







#本博客是参加上海人工智能实验室OPENMMLAB大模型实战营活动而作
一、背景
当下大模型已经成为发展通用人工智能的重要途径。
以往的人工智能发展大多为专用性人工智能,自2006年深度学习理论完成突破后,无论是2012年的ImageNet,抑或是14年LFW人脸识别上99%超越人类的识别准确率,抑或是2016年的AlphaGo 4:1李世石的围棋比赛,都是优秀的专用型人工智能的代表。然而随着实际问题需求的改变与增长,人们迫切的需要一个任务应对多种模态,通用大模型应运而生。
上海人工智能实验室也是投入了非常大的力量在大语言模型上:(图源侵删)

二、书生·浦语大模型的介绍
到现在为止,书生浦语大模型可分为三个系列:
- 轻量级,InternLM-7B,70亿参数,小巧轻便便于部署
- 中量级,InternLM-20B,200亿参数,在模型与推理之间取得平衡
- 重量级, InternLM-123B,1230亿参数,性能强大
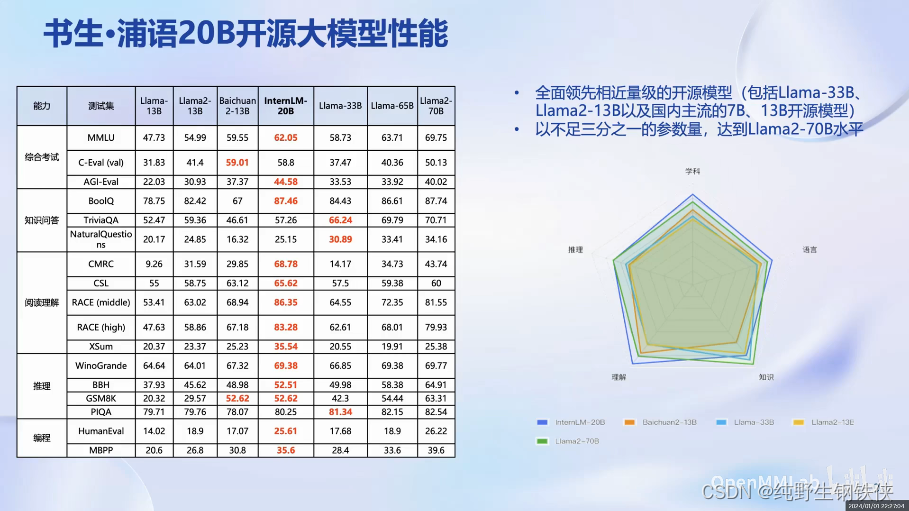
InternLM-20B在多维度上都有着比较优异的表现(见上图)
任何一个模型从研发出来到实际部署应用,都需要经过比较多的迭代步骤与环节,为此书生·浦语开放了全链条开放体系。

除了上述开源链条外,还开放了OpenDataLab 数据平台,其中提供了丰富种类的数据:

接下来介绍一下InternLM-train工具的特点:

三、大语言模型的微调:(见后续博客)
大语言模型的下游应用中,增量续训和有监督微调是经常用到的两种方式。
增量续训
使用场景:让基座模型学到一些新知识,比如某个垂类领域知识
训练数据:文章、书籍、代码等
有监督微调
使用场景:让模型学会理解和遵循各种指令,或者注入少量领域知识
训练数据:高质量对话、问答数据
可以分为以下两种:
全量参数微调:基于预训练模型(已经学到了大量的通用特征和语义信息,因此在目标任务上可能能够更快地收敛和取得更好的性能)来对模型整体进行调整,(不仅是输出层)全量参数微调也可能需要更大的计算资源和训练时间,因为需要调整的参数更多。
部分参数微调:微调过程中,只调整预训练模型的部分参数而不是整个模型的参数。通常,这涉及冻结预训练模型的一部分层(通常是底层或中间层),使其在微调期间保持不变,而只调整模型的一小部分参数,通常是输出层或顶层。
关于微调,开源了高效的微调框架Xtuner,适配多种生态:
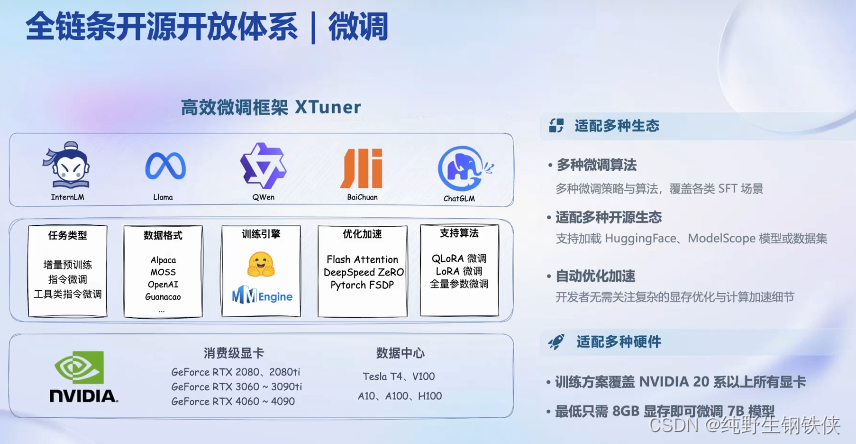 可以在8GB的显存上实现7B模型的微调(还是很强的)
可以在8GB的显存上实现7B模型的微调(还是很强的)
四、大语言模型的评测:OpenCompass
当前国内外有很多种评价体系与评测方式:(如下)

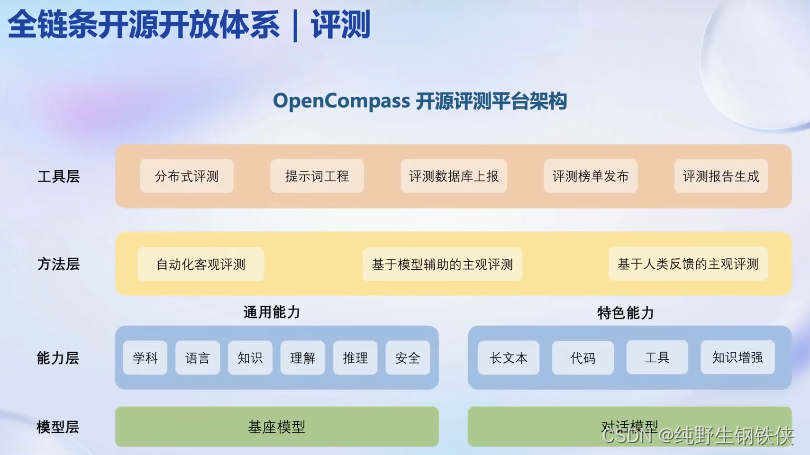
OpenCampass从六个维度来进行评价模型的能力:

架构主要分为四层:
模型层:支持了基座模型和对话模型(已开源)
能力层:通用能力和特色能力两部分评价
评测方法:自动化客观、基于模型辅助的主观、基于人类反馈的主观
工具层:分布式、提示词工程、评测数据库上报、评测榜单发布、评测报告生成
 五、大语言模型的部署 LMDeploy
五、大语言模型的部署 LMDeploy
大语言模型本身的特点,给部署上带来了一系列的技术挑战

















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









