







第1关:从视图V_SPQ找出供应商S1的供应情况
三建工程项目视图V_SPQ由供应商代码(SNO)、零件代码(PNO)、供应数量(QTY)组成。 视图V_SPQ如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
SELECT PNO,QTY
FROM V_SPQ
WHERE SNO='S1'
########## End ##########第2关:定义查询S2供应商的所有供应明细的视图V_SPJ2
供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:
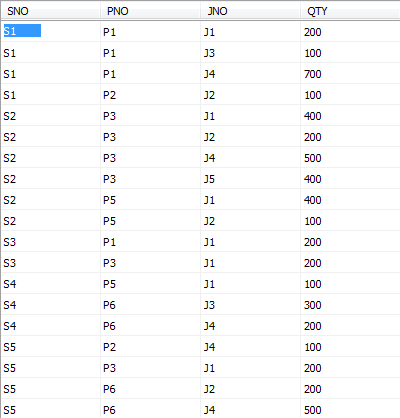
USE mydata;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW V_SPJ2
AS
SELECT * FROM SPJ
WHERE SNO='S2';
########## End ##########
#以下代码禁止删除
SELECT * FROM V_SPJ2;第3关:定义查询北京的供应商的编号、名称和城市的视图V_BJS
供应商表S由供应商代码(SNO)、供应商姓名(SNAME)、供应商状态(STATUS)、供应商所在城市(CITY)组成. S表如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW V_BJS
AS
SELECT SNO,SNAME,CITY
FROM S
WHERE CITY='北京';
########## End ##########
#以下代码禁止删除
SELECT * FROM V_BJS;第4关:定义查询各工程名称使用的各种颜色零件的个数的视图V_PJQ
零件表P由零件代码(PNO)、零件名(PNAME)、颜色(COLOR)、重量(WEIGHT)组成; P表如下图:

工程项目表J由工程项目代码(JNO)、工程项目名(JNAME)、工程项目所在城市(CITY)组成。 J表如下图:

供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW V_PJQ AS
SELECT JNAME,COLOR,SUM(QTY) AS SUM_QTY
FROM SPJ,P,J
WHERE SPJ.JNO=J.JNO AND SPJ.PNO=P.PNO
GROUP BY J.JNO,COLOR;
########## End ##########
#以下代码禁止删除
SELECT * FROM V_PJQ ORDER BY V_PJQ.JNAME ASC, V_PJQ.COLOR ASC;第5关:将视图V_SPQ中供应数量为400的供应商改为'S1',并观察基本表SPJ的变化
三建工程项目视图V_SPQ由供应商代码(SNO)、零件代码(PNO)、供应数量(QTY)组成并由基本表J,SPJ构建。 视图V_SPQ如下图:
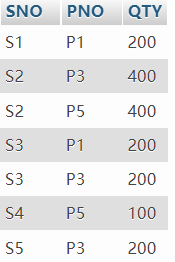
工程项目表J由工程项目代码(JNO)、工程项目名(JNAME)、工程项目所在城市(CITY)组成。 J表如下图:

供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:
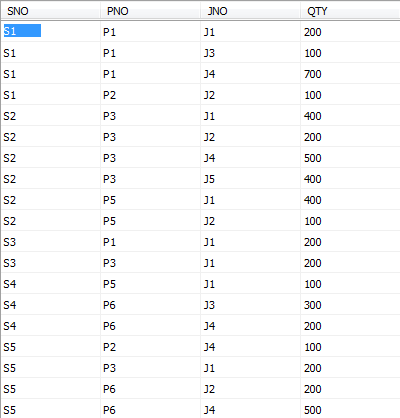
USE mydata;
#请在此处添加实现代码
########## Begin ##########
UPDATE V_SPQ
SET SNO='S1'
WHERE QTY=400;
########## End ##########
#以下代码禁止删除
SELECT * FROM SPJ;第6关:建立比赛 1001 的所有解答的视图v_1001,并要求进行修改和插入操作时仍需保证该视图只有比赛1001的解答。
solution为选手提交的题目解答 solution表如下图(仅显示前几条):
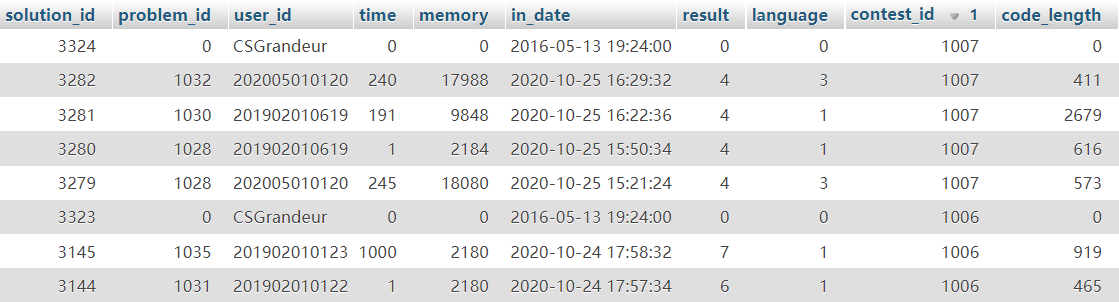
USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW v_1001 AS
SELECT* FROM solution
WHERE contest_id='1001' WITH CHECK OPTION;
########## End ##########
#保证下面一行MYSQL语句在16行的位置,以保证结果匹配
UPDATE v_1001 SET v_1001.contest_id = 1002;第7关:建立2020级做了1003号题的选手视图v_user2020_1003(包括user_id、name、result),注意user_id、name、result构成的记录去重。
users为选手信息表; users表如下图(仅显示前几条):

