






一,JDK,JRE,JVM之间的区别
一,计算机的最主要的几个部件
1.CPU:中央处理器,负责发送并执行指令,负责计算,负责运算;
2.内存:程序在临时运行过程中临时数据的存储空间 ,断电之后或者关机之后内存的数据就消失。
二,JDK,JRE,JVM
1.JDK:JAVA开发工具箱
2.JRE:java运行环境
3.jvm:java虚拟机,不能够独立安装
安装的顺序,当用户下载安装jdk时,Java运行环境jre自动安装并且jvm也自动安装成功。
4.JVM可以识别的是字节码:
java代码这种普通文本通过jre编译成字节码后才可以被jvm识别
5.数据类型的作用:不同的数据类型,在内存中分配不同空间大小

根据数据的类型分配不同大小的内存空间
byte 1 个字节
char,short 2个字节
int,float 4个字节 1个字节8个比特
long,double 8个字节

6.字符编码:
在字符编码中规定了一系列的文字对应的二进制。
7.字符的转换:当大容量的字符向小容量转换时称为强制类型转换,在Java开发中比较常用 向上转型
在类型转换时需要的遵循的原则:
(1)除了boolean类型之外其他的7中数据类型都可可以进行转换
(2)如果整型字面量没有超出byte,short,char可以直接赋值给byte,short,char类型的变量。
(3)大容量转小容量称为强制类型的转换,编写时必须添加“强制类型转换符”,但在运行时可能出现精度损失。
8.标识符可以标识:
类名,接口名,变量名,方法名,常量名
9.标识符的,命名的规则
只能有数字,字母,(可以有中文)下划线,美元符号组成不能有其他的符号
(1)标识符不能以数字开头
(2)标识符严格区分大小写
(3)关键字不能作为标识符
10.java中的方法,没有方法会怎么样????
(1)方法是自上而下的顺序逐行执行的
(2)方法定义在类体中
【修饰符列表】 返回值类型 方法名(形式参数列表){ 方法体 }
return 是用来截止方法的
10.JVM:
(1)栈内存:方法调用的时候,该方法需要的内存空间在栈中分配
(2)堆内存: 堆允许程序在运行时动态地申请某个大小的内存空间
(3)方法区内存:方法区中存放代码片段,存放class字节码
方法只有被调用的时候才会在栈中分配空间
(1)局部变量:当方法执行时开辟空间
(2)实例变量:当构造方法执行时,对象创建,分配空间
(3)静态变量:类加载时初始化,分配空间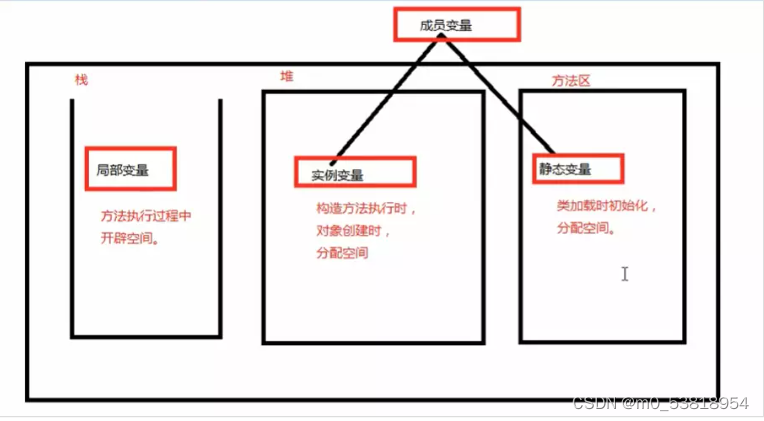
(4)对象和引用的区别
对象是通过new出来的,在堆内存中存储
引用是但凡是变量,并且该变量中保存了内存地址指向了堆内存中的对象

11.数据结构:栈帧永远指向站顶部元素
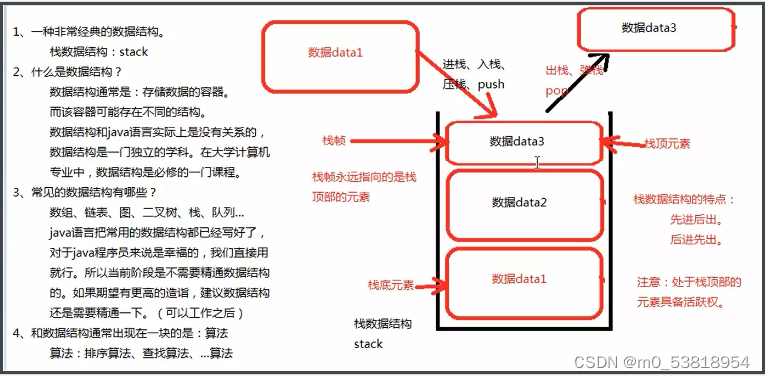
12.内存图:

13.数组的算法两种排序
(1)冒泡排序:从左往右,依次相比
for (int i=arr.length-1;i>0;i--){
for (int j=0;j<i;j++) {
// System.out.println(i);
if (arr[j]>arr[j+1]){
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
for (int i=0;i<arr.length;i++){
System.out.println(arr[i]);
}
(2)选择排序
选择排序要比冒泡排序的效率高,选择排序的每次交换位置都有意义!!
