







Hadoop入门
1. 了解Hadoop
1.1 Hadoop 的优势(4高)
高可靠性:存在多个数据副本,即使某个元素或存储出现故障,也不会导致数据的丢失
高拓展性:在集群见分配任务数据,可方便的拓展数以千计的节点
高效性:Hadoop是并行工作的,以加快任务的处理速度
高容错性:能够自动将失败的任务重新分配
1.2 Hadoop的组成
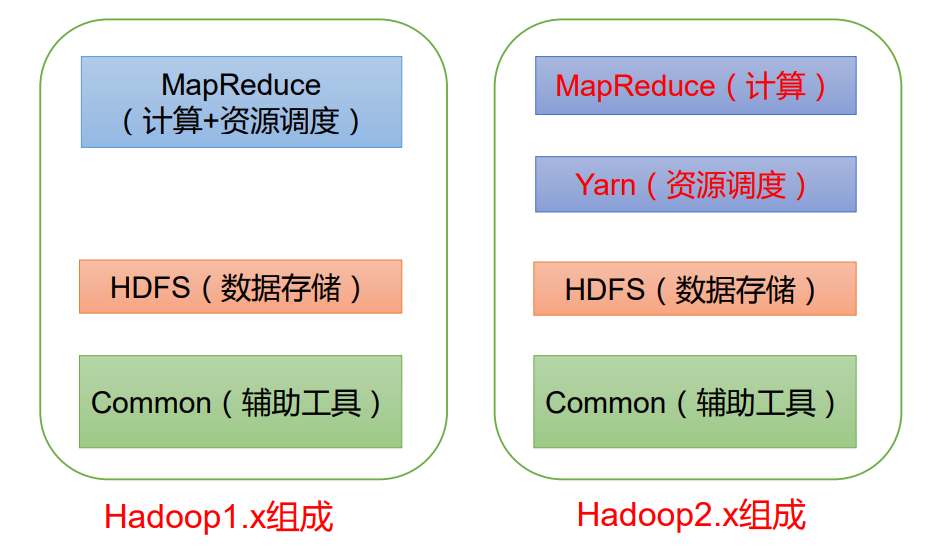
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑和资源的调度,耦合度比较大
在Hadoop2.x时代,Hadoop增加了Yarn,Yarn只负责资源的调度,MapReduce只负责运算。
Hadoop3.x时代在组成上没有发生变化。
1.3HDFS架构
什么是HDFS?
HDFS是Hadoop DIstributed File System 的简称,是一个分布式文件系统
HDFS简述
NameNode(nn):
存储文件中的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
DateNode (dn)
在本地文件系统存储文件块数据,以及块数据的校验和
Secondary NameNode(2nn)
每隔一段时间对Name Node原数据进行备份
YARN概述
