






1 knn K近邻算法原理
KNN 是 supervised learning, non parametric(无参数) instance-based(基于实例) learning algorithm.
KNN算法通俗的理解就是,通过待分类点附近的点的类型来确定分类点的种类,这个种类和K值有关。也就是人们常说的“物以类聚,人以群分”。这种算法所实现的准确率也比较高。
K值选择、距离度量、以及分类决策(一般多数表决)为K近邻算法的三个基本要素。
1.1 K值选择
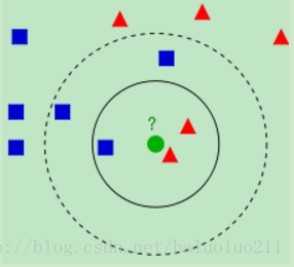
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
可见K值的选择对分类的结果还是有很大的影响。
2.实例演示
import csv
import random
//读取数据
with open("Prostate_Cancer.csv", "r") as file:
reader = csv.DictReader(file)
datas = [row for row in reader]
random.shuffle(datas)
n = len(datas) // 3
test_set = datas[0:n]
train_set = datas[n:]
def distance(d1, d2):
res = 0
for key in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res += (float(d1[key]) - float(d2[key])) ** 2
return res ** 0.5
K = 5
def knn(data):
res = [
{"result": train["diagnosis_result"], "distance": distance(data, train)}
for train in train_set
]
res = sorted(res, key=lambda item: item['distance'])
res2 = res[0:K]
result = {'B': 0, 'M': 0}
sum = 0
for r in res2:
sum += r['distance']
for r in res2:
result[r['result']] += 1 - r['distance'] / sum
if result['B'] > result['M']:
return 'B'
else:
return 'M'
correct = 0
for test in test_set:
result = test['diagnosis_result']
result2 = knn(test)
if result == result2:
correct += 1
print("准确率:{:.2f}%".format(100 * correct / len(test_set)))KNN改进方法
-
不同的K值加权
-
距离度量标准根据实际问题,使用不同的距离
-
特征归一化,例如,身高和体重x=[180,70],升高计算明显,更影响结果,所有需要对两者分别求平均值,然后归一化。
-
如果维数过大,可以做PCA降维处理















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









