






Junyu Chen1,2∗, Han Cai3∗†, Junsong Chen3, Enze Xie3, Shang Yang1, Haotian Tang1, Muyang Li1, Yao Lu3, Song Han1,3
1 麻省理工学院(MIT)
2 清华大学
3 英伟达(NVIDIA)
GitHub链接
翻译:
我们提出了一种新型自编码器——深度压缩自编码器(DC-AE),用于加速高分辨率扩散模型。现有自编码器在中等空间压缩比(例如 8×)下表现出色,但在高空间压缩比(例如 64×)时无法维持令人满意的重建精度。为了解决这一挑战,我们引入了两项关键技术:(1)残差自编码,其中我们设计模型学习基于空间到通道转化特征的残差,以缓解高空间压缩自编码器的优化难度;(2)解耦高分辨率适应,一种高效的解耦三阶段训练策略,以减轻高空间压缩自编码器的泛化惩罚。通过这些设计,我们将自编码器的空间压缩比提高到 128,同时保持重建质量。将我们的 DC-AE 应用于潜在扩散模型,我们实现了显著的加速而不降低准确性。例如,在 ImageNet 512 × 512 上,我们的 DC-AE 为 UViT-H 提供了 19.1 倍的推理加速和 17.9 倍的训练加速,相比于广泛使用的 SD-VAE-f8 自编码器,取得了更好的 FID 评分。
解释:
这段话介绍了一种新的自编码器模型,旨在加速处理高分辨率图像的扩散模型。虽然以前的模型在中等压缩下表现良好,但在更高压缩比时精度下降。为了解决这个问题,研究者们采用了两种新方法:一种是通过学习图像的“残差”来提高压缩效果,另一种是通过分阶段训练来提高模型的泛化能力。最终,他们的模型在保持图像质量的同时,大幅提升了处理速度,相比于其他模型表现更好。
翻译:
潜在扩散模型(Rombach 等,2022)已经成为一种领先的框架,并在图像合成方面取得了巨大的成功(Labs,2024;Esser 等,2024)。它们使用自编码器将图像投影到潜在空间,以降低扩散模型的计算成本。例如,目前潜在扩散模型中广泛采用的解决方案是使用空间压缩比为 8 的自编码器(记作 f8),将空间大小为 H × W 的图像转换为空间大小为 H/8 × W/8 的潜在特征。对于低分辨率图像合成(例如 256 × 256),这个空间压缩比是令人满意的。然而,对于高分辨率图像合成(例如 1024 × 1024),进一步提高空间压缩比是至关重要的,特别是对于计算复杂度与令牌数量成平方关系的扩散变换器模型(Peebles & Xie,2023;Bao 等,2023)。
解释:
这段话讲的是一种叫做潜在扩散模型的技术,它在生成图像方面非常成功。它通过一种叫自编码器的工具,把图像转换成一种更小的格式,这样可以减少计算量。现在使用的常见方法是把图像的大小减少到原来的八分之一,这对于生成小图像效果不错。但如果要生成更大的图像(比如 1024 × 1024),就需要进一步压缩,以便计算机能更快地处理这些信息,尤其是在处理复杂的模型时。
翻译:
目前进一步减少空间大小的常见做法是在扩散模型侧进行下采样。例如,在扩散变换器模型(Peebles & Xie,2023;Bao 等,2023)中,这通过使用补丁嵌入层实现,该层的补丁大小为
p
p
p,将潜在特征压缩为
H
/
8
p
×
W
/
8
p
H/8p \times W/8p