Yet Another Resource Negotiator简称YARN,是资源协调者,是Hadoop的资源管理器
ResourceManager(RM)
整个集群资源(CPU、内存等)的老大
NodeManager(NM)
单个节点服务器资源的老大
ApplicationMaster(AM)
单个任务运行的老大
Container
容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等
客户端可以存在多个
集群上可以运行多个ApplicationMaster
每个NodeMangager 可以有多个Container
MapReduce
MapReduce将运算过程分为两个阶段
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
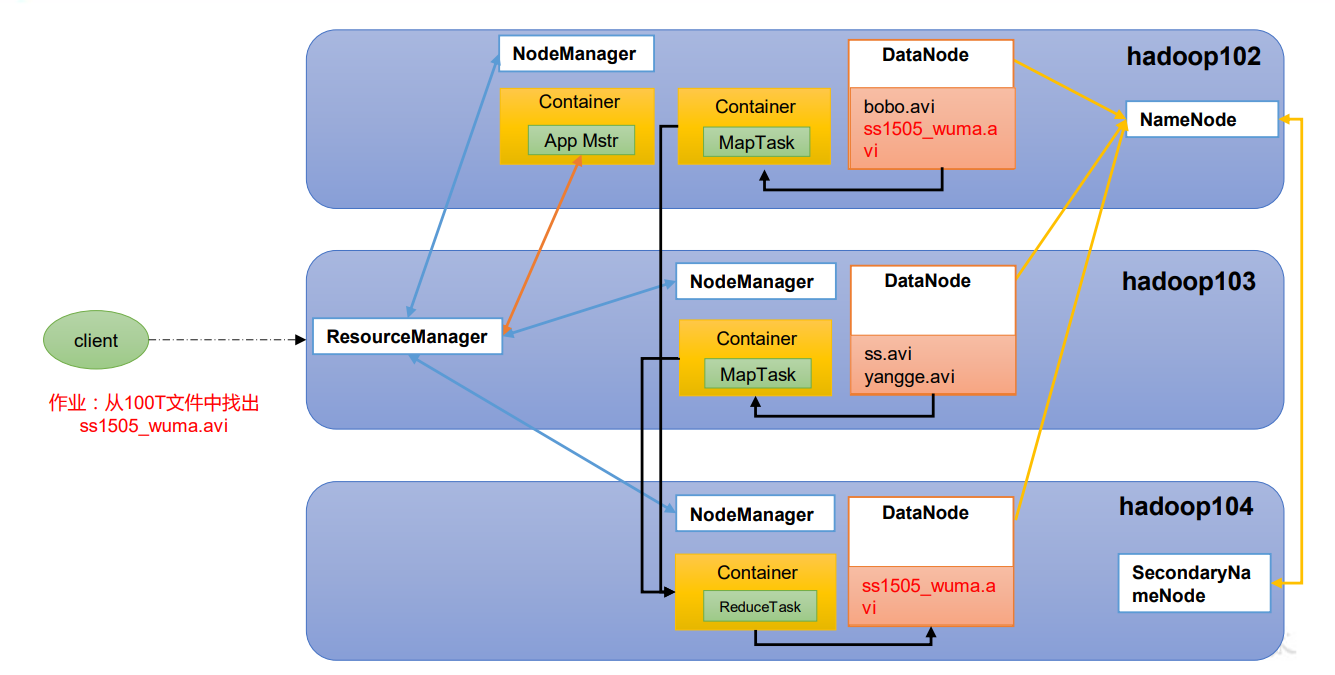
HDFS YARN MapReduce三者之间的关系
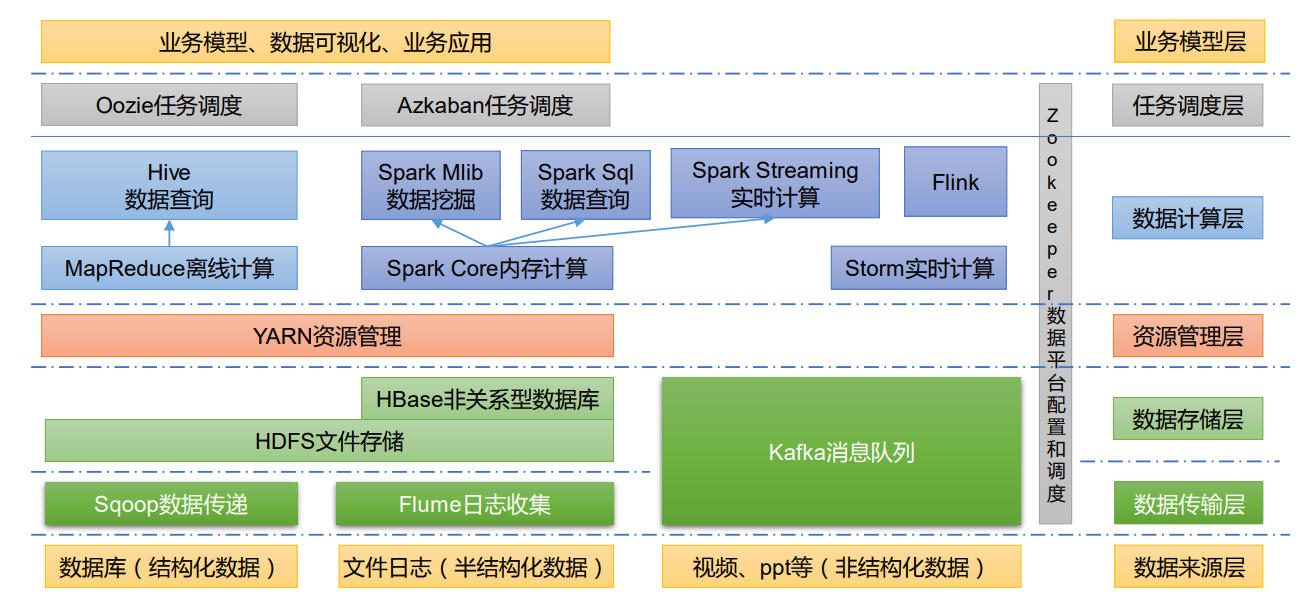
大数据技术生态体系
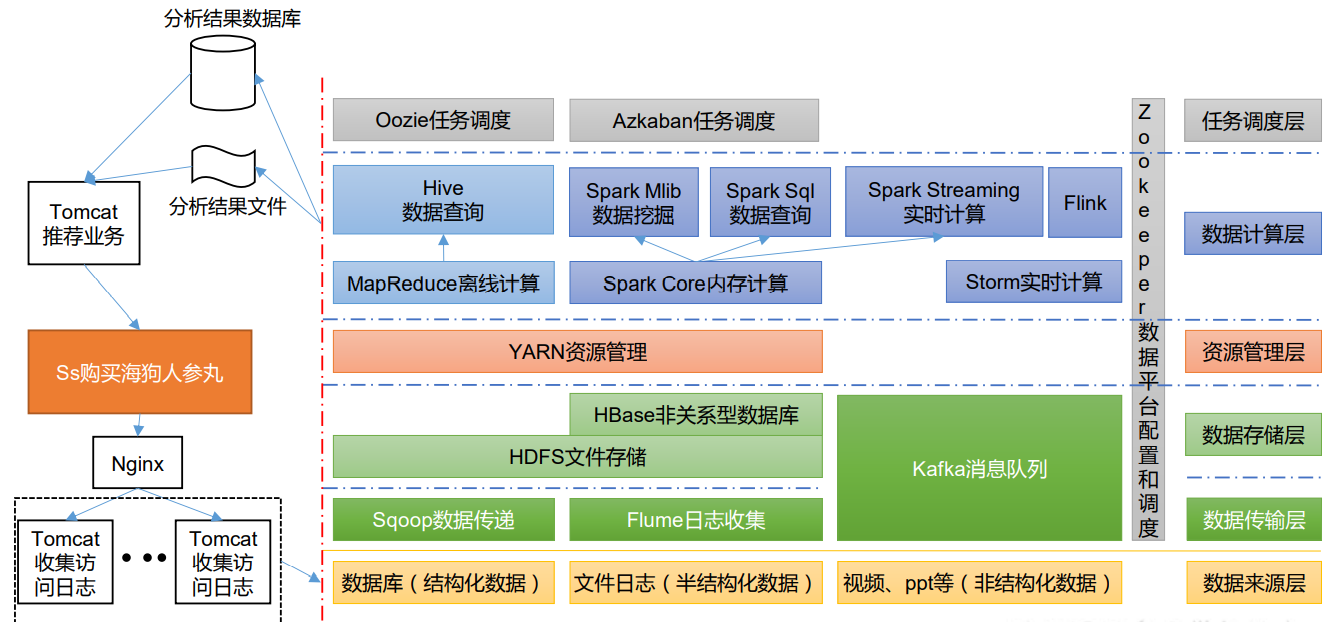
框架图:
Hadoop集群环境的安装
集群角色的规划
规划准则
根据软件工作特性和服务器硬件资源情况合理分配
角色规划注意事项
资源上有争抢夺冲突的,尽量不要部署在一起。
