







目录
1.4 文本可视化的流程
1 文本数据在大数据中的应用
1.1 文本可视化的实现工具——词云
•自动的从文本中提取频繁出现的词语
•以特定的布局直观地呈现这些词语
1.2 文本可视化的意义
•帮助用户快速的完成大量文本阅读和理解,并从中获取重要的信息
1.3 文本的理解需求与对应算法
自然语言处理(NLP):研究人与计算机交互的语言问题
Python自然语言处理工具库:spaCy、PyNLPl、Pattern…
1.4 文本可视化的流程
(1)文本信息挖掘—文本数据的预处理、文本特征的抽取、文本特征的度量
(2)视图绘制—图元设计、图元布局
(3)人机交互
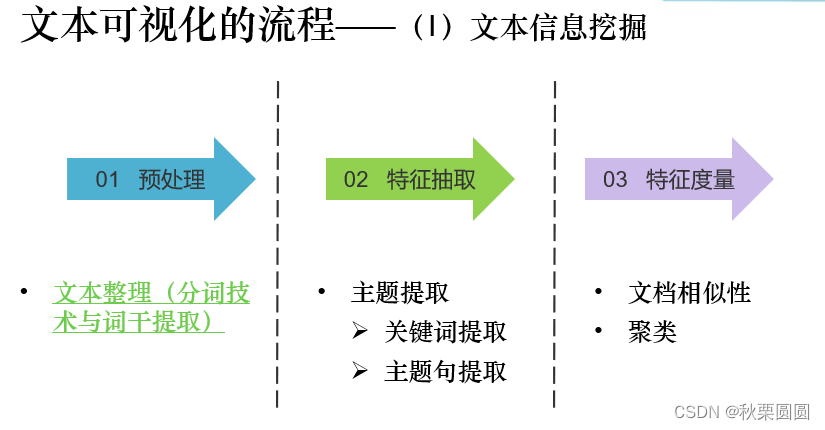
文本信息挖掘——01 预处理
分词技术和词干提取
分词技术和词干提取方法通常用于文本数据的预处理
分词:将一段文字划分为多个词项,剔除停词,从文中提取有意义的词项
词干提取:去除词缀得到词根,得到单词最一般写法的技术,避免了同一个词的不同表现形式对文本分析的干扰
文本信息挖掘——02 特征抽取
将文本转换为特征、并将其向量化
关键词提取算法:TF-IDF(词频-逆向文件频率)法
TF原理:反映出目标词语在某一篇文章中的重要性
分子:目标词语在文档中出现的次数;分母:文档中所有词语数
IDF原理:包含目标词语w的文档越少,IDF越大,词语w在整个文本集中的类别区分能力越大
IDF=log10( N / Df(w) )
N:文档总数;Df(w):包含词语w的文档数量+1
TF-IDF计算方法:TF-IDF = TF × IDF
TF-IDF主要思想:
Ø如果某个词或者短语在一篇文章中出现的次数多,同时在其他文章中出现的次数少,则说明这个词或短语能直观的刻画出这篇文章;Ø可以用TF-IDF较大的词作为关键词,实现文本进行
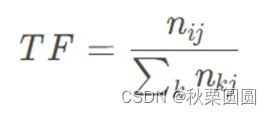
文本信息挖掘——03 特征度量
在多种环境或多个数据源所抽取的文本特征进行深层分析
Ø ( 1 )相似性度量:衡量两个文本的相似度,算法有欧氏距离、余弦距离、最小编辑距离等Ø ( 2 )文本聚类:根据同类文档相似度较大、不同类文档相似度较小这一特征进行文档分组
2 文本内容可视化
(1)关键词可视化
(2)时序文本可视化
(3)文本特征分布可视化
3 文本关系可视化
3.1 文本关系可视化的概念
•
研究文本或文档集合中的关系信息
•
比如:文本的相似性、互相引用的情况、链接
•
关系布局,一般都是树或图
•
分类:
Ø
(
1
)文本内容关系可视化
Ø
(
2
)文档集合关系可视化
3.2 文本内容关系可视化
词语树(Word Tree)
•
把文本中的句子按树形结构布局
•
字体大小反映单词在文本中出现的频率
•
树形结构反映单词前后的联系
短语网络(Phrase Nets)
•
由节点和边组成
•
节点:从文本中挖掘出的词汇级或语法级的语义单元
•
颜色代表词性
•
边代表语义单元的联系
•
边的方向即短语的方向
•
边的宽度是短语在文本中出现的频率
3.3 文档集合关系可视化
•定义每个文档的特征向量
• 利用向量空间模型计算文档间的相似性• 采用相应的投影技术呈现文档集合的关系• 可视化方法:Ø 星系图( Galaxy View )Ø 主题地貌( ThemeScape )


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