H/8p×W/8p 个令牌。相比之下,针对自编码器的改进则较少。限制高空间压缩自编码器使用的主要瓶颈是重建精度的下降。例如,图 2 (a) 显示了 SD-VAE(Rombach 等,2022)在 ImageNet
256
×
256
256 \times 256
256×256 上不同空间压缩比的重建结果。我们可以看到,如果从
f
8
f8
f8 切换到
f
64
f64
f64,重建 FID(rFID)从
0.90
0.90
0.90 降低到
28.3
28.3
28.3。
解释:
现在,要让图像变得更小,通常是在扩散模型中通过一种叫做下采样的技术来实现。这种技术使用一个特定大小的补丁来压缩图像信息,变成更小的格式(比如
H
/
8
p
×
W
/
8
p
H/8p \times W/8p
H/8p×W/8p 个小块)。但在自编码器的改进方面做得不多。主要的问题是,当压缩比变得很高时,重建出的图像质量会下降。比如,在处理 ImageNet
256
×
256
256 \times 256
256×256 的图像时,重建质量的评分会从
0.90
0.90
0.90 降到
28.3
28.3
28.3,这表明图像质量变差。
翻译:
本研究提出了深度压缩自编码器(DC-AE),这是一种高空间压缩自编码器的新系列,用于高效的高分辨率图像合成。通过分析高空间压缩和低空间压缩自编码器之间精度下降的根本原因,我们发现高空间压缩自编码器更难以优化(第 3.1 节),并且在不同分辨率间面临泛化惩罚(图 3 b)。为此,我们引入了两项关键技术来应对这两个挑战。首先,我们提出了残差自编码(图 4),以减轻高空间压缩自编码器的优化难度。它在自编码器中引入额外的非参数快捷通道,使神经网络模块能够基于空间到通道的操作学习残差。其次,我们提出了解耦高分辨率适应(图 6)来解决另一个挑战。它引入了高分辨率潜在适应阶段和低分辨率局部细化阶段,以避免泛化惩罚,同时保持低训练成本。
解释:
这段话讲的是一种新的自编码器,叫做深度压缩自编码器(DC-AE),用于高效生成高分辨率图像。研究者发现,高空间压缩的自编码器在优化时比较困难,而且在不同图像分辨率间的表现不够稳定。为了克服这些问题,他们提出了两种方法:一种是残差自编码,它能帮助自编码器更容易地学习,另一种是解耦高分辨率适应,它通过不同的训练阶段来提高模型的灵活性和效率,同时减少训练成本。
翻译:
通过这些技术,我们将自编码器的空间压缩比提高到 32、64 和 128,同时保持良好的重建精度(表 2)。扩散模型可以完全专注于去噪任务,而我们的 DC-AE 则负责整个令牌压缩任务,这比之前的方法提供了更好的图像生成结果(表 3)。例如,将 SD-VAE-f8 替换为我们的 DC-AE-f64,在 UViT-H(Bao 等,2023)上,我们实现了 H100 训练吞吐量提高 17.9 倍和 H100 推理吞吐量提高 19.1 倍,同时将 ImageNet
512
×
512
512 \times 512
512×512 的 FID 从 3.55 改善到 3.01。我们总结了我们的贡献如下:
• 我们分析了提高自编码器空间压缩比的挑战,并提供了应对这些挑战的见解。
• 我们提出了残差自编码和解耦高分辨率适应,这有效提高了高空间压缩自编码器的重建精度,使其在潜在扩散模型中可行。
