










- 题目:
- 3D Human Pose Estimation with Spatial and Temporal Transformers
- 利用时空Transformer去预测人体骨骼点的3D坐标
- 采用的数据集:
- We evaluate our model on two commonly used 3D HPEdatasets, Human3.6M and MPI-INF-3DHP
- 主体思想:
- 利用已经有的基于2D平面的坐标点(已知)去预测其3D坐标
- 输入输出形状

- 上面是输入(batchsize,frame,17,2)81帧,17个关键点,维度是2
- 上面是输入(batchsize,1,17,2)预测1帧,17个关键点,维度是3
- 模型:
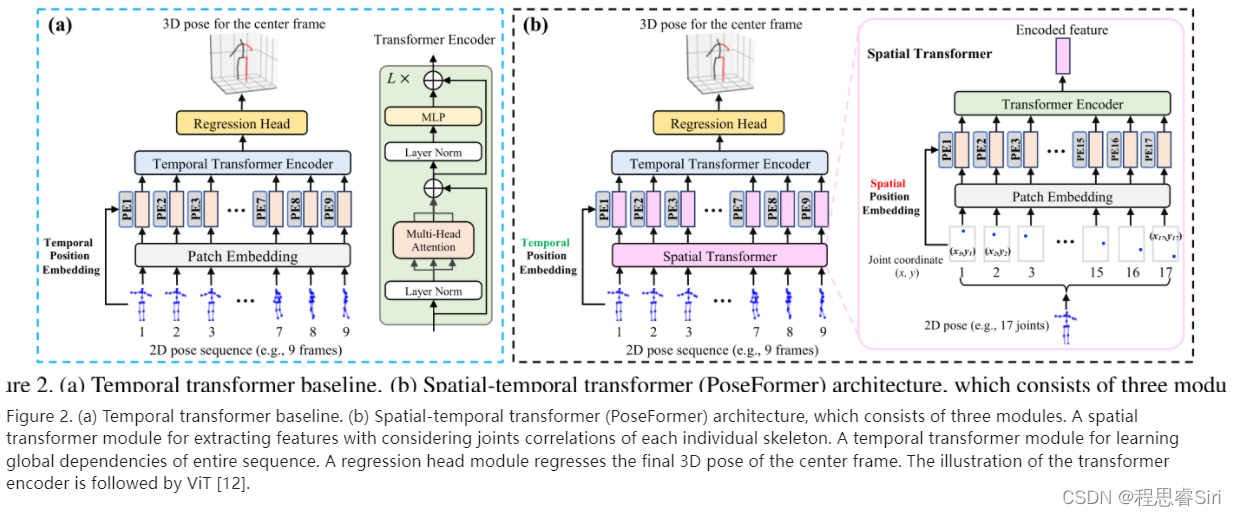
- Baseline是左边这张图,文章所提出的模型是右边这张图
- Spatial and Temporal Transformers(时空transformer)
- Temporal Tranformer Baseline(时间transformer)
- 主要思想是传统的transformer模型,将每一帧的2D pose骨骼关键点作为输入的的token,经过embedding之后输入到Temporal Transformer 中,以此预测的3D骨骼关键点。
- Spatial and Temporal Transformers(时空transformer)
- 而作者提出的Spatial and Temporal Transformers是在原有的Temporal Transformer的情况下,将Encoder中的Embedding部分改为一个Spatical Transformer,将每一帧的17个骨骼关键点分开为17份,每一份作为一个Spatial Transformer的Token,生成一个Encoded Feature。如果一开始有9帧,每一帧都会生成一个feature,所以空间Transformer的输出就会有9个feature,作为Encoding的结果输入到下一步参与训练。
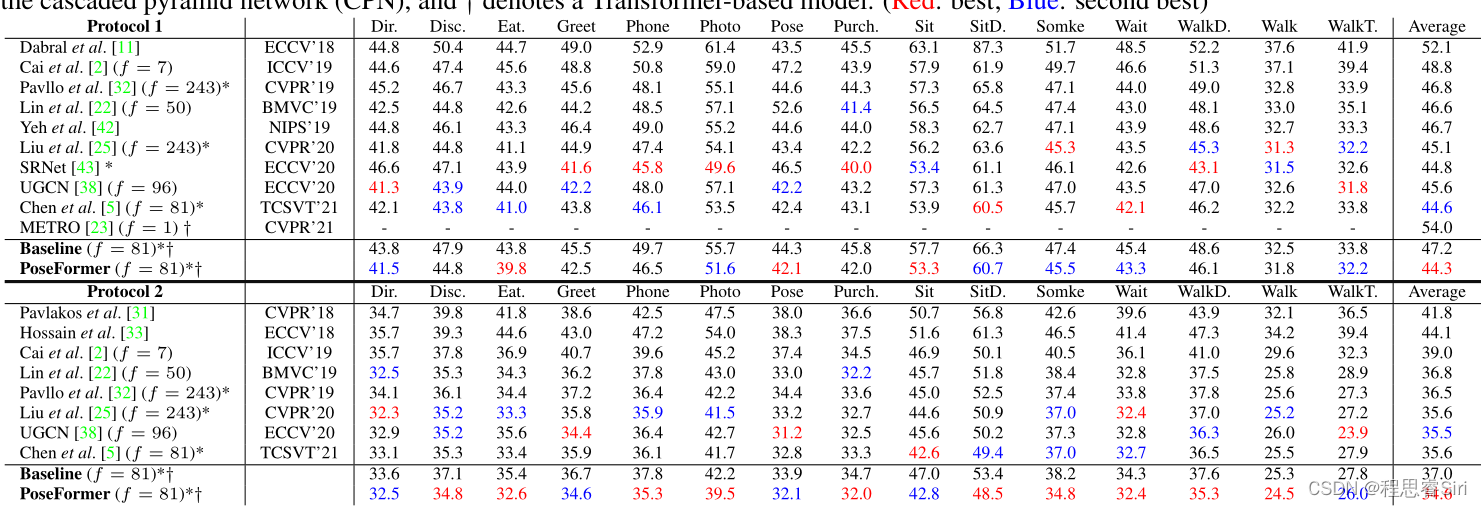
- 测试指标:
- Protocol1:MPJPE:
- Mean Per Joint Position Error即“平均(每)关节位置误差”

- Protocol2:P-MPJPE
- 先经过旋转、对齐等变换再进行MPJPE
- 最后效果
- (Red: best; Blue: second best)
- Protocol1:MPJPE:
5. 其中需要的一些数据包需要自己下载,可以自己上网搜或者按照readme给出的链接下载。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











