







多模态大语言模型综述
中科院一区 2024.11
多模态大语言模型(MLLM)
1. 简介
LLM在自然语言处理(NLP)任务上表现很好,例如指令遵循,上下文学习,思维链。但是,它们有一个很大的局限性:它们只能处理文本信息,无法处理图像、视频等视觉信息。
大型视觉模型(LVM)能够很好地处理图像和视频,但它们在推理方面表现不佳。也就是说,它们可以“看到”东西,但不擅长理解这些视觉信息背后的含义。
因为LVM基本还是传统的CV模型,只是近年来参数越来越大。目前最先进视觉模型也就几个b的大小,因为图像虽然计算量大,纬度空间不高,不算复杂。
两个结合就形成了多模态大语言模型MLLM,它在LLM的基础上,能够理解图像,音频等多模态信息。不过本文这里讲多模态只讲图像。
多模态之前的研究分两类:
分辨式就是经典的cv,做语义分割,图像分类,目标检测。clip就是分辨式最代表性的模型。
生成式的代表模型OFA(one for all),它把多模态任务统一到序列到序列的方式,就像训练LLM一样,通过decoder架构学习这个词的前后关系,预测下一个词。我们把这个视觉信息和文本信息都统一在一个空间中,都叫token,然后进行序列到序列的训练,那这个模型就能理解视觉信息了。
MLLM基于LLM,所以是生成式模型,把视觉信息和文本信息对齐,预测下一个token。
MLLM展现出了许多新的能力,比如:
- 基于图像编写代码:给出网站图片,生成对应的前端代码
- 理解图片的深层含义:能够理解图片中的幽默或讽刺含义。
- 无需OCR的数学推理:给出数学题目截图,直接从图像中进行数学推理,而不需要先将图像中的文字识别出来。
最开始研究集中在基于文本提示和图像的文本处理,后续工作扩展了功能和使用场景,往后的工作在更多的方向,比如:
- 更精细的用户提示控制:用户可以通过框选或点击来指定图像中的特定区域或对象。
- 支持更多模态:除了文本和图像,还支持视频、音频和点云等。
- 支持更多语言:尽管训练数据有限,但也在努力让MLLM支持更多语言,如中文。
- 扩展到更多领域:比如医学图像理解和文档解析。
—————————————————————————————————————————
1.1. 大型语言模型(LLM)的现状
近年来,大型语言模型(LLM)取得了巨大的进步。这些模型通过处理大量的数据和参数,在自然语言处理(NLP)任务上表现很好,比如:
- 指令遵循:能够理解并执行人类给出的指令。
- 上下文学习(ICL):能够根据上下文信息更好地理解任务。
- 思维链(CoT):能够逐步推理解决问题。
但是,它们有一个很大的局限性:它们只能处理文本信息,无法处理图像、视频等视觉信息。
1.2. 大型视觉模型(LVM)的现状
大型视觉模型(LVM)能够很好地处理图像和视频,但它们在推理方面表现不佳。也就是说,它们可以“看到”东西,但不擅长理解这些视觉信息背后的含义。
因为LVM基本还是传统的CV模型,只是近年来参数越来越大。目前最先进视觉模型也就几个b的大小,因为图像虽然计算量大,但是并不复杂,纬度空间不高。
通过卷积核或者是注意力机制把每个小patch特征提取出来,在几个b的体量,就够了。
1.3. 多模态大型语言模型(MLLM)的诞生
我们希望既有视觉能力,又有推理能力
为了解决LLM和LVM的局限性,互补,研究者们开始将它们结合起来,形成了多模态大型语言模型(MLLM)。MLLM的目标是让模型能够同时处理文本和视觉信息,比如图像、视频等。
MLLM有以下几个特点:
- 基于大型语言模型(LLM):它继承了LLM的强大语言处理能力。
- 多模态输入和输出:能够接收和处理多种类型的信息(如图像、文本、音频等),并生成相应的输出。
很多MLLM不一定输出多模态,但可以输入多模态
多模态之前的研究分两类:
