






在代码编程中,总是遇到类中实现了Serializable:
那么Serializable是什么,我们又为什么要试下它呢?
在阅读资料中知道:
一个对象序列化的接口,一个类只有实现了Serializable接口,它的对象才能被序列化。
Serializable是java.io包中定义的、用于实现Java类的序列化操作而提供的一个语义级别的接口。
Serializable序列化接口没有任何方法或者字段,只是用于标识可序列化的语义。
实现了Serializable接口的类可以被ObjectOutputStream转换为字节流,同时也可以通过ObjectInputStream再将其解析为对象。例如,我们可以将序列化对象写入文件后,再次从文件中读取它并反序列化成对象,也就是说,可以使用表示对象及其数据的类型信息和字节在内存中重新创建对象。
什么是序列化?
序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。
为什么要序列化对象
把对象转换为字节序列的过程称为对象的序列化
把字节序列恢复为对象的过程称为对象的反序列化
序列化对于面向对象的编程语言来说是非常重要的,因为无论什么编程语言,其底层涉及IO操作的部分还是由操作系统其帮其完成的,而底层IO操作都是以字节流的方式进行的,所以写操作都涉及将编程语言数据类型转换为字节流,而读操作则又涉及将字节流转化为编程语言类型的特定数据类型
什么情况下需要序列化?
当我们需要把对象的状态信息通过网络进行传输,或者需要将对象的状态信息持久化,以便将来使用时都需要把对象进行序列化。
那为什么还要继承Serializable。那是存储对象在存储介质中,以便在下次使用的时候,可以很快捷的重建一个副本。
而当我点开Serializable时
此时会发现里面什么都没有,它只是一个空的接口:
那它存在的意义是什么呢?
在Java中的这个Serializable接口其实是给jvm看的,通知jvm,我不对这个类做序列化了,你(jvm)帮我序列化就好了。Serializable接口就是Java提供用来进行高效率的异地共享实例对象的机制,实现这个接口即可。
再到serialversionUID:

为什么要定义serialversionUID变量
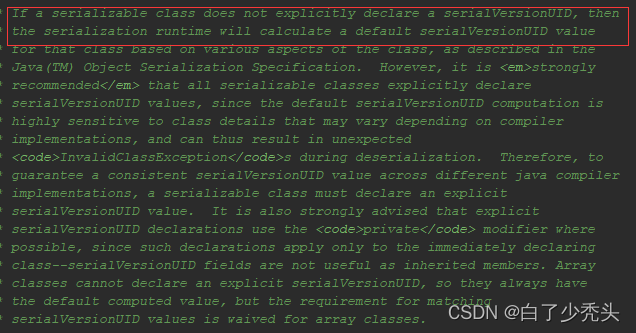
我们可以在serialversion接口中看到,当我们没有定义serialversionUID时,它会自动默认给我们生成一个serialversionUID。我们可以看到,它强烈建议我们自己定义一个serialversionUID,因为默认生成的serialversionUID对class极其敏感,在反序列化的时候很容易抛出InvalidClassException异常。
serialVersionUID属性是用来序列的标识符/反序列化的对象序列化类。
序列化运行时与每个可序列化的类关联一个版本号,称为serialVersionUID,在反序列化期间使用该版本号来验证序列化对象的发送者和接收者是否已加载了该对象的与序列化兼容的类
对于JVM来说,要进行持久化的类必须要有一个标记,只有持有这个标记JVM才允许类创建的对象可以通过其IO系统转换为字节数据,从而实现持久化,而这个标记就是Serializable接口。而在反序列化的过程中则需要使用serialVersionUID来确定由那个类来加载这个对象,所以我们在实现Serializable接口的时候,一般还会要去尽量显示地定义serialVersionUID。
这个serialVersionUID的详细的工作机制是:在序列化的时候系统将serialVersionUID写入到序列化的文件中去,当反序列化的时候系统会先去检测文件中的serialVersionUID是否跟当前的文件的serialVersionUID是否一致,如果一直反序列化不成功,就说明当前类跟序列化后的类发生了变化,比如是成员变量的数量或者是类型发生了变化,那么在反序列化时就会发生crash,并且回报出错误:
java.io.InvalidClassException: User; local class incompatible: stream classdesc serialVersionUID = -1451587475819212328, local class serialVersionUID = -3946714849072033140at
