




AIM: Let Any Multimodal Large Language Models Embrace Efficient In-Context Learning
AAAI 2025
预印 2024.6
Why
这篇论文主要针对多模态大语言模型(MLLMs)在进行上下文学习(In-Context Learning, ICL)时面临的两个核心问题:
- 无法处理多个多模态演示:
- 目前主流的MLLMs(如LLaVA, BLIP-2等)大多是在单个图像-文本对的数据集上训练的。这使得它们在设计上就无法理解包含多个图像的上下文学习示例。例如,它们无法处理像
[图1, 文本1], [图2, 文本2], [查询图, 查询指令]这样的输入。
- 目前主流的MLLMs(如LLaVA, BLIP-2等)大多是在单个图像-文本对的数据集上训练的。这使得它们在设计上就无法理解包含多个图像的上下文学习示例。例如,它们无法处理像
- 计算成本高昂且性能下降:
- 即使某些模型理论上可以处理多张图像(如类似Flamingo的模型),每个图像都会引入成百上千的视觉token(visual tokens)。当使用多个演示图像时,会导致:
-
硬件挑战:大量的视觉token使得输入序列变得极长,对显存(CUDA Memory,如图1所示)和计算资源的需求急剧增加,变得不切实际。这一点在论文的
图1中有清晰的展示:随着演示数量(# shots)的增加,LLaVA-Next和OpenFlamingo的显存占用急剧上升,而AIM则基本保持不变。
![* ![[image-86.png]]](https://i-blog.csdnimg.cn/direct/cdaed07770114b0ea8eb7bcfe6d22178.png)
-
ICL性能下降:过长的输入序列(尤其是视觉token过多)可能会让底层的LLM感到困惑,反而降低ICL的性能。论文还指出,在生成过程中,LLM内部更关注演示中的文本模态信息。这一点可以参考
图3(热力图),它显示了QWen-VL在生成 hateful memes 数据集第一个token时,对演示中视觉和文本部分的注意力分布,亮色区域(更高注意力)更多地集中在文本部分。
![* ![[image-87.png]]](https://i-blog.csdnimg.cn/direct/8f4be61e13a1411999471eed8e5e179a.png)
-
- 即使某些模型理论上可以处理多张图像(如类似Flamingo的模型),每个图像都会引入成百上千的视觉token(visual tokens)。当使用多个演示图像时,会导致:
简单来说,现有的MLLMs要么不能进行包含多个图像示例的多模态ICL,要么即使能做,也效率低下且效果可能不佳。
What
AIM (Aggregating Image information of Multimodal demonstrations,聚合多模态演示中的图像信息) 是一个通用且轻量级的框架,旨在解决上述问题。其核心思想是:
-
将图像信息融合到文本表示中:
- 对于每个演示中的“图像-文本”对,AIM不再直接将原始图像及其大量的视觉token输入给LLM。
- 而是先独立处理每个演示对,将其中的图像信息“聚合”或“融合”到其对应文本标签的隐层空间中。
-
生成紧凑的“融合虚拟token”:
- 这种聚合后的信息被转换成一小组“融合虚拟token”(fused virtual tokens),其长度与原始文本token的长度相当。这些融合虚拟token有效地代表了整个“图像-文本”演示,但形式上更像文本,且非常紧凑。
-
替代原始演示:
- 这些融合虚拟token取代了原始的、包含大量视觉token的“图像-文本”演示对。这样,MLLM看到的输入就变成了一系列紧凑的融合虚拟token,后面跟着实际的查询图像和查询文本。这整个过程在
图4中有清晰的架构展示:左侧展示了如何从原始的视觉和文本token(Vision Tokens, Text Tokens)经过LLM Layer N层处理后,通过一个线性层(Linear Layer)并丢弃(Discarding)原始视觉信息,得到融合后的token;右侧则展示了这些融合后的token(Concatenated Fused Tokens)如何与查询图像(经过Perceiver处理)一起输入到大型语言模型中。