14.java中对异常的处理有两种方式:
(1)在的方法的声明上吗,使用Throws关键字,抛给上一级!!
(2)使用try。。。catch语句进行异常的捕,catch后面的异常类型可以是具体的也可以是包含他的!
二,JAVA的面向对象思想
1.java面向对象的基本概念:
java是面向对象的编程语言,对象就是面相对象程序设计的核心,所谓对象就是真实世界中的实体,对象与实体是一一对应的,也就是说世界中每一个实体都是一个对象,他是一个具体的概念!
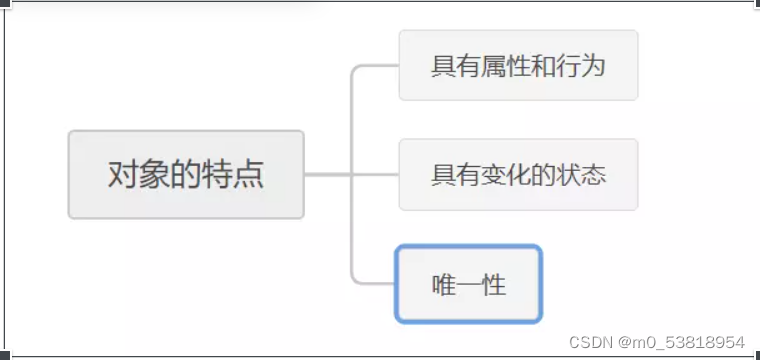
2.对象具有的特点:
2.面向对象的三大核心特性:
(1)可重用性:代码可以重复使用,提高开发效率
(2)可扩展性:新的功能可以很容易的加入到系统中,便于软件的修改
(3)可管理性:能够将数据与功能相结合,便于管理
3.继承性:
3.1在JAVA中的继承性是指子类拥有父类的全部特征和行为,继承性是类与类之间的关系,
3.2在JAVA中只支持单继承不支持多继承,只允许一个类继承另一个类
3.3即子类只能有一个父类,关键词extends后面只能有一个类名;
4.封装性:
4.1封装是将代码及其所处理的数据绑定在一起的一种编程机制,该机制是保证程序和数据都不受外部干扰和误用;
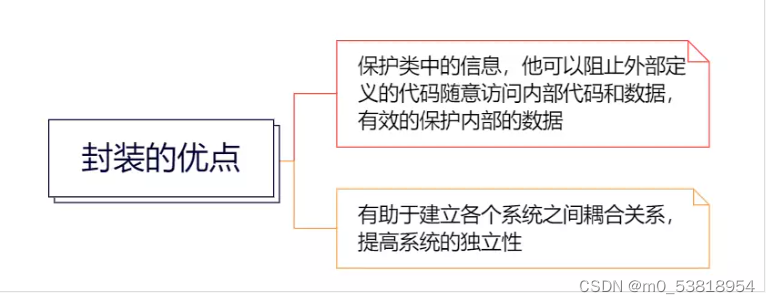
4.2java语言的基本封装单位是类,封装的目的是在于保护信息!提供私有和公有的访问模式。
4.3封装的主要优点
4.4实现封装的步骤:

5.java的多态性:
面向对象的多态性是:一个接口,多个方法。多态性体现在父类中定义的属性和方法被子类继承后,可以具有不同的属性或表现形式。多态性允许一个接口被多个同类使用,弥补了单继承的不足,对面向对象来说,多态分为--编译时多态和运行时多态;
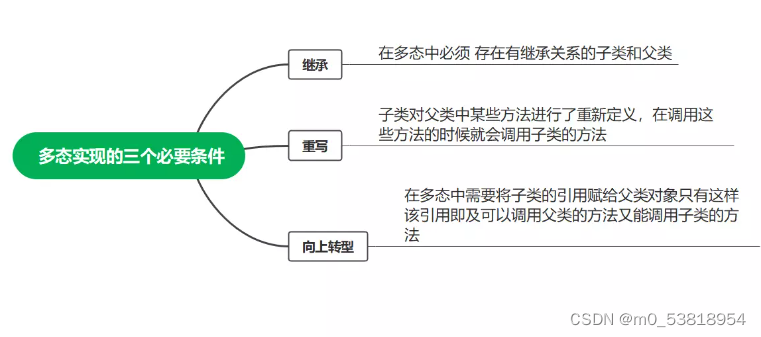
java实现多态有三个必要的条件:继承,重写,向上转型!