java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)at
java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1885)at
java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)at
java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)at
java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)at
java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)at
Main.readUser(Main.java:32)at Main.main(Main.java:10)刚开始提到了,serialVersionUID要不要指定呢?如果不指定会出现什么样的后果?如果指定了以后后边的值又代表着什么意思呢?既然系统指定了这个字段,那么肯定是有它的作用的。
如果我们在序列化中没有显示地声明serialVersionUID,则序列化运行时将会根据该类的各个方面计算该类默认的serialVersionUID值。但是,Java官方强烈建议所有要序列化的类都显示地声明serialVersionUID字段,因为如果高度依赖于JVM默认生成serialVersionUID,可能会导致其与编译器的实现细节耦合,这样可能会导致在反序列化的过程中发生意外的InvalidClassException异常。因此,为了保证跨不同Java编译器实现的serialVersionUID值的一致,实现Serializable接口的必须显示地声明serialVersionUID字段。
此外serialVersionUID字段地声明要尽可能使用private关键字修饰,这是因为该字段的声明只适用于声明的类,该字段作为成员变量被子类继承是没有用处的!有个特殊的地方需要注意的是,数组类是不能显示地声明serialVersionUID的,因为它们始终具有默认计算的值,不过数组类反序列化过程中也是放弃了匹配serialVersionUID值的要求。
序列化的使用
先定义一个序列化对象User:
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private String userId;
private String userName;
public User(String userId, String userName) {
this.userId = userId;
this.userName = userName;
}
} 然后我们编写测试类,来对该对象进行读写操作,我们先测试将该对象写入一个文件:
public class SerializableTest {
/**
* 将User对象作为文本写入磁盘
*/
public static void writeObj() {
User user = new User("1001", "Joe");
try {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("/Users/guanliyuan/user.txt"));
objectOutputStream.writeObject(user);
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String args[]) {
writeObj();
}
} 运行上述代码,我们就将User对象及其携带的数据写入了文本user.txt中。
接下来,我们继续编写测试代码,尝试将之前持久化写入user.txt文件的对象数据再次转化为Java对象,代码如下:
public class SerializableTest {
/**
* 将类从文本中提取并赋值给内存中的类
*/
public static void readObj() {
try {
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("/Users/guanliyuan/user.txt"));
try {
Object object = objectInputStream.readObject();