![* ![[image-88.png]]](https://i-blog.csdnimg.cn/direct/10a0dbc58a3a440da283db2e4aea81a3.png)
- 这些融合虚拟token取代了原始的、包含大量视觉token的“图像-文本”演示对。这样,MLLM看到的输入就变成了一系列紧凑的融合虚拟token,后面跟着实际的查询图像和查询文本。这整个过程在
-
赋能任何MLLM进行多模态ICL:
- 对于那些原本只在单图上训练的MLLM,AIM使得它们也能够进行多模态ICL,因为演示中的图像信息已经被“吸收”进了文本token,最终模型只需要处理单个查询图像。
- 对于所有MLLM,这种方法都显著减少了输入序列的长度,从而节省了内存和计算资源。
-
演示数据库 (Demonstration Bank, DB):
- 由于每个演示的融合过程是独立的,所得到的融合虚拟token可以被预先计算并缓存起来,形成一个“演示数据库”。在推理时,可以直接从数据库中调取,避免了对相同演示的重复聚合操作,显著提高了效率。这一点在
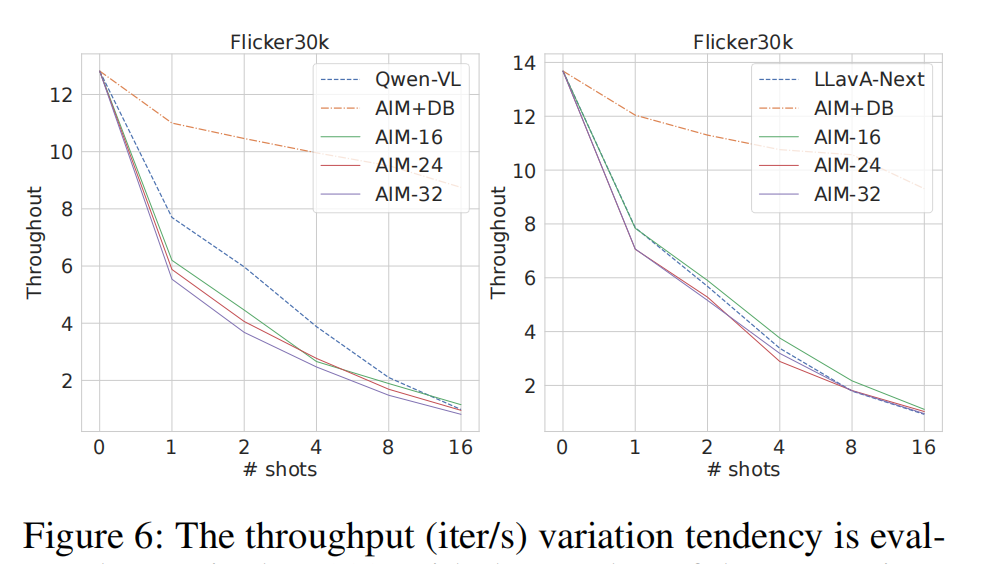
图6中通过AIM+DB的曲线有所体现,显示了使用DB后吞吐量的提升。
![* ![[image-89.png]]](https://i-blog.csdnimg.cn/direct/cbc4e059bb144e7488f4421771f0184d.png)
- 由于每个演示的融合过程是独立的,所得到的融合虚拟token可以被预先计算并缓存起来,形成一个“演示数据库”。在推理时,可以直接从数据库中调取,避免了对相同演示的重复聚合操作,显著提高了效率。这一点在
总而言之,AIM将复杂的多模态演示转换成了高效的、类似文本的表示,使得任何MLLM都能够轻松地使用它们进行上下文学习,而LLM本身无需直接“看到”演示中的图像。
How
3.1 实现方式
1. 核心思想回顾
AIM的核心是将演示中的图像信息聚合到其对应文本的隐层表示中,并生成紧凑的“融合虚拟token”来替代原始的图像-文本演示对。(参见论文图4的整体架构图)
![![[image-88.png]]](https://i-blog.csdnimg.cn/direct/51061a8caafb46deaa2542f3b1048102.png)
2. 图像信息聚合模块
- 输入:对于第 i i i 个演示对 ( X i v , Y i t ) (X_i^v, Y_i^t) (Xiv,Yit),其中 X i v X_i^v Xiv 是图像, Y i t Y_i^t Yit 是对应的文本标签(可能已用指令包装)。
- 视觉特征提取:图像 X i v X_i^v Xiv 首先通过MLLM自身的(冻结的)视觉编码器(如论文中提到的Perceiver,或ViT后接MLP)转换成视觉token序列。(图4左侧 “Vision Tokens” 部分)
- 图文交互与信息融合:将视觉token序列与文本 Y i t Y_i^t Yit 的嵌入序列拼接或以特定方式组合,然后输入到MLLM中冻结的LLM的前 N N N层(论文中提到会实验不同层数)。(图4左侧 “LLM Layer N N N” 堆叠部分)
- 提取融合后的文本表示:取LLM前
N
N
N层输出中,对应于文本
Y
i
t
Y_i^t
Yit 位置的最后一层隐藏状态,记为
H
Y
i
H_{Y_i}
HYi。由于LLM内部的自注意力机制,
H
Y
i
H_{Y_i}
HYi 此时已经捕获了来自图像
X
i
v
X_i^v
Xiv 的相关信息。
![![[image-90.png]]](https://i-blog.csdnimg.cn/direct/68fc2b8d018a47b4a93f044d67262d2e.png)
3. 投影层与融合虚拟token生成
- 引入一个可训练的轻量级线性投影层 W p W_p Wp (论文中提到约17M参数)。(图4中 “Linear Layer” 部分,虽然图中是作用在聚合后的输出上)
- 该投影层将上一步得到的融合文本表示 H Y i H_{Y_i} HYi 映射到一个新的空间,生成“融合虚拟token” Y ^ i \hat{Y}_i Y^i。即:
Y ^ i = W p ⋅ H Y i ( 公式2 ) \hat{Y}_{i}=W_{p} \cdot H_{Y_{i}} \quad (\text{公式2}) Y^i=Wp⋅HYi(公式2)
-
Y
^
i
\hat{Y}_i
