






| 模型类型 | 代表模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 传统模型 | BM25 | 高效、无需训练数据 | 无法捕捉语义 | 初筛、日志分析 |
| 神经双编码器 | DPR、ANCE | 高效、支持大规模检索 | 精度低于交互式模型 | 千万级文档库召回 |
| 神经交互式模型 | ColBERT、BERT | 高精度、语义理解强 | 计算成本高 | 精排、复杂查询 |
| 生成式模型 | DSI | 端到端、无需索引 | 依赖训练数据、可扩展性挑战 | 动态数据、小规模场景 |
| 多模态模型 | CLIP | 跨模态对齐 | 需要多模态预训练 | 图像/视频检索 |
目录
1.2 向量空间模型(Vector Space Model, VSM)1.2 向量空间模型(向量空间模型,VSM)
查询似然模型(Query Likelihood Model)
3. 神经检索模型(Neural Retrieval Models)
3.3 核匹配模型(Kernel-Based Models)3.3 基于核的匹配模型(Kernel-Based Models)
1. 传统检索模型

关键特性对比
| 维度 | 布尔模型 | 扩展布尔 | VSM | BIM | BM25 | 概率推理模型 |
|---|---|---|---|---|---|---|
| 排序能力 | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| 部分匹配 | ❌ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ |
| 语义处理 | ❌ | ❌ | ❌(词袋) | ❌ | ❌ | ✔️(语言模型) |
| 文档长度适应 | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ |
| 计算效率 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌(部分复杂) |
| 需训练数据 | ❌ | ❌ | ❌ | ✔️(相关集) | ❌ | ✔️(部分) |
1.1 布尔模型(Boolean Model)
-
时间:1950年代
-
-
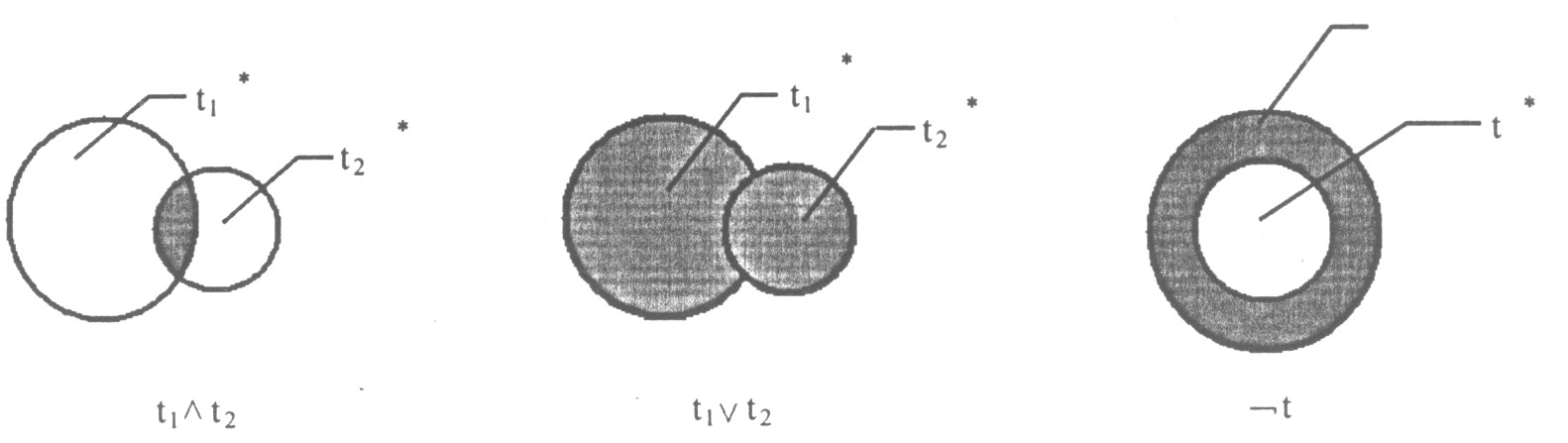
核心思想:基于布尔逻辑运算符(AND/OR/NOT)的精确匹配,文档与查询的匹配结果为二元判定(相关/不相关)。
-
标准的布尔逻辑模型为二元逻辑,即一系列对应于文献特征的二元变量。这些变量包括从文献中提取的文本检索词、短语、私人签名和手工加入的标引词。
-
用户根据检索项在文档中的布尔逻辑关系递交査询,匹配函数由布尔逻辑的基本法则确定。
-
所检索出的文档或者与查询相关,或者与查寻无关,查寻结果一般不进行相关性排序。
-
-
优点:规则透明,实现简单,适用于结构化数据(如数据库)。
-
缺点:
-
二元匹配:仅支持“相关”或“不相关”的二元判断,无法排序。