工作上需要相互配合的,尽量部署在一起。
安装JDK
由于是最小安装,所以不在带openJDK,只能自己安装。
将jdk拖入到服务器进行解压,随后配置环境变量如下:
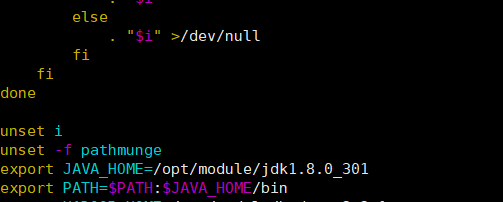
随后输入使得文件重新加载。
source /etc/profile
输入Javac 查看是否安装成功
显然安装成功。
安装Hadoop
下载Hadoop 然后进行解压,这里是解压到了opt/module下,解压后进入到其路径下,获取路径

随后配置环境变量:
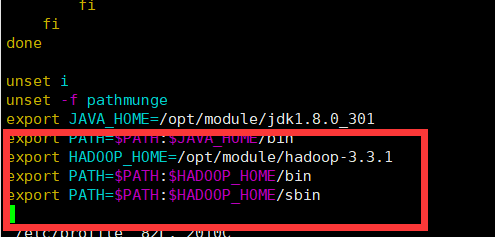
重新加载,随后进行检查:
hadoop version
运行结果如下:

显然已经安装成功。若搭配集群,操作方法相同。
配置免密登录
配置免密登录需要安装ssh,这里由于是提前安装好的,就不再进行安装。由于我实在root用户下进行操作的,所以某些操作可能不同
进入到/root/.ssh下
生成公钥、私钥:
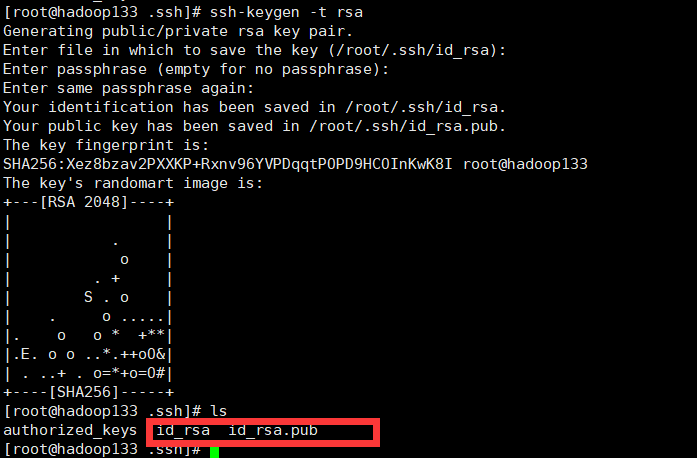
在这个过程中需要连点三个回车。随后需要将公钥交给免密登录的目标机器上,由于是集群,这里一共有四个hadoop132 ~ hadoop-135,其中将hadoop132作为父节点,加上了-father 即hadoop132-father
开始进行拷贝。
ssh-copy-id hadoop132-father
ssh-copy-id hadoop133
ssh-copy-id hadoop134
ssh-copy-id hadoop135
集群的角色划分
| 服务器 | 运行角色 |
|---|---|
| hadoop132-father | namenode datanode resourcemanager nodemanager |
| hadoop133 | secondarynamenode datanode nodemanager |
| hadoop134 | datanode nodemanager |
配置文件
配置文件主要在hadoop目录下的etc/hadoop/文件下
配置hadoop-env.sh
文件路径在 HADOOP_HOME下的etc/hadoop
配置文件如下:
export JAVA_HOME=/opt/module/jdk1.8.0_301
export HADOOP_HOME=/opt/module/hadoop-3.3.1
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置core-site.xml
core-site.xml是hadoop的核心配置文件,但是这是可以进行自定义的,默认配置文件为core-default.xml.