6.什么是类:类是描述一组具有相同属性和相同方法的一组对象的集合,对象所拥有的特征在类中表示时称为类的属性
在java中类似构成面向对象的程序的基本单位
对象所执行的操作成为类的方法
7.什么是方法的重写?(override)在java中子类中创建一个与父类有相同的名称,相同的返回值类型,相同的参数列表 ,只是方法体中的实现不同,以实现不同于父类中的功能!
7.1方法重写的原则
(1)参数列表(参数的个数和参数的类型)必须完全与被重写的方法参数列表相同;
(2)函数的返回类型必须与重写的方法的返回类型相同
(3)重写的方法的访问权限不能比父类的中被重写的方法的访问权限低,(public>protect>default>private)
(4)重写的方法一定不能抛出新的检查异常,例如:父类的一个方法声明了一个检査异常 IOException,在重写这个方法时就不能抛出 Exception,只能拋出 IOException 的子类异常,可以抛出非检査异常。
(5)父类的成员只能被他的子类重写,构造方法也不能被重写
(6)声明为static的方法不能被重写但是能够再次声明
8.什么是方法的重载?(overload)在java中允许同一个类中定义多个同名的方法,只要他们打的参数列表不同即可。如果不能继承一个方法那么就不更不可能重写了!
(1)方法名相同
(2)方法的参数不同,参数的个数,参数的类型不同
三,数据集合模型

一,ArrayList的注意按事项
- 1.1.可以加入null并且是多个
- 1.2.是由数组来实现数据存储的
- 1.3.基本等同于Vector除了ArrayList是线程不安全(执行效率高)在多线程情况下,不建议使用ArrayList
- 1.3.当使用多线程任务时,要是用Vector比较合适!!!
二,ArrayList的扩容机制
/** * (1)如果元素的个数+1小于等于Capacity那就放心的添加元素; *(2)元素个数+1大于Capavity,那Array就会发生孔融机制,容量变为原来的1.5倍Capacity * Capacity=Capacity+Capacity>>1,Capacity>>1是指Capacity这个数进行位运算, * 而且是左移运算,左移一位,所以Capacity>>1其实就是0.5个Capacity * 所以Capacity+Capacity>>1就等于1.5Capacity+Capacity) */
扩容机制:
private void grow(){
int oldCapacity=elementData.length;
int newCapacity=oldCapacity+(oldCapacity >>1);
if (newCapacity-minCapacity<0)
newCapacity = minCapacity;
if (newCapacity-MAX_ARRAY_SIZE>0)
newCapacity=hugeCapacity(mincapacity);
}
(1) Vector类的定义说明:
public class Vector<E>extends AbstractList<E>
implements List<E>, RandomAccess,Cloneble,Serializable
(2) Vector底层也是一个数组,protected Object【】elementData;
(3)Vector 是线程同步的,即线程的安全,Vector类的操作方法带有关键字
(4)在开发中,需要线程同步安全时,考虑使用Vector
一.开始集合的概述
(1)集合实际上就是一个容器,可以容纳其他类型的数据,可以一次容纳多个对象;集合本身就是一个对象,仍何时候存储的都是引用!!
(2)集合里面不能存储基本数据类型,另外java集合也不能字节存储Java对象,在集合当中存储的是Java对象的内存地址。
(3)new ArrayList();创建一个集合,底层是数组
new LinKedList() ;创建的是一个集合对象,底层是链表
new TreeSet();创建一个集合对象,底层是二叉树
- (4)集合的大致框架
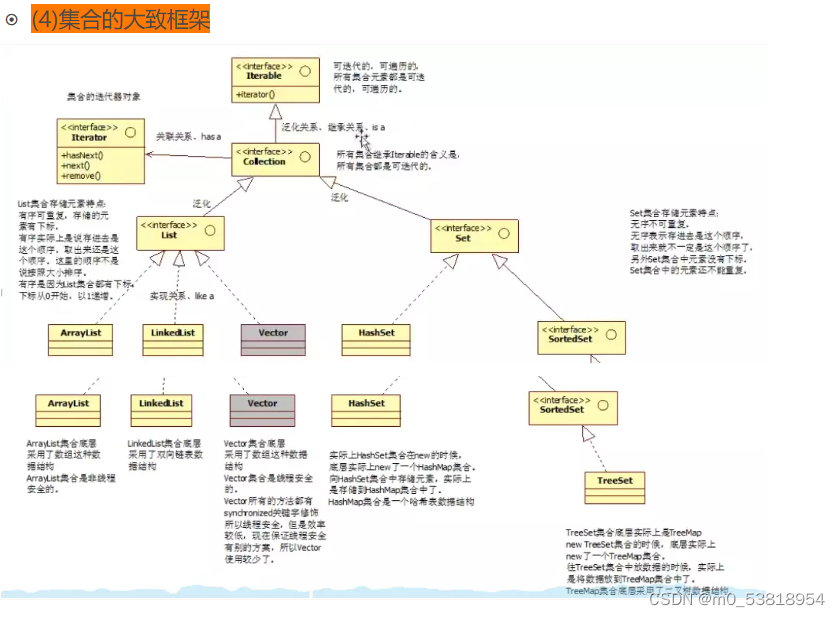
2.Collection中能存放什么样的对象,没有使用“泛型”之前可以存储Object所有的子类型,集合中不能直接存储基本数据类型,也不能存储java对象,只是存储Java对象的内存地址。
3.collection结合的迭代器
都是迭代器对象的方法
boolean hasNext();
Object next();
放在集合中的元素一定要重写equals()方法,这个equals方法的比较原理,只要姓名一样就表示同一个用户;
public boolean equals(Object obj){
if (obj==null||!(obj instanceof Student)) return false;
if (obj==this) return true;
Student s =(Student )obj;
return s.name.equals(this.name);
}
}
4.ArrayLIst()集合的底层是数组,应该怎么优化?:Arrahlist()集合应该尽可能少的进行扩容,,因为数组的扩容的效率比较低,建议在使用Arraylist()集合时候预估元素的个数,给定一个初始化的容量;数组的优点是:检索(每个元素占用的空间大小相同,知道元素的内存地址,让后知道下标,通过数学表达式计算出元素的内存地址,所以检索的效率最高)的效率的比较高,,向数组末尾添加元素时,效率不受影响:
5.集合面试题:这么多的集合中,你用哪一个集合比较多?