分辨式就是经典的cv,做语义分割,做分类,目标检测。clip就是分辨式最代表性的模型,他把这个视觉跟文本的信息投射到一个统一的映射空间里面,把这两个模态进行统一。
生成式的代表模型OFA(one for all),它把多模态任务统一到序列到序列的方式,就像训练LLM一样,通过decoder架构学习这个词的前后关系,预测下一个词。那么我们把这个视觉信息和文本信息都统一在一个空间中,都叫token,然后进行序列到序列的训练,那这个模型就能理解视觉信息了。
MLLM的主流做法类似OFA,把图像通过编码方式,然后跟这个文本打包到同一个向量空间里,进行下一个token的预测。
那么MLLM与OFA有什么区别呢,
- 基于LLM
- MLLM使用了新的训练技巧把这个多模态能力给完全释放出来,比如使用多模态的指令微调技术,更好遵循指令
基于以上区别,MLLM展现出了许多新的能力,比如:
- 基于图像编写代码:给出网站图片,生成对应的前端代码
- 理解图片的深层含义:能够理解图片中的幽默或讽刺含义。
- 无需OCR的数学推理:给出数学题目截图,直接从图像中进行数学推理,而不需要先将图像中的文字识别出来。
1.4. MLLM的发展历程
自GPT-4发布以来,MLLM的研究迅速发展,比如23年发布的gpt-4-turbo语言理解能力很强,gpt-4v图片识别很强,但文本理解能力很弱,直到24年8月发布的gpt-4o才统一了两者之间的差距,走的是同一个框架。
最开始集中在基于文本提示和图像的文本处理,后续工作扩展了功能和使用场景,往后的工作在更多的方向,比如:
- 更精细的用户提示控制:用户可以通过框选或点击来指定图像中的特定区域或对象。
- 支持更多模态:除了文本和图像,还支持视频、音频和点云等。
- 支持更多语言:尽管训练数据有限,但也在努力让MLLM支持更多语言,如中文。
- 扩展到更多领域:比如医学图像理解和文档解析。
代表性MLLM的时间表
![![[Pasted image 20250407184514.png]]](https://i-blog.csdnimg.cn/direct/0a1c7f62758b42ec846c8c5a1bf6301b.png)
2. 多模态大语言模型的架构
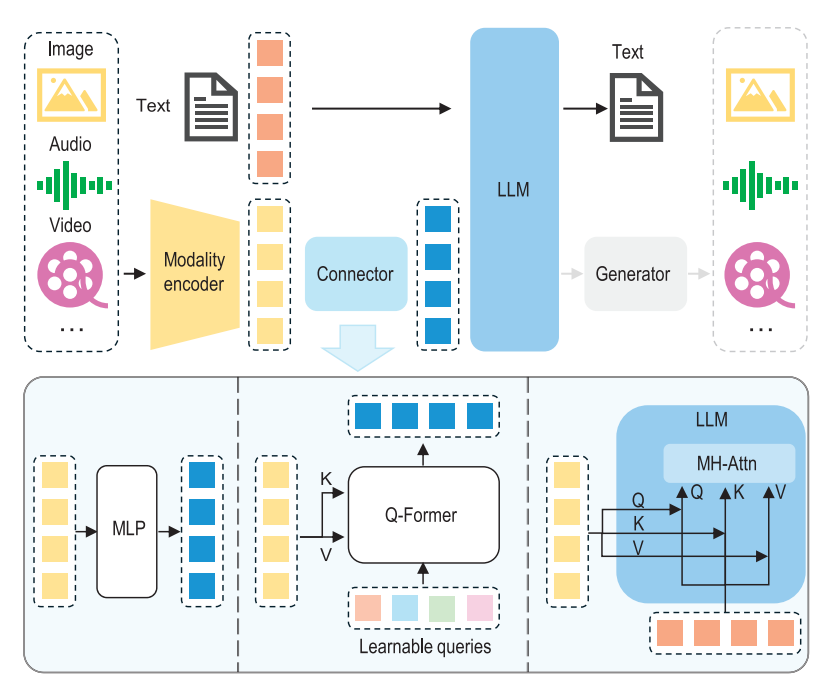
多模态大语言模型(MLLM)的架构可以分为三个主要部分:模态编码器、大型语言模型(LLM)和模态接口。我们可以把它们类比为人类的感官系统和大脑。
- 模态编码器(Modality encoder):就像人的眼睛和耳朵一样,模态编码器负责接收和处理图像、音频等信息。这些编码器会把复杂的图像或音频转换成更简洁的信息,让后续的处理更方便。
- 大型语言模型(LLM):这就好比人类的大脑,它负责理解和推理。LLM通过大量的预训练,已经学会了如何处理语言信息,并且能够进行复杂的思考。
- 模态接口(Connector):这个部分就像是眼睛和大脑之间的“神经”,它负责把编码器处理好的信息传递给LLM,并且让两者能够协同工作。
部分MLLM还包含一个生成器(Generator),用于输出文本之外的其他模态内容。但是大部分的MLLM,只是做VQA图像理解的事情。多模态的生成呢,有其他更好的模型可以做,比如说生成图像的主流方法是用扩散模型来做。
————————
模态编码器最常用的是CLIP,多模态大语言模型相关研究,80%的情况都是用到了CLIP的变体。
主要介绍一下CLIP的原理,这就能代表模态编码器的原理。
讲解一下clip的预训练过程(左)和使用过程(右)
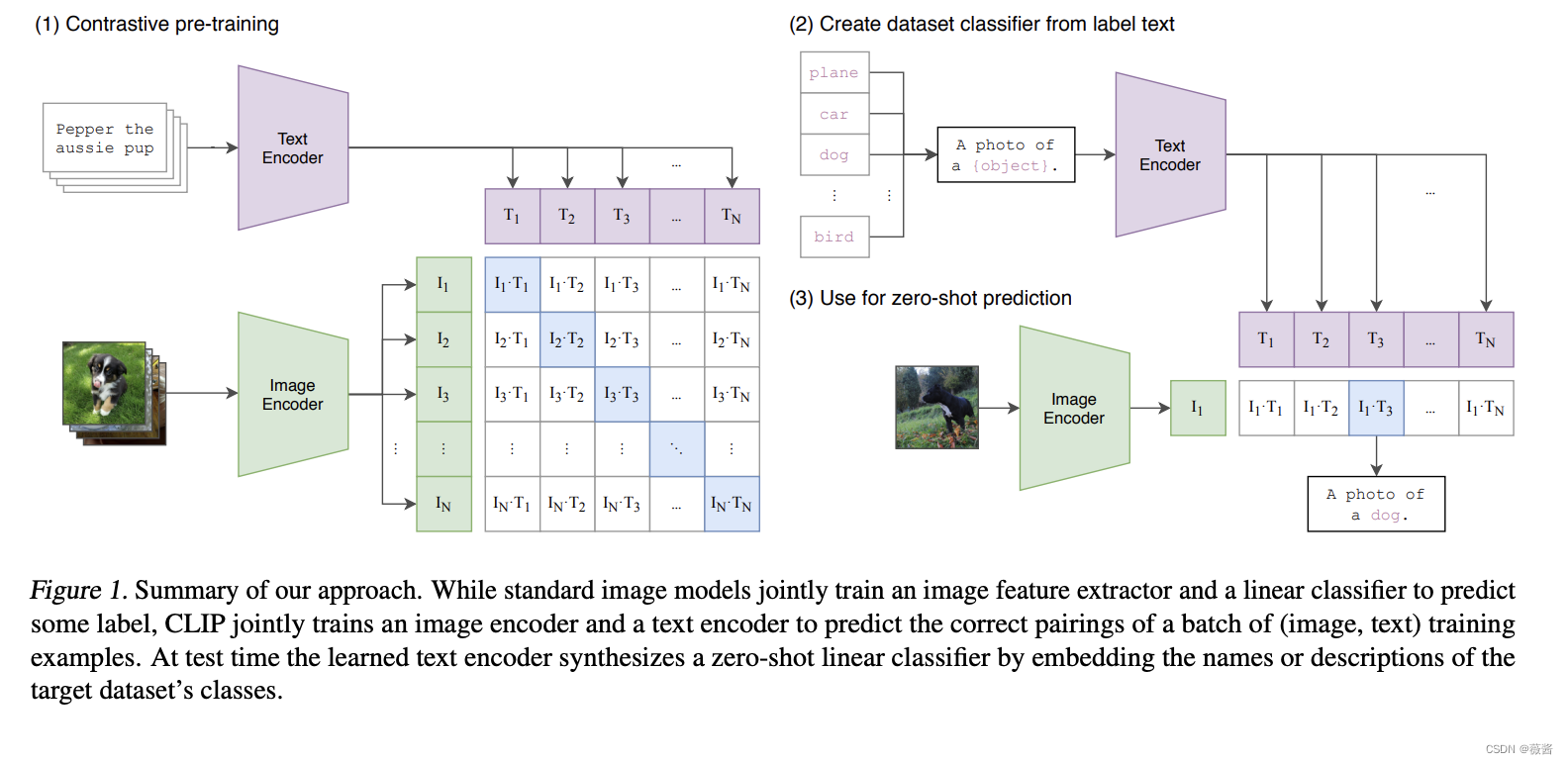
