







本人一直想做DWG文件批量处理成PDF文件,无意中从网上查找到Pdftron这个软件,当我用DWG批量处理成PDF文件时,用demo试用版本发现导出的文件会出现如下图的水印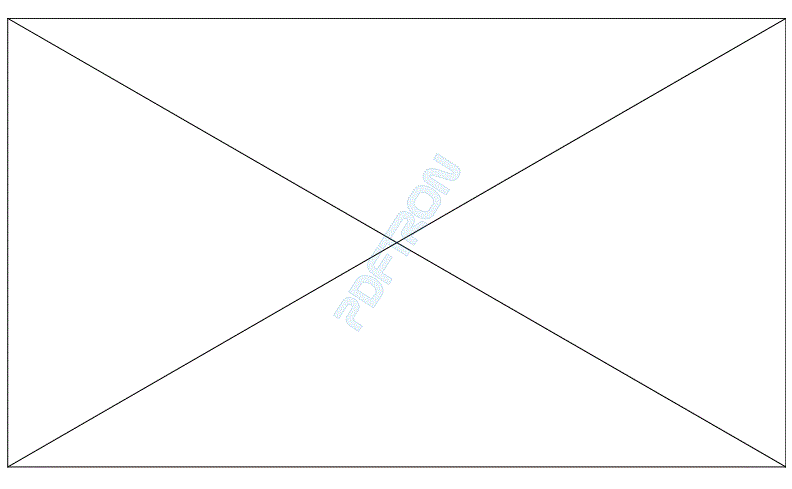
那如果我们运用时需要去除上面的水印,鄙人从网上查阅好多资料都是转成图片再根据色差去除水印然后再转回pdfk但是会得到以下效果

可以看出pdf非常不清晰,这不能到达我们的需求,究其根本原因就是不能从pdf本身,解决这些问题。我在想能不能从pdf本身来解析其中信息,找到水印的信息直接删除呢,最终运用PyPDF4达到自己的目的,这里代码只列出一个文件去除pdf水印,多文件就需要写几个for循环即可,这对于大家来说小菜一碟,这里这是给大家提供一个可靠的思路,原则上所有水印即文字的,图画的,图形的都可以去除代码如下:
import os
from PyPDF4 import PdfFileReader,PdfFileWriter
output = PdfFileWriter()
pdf = PdfFileReader("C:/Users/13283/Desktop/hahaha/output/Drawing1.pdf", 'rb')
pdf1=pdf.getPage(0)
pdf1['/Resources']['/XObject']['/Trn3dK9'].clear()
output.addPage(pdf1)
with open("C:/Users/13283/Desktop/hahaha/output/out.pdf",'wb') as ouf:
output.write(ouf)其中"C:/Users/13283/Desktop/hahaha/output/Drawing1.pdf"为带有水印的文件pdf1=pdf.getPage(0)为第一页,因为这里只有一页,多页的话直接遍历就可,因为水印的形式大多数都差不多,遍历都就可以都删除pdf1['/Resources']为页面结构,本人经验来说大多数元素都在pdf1['/Resources']['/XObject']之中,其中['/Trn3dK9']就为中间的水印,我们把它删除掉再加入pdf页面中水印就消失。下图为处理之后的
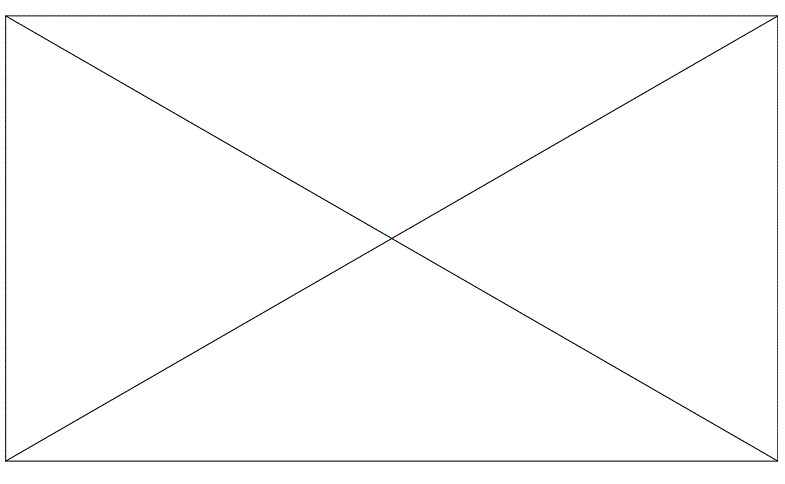
是不是和原来一样。
这里说一下,Pdftron是商业软件,此方法仅供学习使用禁止商用,谢谢。
如果你你们满意的话,请多多支持,本人为R语言与python学习者,有啥问题可私信一起学习哈。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