当然是ArrayList(集合比较多)因为在数组的末尾添加元素时,效率不受影响,另外我们在检索或者查找某个元素的操作比较多!!
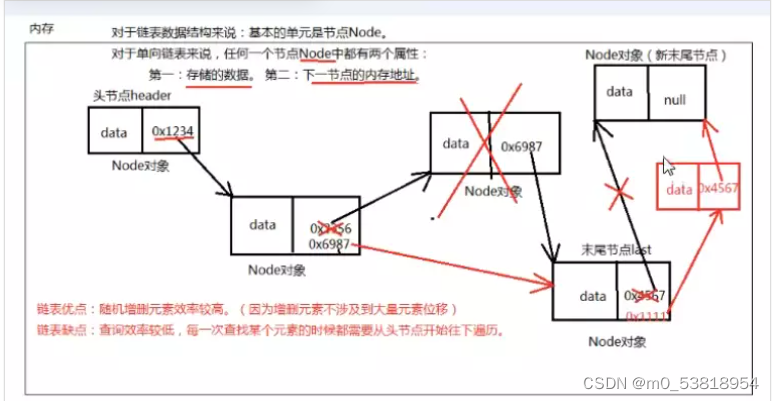
6.单链表中的节点:
节点是单向链表的基本单元,每一个节点Node都有两个属性:
(1)是存储的数据
(2)下一个节点的内存地址
7.链表的优点:随机的增删元素的效率高(数组的增删元素的效率低),(因为增删元素不涉及大量元素位移)
8.链表的缺点:(数组的查询效率高)查询效率低。每一次查找元素都需要从头结点开始往下遍历;
ArrayList:把检索功能发挥到了极致
LinkedList:把随记增删发挥到了极致
9.LinkedList内存图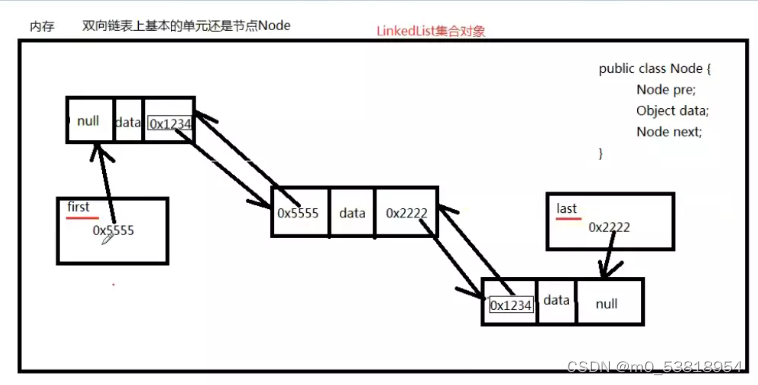
10.LinkedList集合没有初始化容量,最初这个链表没有任何元素,first和last引用都是null。因为我们面向接口编程。
10.讲一个线程不安全集合安全转换成一个线程安全的:
List mylist=new ArrayList();//非线程安全的 Collections.synchronizedList(mylist);
Collections.synchronizedList(Object)
11.泛型机制:(Generic)泛型只在编译阶段起作用,而在运行阶段泛型没有用。使用泛型的好处:(1)集合中存储的元素类型统一(2)从集合中取出的元素类型是泛型指定的类型,不需要进行大量的“向下转型”缺点:导致集合中存储的元素缺乏多样性。
12.自动类型推断机制<>
13.自定义泛性
14.增强foreach循换,结构:
for( 数据类型 变量名 : 数组或者集合 ){ System.out.println(变量名) }
缺点:foreach没有下标,在需要使用下标的循环中,不建议使用增强for循环。
15.Map:map和collection没有任何继承关系;map集合一key和value的方式存储数据---键值对,key和value都是引用数据类型,都是存储对象的内存地址,key起到了主导的地位,value是key的一个附属品
Map集合中的常用方法:
put(K key,V value)//向map集合中添加键值对
(第一种方式)获取key和value
Set<Map.Entry<Integer,String>> set =map.entrySet();
Iterator<Map.Entry<Integer,String>> it=set.iterator();
while (it.hasNext()) {
Map.Entry<Integer,String> node= it.next();
Integer key= node.getKey();
String value= node.getValue();
(第二种方式)获取key和value(比较适合大数据量)
for (Map.Entry<Integer,String> node:set) {
// Integer key= node.getKey();
// String value= node.getValue();
System.out.println(node.getKey()+"====="+node.getValue());
}
get(Object key)通过key获取value
16.HashMap查询的效率高而且增删改的效率也高,充分的结合了数组个单向链表的优点!!

