







Redis的引入
随着网络请求量越来越大,服务器存在各种压力
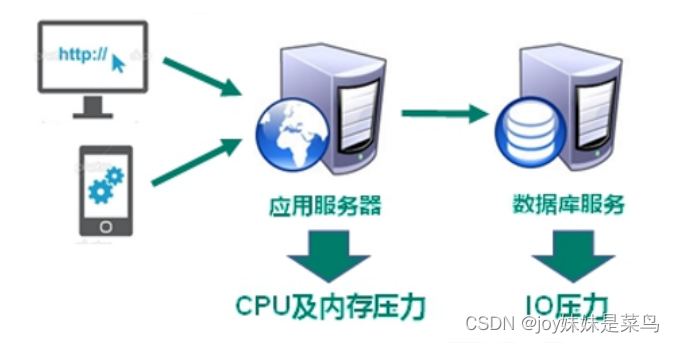
解决CPU及内存压力
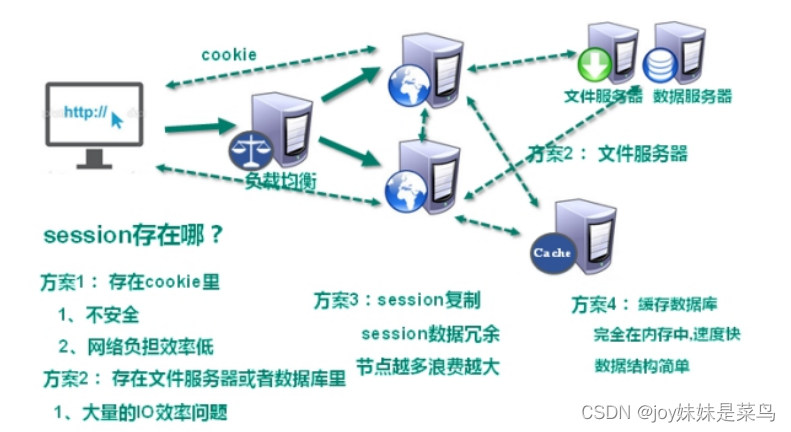
解决IO压力
分布式集群遇到的问题是
当一个客户端多次请求时,可能每次请求被分到了不同的服务器
但每次都需要验证该客户端是否登录
于是我们可以选择将sessionID和它的值存为key-value对存入数据库(数据库将内容记录在硬盘)中
但是本来数据库查询都是很慢需要优化的过程
于是我们引入Redis
NoSQL数据库
NoSQL数据库
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库
NoSQL 不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
-
不遵循SQL标准。
-
不支持ACID。
-
远超于SQL的性能。
NoSQL适用场景
-
对数据高并发的读写
-
海量数据的读写
-
对数据高可扩展性的
NoSQL不适用场景
-
需要事务支持
-
基于sql的结构化查询存储,处理复杂的关系,需要即席查询。
-
(用不着sql的和用了sql也不行的情况,请考虑用NoSql)
Redis
Remote Dictionary Server远程字典系统
单线程的内存级别的NoSQL缓存数据库
非常之快(内存比硬盘快)
概述
-
Redis是一个开源的key-value存储系统。
-
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
-
这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
-
在此基础上,Redis支持各种不同方式的排序。
-
与memcached一样,为了保证效率,数据都是缓存在内存中。
-
区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
-
并且在此基础上实现了master-slave(主从)同步。
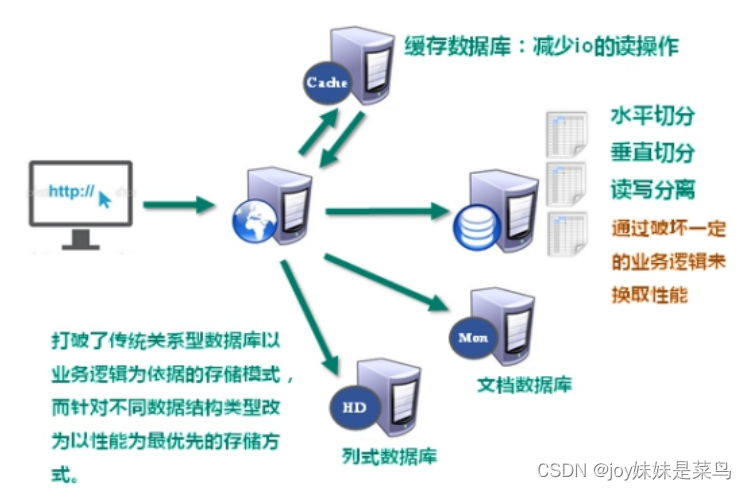
应用场景
配合关系型数据库做高速缓存
-
高频次,热门访问的数据,降低数据库IO
-
分布式架构,做session共享
多样的数据结构存储持久化数据
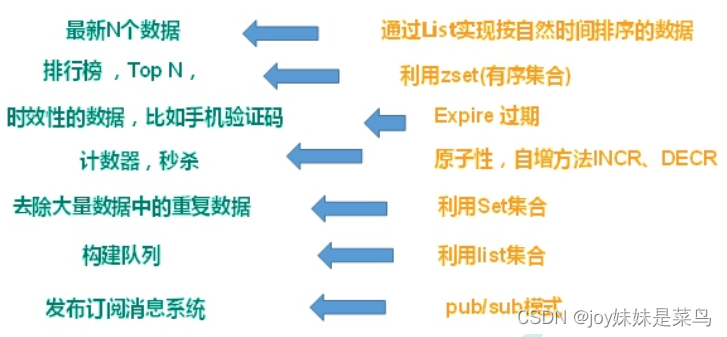
数据类型
(后继学习之后再补充)
- string
- list
- set
- hash
- Zset(带权set)
实例演示
不同服务器使用redis实现session同步(spring-session-redis)
未使用Redis
开启两个项目,controller层测试代码如下:
@RequestMapping("/test.do")
@ResponseBody
public ResultObject test(HttpSession session){
if (session.getAttribute("test")!=null){
System.out.println("exam server"+session.getAttribute("test"));
}else {
System.out.println("没有session");
session.setAttribute("test","this is exam server");
}
return ResultObject.ERROR("数据失败");
}
@RequestMapping("/test.do")
@ResponseBody
public ResultObject test(HttpSession session){
if (session.getAttribute("test")!=null){
System.out.println("springboot server"+session.getAttribute("test"));
}else {
System.out.println("没有session");
session.setAttribute("test","this is springboot server");
}
return ResultObject.ERROR("数据失败");
}
开启Nginx(任务管理器中会有两个nginx.exe)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fl67Gwgz-1659267161893)(C:\Users\pon18\AppData\Roaming\Typora\typora-user-images\image-20220731190232693.png)]](https://img-blog.csdnimg.cn/bff361f74c9d4c4982896d89d23fa54a.png)
启动两个项目(记得修改其中一个的端口号)
在地址栏中输入项目中方法的地址映射
(Nginx相关原理及操作见Nginx相关内容)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jQ9KJjgC-1659267161896)(C:\Users\pon18\AppData\Roaming\Typora\typora-user-images\image-20220731190040969.png)]](https://img-blog.csdnimg.cn/22c647ecf5ac4655af06624cf2c83296.png)
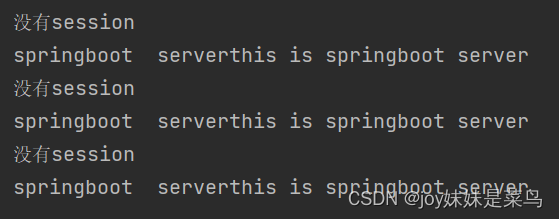
没有导入redis,启动两个项目时,他们的session会被切换,所以控制台中每次都会提示没有session
在项目中导入Redis

