






论文链接:AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection | OpenReview
论文代码链接:zqhang/AnomalyCLIP: Official implementation for AnomalyCLIP (ICLR 2024)
一、论文动机
零样本异常检测(ZSAD)中,传统的预训练视觉语言模型(VLMs)在面对不同领域的异常检测时,由于其侧重于学习前景对象的类别语义,而不是图像中的异常性,导致 ZSAD 性能较弱。
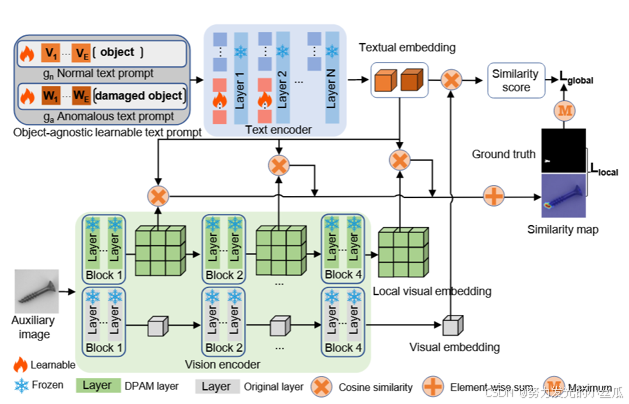
二、论文方法
(1)对象无关提示学习

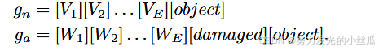
- CLIP 中常用的文本提示模板,主要关注对象语义。因此,它们无法生成捕获异常和正常语义的文本嵌入来查询相应的视觉嵌入。
- 设计具有特定异常类型的模板,但异常的模式通常是未知且多样的,因此实际上很难列出所有可能的异常类型。因此,使用通用异常语义定义文本提示模板非常重要。
- 于是,采用文本 damaged [cls] 来覆盖全面的异常语义。然而,使用此类文本提示模板在生成通用异常区分文本嵌入方面带来了挑战。这是因为 CLIP 最初的预训练侧重于与对象语义保持一致,而不是图像中的异常和正常性。为了解决这一限制,引入可学习的文本提示模板,并使用辅助 AD 相关数据调整提示。在微调过程中,这些可学习的模板可以包含广泛而详细的异常语义,从而产生在正常和异常之间更具区分性的文本嵌入。
螺母和金属板上的划痕、晶体管和 PCB 的错位以及各种器官表面的肿瘤等异常情况都可能具有类似的异常模式。 准确的 ZSAD 的关键是识别这些通用异常模式,而不管不同对象的语义如何。因此,对于 ZSAD,在对象感知文本提示模板中包含对象语义通常是不必要的。它甚至会阻碍检测在学习过程中未见的类中的异常。 更重要的是,从文本提示模板中排除对象语义可以使可学习的文本提示模板专注于捕获异常本身的特征,而不是对象。 引入与对象无关的提示学习,目的是捕捉图像中的一般正常和异常,而不管对象语义如何。
(2)全局和局部上下文优化