• 我们构建了 DC-AE,这是一种基于我们技术的新型自编码器。与之前的自编码器相比,它为扩散模型提供了显著的训练和推理加速。
解释:
通过新技术,我们能够将自编码器的压缩能力提高到 32、64 和 128,同时仍然保持较好的图像质量。这样,扩散模型可以专注于去噪,而我们的 DC-AE 负责压缩图像信息,这使得生成的图像效果比以前的方法更好。例如,当我们用 DC-AE-f64 替换 SD-VAE-f8 时,训练和推理的速度分别提高了 17.9 倍和 19.1 倍,图像质量评分也有了显著提升。我们总结了我们的贡献,包括分析压缩比提升的挑战、提出有效的解决方案以及构建一种新的自编码器,从而为扩散模型提供了更快的处理速度。

图 1:DC-AE 通过提高自编码器的空间压缩比来加速扩散模型。
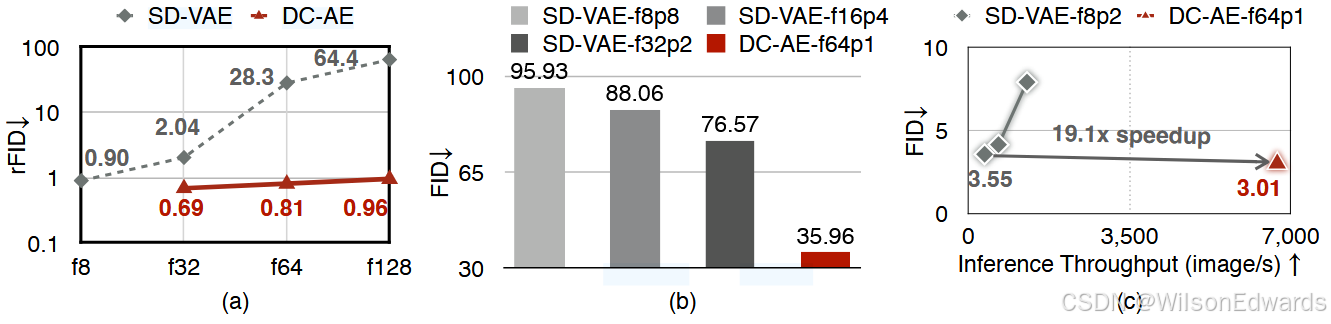
图 2:
(a)在 ImageNet
256
×
256
256 \times 256
256×256 上的图像重建结果。
f
f
f 表示空间压缩比。当空间压缩比增加时,SD-VAE 的重建精度显著下降(更高的 rFID),而 DC-AE 没有这个问题。
(b)在 UViT-S 上的 ImageNet
512
×
512
512 \times 512
512×512 图像生成结果,使用了各种自编码器。
p
p
p 表示补丁大小。将令牌压缩任务转移到自编码器使扩散模型能更专注于去噪任务,从而获得更好的 FID。
(c)在 UViT 变体上,比较 ImageNet
512
×
512
512 \times 512
512×512 的 SD-VAE-f8。DC-AE-f64p1 在 UViT-H 上提供了 19.1 倍更高的推理吞吐量和 0.54 更好的 ImageNet FID,相比于 SD-VAE-f8p2。
翻译:
2 相关工作
自编码器在扩散模型中的应用。直接在高分辨率像素空间中训练和评估扩散模型会导致极高的计算成本。为了解决这个问题,Rombach 等(2022)提出了潜在扩散模型,它们在由预训练自编码器生成的压缩潜在空间中运行。该自编码器具有 8 倍的空间压缩比和 4 个潜在通道,已被后续工作广泛采用(Peebles & Xie,2023;Bao 等,2023)。此后,后续研究主要集中在通过增加潜在通道的数量来提高 f8 自编码器的重建精度(Esser 等,2024;Dai 等,2023;Labs,2024)。相比之下,我们的工作关注一个正交的方向,即提高自编码器的空间压缩比(例如,f64)。据我们所知,我们的工作是这一关键但未被充分探讨方向的首个研究。
解释:
这一部分介绍了自编码器在扩散模型中的作用。因为直接处理高分辨率图像会消耗大量计算资源,Rombach 等人提出了潜在扩散模型,通过使用预训练的自编码器把图像压缩到更小的空间中。以前的研究主要是通过增加潜在通道来提高这种自编码器的图像重建质量。但我们则选择了一个不同的方向,专注于提高自编码器的压缩能力(例如,压缩比从 8 倍提高到 64 倍)。我们认为这是一个重要但仍然不够深入研究的领域。
翻译:
扩散模型加速。扩散模型已被广泛应用于图像生成,并取得了令人印象深刻的成果(Labs,2024;Esser 等,2024)。然而,扩散模型计算量大,因此许多研究致力于加速扩散模型。一种代表性策略是通过训练无关的少步采样器(Song 等,2021;Lu 等,2022a;b;Zheng 等,2023;Zhang & Chen,2023;Zhang 等,2023;Zhao 等,2024b;Shih 等,2024;Tang 等,2024)或基于蒸馏的方法(Meng 等,2023;Salimans & Ho,2022;Yin 等,2024b;a;Song 等,2023;Luo 等,2023;Liu 等,2023)来减少推理采样步骤的数量。另一种代表性策略是利用稀疏性(Li 等,2022;Ma 等,2024)或量化(He 等,2024;Fang 等,2024;Li 等,2023;Zhao 等,2024a)进行模型压缩。设计高效的扩散模型架构(Li 等,2024c;Liu 等,2024;Cai 等,2024)或推理系统(Li 等,2024b;Wang 等,2024)也是提高效率的有效方法。此外,提高数据质量(Chen 等,2024b;a)可以提升扩散模型的训练效率。所有这些研究都关注扩散模型,而自编码器保持不变。我们的工作开启了一个加速扩散模型的新方向,这可以同时提升训练和推理的效率。
解释:
这一段讨论了如何加速扩散模型。虽然这些模型在生成图像方面表现很好,但它们需要大量计算资源,所以研究人员提出了多种方法来提高效率。例如,有些方法通过减少模型生成图像所需的步骤来加快速度,其他方法则通过优化模型的结构或压缩模型大小来减少计算需求。还有些研究专注于提高数据的质量,从而加快训练过程。尽管这些研究专注于扩散模型本身,但我们的方法则是探索如何通过改进自编码器来加速扩散模型,从而在训练和推理过程中都能受益。
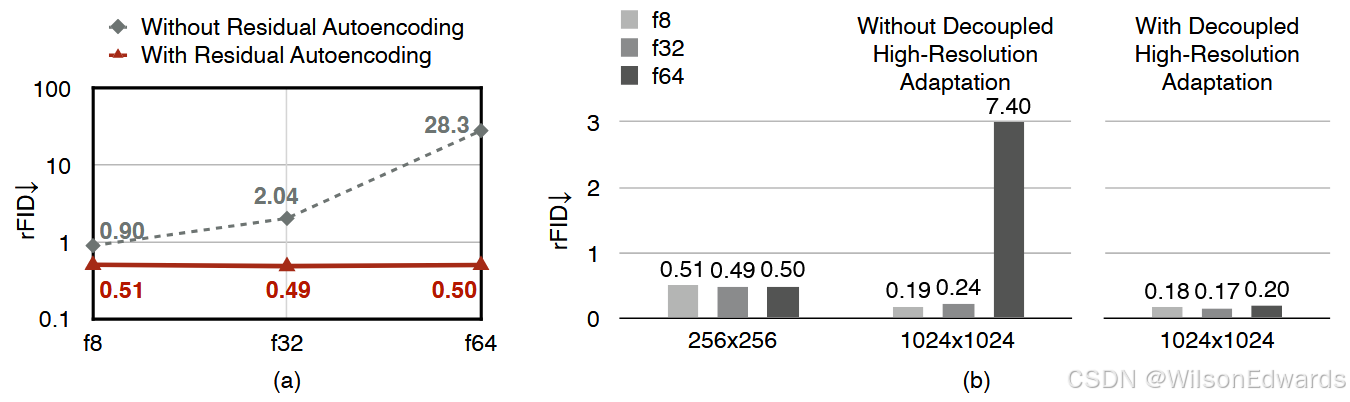
图 3:
(a)高空间压缩自编码器更难以优化。即使具有相同的潜在形状和更强的学习能力,它仍然无法匹配
f
8
f8
f8 自编码器的 rFID。
(b)高空间压缩自编码器在从低分辨率到高分辨率的泛化过程中,重建精度显著下降。
解释:
这幅图展示了高空间压缩自编码器的一些挑战。部分(a)说明,这种自编码器即使有相同的结构和更强的学习能力,仍然难以达到较低压缩比(
f
8
f8
f8)自编码器的重建效果。部分(b)则表明,当从低分辨率图像转向高分辨率时,高空间压缩自编码器的重建质量会明显下降。也就是说,随着压缩比的增加,自编码器在生成高质量图像时会遇到更多困难。
翻译:
3 方法
在这一部分,我们首先分析现有的高空间压缩自编码器(例如,SD-VAE-f64)为什么无法匹配低空间压缩自编码器(例如,SD-VAE-f8)的准确性。然后,我们介绍我们的深度压缩自编码器(DC-AE),以及残差自编码和解耦高分辨率适应的设计,以缩小准确性差距。最后,我们讨论 DC-AE 在潜在扩散模型中的应用。
解释:
这一部分将介绍我们的方法。我们首先探讨为什么一些高压缩比的自编码器(像 SD-VAE-f64)在生成图像时不如低压缩比的自编码器(像 SD-VAE-f8)准确。接着,我们会介绍我们的新型自编码器(DC-AE),以及它采用的两种技术:残差自编码和解耦高分辨率适应,这些方法旨在提高准确性。最后,我们会讨论如何将 DC-AE 应用于潜在扩散模型。
翻译:
3.1 动机