即添加两个依赖:redis和spring-session
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
在配置文件中引入
spring.session.store-type=redis
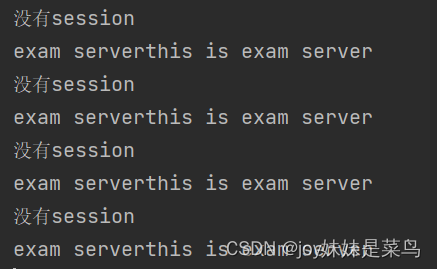
随后重新启动,并在浏览器中输入映射可以发现:
exam起初没有session,创建session后,exam保存的session可以在springboot server同步
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uSYxkL66-1659267161903)(C:\Users\pon18\AppData\Roaming\Typora\typora-user-images\image-20220731191840128.png)]](https://img-blog.csdnimg.cn/b61751fcd3dd4323bc888a9b9b22764c.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4mGIKtq2-1659267161904)(C:\Users\pon18\AppData\Roaming\Typora\typora-user-images\image-20220731191828615.png)]](https://img-blog.csdnimg.cn/4ff337a0a39f4f2ca6a119b16da2c533.png)
至此,我们通过redis缓存存储session,实现了用户的请求操作执行在不同的服务器上
补充:想要保存用户对象,就要实现序列化
要想反序列化出来要确保在同一个包下
所以,开发过程中,创建实体类都要序列化,对象序列化之后方能存入到redis缓存中
redis持久化
redis数据是放在内存中的,断电就没,我们要将数据放到硬盘里持久化
RDB
全表备份
放到dump RDB文件中
下次打开时原封不到放在redis中
概述
在指定的时间间隔内将内存中的数据集快照写入磁盘,它恢复时是将快照文件直接读到内存里
备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
命令save VS bgsave
save :save时只管保存,其它不管,全部阻塞(会锁)。手动保存。不建议。可用性×
bgsave:Redis会在后台异步进行快照操作, 快照同时还可以响应客户端请求。新写进来的内容无法备份 最终一致性×
可以通过lastsave 命令获取最后一次成功执行快照的时间
优势
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 恢复速度快
劣势
- Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。数据丢失风险大。
AOF
记录到aof文件中(记录的是命令)
恢复非常慢,因为要先执行aof文件中的命令
概述
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来**(读操作不记录**), 只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
(4)Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;
优势
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
劣势
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
- 存在个别Bug,造成恢复不能。
缓存遇到的问题及解决方案
缓存雪崩
大量缓存失效
缓存在同一时间内大量键过期(失效),一大波请求瞬间都落在了数据库中,导致连接异常
解决方案:
- 设置缓存永不失效
- 使用互斥锁排队
缓存击穿
缓存没有但数据库有数据
指缓存中没有但数据库中有的数据,一般是缓存时间到期,此时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库取数据,引起数据库压力瞬间增大
解决方案:
- 设置缓存永不失效
- 使用互斥锁排队
- 设置定时器,在缓存快失效时更新
缓存穿透
缓存和数据库都没有数据
缓存和数据库都没有的数据,而用户不断发起请求,这时的用户如果是攻击者,攻击会导致数据库压力过大
解决方案:
- 缓存空对象
- 布隆过滤器(推荐)
布隆过滤器的原理介绍
布隆过滤器可以确定此id不在我的id序列里
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。















 4146
4146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