比如说这个讲到了一个zero-shot perdiction,就是说我们输入一张图像,就可以判断图像是什么。比如我们这里提供了一系列的这个可选的描述文本,比如这个数据集是CIFAR的100个类别。那么我们输入一张图像,然后这个图像通过这个CLIP的image encoder来编码,然后到一个image的embedding空间,然后我们对这100个不同的描述同样做这个text encoder到text embedding中,然后去测算image embedding跟每个text embedding之间的一个点积,相当于是一个CLIP-score,就是来看这个图文的这个匹配相似度。,然后我们发现第三个,dog的相似度最高,然后就输出。这就是CLIP模型最典型的应用来做一个图文配对的事情。这里的文本可以是任何形式的,任何的文本我们都可以做一个跟这个图像相似度匹配的事情。所以可以进一步识别是站着的狗还是蹲着的狗。
那么这个模型训练就是用图文对训练,首先是有个数据集,数据集就是网上爬虫下来的图文配对数据,这些数据没经过监督,但是大部分情况下都是有效的,最重要的是数据的体量够大,我们人工设计的一些文本对数据集体量太小了,要么用模型生成,要么在网上爬虫。然后我们训练一个text encoder把得到的数据集的文本转成对应的text embedding,比如n是100就100个
embedding,同样的,图像通过训练的一个image encoder,一般基于ViT(vision transformer),训练的时候打成一个小patch去理解,然后输出一个image embedding。
然后把图文对的text embedding 和image embedding对应拼成一个矩阵,两两做点积,最后训练策略就是让对角线上的值尽量大,非对角线上的值尽可能小。这样模型就学会了图文的配对方式。
这个训练采用无监督的方式,泛化能力很强,从21年推出至今广泛用在各类的图像编码器中。
——————
就是平常用的大语言模型。
模型参数越大,性能越好
——————
connector的作用把这个多模态的embedding转换到能够跟text embedding匹配的一个空间里面去。
大致有三种类型的连接器:基于映射,查询和融合。前两种类型采用token级融合,将特征处理成token并与文本token一起发送给LLM,而最后一种类型在LLM内部实现特征级融合。
- 一个是直接用个mlp(多层感知机)层做映射,把各种形式多模态embedding对齐到能跟我们的text embedding一致的一个空间里面去,比较简单直接但有效,LLaVA模型就这么做的。
- 另外一个基于查询,就稍微复杂一点了,它引入一个小的transformer模块来,根据KQV(qkv是transformer的基本概念,Query查询、Key键、Value值,Query 用于向 Key - Value 对发起 “查询”,以确定需要关注的信息。),之前通过encoder得到的多模态embedding作为k和v,然后我们设一个可以学习的query,通过这个一个小query transformer,把它映射到一个能跟文本匹配的embedding空间里面去。
- 第三种就是基于特征的融合,直接在大模型的内部做一个融合,LLM的原理就是将text embedding进入Transformer 层的attention模块,转换为QKV,并用多头注意力机制捕捉 token 之间的关系。经过多层 Transformer 的处理,模型逐步提取上下文信息并生成最终的输出。现在我们的这个多模态embedding也进入Transformer 层,为了能够让大语言模型接收和理解,这个attention模块会做相应的调整,能够把这个多模态的QKV信息抓取进来。
专家模型
它的原理用一个视觉专家模型替代encoder和connector,直接文字描述图片内容。比较典型的例子就是image2LLM,专家模型对图片做多轮的描述(image captioning),然后把这个图片描述的对话文本,结合提示词一起发给LLM。