User user = (User) object;
System.out.println(user);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String args[]) {
readObj();
}
}通过反序列化操作,可以再次将持久化的对象字节流数据通过IO转化为Java对象,结果如下:
cn.wudimanong.serializable.User@6f496d9f
序列化与反序列化操作过程就是这么的简单。只需要将User写入到文件中,然后再从文件中进行恢复,恢复后得到的内容与之前完全一样,但是两者是不同的对象。
三种java对象跨语言序列化反序列化实现与效率对比
java对象常用的跨语言序列化反序列化主要有三种:一是xml形式;二是json形式;三是protobuf字节流形式。本篇文章主要介绍这三种序列化反序列化方式的实现和其效率对比。
首先介绍xml形式的序列化与反序列化,使用jaxb来实现。JAXB能够使用Jackson对JAXB注解的支持实现(jackson-module-jaxb-annotations),既方便生成XML,也方便生成JSON,这样一来可以更好的标志可以转换为JSON对象的JAVA类。JAXB允许JAVA人员将JAVA类映射为XML表示方式,常用的注解包括:@XmlRootElement,@XmlElement等等。其maven依赖为:
<!-- http://mvnrepository.com/artifact/com.sun.xml.bind/jaxb-core -->
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
<!-- http://mvnrepository.com/artifact/javax.xml/jaxb-api -->
<dependency>
<groupId>javax.xml</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.1</version>
</dependency>
<!-- http://mvnrepository.com/artifact/com.sun.xml.bind/jaxb-impl -->
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>定义的pojo类有两个:第一个是Book.java,另一个为BookList.java,是Book的集合类。只需要在定义的类名上添加@XmlRootElement注解即可,对业务代码没有侵入性。其中两个类中的属性值上有@Protobuf注解,这是protobuf序列化需要的,对xml序列化无影响。
Book类代码
package zhangq.pojo;
import javax.xml.bind.annotation.XmlRootElement;
import com.baidu.bjf.remoting.protobuf.FieldType;
import com.baidu.bjf.remoting.protobuf.annotation.Protobuf;
@XmlRootElement
public class Book {
@Protobuf(fieldType = FieldType.INT32, order=1)
int id;
@Protobuf(fieldType = FieldType.STRING, order=2)
String name;
@Protobuf(fieldType = FieldType.STRING, order=3)
String address;
@Protobuf(fieldType = FieldType.STRING, order=4)
String buyer;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getBuyer() {
return buyer;
}
public void setBuyer(String buyer) {
this.buyer = buyer;
}
@Override
public String toString() {
return "Book [id=" + id + ", name=" + name + ", address=" + address + ", buyer=" + buyer + "]";