solution为选手提交的题目解答 solution表如下图(仅显示前几条):

USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW v_user2020_1003 AS
SELECT distinct solution.user_id,name,result
FROM users,solution
WHERE solution.user_id=users.user_id AND solution.user_id LIKE '2020%' AND solution.problem_id=1003;
########## End ##########
#以下代码禁止删除
SELECT * FROM v_user2020_1003;第8关:建立2020级做了1001号题且result为6的选手视图v_user2020_1001_6,包括user_id、name、result、problem_id,且按user_id升序排序,注意user_id、name、result、problem_id构成的记录去重。
users为选手信息表; users表如下图(仅显示前几条):

solution为选手提交的题目解答 solution表如下图(仅显示前几条):
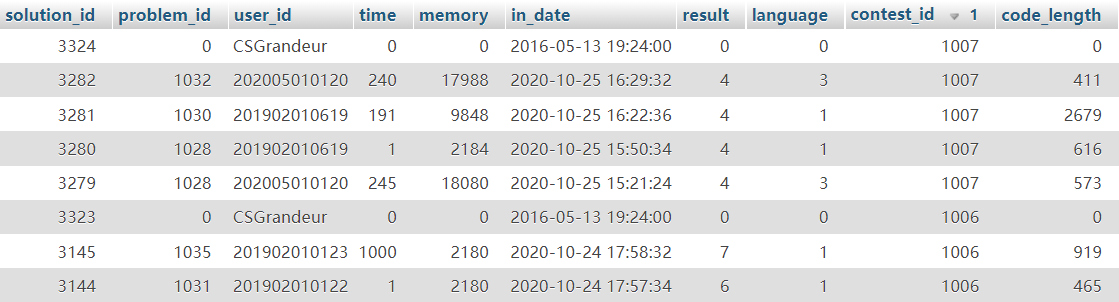
USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW v_user2020_1001_6 AS
SELECT distinct users.user_id,name,result,problem_id
FROM users,solution
WHERE users.user_id=solution.user_id and users.user_id LIKE '2020%' and problem_id='1001' and solution.result=6
ORDER BY user_id ASC;
########## End ##########
#以下代码禁止删除
SELECT * FROM v_user2020_1001_6;第9关:将选手的user_id及解答的平均avgmemory定义为一个视图v_users_avgmemory
solution为选手提交的题目解答 solution表如下图(仅显示前几条):

USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
CREATE VIEW v_users_avgmemory(user_id,avgmemory) AS
SELECT user_id,AVG(memory) as 'avgmemory'
FROM solution
GROUP BY user_id;
########## End ##########
SELECT * FROM v_users_avgmemory;第10关:删除视图v_1001
视图v_1001为比赛 1001 的所有解答。 视图v_1001如下图(仅显示前几条):

USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
DROP VIEW IF EXISTS v_1001;
########## End ##########
#保证下面一行MYSQL语句在9行的位置,以保证结果匹配
SELECT v_1001.* FROM v_1001;第11关:在视图v_users_avgmemory中查询avgmemory在2000以下的user_id及avgmemory
视图v_users_avgmemory为选手的user_id及解答的平均avgmemory。 视图v_users_avgmemory如下图(仅显示前几条):
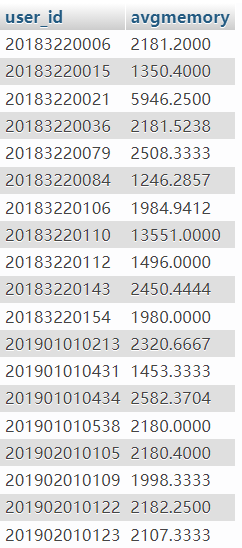
USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
SELECT user_id,avgmemory
FROM v_users_avgmemory
WHERE avgmemory<2000;
########## End ##########第12关:在视图v_1001中删除user_id为201902010318的记录
视图v_1001为比赛 1001 的所有解答。 视图v_1001如下图(仅显示前几条):