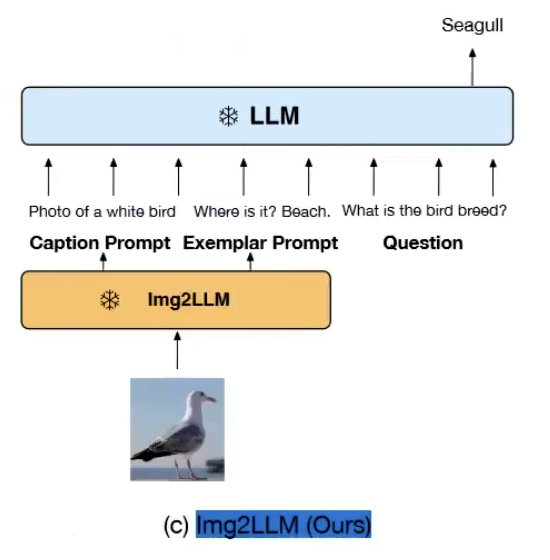
这方法优点就是简单,但在视频领域,时空的依赖关系可能给忽视掉。
————————
总的来说,MLLM的架构还是很简单的,核心还是LLM,这部分都是预训练好的,一般冻结,不做改变,一般使用LLaMa,Qwen这些主流的大语言模型作为这个大脑,然后我们这个多模态信息走一个这个多模态的encoder里,编码到一个embedding空间里。比如说我们就说图像的话,这个常见的encoder就是clip,CLIP 将图像分割成固定大小的 patches,并将这些 patches 转换到embedding里面,然后这个图像embedding已经非常接近这个text embedding了,但是由于clip跟我们这个LLM用的这个tokenizer还是有蛮大差别的,所以我们都会需要一个connector,把这个图像embedding空间对齐到能跟大模型能接受的这个embedding上来,这就是connector做的这个事情。这个connector有三种实现方式,最简单的用mlp,这是LLaVA的实现方式。第二个复杂一点比如说BLIP,就是用的Q-former,接一个小的transformer,把这个多模态embedding空间转换一下,第三个再复杂一点,直接在LLM的transformer层里面做一个调整。
————————————————————————————————第二部分稿子
2.1 模态编码器(Modality encoder)
模态编码器的作用是把图像、音频等原始信息转换成更简洁的形式。通常,我们会使用已经预训练好的编码器,因为这些编码器已经在大量的图像和文本数据上进行了学习,能够很好地理解图像和文本之间的关系。
模态编码器最常用的是CLIP,多模态大语言模型相关研究,80%的情况都是用到了CLIP的变体。
主要介绍一下CLIP的原理,这就能代表模态编码器的原理了。
讲解一下clip的预训练过程(左)和使用过程(右)
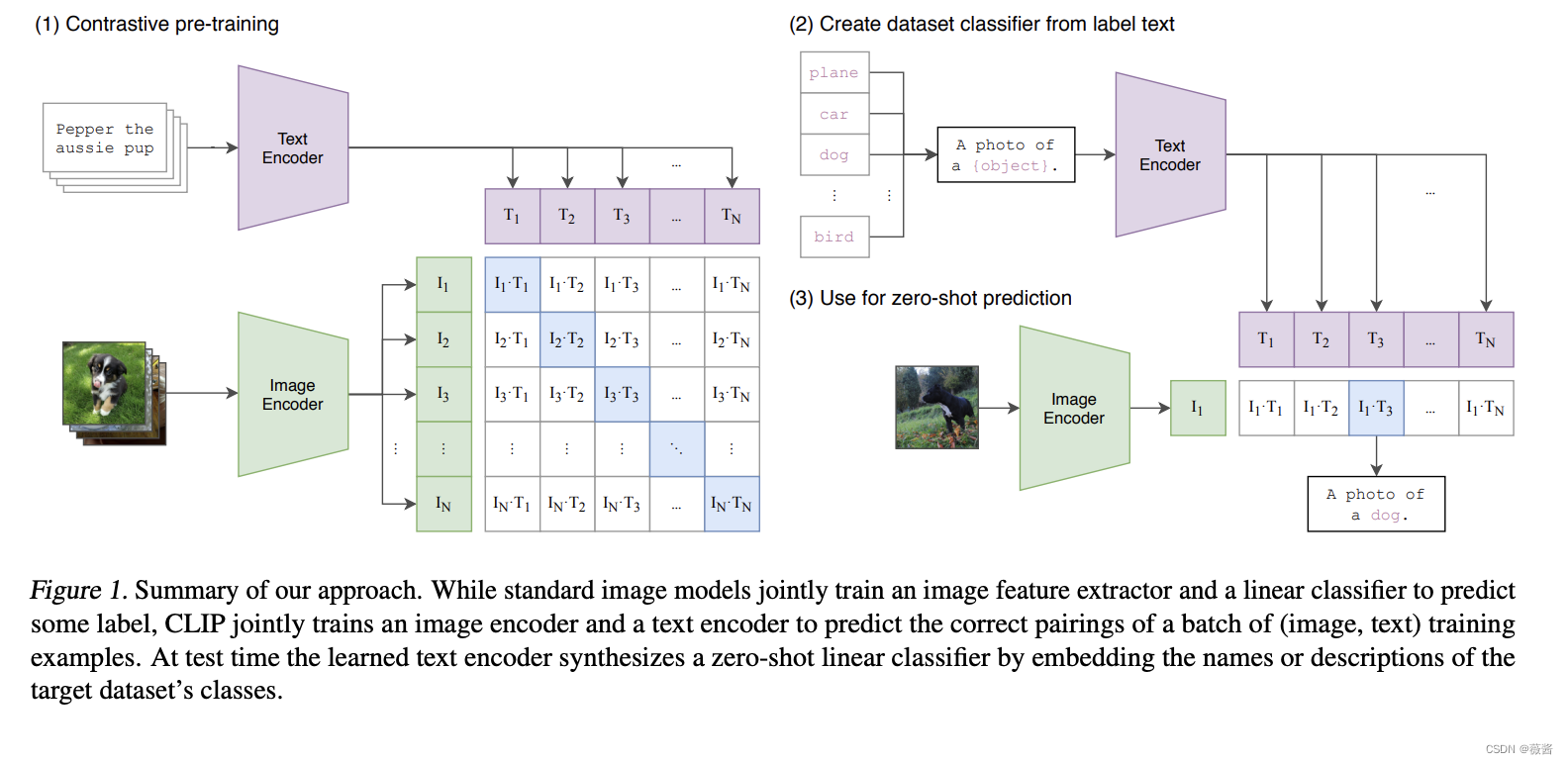
比如说这个讲到了一个zero-shot perdiction,就是说我们输入一张图像,就可以判断图像是什么。比如我们这里提供了一系列的这个可选的caption文本,比如这个数据集是CIFAR的100个类别。那么我们输入一张图像,然后这个图像通过这个CLIP的image encoder来编码,然后到一个image的embedding空间,然后我们对这100个不同的caption同样做这个text encoder到text embedding中,然后去测算这个图像,image embedding跟每个text embedding之间的一个点积,相当于是一个CLIP-score,就是来看这个图文的这个匹配相似度。,然后我们发现第三个,dog的相似度最高,然后就输出。这就是CLIP模型最典型的应用来做一个图文配对的事情。这里的文本可以是任何形式的,任何的文本我们都可以做一个跟这个图像相似度匹配的事情。所以可以进一步识别是站着的狗还是蹲着的狗。
那么这个模型是怎么实现这个效果的,首先是有个数据集,数据集就是网上爬虫下来的图文配对数据,这些数据没经过监督,但是大部分情况下都是有效的,最重要的是数据的体量够大,我们人工设计的一些文本对数据集体量太小了,要么用模型生成,要么在网上爬虫。然后我们训练一个text encoder把得到的数据集的文本转成对应的text embedding,比如n是100就100个
embedding,同样的,图像通过训练的一个image encoder,一般基于ViT(vision transformer),训练的时候打成一个小patch去理解,然后输出一个image embedding。然后把图文对的text embedding 和image embedding对应拼成一个矩阵,两两做点积,最后训练策略就是让对角线上的值尽量大,非对角线上的值尽可能小。这样模型就学会了图文的配对方式。