-
严格逻辑:必须完全满足AND/OR/NOT条件,忽略部分匹配和语义相似性。
-
用户不友好:需用户熟悉布尔运算符,难以处理复杂自然语言查询。
-
-
应用:早期图书馆目录、法律文档检索系统。
-
扩展布尔模型(Extended Boolean Model):
-
引入模糊逻辑(Fuzzy Logic),支持部分匹配(如P-norm模型)
-
将文档与查询的匹配程度从二元扩展为连续值(0到1之间的隶属度),支持部分匹配和相关性排序。
-
运算公式:

-
模糊集合理论
-
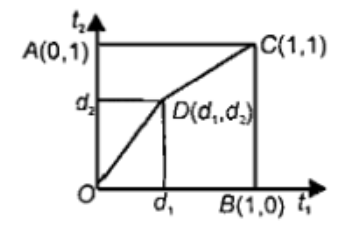
P-norm 模型 3.2 P-范数模型
定义:通过参数 p 控制逻辑运算的严格性,平衡AND的“严格性”与OR的“宽松性” -
隶属度计算:词频归一化,TF-IDF加权
-
实例说明
假设用户查询为 Q=健康 AND 饮食Q=健康 AND 饮食,两篇文档的隶属度如下:
-
-
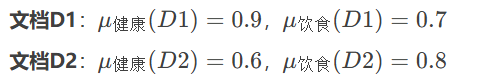
-
使用P-norm模型(设 p=2p=2)计算相似度:
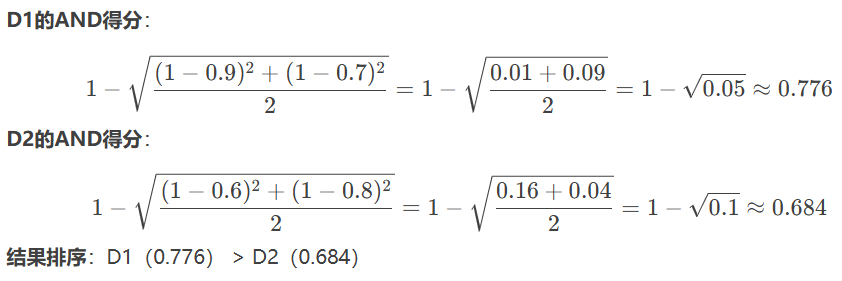
-
实际应用场景
-
搜索引擎初筛:在传统布尔模型基础上增加排序能力。
-
专业数据库检索:如医学文献库,需结合精确逻辑与部分匹配。
-
混合系统组件:与BM25或神经模型结合,优化召回阶段效果。
-
-
-
1.2 向量空间模型(Vector Space Model, VSM)
1.2 向量空间模型(向量空间模型,VSM)
-
时间:1970年代(Salton等人提出)
-
核心思想:将文档和查询表示为向量,权重计算基于TF-IDF,相似度通过余弦相似度衡量。
-
特点
-
优点 缺点 支持部分匹配和相关性排序 高维稀疏性:词项维度随语料库增长,存储和计算成本高 简单直观,易于实现 忽略词序和语义:将文本视为词袋(Bag-of-Words) 灵活适应不同权重策略(TF-IDF变体) 无法处理同义词和多义词:如“苹果”公司 vs. 水果 适合中小规模文档库 对长文档处理不足:词频可能偏向长文档
-
-
关键组件与公式

- 逆向文件频率(inverse document frequency,IDF)
- 词频(term frequency,TF)
-
改进方向:
-
潜在语义分析(LSA/LSI):通过SVD降维捕捉潜在语义。
-
词向量加权:结合Word2Vec或GloVe生成稠密向量。
-
-
应用:早期搜索引擎(如Altavista)、文本分类。TF-IDF 加权与余弦相似度仍是文本检索的基线方法,尤其在轻量级系统中具有实用价值。
1.3 概率模型
| 特性 | BIM | BM25 | 语言模型 |
|---|---|---|---|
| 词频处理 | 不考虑 | 非线性饱和 | 考虑词频 |
| 长度归一化 | 无 | 显式处理 | 隐式处理 |
| 理论基础 | 概率论 | 概率框架+启发式扩展 | 统计语言模型 |
| 参数需求 | 需要相关文档集 | 无需相关集 | 需要背景语言模型 |