}
}BookList类代码:
package zhangq.pojo;
import java.util.List;
import javax.xml.bind.annotation.XmlRootElement;
import com.baidu.bjf.remoting.protobuf.annotation.Protobuf;
@XmlRootElement
public class BookList{
@Protobuf(order=1)
private List<Book> books;
public List<Book> getBooks() {
return books;
}
public void setBooks(List<Book> books) {
this.books = books;
}
@Override
public String toString() {
return "BookList [books=" + books + "]";
}
}定义完pojo后,就可以进行xml的序列化与反序列化实现了。
首先定义一个测试辅助类,用来生成pojo实例
package zhangq.test;
import java.util.ArrayList;
import java.util.List;
import zhangq.pojo.Book;
import zhangq.pojo.BookList;
public class TestHelper {
public static BookList buildBookList(int count){
BookList bookList = new BookList();
List<Book> books = new ArrayList<Book>();
for (int i=0; i<count; i++){
books.add(buildBook(i));
}
bookList.setBooks(books);
return bookList;
}
public static Book buildBook(int id){
Book book = new Book();
book.setAddress("Peking");
book.setBuyer("hello");
book.setId(id);
book.setName("Netty");
return book;
}
}然后,定义一个性能记录类,用来记录序列化与反序列化的耗时:
package zhangq.util;
import org.apache.log4j.Logger;
public class PerformanceRecord {
private static Logger m_Logger = Logger.getLogger(PerformanceRecord.class);
private String desp;
private long iStart;
private PerformanceRecord(String desp){
this.desp = desp;
}
public static PerformanceRecord getInstance(String desp){
return new PerformanceRecord(desp);
}
public long start(){
iStart = System.nanoTime();
return iStart;
}
public double endInSeconds(){
long iEnd = System.nanoTime();
double timeInSeconds = (iEnd - iStart) / (1000000000.0);
m_Logger.info(desp + " 耗时为 [" + timeInSeconds + "] 秒");
return timeInSeconds;
}
public double endInMs(){
long iEnd = System.nanoTime();
double timeInMs = (iEnd - iStart) / (1000000.0);
m_Logger.info(desp + " 耗时为 [" + timeInMs + "] 毫秒");
return timeInMs;
}
public long endInNs(){
long iEnd = System.nanoTime();