我们进行消融研究实验,以深入了解高空间压缩自编码器与低空间压缩自编码器之间准确性差距的根本原因。具体来说,我们考虑三个设置,逐渐增加空间压缩比,从
f
8
f8
f8 到
f
64
f64
f64。每当空间压缩比增加时,我们在当前自编码器上叠加额外的编码器和解码器阶段。通过这种方式,高空间压缩自编码器包含低空间压缩自编码器作为子网络,因此具有更高的学习能力。此外,我们增加潜在通道的数量,以在不同设置中保持相同的总潜在大小。然后,我们可以通过应用空间到通道操作将潜在转换为更高的空间压缩比:
H
×
W
×
C
→
H
/
p
×
W
/
p
×
p
2
C
H \times W \times C \rightarrow H/p \times W/p \times p^2C
H×W×C→H/p×W/p×p2C。我们在图 3(a,灰色虚线)中总结了结果。即使具有相同的总潜在大小和更强的学习能力,当空间压缩比增加时,我们仍观察到重建精度下降。这表明,新增的编码器和解码器阶段(由多个 SD-VAE 构建块组成)的效果不如简单的空间到通道操作。基于这一发现,我们推测准确性差距源于模型学习过程:尽管在参数空间中存在良好的局部最优解,优化难度却阻碍了高空间压缩自编码器达到这些局部最优解。
解释:
在这一部分,我们通过实验研究了为什么高压缩比的自编码器在准确性上不如低压缩比的自编码器。我们逐步增加空间压缩比,从
f
8
f8
f8 到
f
64
f64
f64,并在每次增加时添加额外的编码和解码阶段。这样一来,高压缩自编码器就包含了低压缩自编码器,使其学习能力更强。此外,我们增加了潜在通道的数量,以保持潜在大小的一致性。虽然这些修改提高了学习能力,但我们发现重建质量并没有提升,反而下降了。这表明新增的编码器和解码器的组合效果不如简单的压缩方法。我们的猜测是,这种准确性差距与模型的学习过程有关:虽然在参数空间中有好的局部最优解,但优化过程的难度使得高压缩自编码器无法达到这些解。
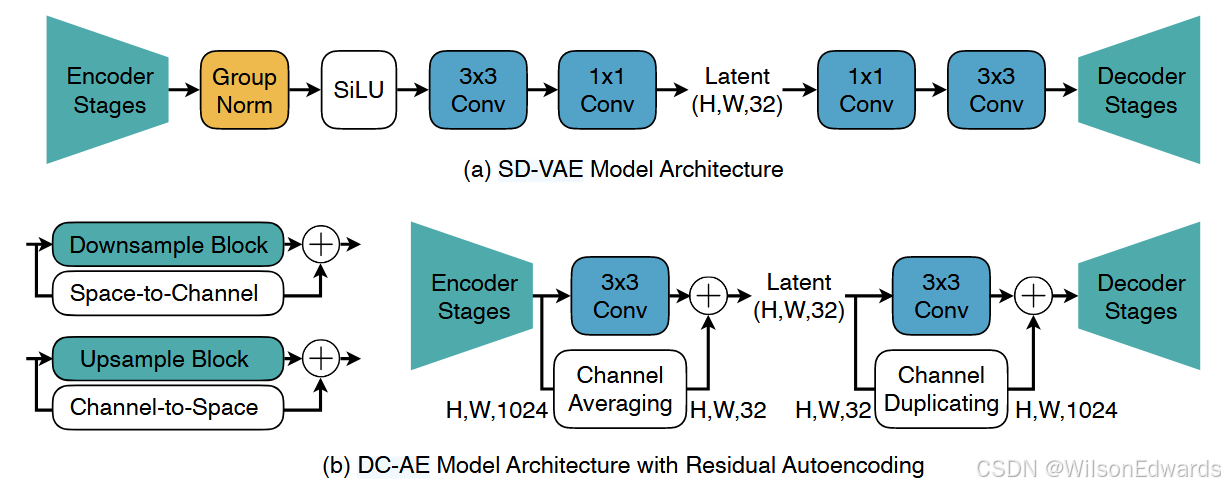
图 4:残差自编码的示意图。它添加了非参数快捷方式,让神经网络模块根据空间到通道操作学习残差。
翻译:
3.2 深度压缩自编码器
残差自编码。基于之前的分析,我们引入了残差自编码来解决准确性差距。其一般思路如图 4 所示。与传统设计的核心区别在于,我们明确让神经网络模块学习基于空间到通道操作的下采样残差,以缓解优化难度。与 ResNet(He et al., 2016)不同,这里的残差不是恒等映射,而是空间到通道映射。实际操作中,这通过在编码器的下采样块和解码器的上采样块上添加额外的非参数捷径来实现(图 4 b,左侧)。具体来说,对于下采样块,非参数捷径是一个空间到通道操作,后面接着一个非参数通道平均操作,以匹配通道数量。例如,假设下采样块的输入特征图形状为
H
×
W
×
C
H \times W \times C
H×W×C,输出特征图形状为
H
/
2
×
W
/
2
×
2
C
H/2 \times W/2 \times 2C
H/2×W/2×2C,那么添加的捷径是:
H
×
W
×
C
→
space-to-chamel
H
2
×
W
2
×
4
C
split into two groups
[
H
2
×
W
2
×
2
C
,
H
2
×
W
2
×
2
C
]
→
average
H
2
×
W
2
×
2
C
.