17.HashMap集合底层的源代码:

(1)final int hash 哈希值是key的hashCode()方法执行的结果
(2) final K key 存储到map集合中的那个key
map.put(k,v)存入数据 v=map.get(kj0lo9
18.map.put(k,v)实现的原理:
第一步.现将k,v封装到Node对象中当中
第二步.底层会调用k的还是从的()方法得出hash值,然后通过hash值转换成数组的下标,如果下标位置上没有任何元素,就把Node添加到这个位置上,如果下表位置上哟偶这个链表,此时会拿着key和链表中的没一个节点z中的key进行比较equals,如果所有的equals都返回了false,那么这个新节点将被添加到链表的末尾,如果其中有一个equals返回来true那么这个节点的values值将会被覆盖。
3.v=map.get(k)的实现原理:
第一步:先调用key的还是从的()方法得出哈希值,通过哈希算法转换成数组的下标,通过数组的下标快速定位到某个位置上,如果在这个位置上什么都没有,返回null;如果在这个位置上有单向链表,那么拿着这个参数k和单向链表上的每个节点中的key进行equals,如果所有的equals返回false,那么get方法返回null;只要其中的一个节点key和参数k equals的时候返回true,那么此时这个节点的value的值是我们要找的value,get()方法返回最终要返回这个要找的value。
4.hashcode()和equals()这两个方法都要重写
5.散列分布不均匀
6.重点!!!
HashMAp集合初始化容量必须是2的倍数,这也是官方推荐的,这是因为可以达到散列均匀,为了提高HashMAP集合的存取效率所必需的!!hashmap的初始化容量是16,达到加在因子(0.76)75%会自动扩容!!!
7.hashmap的key和value都可以为空但是hashtable不都不可以为空!!
8.Treeset的底层是一个treemap,而treemap的底层是一个二叉树,放到treeset集合中的元素,等同于放入到treemap集合的key部分,treeset集合中的元素无序不可重复,但是可以按照元素的大小顺序自动的排序
9.TreeSet和TreeMap底层都是二叉树,迭代器采用的是中序遍历,
存放数据采用:遵循左小右大的原则
取出数据采用:中序遍历
10.放在treeset或者treemap集合key部分元素要做到排序,包括两种方式:
第一种:放在集合中的元素实现java.long.comparable接口
当比较规则不会发生改变的时候,或者说此时的比较规则只有一个的时候,建议实现Comparable接口
第二种:在构造treeset或者treemap集合的时候给她传递一个比较器对象
当比较规则有多个的时候,并且需要多个比较规则之间频繁切换,建议使用Conparator接口
11.ArrayList()集合是线程不安全的,要变成线程安全的则需要
12.学完集合之后要掌握那些知识:
/** * 1.每个集合的创建(new) * 2.向集合中添加元素 * 3.从集合中取出某个元素 * 4.遍历集合 */
(1)ArrayList集合,LinkedList集合
//ArrayList是线程不安全的
List<String> list=new ArrayList<>();
//转换成线程安全的
Collections.synchronizedList(list);
12.// 1.每个集合的创建(new)
ArrayList< String > list=new ArrayList<>();
// 2.向集合中添加元素
list.add("邓元湖");
list.add("张茜");
// 3.从集合中取出某个元素
System.out.println(list.get(0));
System.out.println(list.get(1));
// 4.遍历集合
//1.增强for循环
for (String n:list
) {
System.out.println(n);
//2.迭代器
Iterator it =list.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
//下标循环
for(int i=0;i<list.size();i++){
System.out.println( list.get(i));
}
}
}
}
(2)HashSet()集合,HashMap(hashmap的key,存储在hashmap集合的key元素需要同时重写hashcode和equals方法)集合
HashSet<String> set = new HashSet<>();
set.add("邓元湖");
set.add("张茜");
//1.增强for循环
for (String n : set) {
System.out.println(n);
}
//2.迭代器
Iterator it = set.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
HashSet<Setduixiang> mylist=new HashSet<>();
mylist.add(new Setduixiang(12,"邓元湖1"));
mylist.add(new Setduixiang(12,"张茜1"));
for (Setduixiang s:mylist
) {
System.out.println(s);
}
}
}
class Setduixiang {
int age;
String name;
public Setduixiang(int age,String name){