long timeInNs = (iEnd - iStart);
m_Logger.info(desp + " 耗时为 [" + timeInNs + "] 纳秒");
return timeInNs;
}
}使用jaxb进行xml序列化的代码为:
public static String testMarshallList(int count) throws Exception{
BookList books = TestHelper.buildBookList(count);
JAXBContext jaxbContext = JAXBContext.newInstance(BookList.class);
Marshaller marshaller = jaxbContext.createMarshaller();
marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
OutputStream outputStream = new ByteArrayOutputStream();
PerformanceRecord performanceRecord = PerformanceRecord.getInstance("XmlMashall");
performanceRecord.start();
marshaller.marshal(books, outputStream);
performanceRecord.endInMs();
String string = outputStream.toString();
outputStream.close();
//m_Logger.debug("ObjToXml:");
//m_Logger.debug(string);
return string;
}使用jaxb进行xml反序列化的代码为:
public static BookList testUnMarshallList(String string) throws Exception{
JAXBContext jaxbContext = JAXBContext.newInstance(BookList.class);
Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
InputStream inputStream = new ByteArrayInputStream(string.getBytes());
PerformanceRecord performanceRecord = PerformanceRecord.getInstance("XmlUnmashall");
performanceRecord.start();
BookList books = (BookList)unmarshaller.unmarshal(inputStream);
performanceRecord.endInMs();
//m_Logger.debug("XmlToObj:");
//m_Logger.debug(books.toString());
return books;
}其次介绍json的序列化,使用jackson实现。使用jackson,不需要对pojo进行任何修改,不需要添加注解。其maven依赖为:
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-annotations -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.5</version>
</dependency>jackson的json序列化代码为:
public static String testObjToJsonList(int count) throws Exception{
String string = null;
BookList books = TestHelper.buildBookList(count);
ObjectMapper mapper = new ObjectMapper();
PerformanceRecord performanceRecord = PerformanceRecord.getInstance("Jsonmashall");
performanceRecord.start();
string = mapper.writeValueAsString(books);