⏟
channel averaging
\begin{aligned}H\times W\times C&\xrightarrow{\text{space-to-chamel}}\frac H2\times\frac W2\times4C\\&\underbrace{\frac{\text{split into two groups}}{[\frac H2\times\frac W2\times2C,\frac H2\times\frac W2\times2C]}\xrightarrow{\text{average}}\frac H2\times\frac W2\times2C.}_{\text{channel averaging}}\end{aligned}
H×W×Cspace-to-chamel2H×2W×4Cchannel averaging
[2H×2W×2C,2H×2W×2C]split into two groupsaverage2H×2W×2C.
解释:
在这一部分,我们介绍了“深度压缩自编码器”的一个新方法,叫“残差自编码”。这个方法的目标是解决自编码器在压缩时准确性下降的问题。它的主要想法是让神经网络更好地学习如何处理图像的细节。
与传统的方法不同,我们不是直接把输入和输出对比,而是通过一种叫“空间到通道”的方式进行处理。具体来说,我们在图像处理的过程中,增加了一些特别的捷径,让网络可以更容易地学习到这些细节。
比如,在处理图像时,我们会把输入图像的特征分成两部分,然后再进行平均,最后输出一个新的特征。这种方法帮助模型在压缩图像时保持更好的准确性,就像给它多了一条路可以选择,从而更容易找到正确的答案。
翻译
因此,对于上采样块,非参数捷径是一个通道到空间的操作,后面接着一个非参数通道复制操作:
H
2
×
W
2
×
2
C
→
channel-to-space
H
×
W
×
C
2
→
duplicate
[
H
×
W
×
C
2
,
H
×
W
×
C
2
]
→
concat
H
×
W
×
C
.
⏟
channel duplicating
\frac{H}{2} \times \frac{W}{2} \times 2C \xrightarrow{\text{channel-to-space}} H \times W \times \frac{C}{2} \\ \underbrace{\xrightarrow{\text{duplicate}} [H \times W \times \frac{C}{2}, H \times W \times \frac{C}{2}] \xrightarrow{\text{concat}} H \times W \times C.}_{\text{channel duplicating}}
2H×2W×2Cchannel-to-spaceH×W×2Cchannel duplicating
duplicate[H×W×2C,H×W×2C]concatH×W×C.