-
基础模型:二元独立模型(BIM)
-
基本假设
-
二元性:文档和查询表示为词项出现与否的布尔向量。
-
独立性:词项在相关文档和不相关文档中的出现相互独立。
-
词项权重:基于词项在相关文档集和不相关文档集中的分布差异。
-
-
公式推导
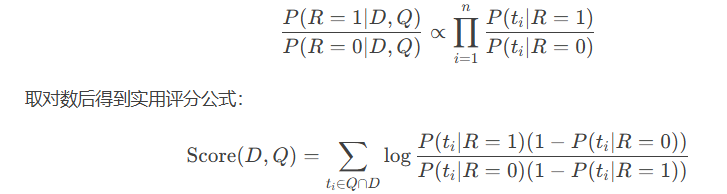
-
-
经典模型:
-
BM25(Best Matching 25) BM25(最佳匹配 25)
-
应用:Elasticsearch、Lucene、商业搜索引擎初筛阶段。 应用:Elasticsearch
-
变种:BM25F(支持多字段加权)、BM25+(改进长尾词处理)。
-
优点:对长文档鲁棒,无需训练数据,计算高效。
与传统 TF-IDF 对比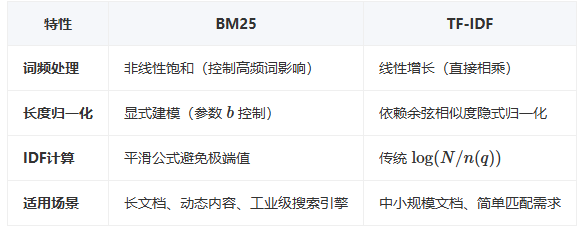
-
关键组件与公式
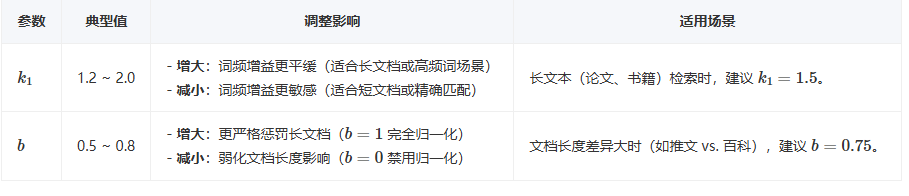
参数调优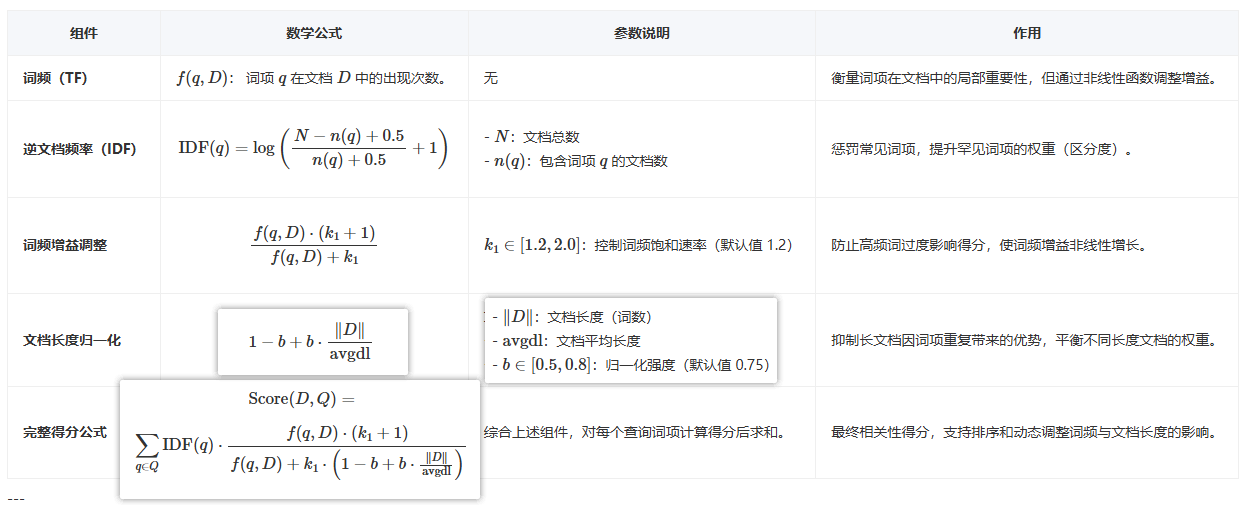
-
核心公式:
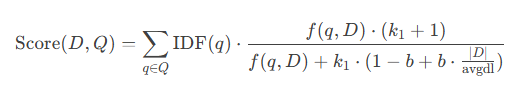
其中 k1 控制词频饱和,b 控制文档长度归一化。(k1, b)平衡了词频增益、文档长度和全局区分度,成为信息检索领域的基准模型。
-
时间:1990年代(Robertson等人提出)
-
概率推理模型(Probabilistic Inference Model)
-
时间:1970年代(Robertson的二元独立模型BIM)
-
核心思想:
-
基于贝叶斯定理计算文档与查询的相关性概率。
-
通过概率方法估计文档 DD与查询 Q 的相关性 P(R=1∣D,Q),即给定文档和查询时相关性的条件概率。不同于VSM的相似度计算,直接对"相关性"进行概率建模。
-
-

-
-
2. 语言模型(Language Models)
| 维度 | 查询似然模型 | BERT |
|---|---|---|
| 理论基础 | 统计语言模型(概率生成) | 深度学习(Transformer自注意力) |
| 语义处理 | 词袋模型(忽略上下文) | 上下文双向语义建模 |
| 匹配方式 | 独立计算词项概率(无交互) | 查询与文档的交叉注意力(交互式) |
| 计算效率 | 高(可预计算文档语言模型) | 低(需实时计算交叉注意力) |
| 数据需求 | 无监督/弱监督(依赖语料统计) | 需大量标注数据微调 |
| 典型应用阶段 | 召回(第一轮筛选) | 精排(最终结果重排序) |
| 可解释性 | 高(基于词频和概率) | 低(黑盒模型) |
| 处理长文档能力 | 依赖平滑策略,对长文档敏感 | 通过分段处理(如512 token限制) |
2.1 基于统计的语言模型
查询似然模型:作为概率检索的基石,适合高效率、可解释性要求高的场景,但语义理解有限。
BERT:代表语义检索的最前沿,通过深度上下文建模显著提升效果,但需权衡计算资源。