Y^i 的维度与LLM期望的输入嵌入维度一致,可以直接作为LLM的输入。其长度远小于原始视觉token加上文本token的长度。(图4中 “Fused Tokens”)
![![[image-91.png]]](https://i-blog.csdnimg.cn/direct/cd94d57e204c46c496cdfd6970f8e12f.png)
4. ICL提示构建与响应生成
- 演示序列构建:将所有 k k k 个演示生成的融合虚拟token Y ^ 1 , Y ^ 2 , … , Y ^ k \hat{Y}_1, \hat{Y}_2, \dots, \hat{Y}_k Y^1,Y^2,…,Y^k 按顺序拼接起来,形成紧凑的演示序列 D = Y ^ 1 ⊕ Y ^ 2 ⊕ ⋯ ⊕ Y ^ k D = \hat{Y}_1 \oplus \hat{Y}_2 \oplus \dots \oplus \hat{Y}_k D=Y^1⊕Y^2⊕⋯⊕Y^k。(图4中 “Concatenated Fused Tokens”)
- 最终输入:将演示序列 D D D、查询图像 X q v X_q^v Xqv 经过视觉编码器得到的视觉嵌入(图4右侧 “Perceiver” 输出)、以及查询指令 ins q \text{ins}_q insq 的文本嵌入拼接起来,作为最终输入送给整个冻结的MLLM(图4顶部 “Large Language Model”)。
- 响应生成:MLLM以自回归的方式生成最终的答案,即:
y
t
=
argmax
P
(
y
∣
D
;
X
query
;
ins.
;
y
<
t
)
.
(
公式3
)
y_{t}=\text{argmax} \, P\left(y \mid D ; X_{\text{query}} ; \text{ins.} ; y_{<t}\right). \quad (\text{公式3})
yt=argmaxP(y∣D;Xquery;ins.;y<t).(公式3)
![![[image-92.png]]](https://i-blog.csdnimg.cn/direct/bb6684734ea9456b9a7b2d9f69be03a4.png)
5. 训练
- 训练目标:仅训练投影层 W p W_p Wp。
- 数据集:使用如MMC4(包含大量网页来源的交错图像和文本)这样的多模态数据集。
- 损失函数:标准的语言建模损失 (公式4)。即,在给定演示的融合虚拟token(和当前上下文)的条件下,最大化模型预测正确后续文本的概率:
loss = − 1 ∣ Y R ∣ ∑ t = 0 ∣ Y ∣ log P ( Y t R ∣ Y ^ 1 , … , Y ^ k ; Y < t R ) . ( 公式4 ) \text{loss} = -\frac{1}{\left|Y^{R}\right|} \sum_{t=0}^{|Y|} \log P\left(Y_{t}^{R} \mid \hat{Y}_{1}, \ldots, \hat{Y}_{k} ; Y_{<t}^{R}\right). \quad (\text{公式4}) loss=−∣YR∣1t=0∑∣Y∣logP(YtR∣Y^1,…,Y^k;Y<tR).(公式4)
- 细节:学习率 3 × 10 − 5 3 \times 10^{-5} 3×10−5,Adam优化器,有效批量大小16,训练10个epoch。每个MMC4实例最多使用5张图片。
6. 演示数据库
- 原理:由于每个演示的融合虚拟token Y ^ i \hat{Y}_i Y^i 是独立生成的,可以预先计算并缓存。
- 优势:在推理时,如果需要使用已缓存的演示,可以直接从DB中提取对应的
Y
^
i
\hat{Y}_i
Y^i,避免了重复的聚合计算,从而显著提升推理速度。(图6中 “AIM+DB” 的曲线显示了其效果)
![![[image-89.png]]](https://i-blog.csdnimg.cn/direct/796ef5c99b844c2d83c6cca0edaa0c34.png)
3.2 实验部分
-
实验设置 (Setting):
-
基线模型 (Backbones):选择两种有代表性的MLLM作为AIM的底层模型:QWen-VL和LLaVA-Next。(参见表1的模型列表)
![* ![[image-93.png]]](https://i-blog.csdnimg.cn/direct/c4d3e3f7eb7c464580a357a1bbc33bd1.png)