USE `sqlexp-sztuoj`;
#请在此处添加实现代码
########## Begin ##########
DELETE FROM v_1001 WHERE user_id='201902010318';
########## End ##########
#以下代码禁止删除
SELECT * FROM v_1001;第13关:在视图v_users_avgmemory中插入一条记录(2020100904,1800),并分析结果。
视图v_users_avgmemory为选手的user_id及解答的平均mavgmemory。 视图v_users_avgmemory如下图(仅显示前几条):

USE `sqlexp-sztuoj`;
#请在第5行开始添加实现代码,务必保证从第5行开始添加代码,以保证结果匹配
########## Begin ##########
INSERT INTO v_users_avgmemory values(2020100904,1800);
########## End ##########第14关:在视图v_user2020_1003中将user_id为20200202的result更改为10
视图v_user2020_1003为2020级做了1003号题的选手视图。 视图v_user2020_1003如下图(仅显示前几条):

USE `sqlexp-sztuoj`;
########## Begin ##########
update v_user2020_1003
set result=10
where user_id=20200202;
########## End ##########
#以下代码禁止删除
SELECT v_user2020_1003.* FROM v_user2020_1003 WHERE v_user2020_1003.user_id = '20200202';第15关:找出工程项目J1使用的各种零件的名称及其数量(SUM_QTY),查询结果按数量降序排序。
零件表P由零件代码(PNO)、零件名(PNAME)、颜色(COLOR)、重量(WEIGHT)组成; P表如下图:

供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
select distinct PNAME,SUM(QTY) AS SUM_QTY
FROM P,SPJ
WHERE SPJ.PNO=P.PNO AND SPJ.JNO='J1'
GROUP BY PNAME
ORDER BY SUM_QTY DESC;
########## End ##########第16关:求使用了300个及以上P1零件的工程名称
工程项目表J由工程项目代码(JNO)、工程项目名(JNAME)、工程项目所在城市(CITY)组成。 J表如下图:

供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
SELECT DISTINCT JNAME
FROM J,SPJ
WHERE J.JNO=SPJ.JNO AND PNO='P1' AND J.JNO IN(
SELECT JNO
FROM SPJ
GROUP BY PNO,JNO HAVING SUM(QTY)>300
)
########## End ##########第17关:求各工程(名)使用的各城市供应的零件总数,结果先按工程名降序排序,再按城市名降序排序。
供应商表S由供应商代码(SNO)、供应商姓名(SNAME)、供应商状态(STATUS)、供应商所在城市(CITY)组成. S表如下图:
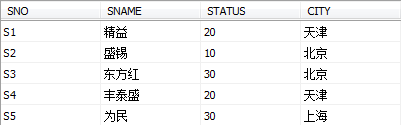
工程项目表J由工程项目代码(JNO)、工程项目名(JNAME)、工程项目所在城市(CITY)组成。 J表如下图:

供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
SELECT JNAME,S.CITY,SUM(QTY) AS SUM_QTY
FROM SPJ,J,S
WHERE SPJ.JNO=J.JNO AND SPJ.SNO=S.SNO
GROUP BY J.JNO,S.CITY
ORDER BY JNAME DESC ,CITY DESC;
########## End ##########第18关:查询这样的工程号:供应该工程零件P1的平均供应量,不小于工程J1使用各零件合计数量的最大值.
供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:
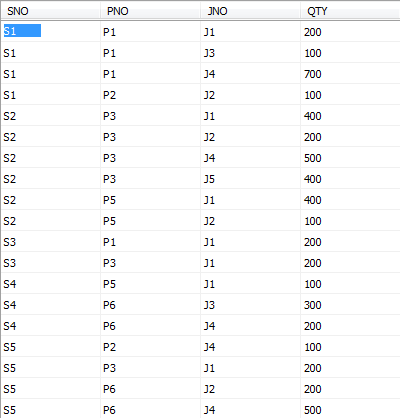
USE mydata;
#请在此处添加实现代码
########## Begin ##########
select x1.JNO
from SPJ x1
where (
select AVG(xx.QTY)
from SPJ xx
where xx.sno='p1'
)>=(
select MAX(x3.max_sum)
from (
select sum(QTY) as max_sum
from SPJ x2
where x2.JNO='J1'
GROUP BY x2.PNO
)as x3
)
########## End ##########第19关:求至少用了供应商 S1所供应的全部零件的工程号 JNO
供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:

USE mydata;
#请在此处添加实现代码
########## Begin ##########
select distinct JNO
from SPJ
where not exists(
select *
from SPJ SS
where SS.SNO='S1' AND NOT exists(
select SSS.PNO
from SPJ SSS
where SSS.JNO=SPJ.JNO and SSS.PNO=SS.PNO
)
)
########## End ##########















 2411
2411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