趋势:工业界趋向结合两者优势,构建“传统召回 + 神经精排”的混合系统,如Google的搜索架构。
-
查询似然模型(Query Likelihood Model)
-
时间:1998年(Ponte & Croft)
-
核心思想:

-
公式:
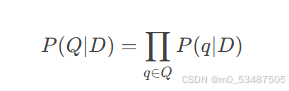

-
应用:早期TREC评测系统、新闻检索。
-
-
基于上下文的语言模型
-
BERT(Bidirectional Encoder Representations from Transformers)
BERT(双向编码器表示从转换器)-
时间:2019年(Google)
-
核心思想:
-
双向Transformer编码器:通过自注意力机制捕捉上下文双向语义信息,生成动态词向量。
-
交互式匹配:直接计算查询与文档的交叉注意力(Cross-Attention),捕捉细粒度语义关联。
-
检索流程:
-
输入表示:
-
将查询 QQ 和文档 DD 拼接为
[CLS] Q [SEP] D [SEP],生成联合输入。
-
-
编码与交互:
-
通过多层Transformer编码器生成上下文表征。
-
[CLS]标记的向量作为整体相关性得分。
-
-
微调目标:
-
使用对比学习(如Triplet Loss)或点积损失优化相关性排序。
-
-
-
应用:
-
多阶段流水线:
-
召回阶段:使用BM25或DPR快速筛选Top-1000文档。
-
精排阶段:BERT对Top-100文档进行重排序。
-
-
混合模型:
-
ColBERT:存储文档的BERT词向量,延迟交互计算相似度(平衡效率与效果)。
-
蒸馏技术:将BERT知识迁移到轻量级模型(如TinyBERT)以提升效率。
-
-
-
-
3. 神经检索模型(Neural Retrieval Models)
3.1 表示学习模型(双编码器)
-
DSSM(Deep Structured Semantic Model)
DSSM(深度结构化语义模型)-
时间:2013年(微软)
-
架构:通过全连接网络将查询和文档映射到低维语义空间,计算余弦相似度。
-
训练数据:依赖点击日志(Query-Doc点击对)。
-
应用:Bing搜索引擎广告匹配。
-
-
DPR(Dense Passage Retriever)
DPR(密集段落检索器)-
时间:2020年(Facebook)
-
架构:基于BERT的双编码器,独立编码查询和段落,通过内积计算相似度。
-
训练方法:对比学习(正例为相关段落,负例为随机采样或BM25筛选)。
-
优点:高效,适合千万级文档库检索。
-
-
ANCE(Approximate Nearest Neighbor Negative Contrastive Estimation)
ANCE(近似最近邻负对比估计)-
时间:2020年(微软)
-
核心改进:动态生成困难负例(通过异步更新索引),提升模型区分能力。
-
3.2 交互式模型(交互式编码器)
-
ColBERT(Contextualized Late Interaction over BERT)