this.age=age;
this.name=name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Setduixiang that = (Setduixiang) o;
return age == that.age && Objects.equals(name, that.name);
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public String toString() {
return "Setduixiang{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
(3)TreeSet()集合
(1)传入比较器
TreeSet<Person> persons=new TreeSet<>(new personCompare());
自定义String类型
(2)lass personCompare implements Comparator<Person> {
(4)Map()集合 map.put();存入元素
遍历map集合中的元素有两种方式
第一种:先获取key然后在遍历key的时候获取value
第二种:是将map集合转换成set集合,在set中每一个元素是node,这个node存放map集合中的键值对key和value,通过调用node.getKey()+"="+node.getValue()分别获取key和value的值
/**
* 1.每个集合的创建(new)
* 2.向集合中添加元素
* 3.从集合中取出某个元素
* 4.遍历集合
*/
public class MapPreview {
public static void main(String[] args) {
Map<Integer,String > map=new HashMap<>();
map.put(1,"邓元湖");
map.put(2,"张茜");
map.put(3,"张三");
map.put(3,"李四");//如果key重复的话,Value会被覆盖
//遍历map集合
//第一种方式:先获取key在遍历key的时候通过key获取value
Set<Integer> keys=map.keySet();
for (Integer key:keys) {
String value=map.get(key);
System.out.println(key+"="+value);
}
//第二种方式:将map集合转换成set集合,set集合中的每一个元素是node,
// 这个node存放的有key和value
Set<Map.Entry<Integer,String>> nodes=map.entrySet();
for (Map.Entry<Integer,String> node:nodes) {
System.out.println(node.getKey()+"="+node.getValue());
}
}
}
(5)properites getProprorites
四,多线程,并发编程
1.什么是进程:是一个软件,一个应用,一个进程可以启动多个线程
2.什么是线程:是一个进程也可以说是一个程序运行的分支!
3.进程和线程之间的关系:
(1)两个不同的进程之间,不共享资源!
(2)两个不同的线程堆内存(实例变量)和方法区(静态变量)之间可以实现资源共享
(3)一个线程对应一个栈内存,占内存是一个线程的独立空间。
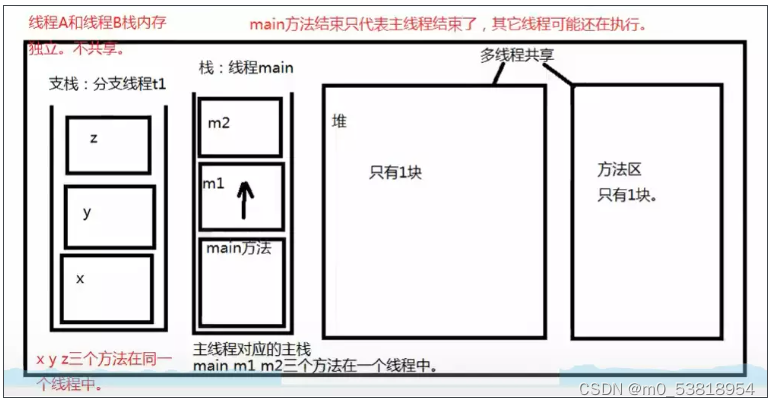
问题1:使用了多线程机制后,main方法结束后,是不是可能程序也不会结束。
答:main方法结束只是主线程结束,只是主栈内存释放了,但是其他的栈(线程)可能还在压栈弹栈!
问题2:单核的CPU不能够做到真正的多线程并发,但是可以做到给人一种“多线程并发的感觉”对于单核的CPU来说,在某一个时间点上,实际上只在做一件事,只执行一个进程,但是由于CPU的处理速度比较快,多个线程之间频繁的切换执行,给我们的感觉是多个事情都在同时执行,既感觉多线程在并发执行!
4.线程的第一种实现的方法:
(1)方法一 ,继承 extends Thread类 通过调用 start()方法来实现的,重写run(){ 方法体} 来创建运行
@
public class Threadtest {
/**
* mythread.start();
* start()方法的作用是:启动一个分支线程,在JVM中开辟一个新的栈空间,这段代码完成之后,瞬间就结束了
* 这段代码的任务就是为了开启一个新的栈空间,只要新的栈空间开辟出来,start()方法就结束了,线程启动成功了
* 启动成功的线程会自动调用分支线程里面的方法,并且分支线程方法在分支栈底部(压栈)
* 分支线程的方法在分支栈的地步,main()方法在主栈的底部。此时分支栈类的方法与main()方法是同级的;
*/
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
for (int i=0;i<100;i++){
System.out.println("主线程-----------------"+i);
}
}
}
class MyThread extends Thread{
@Override
public void run() {
for (int j=0;j<100;j++){
System.out.println("分支线程》》》》》》》》》"+j);
}
}
}
(2)方法二, 编写一个类实现 java.long.runnable接口
这种方式比较常用,因为一个类实现了一个接口,它还可以去继承其他的类,显得更加灵活!
