







语言:python
目的:通过url直接对某一视频进行定向爬取
所需库:requests,lxml,re,os
问题分析:随便打开一个某站视频,点击播放,你发现其就是一个局部动态加载,考虑一手ajex情况,谷歌浏览器F12,打开谷歌自带的调试工具,在网络模块打开xhr/fetch模块
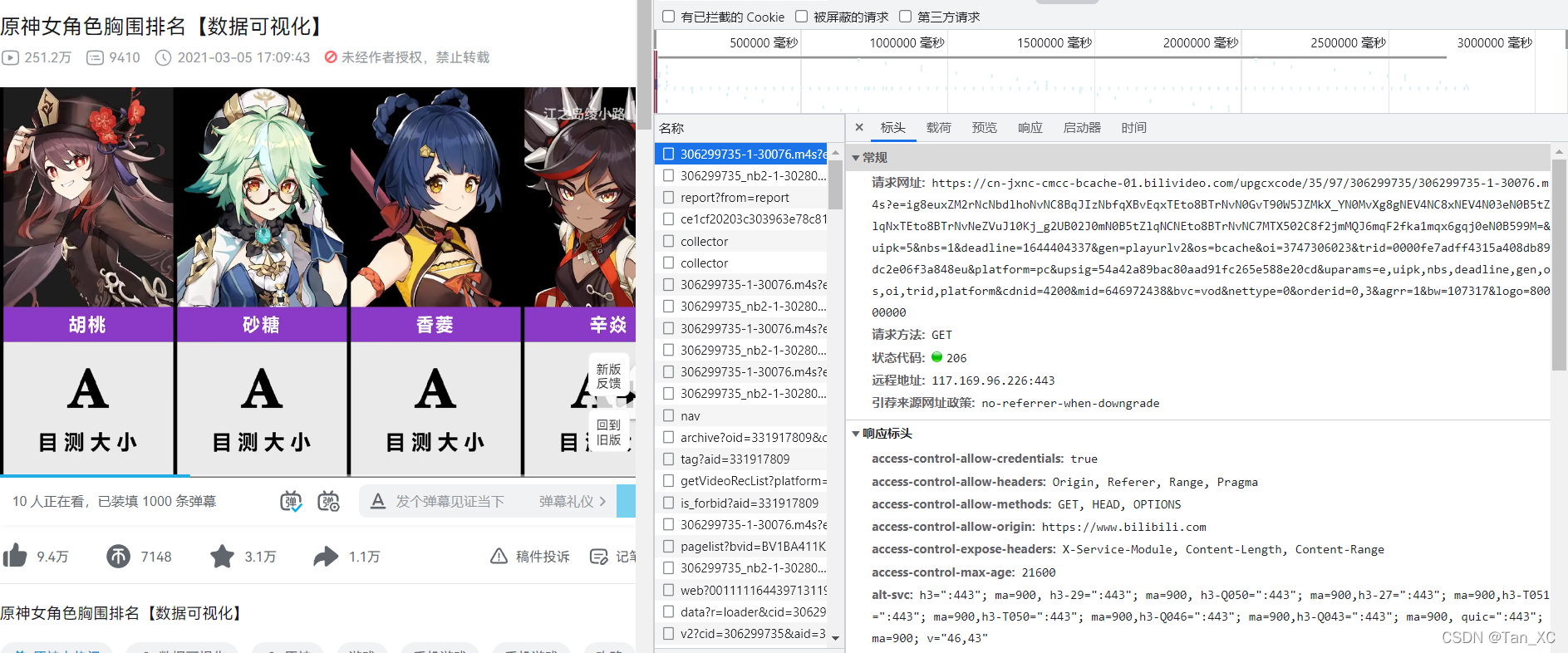
按时间顺序查包看其响应,发现前两个包很特殊,响应式二进制文件,正好所需视频都是以二进制文件存在,分别编写程序对其URL发送请求,保存其响应,你可以发现,这两个响应一个对应视频文件,一个对应音频文件。
那么到这我们所需的内容已经找到了,但是这和我们的初衷不符合,我们的初衷是通过B站的URL直接保存视频,明显这个两个url和我们的目标url不一致且无明显关系,网站一定会把目标视频音频的url放回到我们的响应中或者网页原码中,复制目标视频的url,CTRL+F在网页原码搜索,你会惊奇的发现
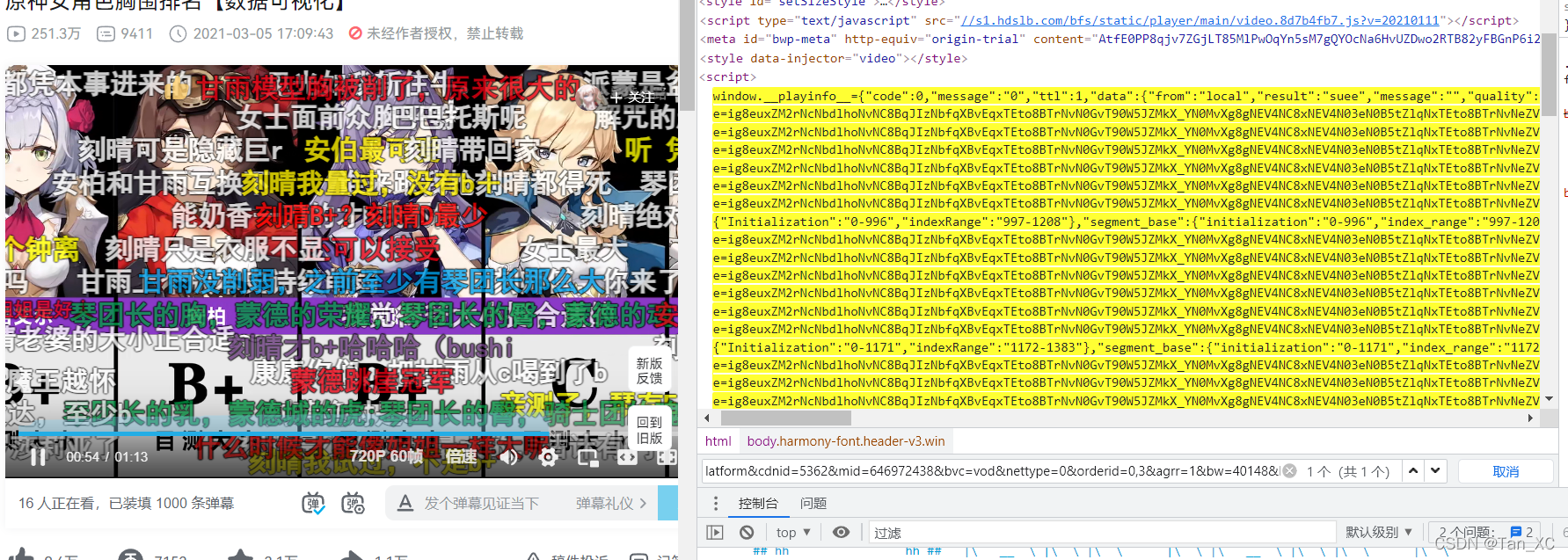
原来目标
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