core-default.xml喝core-site.xml的功能是一样的,如果在core-site.xml中没有配置属性,那么就会自动获取core-default.xml文件中的相同属性的值
我们编写配置文件
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop132-father:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
配置hdfs-site.xml文件
HDFS的核心配置文件,主要配置HDFS的相关参数,默认配置选项为hdfs-default.xml
配置如下:
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop133:9868</value>
</property>
修改mapred-site.xml
MapReduce的核心配置文件
配置如下:
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
修改YARN核心配置文件
核心文件为:yarn-site.xml
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop132-father</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
修改workers
workers主要记录的集群的主机名,一半有以下两个作用:
- 配合一键启动脚本如
start-dfs.sh进行集群的启动。这时候slaver文件里面的主机标记的就是从节点角色所在的机器 - 可以配合
hdfs-site.xml里面的dfs.hosts属性形成一种白名单机制。dfs.hosts指定一个文件,其中包括允许连接到NameNode的主机列表。必须指定文件的完整路径名,那么所有在workers中的主机才可以加入集群。如果为空,表示允许所有集群
配置如下:
hadoop132-father
hadoop133
hadoop134
同步配置
采用的是rsync命令,因为hadoop都是安装好的,所以只需要对修改文件进行一个配置即可。
rsync -av hadoop/ root@hadoop134:/opt/module/hadoop-3.3.1/etc/hadoop/
rsync -av hadoop/ root@hadoop133:/opt/module/hadoop-3.3.1/etc/hadoop/
NameNode format(格式化)操作
本质上时进行一个初始化。首次启动HDFS是必须进行此操作
format本质上是初始化工作,进行HDFS清理和准备工作
命令:hdfs namenode -format
注意:
- 首次启动之前需要进行format操作
- format操作只能执行一次,后续不再进行操作
- 如果多次format出了造成数据丢失外,也会造成hdfs集群主从角色互不识别,通过删除所有机器的hadoop.tmp.dir目录 并重新format进行解决

如果出现了这个就表示格式化成功,或者说初始化成功
启动集群
Hadoop 集群存在两种启动方式:
- 手动单个启动
- 集群启动
手动单个启动
- 缺点:废人
- 优点: 精确,可以用于排除故障
HDFS集群
hdfs -daemon start namenode|datanode|secondarynamenode
hdfs -daemon stop namenode|datanode|secondarynamenode
YARN集群