-
评估数据集:图像描述 (Flickr30k), VQA (OKVQA, VizWiz), 有害Meme检测 (Hateful Memes)。(参见表2的数据集详情)
![* ![[image-94.png]]](https://i-blog.csdnimg.cn/direct/398804d4d3d44364b7bae7b910aa6660.png)
-
数据过滤:确保测试集数据未出现在基线模型的训练集中,以保证ICL结果的可靠性。
-
提示模板 (Prompt Templates):针对不同任务使用固定的、精心设计的提示模板。
-
硬件:单节点8卡Nvidia H800 GPU。
-
-
主要结果与分析 (Main Results and Analysis):
-
性能对比 (Performance Comparison):
-
表3 (Table 3) 详细列出了AIM在不同基线模型、不同shot数(0, 4, 8, 16)下与原始模型和其他方法的性能对比。
![![[image-100.png]]](https://i-blog.csdnimg.cn/direct/0e688d14748340498010cf8698f02408.png)
-
图2 (Figure 2) 以雷达图的形式直观展示了AIM(AIM-QWen, AIM-LLAVA)与其对应基线模型(QWen-VL-Chat, LLaVA-Next)在16-shot设置下各项任务的性能和吞吐量对比。
![* ![[image-96.png]]](https://i-blog.csdnimg.cn/direct/b7eb6b83f61f47d28335bef987013d42.png)
-
-
效率分析:
-
显存消耗 (Memory Cost):图1 (Figure 1) 清晰地展示了AIM与LLaVA-Next、OpenFlamingo在不同shot数下的显存占用对比。AIM的曲线几乎是平的。
![* ![[image-86.png]]](https://i-blog.csdnimg.cn/direct/843e4ba22d7a43c08f6a80082c28a78a.png)
-
推理吞吐量 (Inference Throughput):图6 (Figure 6) 展示了在Flickr30k上,AIM(不同聚合层数和有无DB)与基线模型在不同shot数下的推理速度(iter/s)变化。
-
Token数量统计 (Token Statistics):表4 (Table 4) 列出了AIM在不同基线模型下,多模态演示中视觉token数量、平均文本token数量以及最终保留的token比例。
![* ![[image-97.png]]](https://i-blog.csdnimg.cn/direct/3776ce6e92b74b58b14c82d53ce94fe1.png)
-
-
困惑度分析 (Perplexity Tendency):
- 图5 (Figure 5) 展示了在Flickr30k上,AIM(不同聚合层数)和基线模型在不同shot数下对黄金标签的困惑度变化趋势。
![* ![[image-98.png]]](https://i-blog.csdnimg.cn/direct/8fde9b0f04c746bb8dc050a376732c04.png)
- 图5 (Figure 5) 展示了在Flickr30k上,AIM(不同聚合层数)和基线模型在不同shot数下对黄金标签的困惑度变化趋势。
-
消融实验 (Ablation Studies):
- LLM聚合层数 (-16/-24 in Table 3):表3 中带有 “-16” 和 “-24” 后缀的行展示了使用LLM不同数量的层进行聚合的结果。
- 训练数据的影响:虽然论文中未详细展开,但提到在MMC4上训练投影层有助于模型更好地理解图文交错输入。
- LoRA微调对比:表3 中带 “∗” 标记的行表示对基线模型使用LoRA进一步微调的结果,用于与AIM进行比较。
![![[image-99.png]]](https://i-blog.csdnimg.cn/direct/aa1474af74b94dee922a657854a37c79.png)
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