这个模型采用无监督的方式,泛化能力很强,从21年推出至今广泛用在各类的图像编码器中。
——————————————————————
-
常用的图像编码器:比如CLIP,它通过在大量的图像-文本对上进行预训练,学会了如何把图像和文本对齐。除了CLIP,还有一些其他的编码器,比如MiniGPT-4使用的EVA-CLIP,它通过改进的训练技术进一步提升了性能。
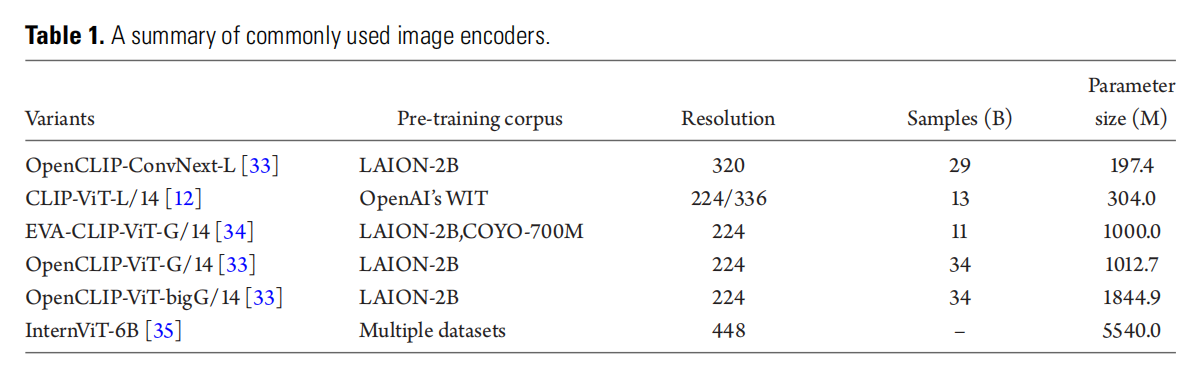
-
输入分辨率的重要性:研究表明,使用更高分辨率的图像可以显著提升模型的性能,输入图像的分辨率越高,模型的性能和输出效果通常会更好。比如,CogAgent使用了双编码器机制,一个处理高分辨率图像,一个处理低分辨率图像,通过交叉注意力将两者的信息结合起来。
2.2 预训练的LLM
不多讲了,就是平常用的大语言模型。
LLM是整个MLLM模型的核心部分,它负责理解和推理。通常,我们会使用已经预训练好的LLM,因为这些模型已经在大量的文本数据上进行了学习,积累了丰富的知识。
-
常用的LLM:比如Flan-T5、LLaMA等,这些模型在自然语言处理任务上表现很好。但它们大多只支持英语,对于多语言的支持有限。相比之下,Qwen是一个支持中文和英语的双语LLM。
![![[Pasted image 20250408133559.png]]](https://i-blog.csdnimg.cn/direct/0a952d1d24c6405ba533b1e6a6aa8a16.png)
-
模型规模的影响:模型的参数规模越大,性能通常越好。比如,当LLM的参数从7B增加到13B时,模型在各种基准测试上的表现都有显著提升。
2.3 模态接口
我们通过模态编码器把这个图像的信息给编码下来之后,还是要桥接一下,才能跟这个语言模型的输入给对齐上去,
这个token层面的融合,前两个方式,模态的编码器是什么类型不重要,输出的这个视觉token数量和输入的分辨率更重要
cross-attention layers 动手脚
实现模态接口主要有两种方法:可学习的连接器(Learnable Connector)和专家模型(Expert Model)。
2.3.1 可学习的连接器
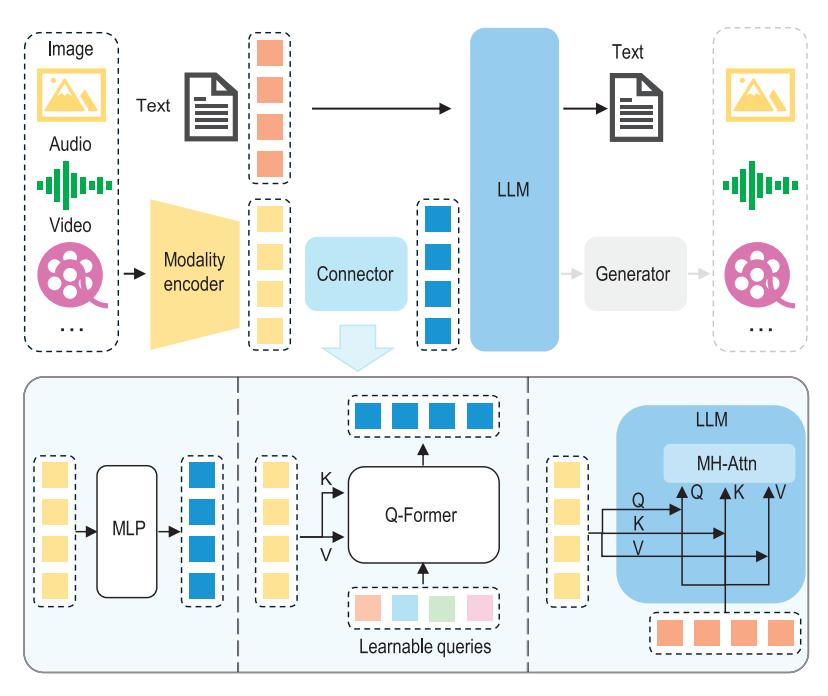
可学习的连接器是一个可训练的模块,它的任务是将不同模态的信息转换成LLM能够高效理解的形式。它通过以下两种方式实现:
-
token级的融合:把编码器输出的特征转换成token,然后和文本token拼接在一起,输入到LLM中。这种方法比较直接,可能会丢失一些信息。
- 一个常见实现(基于查询)基于Q-Former(Querying Transformer) ,它的核心思想是使用一组可学习的“查询Token”(Learnable Queries),通过注意力机制(Attention Mechanism)从编码器输出的特征中提取有用的信息。这些查询Token可以看作是对输入特征的主动“提问”,Q-Former模块会根据这些提问生成一组紧凑的表示向量。这种方法将视觉token压缩成更少的表示向量,从而让LLM能够处理。
- 另一种方法是(基于投影)直接使用基于MLP(多层感知机)的接口来对齐模态,例如LLaVA系列采用MLP将视觉token投影到与文本token对齐的特征维度上。
-
特征级的融合:在LLM的内部插入一些额外的模块,让视觉特征和语言特征能够更深入地交互和融合。比如,Flamingo多模态模型在LLM的Transformer层之间插入了交叉注意力层,这样可以让语言特征更好地利用视觉信息。