//创建一个可运行的对象
// myRunnable m =new myRunnable();
//讲一个可运行的对象封装成一个线程对象
Thread t=new Thread(new myRunnable());
t.start();
for (int j=0;j<1000;j++){
System.out.println("我是主线程"+j);
}
}
}
class myRunnable implements Runnable{
@Override
public void run() {
for (int i=0;i<990;i++){
System.out.println("我是分支线程"+i);
}
}
}
(3)使用内部类创建多线程
//使用匿名内部类也可以实现多线程操作
public static void main(String[] args) {
Thread t=new Thread(new Runnable() {
@Override
public void run() {
for (int i=0;i<1010;i++){
System.out.println("分支线程"+i);
}
}
});
t.start();
for (int j=0;j<1100;j++){
System.out.println("主线程"+j);
}
}
}
5.现成的生命周期

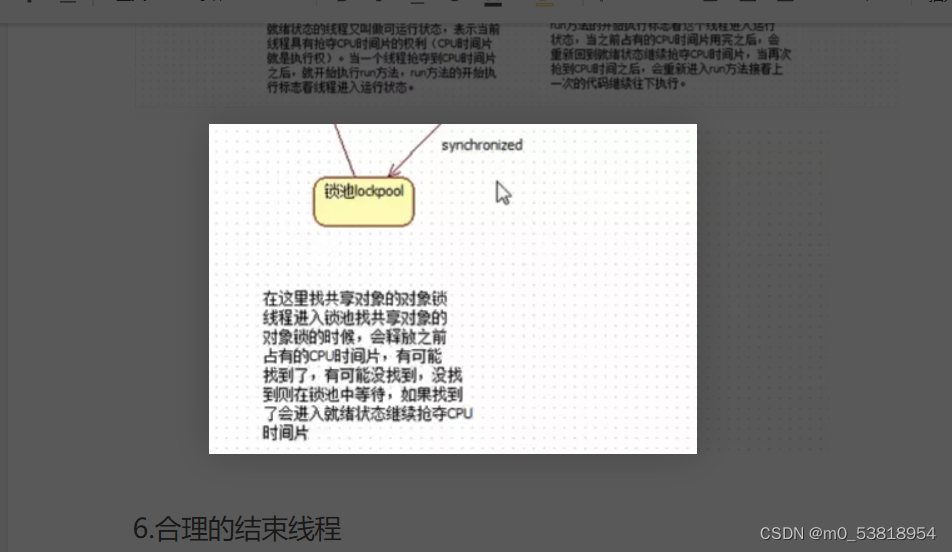
6.合理的结束线程
public static void main(String[] args) {
myThread5 r = new myThread5();
Thread t=new Thread(r);
t.setName("线程测试!!!");
t.start();
try {
Thread.sleep(1000*8);
} catch (InterruptedException e) {
e.printStackTrace();
}
r.run=false;
System.out.println(Thread.currentThread().getName()+"----->");
}
}
class myThread5 implements Runnable{
boolean run =true;
@Override
public void run() {
for (int i = 0; i < 6; i++) {
if (run){
System.out.println(Thread.currentThread().getName()+"---->"+i);
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}else
//终止当前进程//save
return;
}
}
}
7.线程的调度(抢占式模式)
(1)最低优先级是----1
(2)默认优先级设计 -----5
(3)最高优先级是 -----10
优先级比较高的获取CPU时间片可能会多一些
8.重点!!线程的安全问题
多线程并发取款问题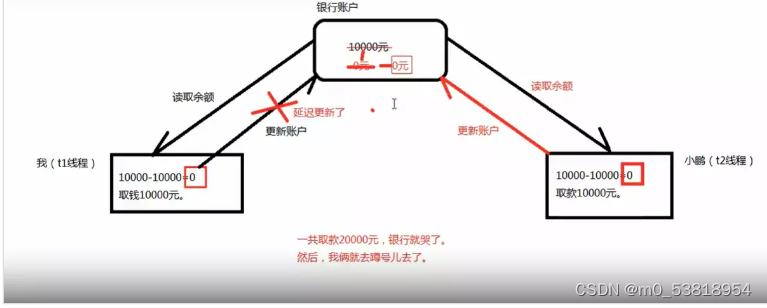
8.怎么解决线程的安全问题?????
java线程排队执行(不能并发异步就是并发
!!),用线程排队执行解决线程的安全问题,这种机制被称为:线程同步机制!
线程同步----为了确保在任何时间点一个共享的资源只被一个线程使用!
8.1java中哪些变量存在线程安全问题
(1)局部变量:局部变量在栈内存中,永远不会共享,永远不会存在线程安全问题!