ColBERT(基于 BERT 的上下文后期交互)-
时间:2020年
-
核心思想:延迟交互(Late Interaction),存储查询和文档的上下文词向量,计算细粒度MaxSim操作。
-
公式:
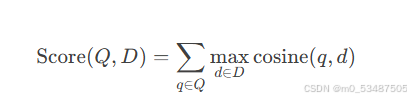
-
优点:平衡精度与效率,支持预计算文档表征。
-
-
Poly-Encoder 多编码器
-
时间:2020年(Facebook)
-
核心思想:通过多个注意力头聚合查询的全局表征,再与文档交互,减少计算量。
-
3.3 核匹配模型(Kernel-Based Models)
3.3 基于核的匹配模型(Kernel-Based Models)
-
KNRM(Kernel-based Neural Ranking Model)
KNRM(基于内核的神经排名模型)-
时间:2017年
-
核心思想:通过高斯核函数捕捉词对交互的多粒度匹配信号。
-
架构:将词嵌入交互矩阵映射到多个核空间,再通过全连接层预测相关性。
-
4. 生成式检索模型
-
DSI(Differentiable Search Index)
DSI(可微分搜索索引)-
时间:2022年(Google)
-
核心思想:直接生成文档ID或URL,端到端训练,无需传统倒排索引。
-
训练目标:最大化相关文档ID的生成概率。
-
挑战:依赖大规模训练数据,文档ID需预定义。
-
-
GENRE(Generative Entity Retrieval)
生成实体检索(Generative Entity Retrieval)-
时间:2021年
-
应用:直接生成实体名称或文档标题,适用于知识库问答。
-
5. 多模态与混合模型
5.1 多模态检索
-
CLIP(Contrastive Language-Image Pretraining)
CLIP(对比语言-图像预训练)-
时间:2021年(OpenAI)
-
核心思想:对齐图像和文本的嵌入空间,支持跨模态检索(如以文搜图)。
-
-
VisualBERT
-
时间:2019年
-
应用:结合图像区域特征和文本描述,用于多模态问答系统。
-
5.2 混合模型
-
BM25 + BERT
-
策略:BM25用于召回(快速筛选Top-K候选),BERT用于精排。
-
应用:工业级搜索引擎(如Google、Bing)。
-
-
SPLADE(Sparse Lexical and Dense Embedding)
SPLADE(稀疏词袋和密集嵌入)-
时间:2021年
-
核心思想:结合稀疏词频权重(BM25风格)和稠密向量表示,提升召回效果。
-
6. 前沿与新兴方向
-
零样本检索(Zero-Shot Retrieval)
-
模型:T5-ANCE、Contriever
-
特点:无需任务特定数据,直接迁移预训练知识。
-
-
可解释性检索
-
模型:ExBERT、IR-T5
-
目标:提供检索结果的可解释性(如高亮关键片段)。
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