yarn -daemon start resourcemanager|nodemanager
yarn -daemon stop resourcemanager|nodemanager
案例:
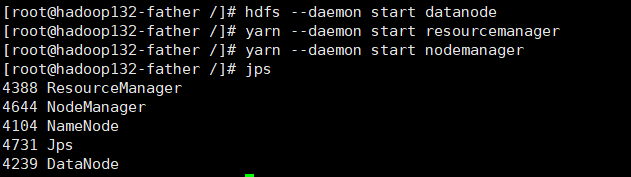
一键操作
可以通过hadoop提供的shell脚本进行一键启动关闭
前提 配置好了免密登录和workers文件
HDFS集群:
start-dfs.sh
stop-dfs.sh
YARN集群
start-yarn.sh
stop-yarn.sh
直接启动hadoop集群
start-all.sh
stop-all.sh
启动测试
father节点:
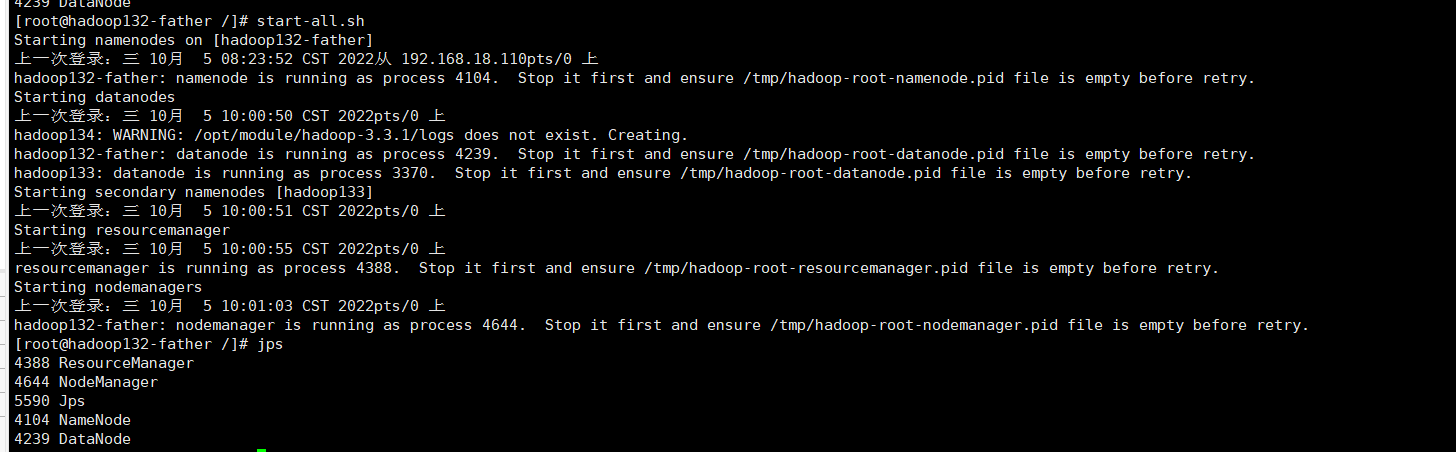
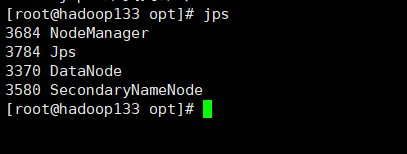
hadoop133节点
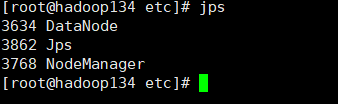
hadoop134节点:
访问UI页面:
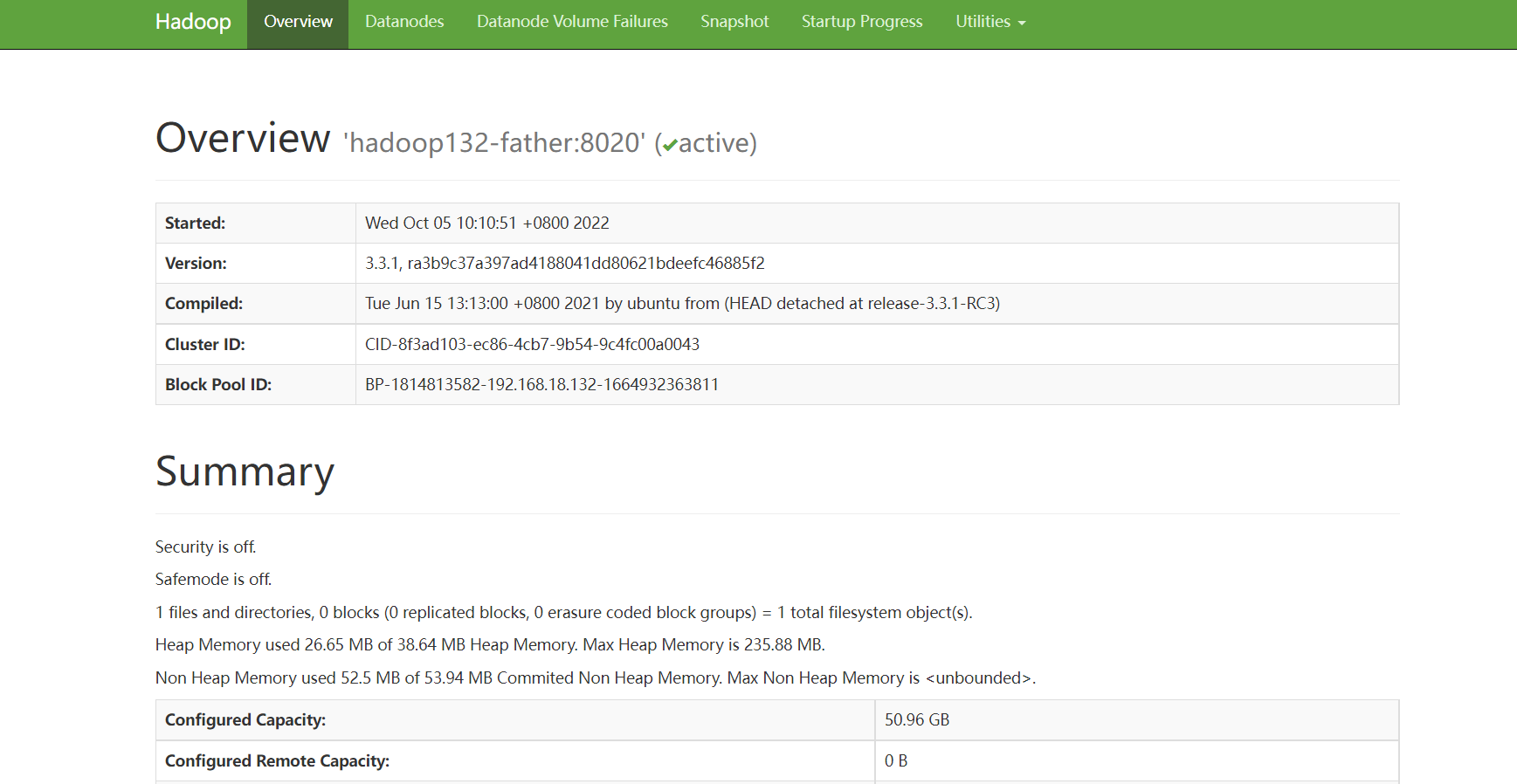
HDFS UI页面
hadoop132-father:9870
页面如下:
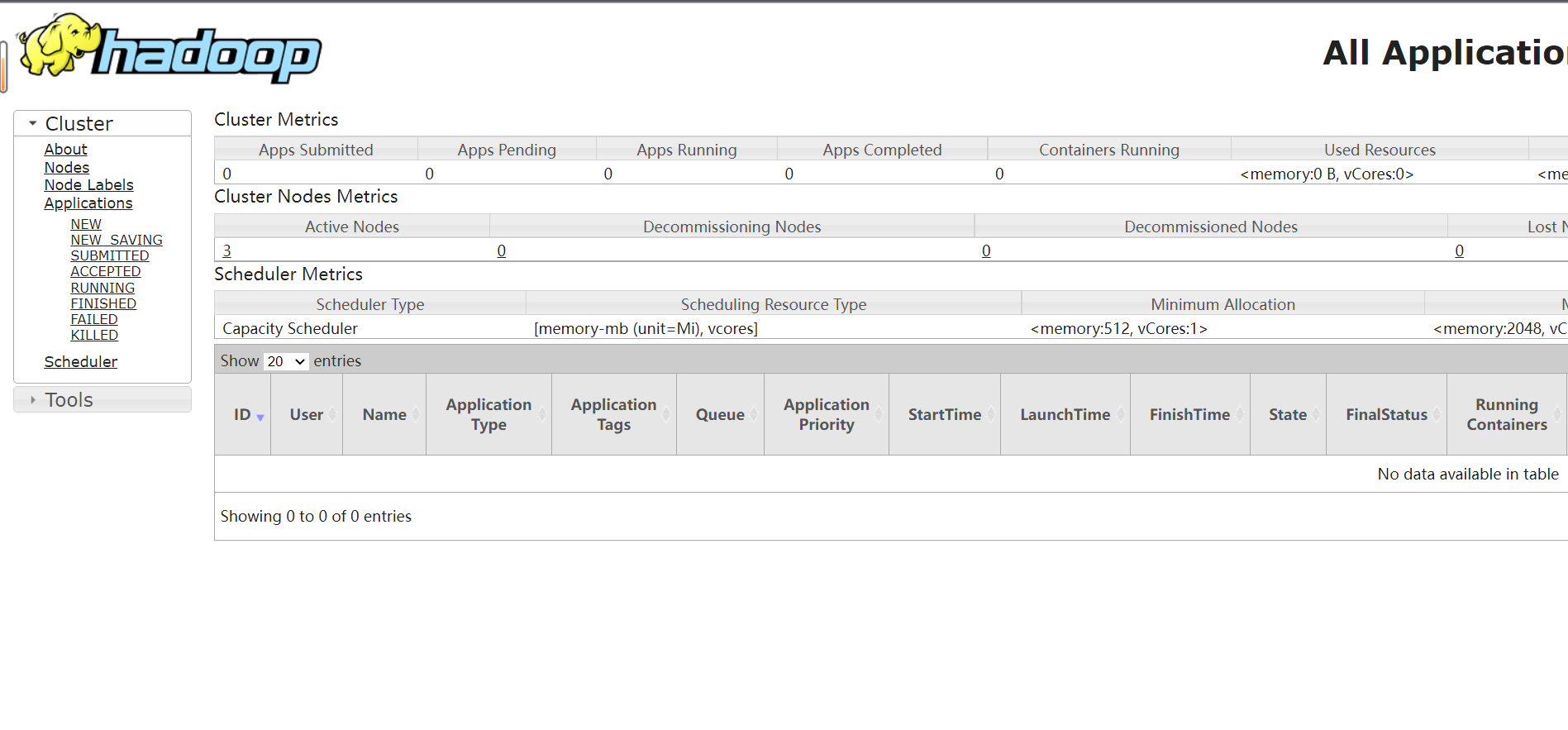
YARN UI页面:
hadoop132-father:8088
页面如下:
测试是否成功:
上传文件进行尝试:
将这个hadoop的压缩包进行一个上传
上传指令:
hadoop fs -put hadoop-3.3.1.tar.gz /w















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