(2)静态变量
(3)实例变量:在类体中定义的变量
9.自己模拟的同步线程对银行账户,安全的取款,代码如下:
package 同步线程取款问题;
import java.util.Scanner;
public class Account {
private String zhanghu;
private Double yue;
//无参构造
public Account(){
}
//有参构造
public Account(String zhanghu,double yue){
this.zhanghu=zhanghu;
this.yue=yue;
}
public String getZhanghu() {
return zhanghu;
}
public void setZhanghu(String zhanghu) {
this.zhanghu = zhanghu;
}
public Double getYue() {
return yue;
}
public void setYue(Double yue) {
this.yue = yue;
}
//做取款操作,取款方法
public void withdraw(double money) {
synchronized (zhanghu) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
double before = getYue();
double after = before - money;
this.setYue(after);
}
}
}
class myAccount implements Runnable{
private Account zh;
public myAccount(Account zh){
this.zh=zh;
}
@Override
public void run() {
System.out.println("请输入你要取款的金额:");
Scanner sc=new Scanner(System.in);
double money =sc.nextInt();
// double money=50;
zh.withdraw(money);
System.out.println(
"当前线程是"+Thread.currentThread().getName()+" "
+"取款成功"+" "+"取款金额为"+money+
" "+"账户余额为"+this.zh.getYue());
}
public static void main(String[] args) {
Account zu =new Account("邓元湖",1000);
Thread t1=new Thread(new myAccount(zu));
Thread t2=new Thread(new myAccount(zu));
t1.start();
t2.start();
}
}
上述代码分析:当synchronized( 共享对象 ){ 代码块 }
当共享代码块越小时,执行效率越高!
9.synchronized可以在实例方法上使用
如果当synchronized出现在实例方法上,一定锁住的是this,而不能是其他的对象,缺点是这种方式不够灵活!!,而且表示整个方法都需要同步,可能会无故扩大同步的范围,导致程序的执行效率降低,所以这种方式不常用!!
10.synchronized的面试题当cynchronized加在静态类中时,会产生类锁,此时不管创建几个对象;类锁只有一把!!都需等待!
11.问题:在以后的工作开发中怎么解决线程的安全的问题???
方案一:尽量使用局部变量来代替“实例变量”和“静态变量(是被static修饰的)”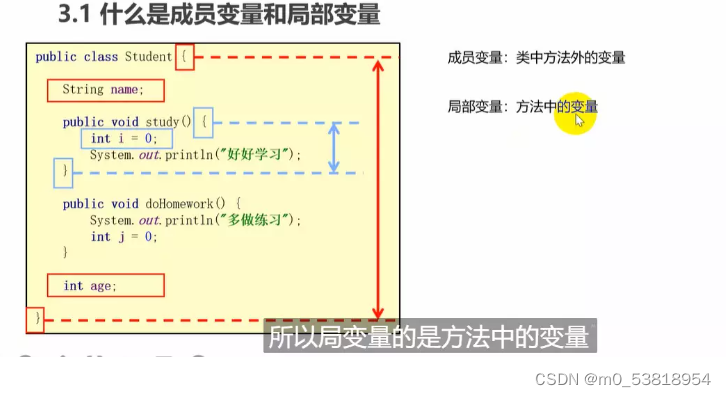
、
方案二:如果必须使用实例变量的话,那么可以考虑创建多个对象,这样实例变量的内存就不共享了(一个线程对应一个对象,对象不共享,就没有数据安全问题!)
12.在java语言中线程分为两类:
(1)用户线程
(2)守护线程(后台线程)垃圾回收线程
13.实现线程的第三种方式 实现Callable接口
14.关于object类中的wait和notify方法

15.线程中的生产者与消费者,wait方法和notify方法建立在xynchronized线程同步基础之上!
重点是:o.wait()方法会让正在o对象上活动的当前线程进入等待状态,并且释放之前战友的o对象的的锁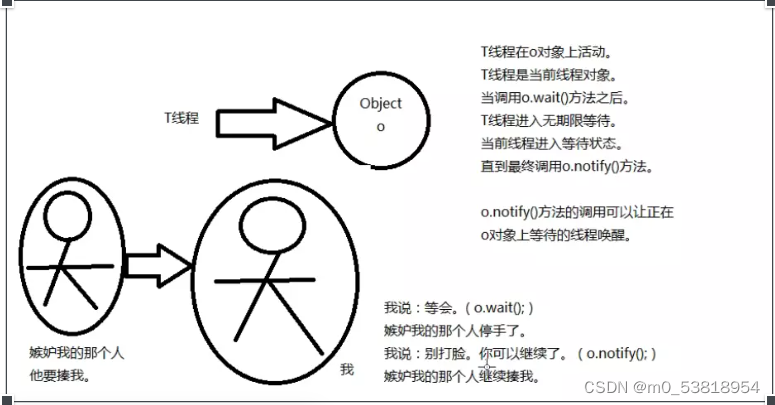
o.notify()方法只会通知,不会释放之前占有的o对象锁!!
















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