解释
在这个部分,我们讨论的是如何在上采样块中处理特征图(图像数据)。具体步骤如下:
-
开始时的特征图:
- 假设我们有一个大小为 H 2 × W 2 × 2 C \frac{H}{2} \times \frac{W}{2} \times 2C 2H×2W×2C 的特征图。这意味着它的高度和宽度都是原来的一半,但通道数是原来的两倍。
-
通道到空间的转换:
- 我们首先将这个特征图进行“通道到空间”的操作。这样做后,特征图的大小变为 H × W × C 2 H \times W \times \frac{C}{2} H×W×2C。也就是说,特征图的高度和宽度恢复到了原来的大小,但通道数减半。
-
通道复制操作:
- 接下来,我们将这个新的特征图复制一份,得到两个一模一样的特征图,形状都是 H × W × C 2 H \times W \times \frac{C}{2} H×W×2C。这一步是为了后面将信息结合得更好。
-
拼接操作:
- 最后,我们把这两个特征图拼接在一起,形成一个新的特征图,大小为 H × W × C H \times W \times C H×W×C。这样,通道数恢复到了原来的 C C C。
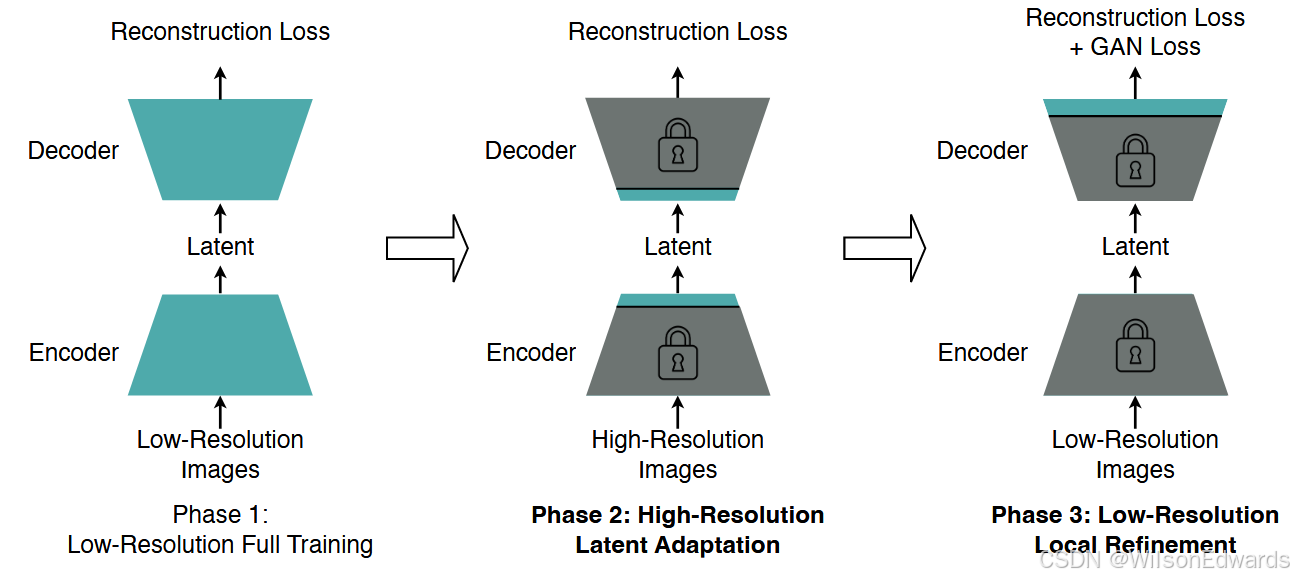
图 6:高分辨率解耦适应的示意图。
翻译
除了下采样和上采样模块外,我们还根据相同的原则更改了中间阶段的设计(图 4 b,右侧)。图 3 (a) 显示了在 ImageNet 256 × 256 上有无残差自编码的比较。我们可以看到,残差自编码有效提高了高空间压缩自编码器的重建准确性。
翻译
解耦高分辨率适应。仅仅依靠残差自编码在处理低分辨率图像时可以缩小准确性差距。然而,当将其扩展到高分辨率图像时,我们发现这并不足够。由于高分辨率训练的成本较大,高分辨率扩散模型的常见做法是直接使用在低分辨率图像(例如,256 × 256)上训练的自编码器(Chen et al., 2024b;a)。这种策略对于低空间压缩自编码器效果良好。然而,高空间压缩自编码器会出现显著的准确性下降。例如,在图 3 (b) 中,我们可以看到,当从 256 × 256 泛化到 1024 × 1024 时, f 64 f64 f64 自编码器的 r F I D rFID rFID从 0.50 降低到 7.40。相比之下, f 8 f8 f8 自编码器在相同设置下的 r F I D rFID rFID从 0.51 提高到 0.19。此外,我们还发现当使用更高的空间压缩比时,这个问题更为严重。在本研究中,我们将这种现象称为高空间压缩自编码器的泛化惩罚。解决这个问题的一个直接方法是在高分辨率图像上进行训练。然而,这会带来较大的训练成本和不稳定的高分辨率 GAN 损失训练。
解释
在这一段中,作者提到仅靠“残差自编码”在处理低分辨率图像时能减少错误,但对于高分辨率图像就不够用了。因为高分辨率训练费用很高,很多时候研究者选择用在低分辨率图像上训练的模型来处理高分辨率图像。然而,这样会导致准确性明显下降,比如一个模型在处理低分辨率时效果很好,但一旦切换到高分辨率,其准确性就大幅下降。作者称这种现象为“泛化惩罚”。虽然在高分辨率图像上训练是解决方案,但这会带来高成本和训练不稳定的问题。
翻译
