






文章目录
一、大数据(持续更新)
1. 前言
1.0作者感言
我水平有限,大数据仍在学习中,但学习日志会不断更新,知识是个积累的过程,这个博客算是记录我学习的过程,而非盈利性的教程。如果你们有更好的办法或者意见,欢迎评论。
1.1选择Typora
众所周知,计算机是一门过程性知识非常多的学科,我们需要一款工具来记录下我们的知识,Typora是一个非常好的选择,支持多种代码块,画面简约,编写方便,启动快速。
1.1.1 选择PicGo(APP)的原因
由于我们的图片在本地,上传md文件到CSDN的时候,CSDN不支持本地相对路径上传图片,会提示失败,这是就需要一个网络中转站,先把我们的图片上传到这个中转站里面,那么我们的图片地址就成了一个网络地址,CSDN就会自动加载
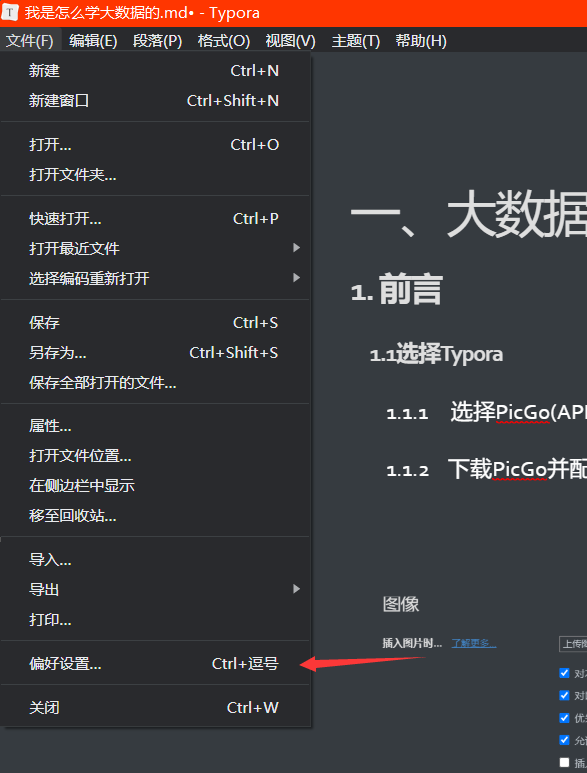
1.1.2 下载PicGo并配置
1. 偏好设置
-
下载PicGo

-
这里注意不要选择带beta的版本,因为不稳定,容易崩溃

- 我选择了


- 我们这里选择腾讯云COS,不选Github,因为Github服务器不在中国,所以会有下载上传缓慢的情况

- 创建对象存储桶(访问权限设置为 公开读私有写 ,提高安全性)

存储桶名称对应“设置存储空间名”
所属地域对应“确认存储区域”
存储桶名称后面的一串数字对应“设定APPID”
-
最后授予PicGo密匙

-

-

-

1.1.3 开始写博客,记录自己学习的点点滴滴
1.1.4 附件下载地址
链接:https://pan.baidu.com/s/1oA1iDFWGUCYC6Sjk5OzVeQ
提取码:s8h9
复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V1的分享
1.2 为什么用Linux?
众所周知,Linux最强的服务器操作系统,并且在一定程度上比windows安全。而大数据框架Hadoop也是运行在服务器之上,所以Linux是最优选。
2.下载VMware并安装Linux
注:附件在前言1.1.4
-

-

-

-

-

-

-

-
如果你的电脑是16G内存可以选择2GB,如果你的电脑是8G,则选择1G内存

-

-

-

-

-

-

-
完成

-

-

-
开启虚拟机

-
默认

-
跳过,选skip

-

-

-

-

-

-

-

-

-

-

-

-
耐心等待

-
这里重启即可

-

-

3. 安装VMwareTools
VMwareTools可以让虚拟机和Windows10之间共享粘贴板
-

-

-
控制台输入以下两条指令
cd /opt mkdir module software -
解压到第3步创建的module文件夹中

-
cd /opt/module/vmware-tools-distrib./vmware-install.pl然后一路回车采用默认设置
-
这里不要着急,不要按ctrl+C,否则会中断,系统也会崩溃,耐心等待

-
这里同样不要着急,不要跳过或者关闭窗口

-
安装成功如图所示

-
重启即可生效
4.配置网络,确保能上网
4.1 vim /etc/sysconfig/network-scripts/ifcfg-eth0
如果你是选择了NAT,那么你的Linux配置好了就能上网,但是需要再配置/etc/sysconfig/network-scripts的ifcfg-eth0,以确保ssh远程登录成功
关键配置如下
BOOTPROTO=static
ONBOOT=yes
配置完成保存,重启即可生效
4.2 配置主机名与Ip的映射
vim /etc/hosts
输入ifconfig指令查询的ip地址
输入hostname指令查询的主机名
如图

