








 本文探讨了一种基于多种群进化算法的测试用例优先级排序策略,旨在提升软件测试效率和缺陷检测能力。通过平均故障检测百分比(APFD)、开销感知APFD(APFDc)和归一化APFD(NAPFD)等指标,评估不同测试序列的效果,并考虑了测试用例执行时间和缺陷严重程度。实验结果显示,提出的算法能有效提高测试速率和缺陷检测质量。
本文探讨了一种基于多种群进化算法的测试用例优先级排序策略,旨在提升软件测试效率和缺陷检测能力。通过平均故障检测百分比(APFD)、开销感知APFD(APFDc)和归一化APFD(NAPFD)等指标,评估不同测试序列的效果,并考虑了测试用例执行时间和缺陷严重程度。实验结果显示,提出的算法能有效提高测试速率和缺陷检测质量。
测试用例优先级评估
评估指标
平均故障检测百分比(APFD)
说明:当给定测试用例的执行次序时,该评测指标可以给出测试用例执行过程中检测到缺陷的平均累计比例。
特点:其取值范围介于0~100%之间,取值越高,则缺陷检测速率越快。
一般性描述:给定程序包含m个故障F={f1,f2,…,fm}和n个测试用例T={t1,t2,…,tn},T’为T的一个优先级序列,TFi为该测试用例学列T’中第一个检测到故障Fi的测试下标,则该优先级序列T’的ADPF值计算公式为:
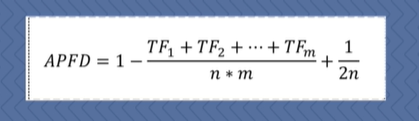

这里面对TFi的描述更具体。
上图来源:DataType: 1
Title-题名: 基于多种群进化算法的测试用例优先级排序研究
Author-作者: 张娜;胡国亨;金瑜婷;史佳炳;包晓安;
Source-刊名: 浙江理工大学学报(自然科学版)
Year-年: 2018
PubTime-出版时间: 2017-12-12 14:40
Keyword-关键词: 回归测试;测试用例优先级;多种群;动态调整
Summary-摘要: 为了提升软件测试的效率,加快软件研发的进度,提出了一种基于多种群进化的测试用例排序算法。该算法首先针对单种群遗传算法容易产生早熟收敛的问题,提出了一种多种群并行进化模型,以增强算法的全局寻优能力;然后根据该模型,结合软件需求覆盖和软件缺陷检测率,综合考虑代码覆盖率、测试用例设计信息和历史执行信息三个方面的因素,提出了一种动态调整测试用例优先级的计算方法。实验结果表明:与传统的面向单一目标覆盖的测试用例优先级排序算法相比,该算法的测试速率和软件缺陷检测能力得到一定的提升。
Period-期: 02
Roll-卷: 39
PageCount-页数: 6
Page-页码: 218-223
SrcDatabase-来源库: 期刊
Organ-机构: 浙江理工大学信息学院;
Link-链接: https://kns.cnki.net/kcms/detail/detail.aspx?FileName=ZJSG201802016&DbName=CJFQ2018
APFD案例

给定一个被测程序P,其包含了测试用例集T={t_1,t_2,t_3,t_4,t_5}和缺陷集F={f_1,f_2,f_3,f_4,f_5,f_6,f_7,f_8,f_9,f_10},各个测试用例的缺陷检测情况如下表所示,所测试序列的执行次序为t_1-t_2-t_3-t_4-t_5,那么该执行序列的APFD取值为?
解:
n = 测试用例数目 = 5
m = 可检测软件缺陷的数量 = 10
T = 1 − 1 + 3 + 3 + 3 + 1 + 2 + 2 + 5 + 5 + 5 5 ∗ 10 + 1 2 ∗ 5 T = 1 - \frac {1+3+3+3+1+2+2+5+5+5} {5*10} + \frac {1} {2*5} T=1−5∗101+3+3+3+1+2+2+5+5+5+2∗51
= 1 − 0.6 + 0.1 = 1 - 0.6 + 0.1 =1−0.6+0.1
= 0.5 = 0.5 =0.5
= 50%
对1+3+3+3+1+2+2+5+5+5的解释:
根据测试序列的执行次序为:t_1-t_2-t_3-t_4-t_5,在t_1中发现的缺陷分别为f_1、f_5,使得对应的TF1和TF5值为t_1的执行次序为1;在t_2中发现的缺陷为f_1、f_5、f_6、f_7,由于f_1、f_5在t_1中已经发现过了,在t_2中不是首次发现,所以只使得f_6、f_7只为t_2的执行次序为2;依次往下,得出每个缺陷的值,带入到APFD值计算公式得出值为50%。

缺点:默认测试用例具有相同的时间开销。未考虑测试用例的执行开销和缺陷危害程度带来的影响。
开销感知平均故障检测百分比(APFDc)
特点:考虑了测试用例的执行开销和缺陷危害程度。
一般性描述:给定程序包含m个故障F={f1,f2,…,fm},它们的严重程度分别为Severity={se1,se2,…sem},和n个测试用例T={t1,t2,…,tn},它们的执行时间分别是Time={time1,time2,…,timen},T’为T的一个优先级序列,TFi为该测试用例学列T’中第一个检测到故障Fi的测试下标,则该优先级序列T’的ADPFc值计算公式为:
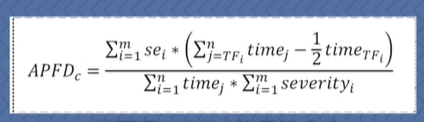
归一化平均故障检测百分比(NAPFD)
特点:考虑了实际优先级排序场景中,
- 测试用例集不能检测到所有缺陷。
- 由于资源限制,无法执行所有测试用例。
一般性描述:给定程序包含m个故障F={f1,f2,…,fm}和n个测试用例T={t1,t2,…,tn},T’为T的一个优先级序列,TFi为该测试用例学列T’中第一个检测到故障Fi的测试下标,p为T’检测到的故障数与程序总的故障数的比值,该优先级序列T’的NAPFD值计算公式为:


















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