研究表明,在视觉问答(VQA)基准测试中,token级融合的表现优于特征级融合。
需要注意的是,可学习连接器的参数量通常比编码器和LLM小得多。例如,在Qwen-VL模型中,基于Q-Former的模态接口的参数量约为0.08B,占总参数量的不到1%,而编码器和LLM分别占约19.8%(1.9B)和80.2%(7.7B)
2.3.2 专家模型
我们不直接对这个图像特征像clip一样做个embedding的特征提取,直接把图片用文字描述出来。
比较典型的例子就是image2LLM,一个图像进来,我们想做多模态,那正常这里应该是接一个clip,然后做image encoder embedding,然后接connector,然后再传到大模型里面。它是怎么做的呢,它直接用一个视觉专家模型,可能是自己训练的可能是现成的,专家模型对图片做多轮的描述(image captioning),然后把这个图片描述的对话文本,结合提示词一起发给LLM。
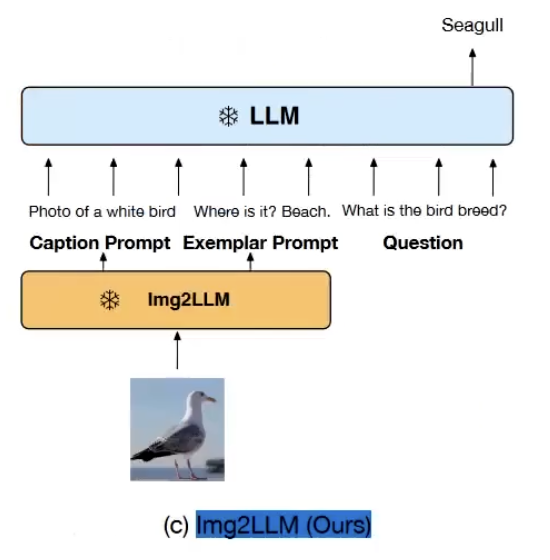
这个优势就是简单,但在视频领域,时空的依赖关系可能给忽视掉。
3. 多模态大语言模型的训练流程
一个完整的MLLM要经历三个阶段的训练:预训练、指令微调和对齐微调。
预训练:让模型学习多模态知识,对齐不同模态。
指令微调:让模型学会理解人类指令,提升零样本性能。
对齐微调:让模型的输出更符合人类偏好,减少幻觉现象。
这和我们训练大语言模型的步骤也是一样的。
3.1 预训练
核心目标
预训练的主要目标是对齐不同模态(例如图像和文本),并让模型学习多模态的知识。
我们预训练要做的事了,做一个模态的对齐。就是我有一个大语言模型作为大脑能够很好做文本的推理跟理解;我有一个预训练好的图像编码器,能很好地理解图像的信息,但是我需要把这个图像的embedding跟文本的embedding两个模态结合在一起。
回忆我们之前讲的这个架构部分,模态编码器和LLM这两部分,其实都是已经预训练好的模型了。所以在MLLM主流预训练方法就只预训练这个connector,另外两部分冻结起来。
预训练需要很大的图像文本对的数据集。
看看这个数据格式:
首先输入一个图像image,用pytorch读进来,转成tensor形式,然后把这个图像数据通过image encoder,转成image embedding,就把图像理解到了。然后呢,我们有个对应的文本信息caption,用LLM的tokenizer把它转成text embedding,然后把这两个配对在一起做一个配对的理解。
![![[Pasted image 20250407234222.png]]](https://i-blog.csdnimg.cn/direct/7ec7e5fcbfa346059eacf65b03f945da.png)
一个用于构建图文数据的简化模板。
<image>是视觉标记的占位符,而{caption}是图像的标题。需要注意的是,只有用红色标记的部分才被用于损失计算(用于衡量模型预测结果与真实目标之间的差异)。
训练策略跟数据质量是强相关的,如果文本数据较短且有噪声(比如从网页上爬取的简单描述),可以使用较低分辨率的图像来加快训练速度。但如果文本数据较长且质量较高,使用更高分辨率的图像会更好,而且能够有效减少幻觉现象(即模型生成与图像内容不符的描述)。
最后提一下,也有一些多模态模型预训练解冻了其他部分,比如qwen-vl在预训练的时候还训练了模态编码器,效果确实好了点。
![![[Pasted image 20250412212434.png]]](https://i-blog.csdnimg.cn/direct/41d4c6620e3e4ff0a5aab320d676a7e2.png)