我们引入了解耦高分辨率适应以应对这一挑战。图 6 演示了详细的训练流程。与传统的单阶段训练策略(Rombach et al., 2022)相比,我们的解耦高分辨率适应有两个关键区别。首先,我们将 GAN 损失训练与完整模型训练解耦,并引入专门的局部精细化阶段用于 GAN 损失训练。在局部精细化阶段(图 6,第 3 阶段),我们仅调整解码器的头层,而冻结其他所有层。这一设计的直觉基于这样的发现:仅凭重建损失就足以学习重建内容和语义。同时,GAN 损失主要改善局部细节并去除局部伪影(图 5)。通过仅调整解码器的头层达到相同的局部精细化目标,这种方法具有更低的训练成本,并比完整训练提供更好的准确性。此外,解耦防止了 GAN 损失训练改变潜在空间。这种方法使我们能够在低分辨率图像上进行局部精细化阶段,而无需担心泛化惩罚。这进一步降低了第 3 阶段的训练成本,并避免了高度不稳定的高分辨率 GAN 损失训练。其次,我们引入了一个额外的高分辨率潜在适应阶段(图 6,第 2 阶段),调整中间层(即编码器的头层和解码器的输入层),以适应潜在空间,从而缓解泛化惩罚。在我们的实验中,我们发现仅调整中间层就足以解决这个问题(图 3 b),同时其训练成本低于高分辨率完整训练(内存成本:153.98 GB → 67.81 GB)1(Cai et al., 2020)。
解释
在这一段中,作者介绍了一种新的方法来提高模型处理高分辨率图像的效果。与之前只用一种训练方式不同,他们的方案有两个主要改进。首先,他们把 GAN 损失的训练和整体模型训练分开,专门为 GAN 损失引入一个局部精细化阶段。在这个阶段,他们只调整解码器的某些部分,而不改变其他部分,这样可以节省训练成本,同时提高准确性。第二,他们增加了一个新的高分辨率潜在适应阶段,调整模型的中间部分,使其更适合处理高分辨率数据,这样可以降低泛化惩罚的问题。通过这些改进,训练的内存需求大大减少,训练也变得更加稳定。
翻译
3.3 应用到潜在扩散模型
将我们的深度压缩自编码器(DC-AE)应用到潜在扩散模型非常简单。唯一需要改变的超参数是补丁大小(Peebles & Xie, 2023)。对于扩散变换模型(Peebles & Xie, 2023; Bao et al., 2023),增加补丁大小
p
p
p 是减少令牌数量的常见方法。这相当于首先对给定潜在图像应用空间到通道操作,将空间大小缩小
p
p
p 倍,然后使用补丁大小为
1
1
1 的变换模型。由于将低空间压缩自编码器(例如,
f
8
f8
f8)与空间到通道操作结合也可以实现高空间压缩比,因此自然会出现一个问题,即与直接使用 DC-AE 达到目标空间压缩比相比,效果如何。我们进行了消融研究实验,并在表 1 中总结了结果。我们可以看到,直接使用自编码器达到目标空间压缩比的效果在所有设置中都是最好的。此外,我们还发现将空间压缩比从扩散模型转移到自编码器始终能带来更好的 FID(Fréchet Inception Distance)。我们推测,这是因为当使用补丁大小
>
1
> 1
>1 时,潜在扩散模型需要同时学习去噪和令牌压缩。当自编码器承担整个令牌压缩任务时,扩散模型可以完全专注于去噪任务,从而实现更好的效果。
解释
这一部分讨论了如何将新的自编码器(DC-AE)应用于图像生成的潜在扩散模型。简单来说,改变补丁的大小是唯一需要调整的参数。增加补丁的大小可以减少模型处理的图像片段数量。这就像先把一幅图像缩小,然后用小块来分析它。
研究表明,直接使用 DC-AE 达到目标的图像压缩效果最好。将压缩工作交给自编码器后,扩散模型可以更专注于去噪,效果也会更好。这就像把一些复杂的任务分配给不同的人,让每个人专心做好自己的工作。这样,整体效果自然就更佳了。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











