







目录
-
实验目的
1.学习非线性回归模型的基本原理和假设。
2.使用Python中的Scikit-Learn库来实现非线性回归模型。
3.使用非线性回归模型来进行预测。
-
实验内容与要求
与房价密切相关的除了单位的房价,还有房屋的尺寸。我们可以根据已知的房屋成交价和房屋的尺寸进行线性回归,继而可以对已知房屋尺寸,而未知房屋成交价格的实例进行成交价格的预测。对于给出的数据集,请对对房屋成交信息建立非线性回归方程,并依据回归方程对房屋价格进行预测。
-
实验程序与结果
| import pandas as pd import numpy as np import matplotlib import random from matplotlib import pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression #2.加载训练数据,建立回归方程 # 读取数据集,建立datasets_X和datasets_Y用来存储数据中的房屋尺寸和房屋成交价格。 datasets_X = [] datasets_Y = [] #打开数据集所在文件prices.txt,读取数据。 fr = open('prices.txt','r') #一次读取整个文件。 lines = fr.readlines() # 读取数据集 #逐行进行操作,循环遍历所有数据 for line in lines: # 去除数据文件中的逗号 items = line.strip().split(',') # 将读取的数据转换为int型,并分别写入datasets_X和datasets_Y。 datasets_X.append(int(items[0])) datasets_Y.append(int(items[1])) #求得datasets_X的长度,即为数据的总数。 length = len(datasets_X) #将datasets_X转化为数组,并变为二维,以符合线性回归拟合函数输入参数要求。 datasets_X = np.array(datasets_X).reshape([length,1]) #将datasets_Y转化为数组 datasets_Y = np.array(datasets_Y) # 以数据datasets_X的最大值和最小值为范围,建立等差数列,方便后续画图。 minX = min(datasets_X) maxX = max(datasets_X) X = np.arange(minX,maxX).reshape([-1,1]) # 线性回归 clf1 = LinearRegression() clf1.fit(datasets_X, datasets_Y) y_l = clf1.predict(X) # 线性回归预测值 # 非线性回归 ployfeat = PolynomialFeatures(degree=3) # 根据degree的值转换为相应的多项式(非线性回归) x_p = ployfeat.fit_transform(datasets_X) print(datasets_X) print(x_p) clf2 = LinearRegression() clf2.fit(x_p, datasets_Y) #画图 print(clf2.intercept_) print(clf2.coef_) font={"family":"FangSong",'size':12} matplotlib.rc("font",**font) plt.figure(figsize = (12,6)) plt.scatter(datasets_X,datasets_Y,label="real value") plt.plot(X,y_l,label = "线性回归") plt.plot(X,clf2.predict(ployfeat.fit_transform(X)),label="非线性回归") plt.legend() plt.show() |
| print(clf2.intercept_) print(clf2.coef_) 49.8601106194547 [ 0.00000000e+00 1.95441885e-01 -4.26246389e-05 7.79675380e-09] |
-
实验结果分析
以下为核心代码:
| # 线性回归 clf1 = LinearRegression() clf1.fit(datasets_X, datasets_Y) y_l = clf1.predict(X) # 线性回归预测值 # 非线性回归 ployfeat = PolynomialFeatures(degree=3) # 根据degree的值转换为相应的多项式(非线性回归) x_p = ployfeat.fit_transform(datasets_X) print(datasets_X) print(x_p) clf2 = LinearRegression() clf2.fit(x_p, datasets_Y) |
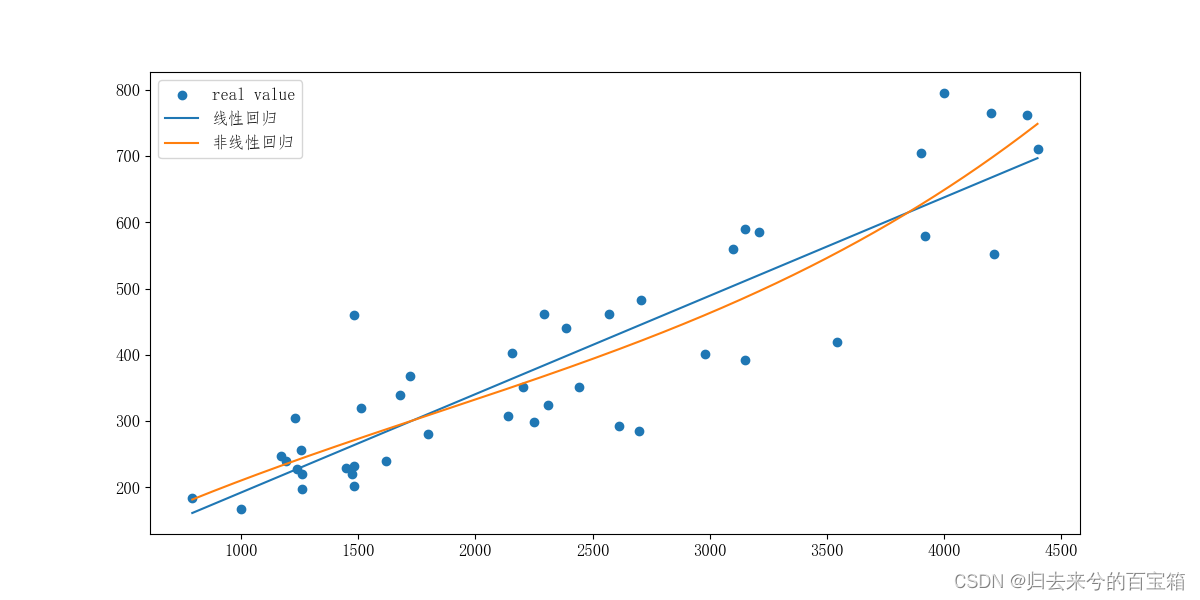
在代码执行的过程中,线性回归可以直接调用LinearRegression和fit函数,然而非线性回归首先需要进行多项式的特征提取,采用fit_transform函数,然后进行同线性回归一致的操作。需要注意的是,在画图过程中,我们需要注意非线性回归的y值需要在多项式的特征提取X值才能正确作图。
| print(clf2.intercept_) print(clf2.coef_) font={"family":"FangSong",'size':12} matplotlib.rc("font",**font) plt.figure(figsize = (12,6)) plt.scatter(datasets_X,datasets_Y,label="real value") plt.plot(X,y_l,label = "线性回归") plt.plot(X,clf2.predict(ployfeat.fit_transform(X)),label="非线性回归") plt.legend() plt.show() |
查看三阶线性回归拟合的系数值,在合理范围之内。
| print(clf2.intercept_) print(clf2.coef_) 49.8601106194547 [ 0.00000000e+00 1.95441885e-01 -4.26246389e-05 7.79675380e-09] |
通过观察线性回归与非线性回归的拟合效果,发现非线性回归的拟合效果更好。
实验问题解答与体会
作为一种经典的监督学习方法,非线性回归模型比线性回归算法在实际问题中具有广泛的应用。通过本次实验,我深刻地体会到了非线性回归模型的建模过程和应用方法。
在实验过程中,我学会了如何使用Scikit-Learn库中的线性回归模型来拟合数据,并且构建了非线性回归模型,并了解了模型的训练和评估方法。同时,我也掌握了如何使用matplotlib库来可视化数据和模型拟合结果,通过直观的图形展示,更好地理解了数据和模型之间的关系。















 1999
1999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









