






第一章:新手村任务——认识你的西瓜田
作者用种西瓜的故事教你认识ML黑话
假设你是个瓜农,手里有个记满西瓜属性的祖传Excel表(数据集),每一行都是你祖上记录的西瓜档案(样本/示例),包括颜色、纹理、敲声等(特征/属性),最后一列写着"好瓜"或"烂瓜"(标签/标记)。
机器学习就是让计算机帮你从这些数据中总结《挑瓜秘籍》(模型),比如发现"蒂落=凹陷且纹理=清晰"的瓜大概率是好瓜(决策树)。

(网图侵删)
划重点冷知识
-
特征空间不是科幻概念,而是把西瓜属性变成多维坐标系(比如把颜色=青绿映射到x轴)
-
学得模型后,你甚至可以拿着未标记的新瓜(测试样本)去菜市场装逼预测
-
监督学习像老师改作业(有参考答案),无监督学习像让孩子自己给积木分类
第二章:如何判断你的模型在裸泳?——评估与选择
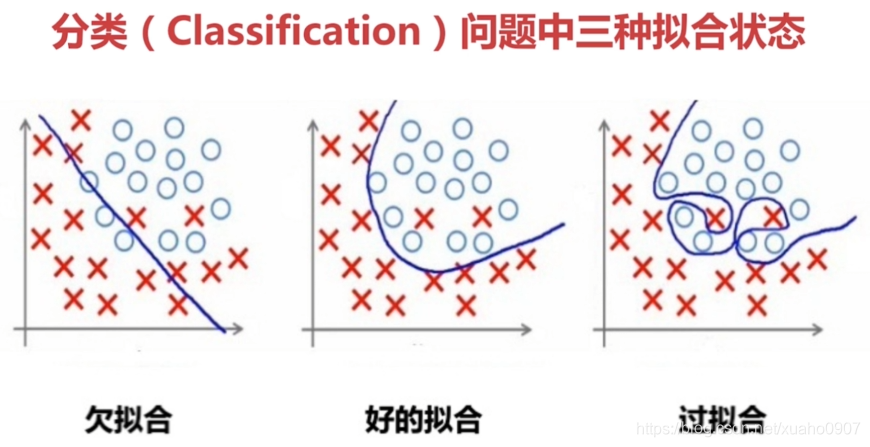
过拟合 vs 欠拟合
-
学渣考前没复习(欠拟合):训练集错误率40%,测试集错误率45%
-
卷王学霸背题库(过拟合):训练集错误率0%,测试集错误率50%
-
理想状态:训练集测试集错误率都低(泛化能力强)
(网图侵删)
评估三件套
-
留出法:把西瓜田划出20%当"模拟考专用瓜"
-
交叉验证法:把瓜田分成5块轮流当测试集(五周目玩家行为)
-
自助法:抽瓜检测后放回(可能重复抽到同一个瓜,适合小数据集)
性能度量鬼故事
买瓜时:
-
查准率:你挑的10个"好瓜"里有多少真好吃
-
查全率:地里所有好瓜有多少被你成功选中
-
F1分数:既要当海王(查全率高)又要不翻车(查准率高)的平衡指标
AI 圈著名冷笑话
"在训练集上准确率99%的模型,实际可能不如随机瞎猜——如果测试集分布和训练集完全不同的话"
第三章:线性模型——你以为的简单,其实全是套路
线性回归:预测西瓜的成熟度
假设西瓜甜度(y)和体积(x)呈线性关系:y = wx + b
虽然现实中可能存在"西瓜越大越水"的反常识情况(非线性关系),但线性模型永远是工程师的第一把瑞士军刀
(网图侵删)
对数几率回归:披着回归外衣的分类器
(Logistic Regression:其实是分类算法!)
用sigmoid函数把线性结果压缩到(0,1),比如:
-
输出0.8 → 80%概率是好瓜
-
本质是在用线性边界划分西瓜:z=0.5的位置就是决策边界
线性判别分析(LDA):西瓜投影艺术
把三维西瓜特征投影到一条直线上,让:
-
好瓜投影点尽可能密集
-
坏瓜投影点尽可能远离好瓜
就像把西瓜横着切一刀,看切面就能区分好坏
隐藏彩蛋
-
类别不平衡问题:如果地里99%都是烂瓜,模型会直接摆烂全预测"烂瓜"拿99%准确率
-
多分类策略:"ovo"(两两单挑)比"ovr"(一挑多)更公平,但计算量爆炸(请自行脑补瓜田修罗场)
后记:西瓜食用指南
前三章就像吃西瓜最甜的中心部分:
-
第1章教你怎么挑西瓜(认识问题)
-
第2章教你怎么验证西瓜甜不甜(评估模型)
-
第3章给你切西瓜的基本刀法(基础模型)
至于后面章节的核方法、神经网络…那都是进阶吃法:西瓜汁、西瓜冰沙、西瓜蛋糕(但小心别被西瓜皮滑倒)
作者:某不愿透露姓名的吃瓜群众
友情提示:看完请自觉翻开西瓜书第4章,否则本文的知识点会在24小时后自动遗忘(人类的本质.jpg)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