一篇文章构建了一个叫shareGPT4V的数据集也应证了这点,它发现在训练高质量图文数据的时候,让这个视觉编码器可训练,会让整体的模型表现更好。
——————————————————
训练过程
- 数据类型:预训练通常使用大规模的图文配对数据,例如图像的字幕。这些文字描述了图像的内容,帮助模型理解图像和文本之间的关系。
- 训练方法:一种常见的方法是冻结预训练的模块(比如视觉编码器和LLM),然后训练一个可学习的接口(模态接口)来对齐这些模态。这样做的好处是可以保留预训练模块已经学到的知识,同时让模型学会如何处理多模态信息。(类似LoRA微调,只微调LLM的一小部分)
- 数据质量与分辨率:如果字幕数据较短且嘈杂(比如从网页上爬取的简单描述),可以使用较低分辨率的图像来加快训练速度。但如果字幕数据较长且质量较高,使用更高分辨率的图像会更好,因为它能帮助模型减少幻觉现象(即模型生成与图像内容不符的描述)。
数据集举例
- CC-3M:包含330万图像-字幕对,数据从网络爬取,经过清洗和过滤,确保图像和字幕的质量。
- LAION系列:这是一个非常大的数据集,包含数十亿图像-文本对,用于训练模型理解和生成高质量的描述。
![![[Pasted image 20250408121541.png]]](https://i-blog.csdnimg.cn/direct/fa5180c61db145459ddd6788430ad8ac.png)
3.2 指令微调
上一步预训练就是对齐不同的模态,然后学习这个多模态知识,学习完了之后,我们就训练好了一个connector了。
现在的指令微调,就是要用这个更复杂的图像文本数据集去提升我们这个模型的能力。之前我们给的数据只是做一个connector,把模态对齐,LLM能看见多模态信息了,但是没见过,看不懂,所以通过指令微调,模型能学习到如何理解图像文本数据中的语义、逻辑等内容,从而提升对多模态信息的理解与处理能力,能够完成多模态任务。
MLLM的指令微调跟LLM的指令微调是一样的,因为这个理解推理部分仍然是LLM来执行,我们前面通过modality encoder 和connector已经把这个图像信息基本都提取出来了,指令微调就是在这个LLM上面训练。
![![[Pasted image 20250412225545.png]]](https://i-blog.csdnimg.cn/direct/f950c4e8d98b4cea81c3f7276e69a01b.png)
一个简化的多模态指令微调的数据集模板。有三个字段,
<instruction>是对任务的文字描述,比如“详细描述这幅图”。{<image>, <text>}是图像和描述信息可能缺少<text>,<output>是模型期望输出。
——————————————————————————————————
![![[Pasted image 20250412221849.png]]](https://i-blog.csdnimg.cn/direct/08b93433a6c24efe8b1485594747a094.png)
另外讲一下,大模型有三种微调范式,(a)预训练微调:用a任务的数据微调,然后做a任务,这是有监督微调,为了让模型完成某项特定任务(b)提示词工程:因为大模型本身就有很强的零样本学习能力,我们只需要在提示词里面把这个任务指定下就能完成,但这样的方式,LLM只是利用通用知识,然后去完成没见过的任务,效果一般。(c)指令微调,做法就是,我们准备一个有非常多种任务的指令数据集,通过大量对不同任务的学习,使模型掌握遵循指令的能力,效果就是拿bcd这些任务去训练大模型,它就能学会执行没见过的a任务。这是为了让模型实现多任务
————————————————————
训练过程
- 数据类型:指令微调的数据包括指令、输入(可以是图像、文本或两者都有)和期望的输出。例如,一个指令可能是“详细描述这幅图”,输入是一张图像,输出是图像的详细描述。
