






3种Flink State Backend | 你该用哪个?
本文主要讲述Flink有状态的流处理中所提供的各种状态后端(state backend) 。 本文将介绍Flink当前所提供的3种状态后端的优缺点以及在具体需求案例中如何去做选择。
在有状态的流处理(stateful-steam-processing)中,为了发生故障时能够完全恢复故障前的数据, 开发者通常会在使用Flink时设置checkpoint。在使用checkpoint时候,通常要涉及到状态后端的选择以决定持久化的状态的存储方式与位置。
Flink 当前提供了以下3种开箱即用的状态后端:
MemoryStateBackend
FsStateBackend
RocksDBStateBackend
在缺省情况下,Flink默认使用 MemoryStateBackend。
首先上结论:
不同 State backend 吞吐量对比
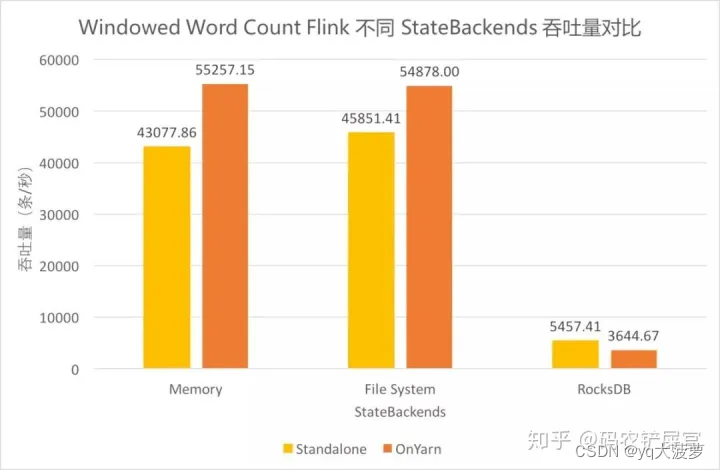
使用 FileSystem(FsStateBackend) 和 Memory (MemoryStateBackend)的吞吐差异不大(都是使用TaskManager堆内存管理处理中的数据),使用 RocksDB 的吞吐差距明显。
Standalone 和 on Yarn 的总体差异不大,使用 FileSystem 和 Memory 时 on Yarn 模式下吞吐稍高,而使用 RocksDB 时 on Yarn 模式下的吞吐低些。
不同 State backend 延迟对比

