的策略是 :
- 如果哈希中的元素个数比较少 , 使用 ziplist 存储 ; 如果哈希中的元素个数比较多 , 使用 hashtable 来表示
- 如果每个 value 的值长度都比较短 , 使用 ziplist 来去存储 ; 如果某个 value 的长度太长 , 还是会转化成 hashtable
也就是说 , 只有哈希中的元素个数比较少 && 每个 value 的值长度都比较短的情况下 , 才会使用 ziplist 去存储
那我们也可以在配置文件中配置 hash-max-ziplist-entries (默认 512 个) 来去设置哈希中的元素个数的标准 , 配置 hash-max-ziplist-value (默认 64 字节) 来去设置每个 value 的值的长度的标准
那我们同样可以通过 object encoding 来去查看具体的编码方式
127.0.0.1:6379> hset key f1 111 # 设置一个短的 value
(integer) 1
127.0.0.1:6379> object encoding key # 获取哈希的具体编码方式
"ziplist" # 长度比较短的时候使用 ziplist
# 设置一个长的 value
127.0.0.1:6379> hset key2 k2 2222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222
(integer) 1
127.0.0.1:6379> object encoding key2
"hashtable" # 长度比较长的时候使用 hashtable
三 . 使用场景 : 作为缓存
我们之前讲过 , string 也是可以作为缓存使用的
那如果要存储结构化的数据 , 使用 hash 会更适合一些
比如我们想要存储这个数据 :
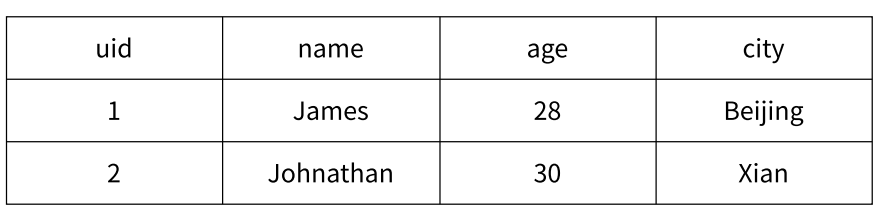
那我们通过哈希类型存储到 Redis 的缓存中就是这个样子 :
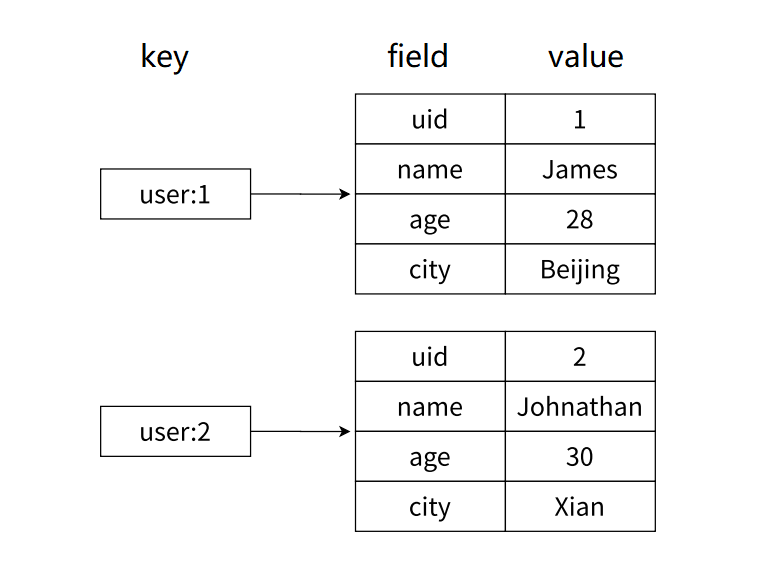
那通过哈希 , 就很容易的将关系型的数据表示出来保存到缓存中
那上述场景我们通过 string 类型也能做到 , 就需要使用到 JSON 这样的结构来去存储 .
但是如果使用 string (JSON) 的格式来去表示相关信息 , 那万一我们只想获取 / 修改其中的某个 field , 就需要把整个 JSON 读取出来 , 解析成对象然后进行修改 , 修改完还需要再转化回 JSON 格式的字符串写入到 Redis 中 , 非常麻烦 .
如果使用 hash 的方式来表示相关信息 , 就可以使用 field 表示对象的相关属性 (也就是数据表的每个列) , 此时就可以非常方便的修改 / 获取任何一个属性的值了
但是也有可能会存在一个问题 , 我们需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换 , 这样就可能会造成内存的消耗 (比如转化成哈希表类型 , 就会有大量元素空缺导致内存浪费)
那除了 string 类型、hash 类型能够存储字符串以外 , 我们还可以使用原生字符串类型来去表示一个复杂的 key
我们刚才讲的 string 的处理方式是通过 value 来去表示信息 , 使用原生字符串类型来去表示一个复杂的 key 这种是通过 key 来去表示信息
比如 : set user:1:name James , set user:1:age 23 …
但是我们并不推荐大家这样做 , 他把同一个数据的各个属性给分散开了
不满足高内聚的特点
那我们比对一下 MySQL 和 Redis 的哈希类型存储数据的区别
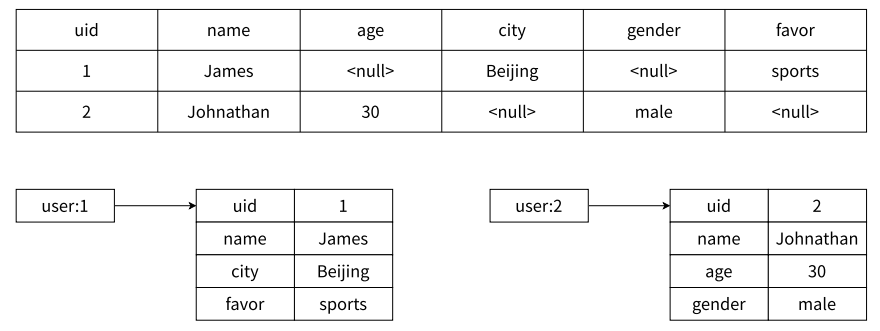
那我们 MySQL 对于数据的格式要求特别严格 , 如果某列不存在我们就需要置为 null
而 Redis 则不是 , 某列不存在那我们就不去存储他 , 比如 user:1 的 James 就没存储 age 的信息
另外 , 关系型数据库是可以做复杂的关系查询的 , 比如 : 联表查询、聚合查询等等 , 而 Redis 想要进行这样的功能就需要我们自己的代码手动实现 .
那我们的 key 也存储了用户的 ID , 而 field 中也存储了 ID , 那我们 field-value 中的 uid 能不能不写 ?
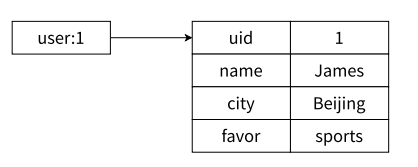
其实可以不写 , 但是在工程中一般都会把 uid 在 key 和 value 中再存一份 , 后续编写代码操作数据会比较方便
本篇文章就讲解到这里了 , 如果对你有帮助的话 , 还请一键三连~

















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