- 为了有效地学习与对象无关的文本提示,设计了一种联合优化方法,该方法能够从全局和局部视角进行正常和异常提示学习,即全局和局部上下文优化。
- 全局上下文优化旨在确保与对象无关的文本嵌入与不同对象图像的全局视觉嵌入相匹配。这有助于从全局特征角度有效地捕获正常/异常语义。
- 局部上下文优化是为了使与对象无关的文本提示除了全局正常/异常特征之外,还能专注于视觉编码器的 M 个中间层中的细粒度局部异常区域。
- 通过最小化以下全局-局部损失函数来学习文本提示
相关知识:
全局视觉嵌入: 从整体图像的角度出发,对图像进行编码后得到的一个特征向量。这个向量综合了图像中各个部分的信息,反映了图像的整体特征。
局部视觉嵌入: 将图像划分成多个小的区域,对每个小区域进行编码得到的特征。这些局部特征能够捕捉到图像中细微的、局部的信息,比如图像中某个物体的局部纹理、特定部位的细节等。在检测图像中物体的异常时,局部视觉嵌入就显得尤为重要,因为异常往往体现在一些局部的细节变化上,如产品表面的小瑕疵、医学影像中病变组织的局部特征等。
分割图生成: 计算原理:在零样本异常检测(ZSAD)任务中,模型需要判断图像中哪些区域是正常的,哪些是异常的,分割图就是用于呈现这种判断结果的一种方式。通过将文本提示的计算扩展到局部视觉嵌入来生成分割图。 对于每个局部视觉嵌入 ,分别计算它与表示正常和异常的文本提示相似度得分。 ,这两个得分分别表示该局部区域属于正常和异常的概率。
结果呈现:通过对图像中每个局部区域都进行这样的计算,得到一系列的概率值,这些概率值构成了分割图 。在分割图中,每个像素点的数值就代表了该位置属于正常或异常的概率。比如,在一个工业产品图像的分割图中,如果某个像素点在异常分割图中的值接近 1,就表示模型认为该位置很可能存在异常;如果在正常分割图中的值接近 1,则表示模型认为该位置是正常的。通过这种方式,分割图能够直观地展示出图像中不同区域的异常情况,帮助人们快速定位和分析图像中的异常部分。
(3)文本提示调优和 DPAM
通过文本提示调整和 DPAM(对角突出注意力图)来优化 CLIP 在文本和局部视觉空间中的提示学习,使模型能够更好地关注异常图像区域。
1.文本提示调优
通过在 CLIP 的文本编码器中添加额外的可学习令牌嵌入,来优化 CLIP 原本的文本空间。这是因为 CLIP 原始的文本空间在用于异常检测时可能不够精确,无法充分捕捉异常和正常的语义差异。
可学习令牌被添加到 CLIP 文本编码器特定层的向量。在文中的文本提示调优环节,随机初始化的可学习令牌嵌入被添加到 CLIP 文本编码器的第m层。它和原始令牌嵌入连接后参与前向传播,能融合进新的信息,让模型学习到更适配异常检测任务的文本表示,提升文本空间区分正常和异常语义的能力。
相关知识:
令牌:在自然语言处理和涉及文本的深度学习模型中,令牌通常是指将文本分解后的基本单元,是一种基本的数据表示单元。比如,对于句子 “A photo of a dog”,可以将每个单词看作一个令牌。在 CLIP 的文本编码器中,文本提示(如 “A photo of a [cls]”)会被转化为一系列的令牌嵌入,每个令牌都有对应的嵌入向量,这些向量携带了文本的语义信息。在处理文本时,模型会基于这些令牌的嵌入来理解和处理文本的含义。
原始令牌嵌入: 原始令牌嵌入是 CLIP 文本编码器在处理文本时产生的基础特征表示,是 CLIP 模型对文本进行理解和处理的关键组成部分。
生成过程:在 CLIP 模型中,输入的文本(如常用的文本提示 “A photo of a [cls]” )首先会被分词,将文本分割成一个个单独的令牌(token)。然后,文本编码器会对这些令牌进行处理,为每个令牌生成对应的向量表示,这些向量就是原始令牌嵌入。这一过程是 CLIP 理解文本语义的基础,通过将文本转化为数值化的向量,模型能够在后续的计算和处理中对文本信息进行操作。
作用:原始令牌嵌入包含了文本的语义和语法等信息。模型会基于这些嵌入进行各种任务相关的计算,例如在零样本识别任务中,计算文本嵌入与视觉嵌入的相似度。在文中的研究场景下,原始令牌嵌入会与可学习令牌嵌入连接,共同参与后续的前向传播过程,以得到更符合异常检测任务需求的文本表示。它为整个文本表示提供了基础信息,后续添加可学习令牌嵌入等操作都是在其基础上进行优化和改进,以增强模型在特定任务(如异常检测)中的性能。
2.DPAM(局部视觉空间的细化)
由于 CLIP 的视觉编码器最初是预先训练的,以对齐全局对象语义,因此 CLIP 中使用的对比损失使视觉编码器产生具有代表性的全局嵌入以进行类识别。 通过自我注意机制,视觉编码器中的注意力图集中在图 b 中红色矩形内突出显示的特定标记上。尽管这些标记可能有助于全局对象识别,但它们会破坏局部视觉语义,这直接阻碍了与对象无关的文本提示中细粒度异常的有效学习。
论文凭经验发现,对角线突出的注意力图有助于减少来自其他标记的干扰,从而改善局部视觉语义。因此,提出了一种称为对角线突出注意力图的机制来优化局部视觉空间,将视觉编码器中原来的 Q-K 注意力替换为对角线突出的注意力 自注意力方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