使用 FileSystem 和 Memory 时延迟基本一致且较低。
使用 RocksDB 时延迟稍高,且由于吞吐较低,在达到吞吐瓶颈附近延迟陡增。其中 on Yarn 模式下吞吐更低,延迟变化更加明显。
State backend 的选择
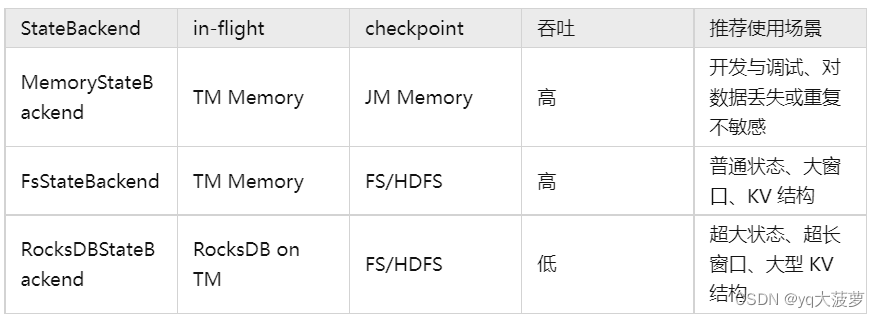
下面逐一介绍Flink的各个状态后端
MemoryStateBackend
MemoryStateBackend将内部的数据存储在java堆上。
当进行checkpoint时,状态后端会对当前的状态进行快照并将其作为checkpoint ACK消息的一部分发送给JobManager, 该JobManager同样将其存储存储在它的堆上。
MemoryStateBackend的四个构造函数如下:
public MemoryStateBackend() {
this(5242880);
}
public MemoryStateBackend(int maxStateSize) {
this(maxStateSize, true);
}
public MemoryStateBackend(boolean asynchronousSnapshots) {
this(5242880, asynchronousSnapshots);
}
public MemoryStateBackend(int maxStateSize, boolean asynchronousSnapshots) {
this.maxStateSize = maxStateSize;
this.asynchronousSnapshots = asynchronousSnapshots;
}
MemoryStateBackend可以采用异步的方式进行快照。异步快照作为一个新的特性可以避免主数据处理流程的堵塞,值得注意的是,默认情况下Flink在该状态后端下是关闭异步快照的,如需打开,可以在初始化该状态后端时将构造方法中的对应参数值设置为true, 如下所示:
new MemoryStateBackend(MAX_MEM_STATE_SIZE, true);
MemoryStateBackend的局限性:
最大的单个状态不能超过akka帧的大小,即默认情况下最大为5MB(该值可以通过其构造函数进行配置)
聚合的状态必须能够在JobManager内存中存放下。
MemoryStateBackend适合在如下场景中使用:
本地开发和调试
一些占用状态很小的任务,如Flink中只包含record-at-a-time算子如(Map,FlatMap,Filter,…) 组成的任务。另外Kafka消费者只需要非常小的状态。
FsStateBackend
在使用FsStateBackend 前,需要配置状态存储的文件系统,格式通常为URL(类型,地址,路径)。
可以是hdfs路径:
hdfs://namenode:40010/flink/config_checkpoints
也可以是文件系统路径:
file:///data/flink/checkpoints
FsStateBackend 中流计算的数据状态会被存在 TaskManager 的内存中。在 checkpoint 时,此后端会将状态快照写入配置的文件系统和目录的文件中,同时会在 JobManager 的内存中(在高可用场景下会存在 Zookeeper 中)存储极少的元数据。
FsStateBackend 的三种构造函数如下:
public FsStateBackend(String checkpointDataUri, boolean asynchronousSnapshots) throws IOException {
this(new Path(checkpointDataUri), asynchronousSnapshots);
}
public FsStateBackend(Path checkpointDataUri, boolean asynchronousSnapshots) throws IOException {
this(checkpointDataUri.toUri(), asynchronousSnapshots);
}
//fileStateSizeThreshold默认1024
public FsStateBackend(URI checkpointDataUri, int fileStateSizeThreshold, boolean asynchronousSnapshots) throws IOException {
Preconditions.checkArgument(fileStateSizeThreshold >= 0, “The threshold for file state size must be zero or larger.”);
Preconditions.checkArgument(fileStateSizeThreshold <= 1048576, “The threshold for file state size cannot be larger than %s”, new Object[]{1048576});
this.fileStateThreshold = fileStateSizeThreshold;
this.basePath = validateAndNormalizeUri(checkpointDataUri);
this.asynchronousSnapshots = asynchronousSnapshots;
}
Flink的默认配置中,FsStateBackend 在进行快照时候采用异步方式,避免在状态进行checkpoint 时阻塞主数据流的处理流程。
使用 FsStateBackend 时有如下几点需要注意:
由于带备份的状态先会存在 TaskManager 中,故状态的大小不能超过 TaskManager 的内存,以免发生OOM。
使用FsStateBackend的场景如下:
FsStateBackend 适用于处理大状态,长窗口,或大键值状态的有状态处理任务。
FsStateBackend 比较适合用于高可用方案。
可以在生产环境中使用。
RocksDBStateBackend
在配置RocksDBStateBackend 时同样需要一个文件系统URL(类型,地址,路径),如下所示:
hdfs://namenode:40010/flink/checkpoints
或
file:///data/flink/checkpoints
RocksDBStateBackend 将处理中的数据使用 RocksDB 存储在本地磁盘上。在 checkpoint 时,整个 RocksDB 数据库会被存储到配置的文件系统中,或者在超大状态作业时可以将增量的数据存储到配置的文件系统中。同时 Flink 会将极少的元数据存储在 JobManager 的内存中,或者在 Zookeeper 中(对于高可用的情况)。
RocksDB是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意RocksDB不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。不过RocksDB支持增量的 Checkpoint,也是目前唯一增量 Checkpoint 的 Backend,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单Key最大2G,总大小不超过配置的文件系统容量即可。
使用 RocksDBStateBackend 时有如下几点需要注意:
由于RocksDB的JNI API 是基于byte[] 的, 故 RocksDB 支持的单 key 和单 value 的大小不能超过 2^31 字节。
对于使用具有合并操作的状态的应用程序,例如 ListState,随着时间可能会累积到超过 2^31 字节大小,这将会导致在接下来的查询中失败。
使用 RocksDBStateBackend的场景如下:
RocksDBStateBackend 最适合用于处理大状态,长窗口,或大键值状态的有状态处理任务。
RocksDBStateBackend 非常适合用于高可用(HA)方案。
RocksDBStateBackend 是目前唯一支持增量 checkpoint 的后端。增量 checkpoint 非常适用于超大状态的场景。
最好是对状态读写性能要求不高的作业。
当使用 RocksDB 时,状态大小只受限于TaskManager的磁盘可用空间的大小。这也使得 RocksDBStateBackend 成为管理超大状态的最佳选择。使用 RocksDB 的权衡点在于所有的状态相关的操作都需要序列化(或反序列化)才能跨越 JNI 边界。与上面提到的堆上后端相比,这可能会影响应用程序的吞吐量。















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