5. 配置SSH连接
终端输入以下指令查看ip地址
ifconfig

此处端口号(port)不要改,否则会出错
选yes即可
6. 配置SSH免密登录
-
关闭防火墙
chkconfig iptables off -
终端输入
ssh-keygen -t rsa
-
回车

-
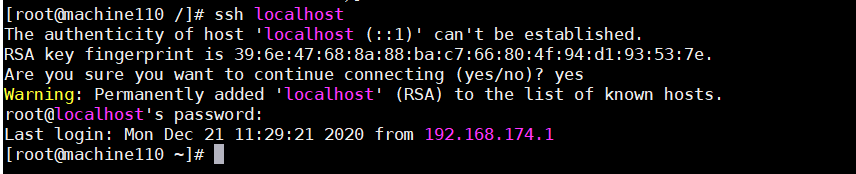
先用ssh登录一遍,这步目的是为了生成.ssh文件
ssh localhost
-
传递公钥
ssh-copy-id machine110第一次会让你输入密码,第二次就不用了
-
成功之后如图

7. 配置hadoop和java环境变量
7.1卸载自带的Java
7.1.1检查自带的Java
7.1.1.1指令解析
rpm命令
-q 使用询问模式,当遇到任何问题时,rpm指令会先询问用户。
-a 查询所有套件。
grep命令用于查找文件里符合条件的字符串。
rpm -qa |grep java
rpm -qa |grep jdk
rpm -qa |grep gcj
如果没有输入提示信息表示没有安装
7.1.2卸载Java
方法一:批量卸载
rpm -qa | grep java | xargs rpm -e --nodeps
方法二:单个卸载
rpm -e 安装包的名字
7.2解压附件安装包
7.2.1解压指令解析
-z或–gzip或–ungzip 通过gzip指令处理备份文件。
-x或–extract或–get 从备份文件中还原文件。
-v或–verbose 显示指令执行过程。
-f<备份文件>或–file=<备份文件> 指定备份文件。
-C<目的目录>或–directory=<目的目录> 切换到指定的目录。

tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
7.3配置/etc/profile
- 终端输入
vim /etc/profile
- 按 “i” 进入编辑模式,加入以下代码
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
-
ESC退出编辑模式,按"wq"进行保存
-
重新加载配置文件
source /etc/profile -
检查是否配置正确
java -version hadoop version
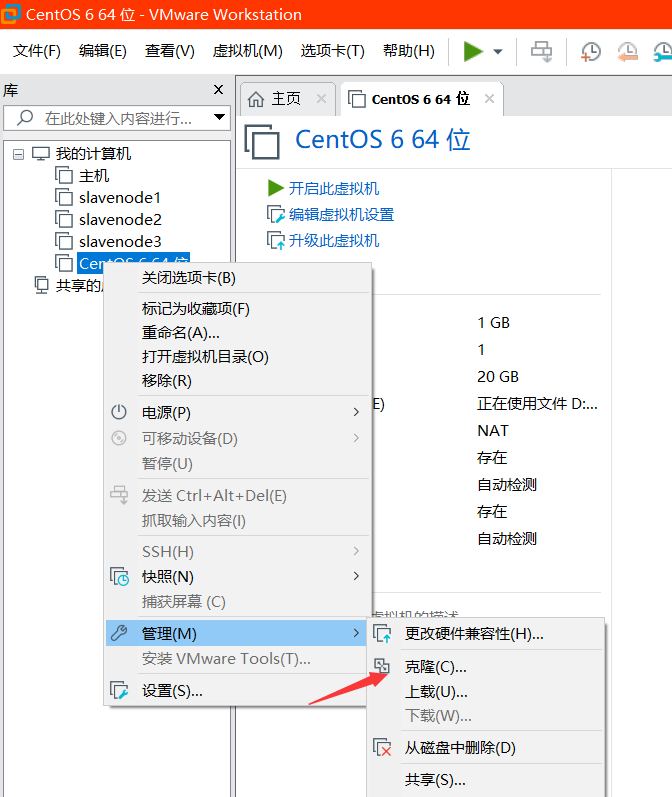
8.克隆虚拟机
8.1为什么要克隆虚拟机?
读者如果亲自配置过虚拟机,你会知道配置的过程是非常繁琐的,而且是非智力的劳动。在实际工作当中,你可能要配置3个节点以上,不可能一个一个配置,当你一个主机配置好后,选择克隆会省下很多功夫。
从安全方面上说,克隆可以防止数据丢失,相当于备份,以免系统崩溃又要从头再来的情况。
















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