performanceRecord.endInMs();
// m_Logger.debug("ObjToJson:");
// m_Logger.debug(string);
return string;
} 最后是protobuf字节流的序列化与反序列化,使用jprotobuf库进行,jprotobuf库的优点是使用简单,只需要在pojo上添加@protobuf注解即可,关于jprotobuf的介绍请看其git:https://github.com/jhunters/jprotobuf/ 。其maven依赖为:
<!-- https://mvnrepository.com/artifact/com.baidu/jprotobuf -->
<dependency>
<groupId>com.baidu</groupId>
<artifactId>jprotobuf</artifactId>
<version>2.1.8</version>
</dependency>jprotobuf序列化代码为:
public static byte[] testObjToByteList(int count){
Codec<BookList> simpleTypeCodec = ProtobufProxy
.create(BookList.class);
BookList books = TestHelper.buildBookList(count);
byte[] bytes = null;
try {
PerformanceRecord performanceRecord = PerformanceRecord.getInstance("ProtoBufMashall:");
performanceRecord.start();
bytes = simpleTypeCodec.encode(books);
performanceRecord.endInMs();
} catch (IOException e) {
// TODO Auto-generated catch block
m_Logger.error(e.toString());
}
return bytes;
}jprotobuf反序列化代码为:
public static BookList testByteToObjList(byte[] bytes){
Codec<BookList> simpleTypeCodec = ProtobufProxy
.create(BookList.class);
BookList books = null;
try{
PerformanceRecord performanceRecord = PerformanceRecord.getInstance("ProtoBufUnMashall:");
performanceRecord.start();
books = simpleTypeCodec.decode(bytes);
performanceRecord.endInMs();
}catch (Exception e){
m_Logger.error(e.toString());
}
return books;
}最后,需要对这三种方式的序列化与反序列化耗时进行记录,并对其序列化后的字节大小进行比较。需要注意的是,这三种方式都会涉及到预处理,并且内部有缓存等优化机制,因此对每种的序列化与反序列化函数运行两次,取第二次的耗时,这更符合实际工程运行时的耗时。
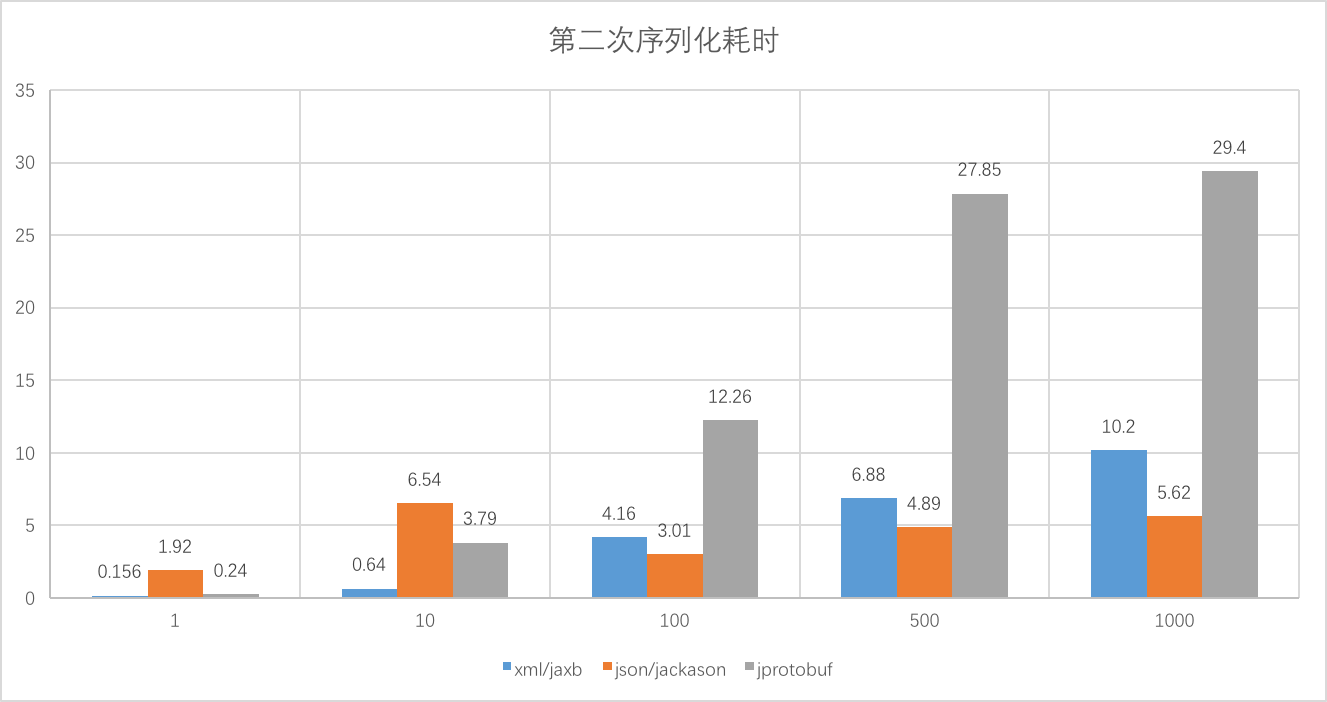
下面是序列化耗时:
其中横轴代表Book实例的个数,纵轴表示耗时,单位毫秒。
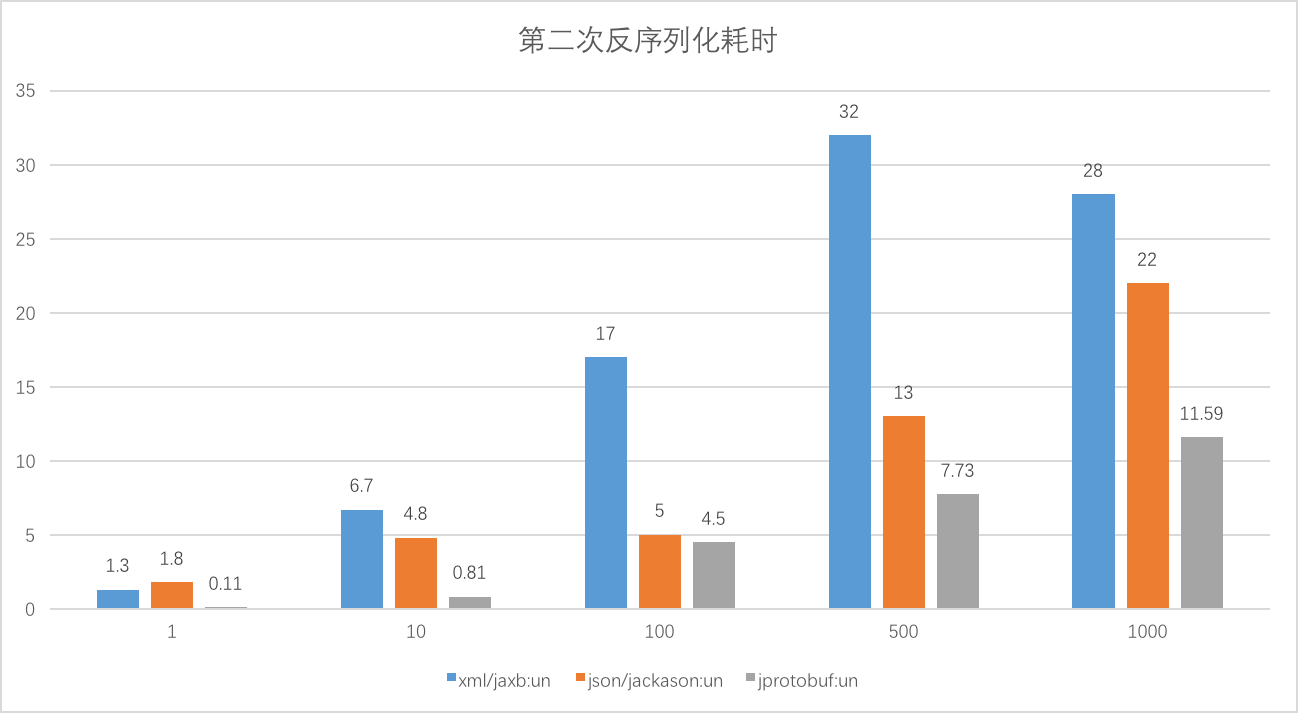
下面是反序列化耗时:
其中横轴代表Book实例的个数,纵轴表示耗时,单位毫秒。
下面是序列化后字节大小:
横轴是Book实例个数,纵轴是字节个数,单位个。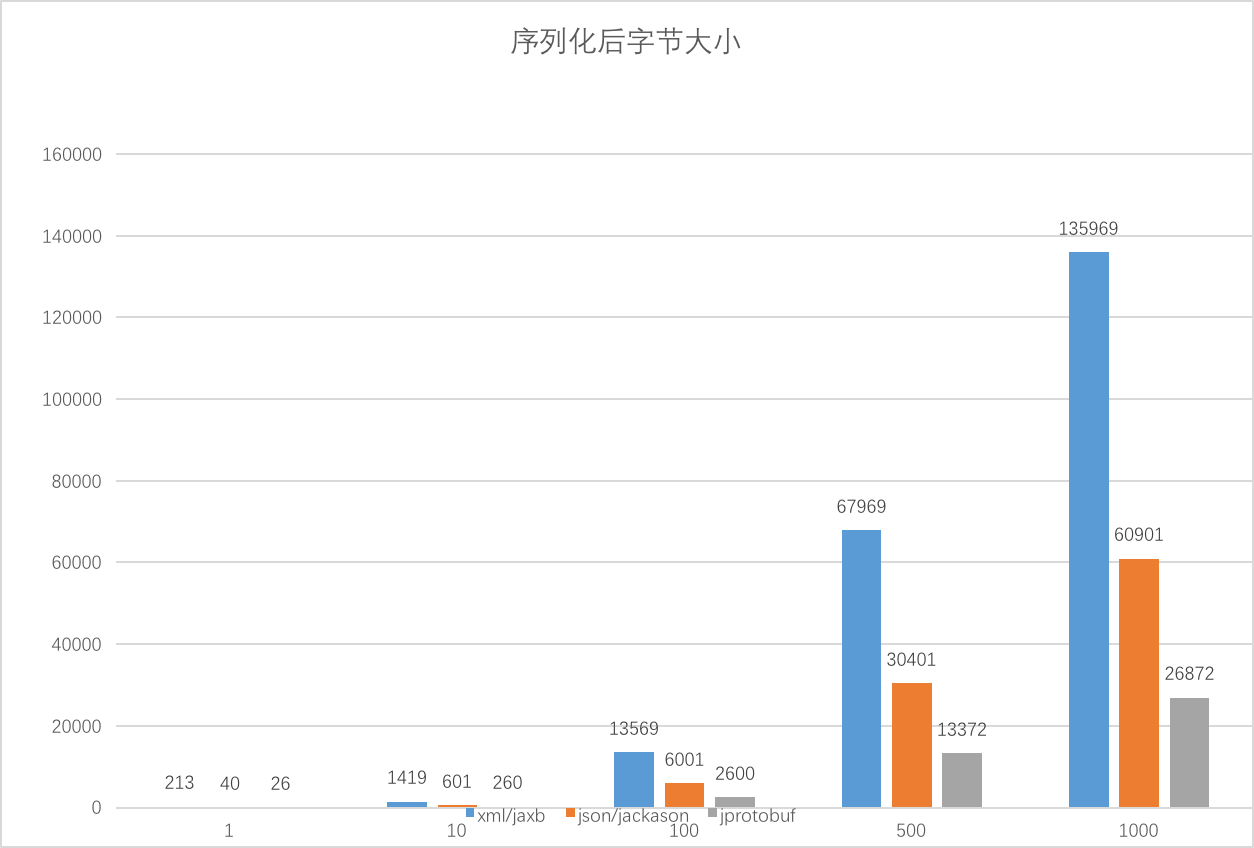
根据图表分析,jprotobuf进行序列化时,耗时最长,但是反序列化耗时最短、序列化字节长度最短。xml/jaxb反序列化耗时最长,序列化字节长度最长。json/jackson表现较为适中















 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