- 训练方法:模型通过学习这些指令和对应的输出,学会如何根据不同的指令生成正确的回答。这通常通过自回归的方式进行,即模型预测输出序列的下一个token。
- 数据收集:收集指令数据比较复杂,因为指令的形式和任务的表述多种多样。常见的方法包括:
- 数据适配:将现有的高质量数据集转换成指令格式。例如,将用于预训练的视觉问答(VQA)数据集中的问题和答案转换成指令和输出的形式。
- 自我指令:利用其他更先进的模型生成指令数据。例如,首先准备一小部分高质量的人工标注数据作为示例,输入给ChatGPT-4,然后ChatGPT-4根据这些示例生成更多的指令数据。
- 数据混合:将多模态指令数据和纯文本对话数据混合使用,提升模型的对话能力和指令遵循能力。
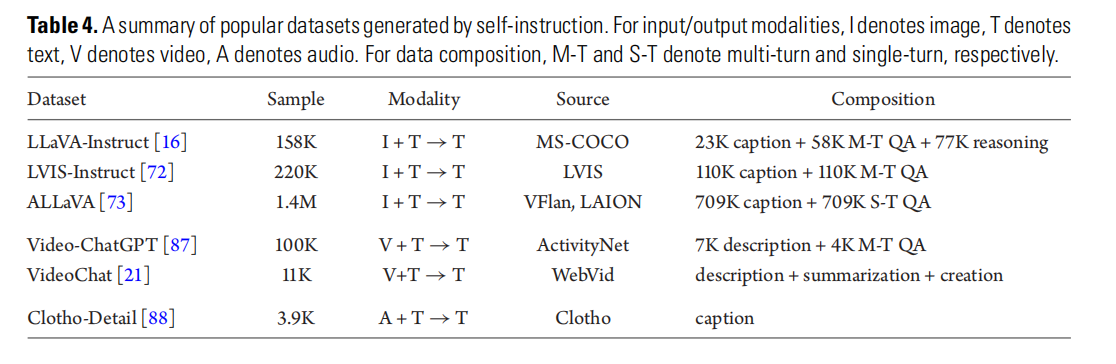
数据质量要求
- 指令多样性:模型需要接触各种各样的指令,这样它才能更好地理解和执行不同的任务。
- 任务覆盖范围:数据中包含的任务类型越丰富,模型的泛化能力就越强。
3.3 对齐微调
核心目标
对齐微调的目的是让模型的输出更符合人类的偏好,例如减少幻觉现象。
有两种训练方法,强化学习人类反馈(RLHF)和直接偏好优化(DPO)
RLHF是训练一个奖励模型对MLLM输出评分,然后让MLLM根据评分调整输出。
DPO直接用人类的偏好标签数据进行微调,不需要训练奖励模型。而且DPO是目前主流方法。
————————————
训练过程
- 强化学习人类反馈(RLHF):
训练一个奖励模型对MLLM输出评分,然后根据评分调整MLLM输出。- 监督式微调:先对MLLM模型进行微调,使其初步符合人类的偏好。
- 奖励建模:训练一个奖励模型,根据人类的偏好对MLLM模型的输出进行评分。
- 强化学习:使用强化学习算法(如PPO)优化模型,让MLLM模型根据奖励模型的评分来调整自己的输出。
- 直接偏好优化(DPO):直接用人类的偏好标签数据进行微调,不需要训练奖励模型。主流方法还是DPO
数据收集
人类偏好标签数据的收集,由人类打分或者ai打分。
- 人类打分:让人类标注员对模型的输出进行评分,决定哪种回答更好。
- AI打分:也可以使用AI模型(如GPT-4V)来提供反馈,但这种方法可能不如人类反馈准确。
数据集举例
- LLaVA-RLHF:包含1万个偏好对,由人类标注,主要用于减少幻觉现象。
- VLFeedback:包含38万个由GPT-4V评分的比较样本,用于提升模型的对齐效果。
![![[Pasted image 20250408124606.png]]](https://i-blog.csdnimg.cn/direct/1eb7a3e959594ef885edfafa00529da3.png)
4. 评价
MLLM的性能评估主要分为两类:封闭集评估和开放集评估。封闭集评估就是做题,开放集评估就是聊天。
封闭集
- 封闭集评估:做题。适用于特定任务的数据集,答案是有限的,可以通过标准评估指标进行衡量。
- 开放集评估:适用于聊天机器人场景,回答可以是任意的,评估更具挑战性,通常需要人工评分或使用GPT模型进行评分。
4.1 封闭集评估
核心概念
封闭集评估是指可能的答案选项被预定义且限定在一个有限集合内的问题。这种评估方法通常用于特定任务的数据集上,例如视觉问答(VQA)或图像字幕生成任务。因为有标准答案,所以可以通过对比模型输出,用标准的评估指标(如准确率、BLEU分数(相似性)等)来衡量模型的性能。
BLEU分数的核心思想是:如果模型生成的文本越接近人工撰写的参考文本,则其质量越高。
评估方法
-
零样本评估(Zero-shot Evaluation):在这种设置中,模型在训练时没有见过测试数据集,但需要在测试时完成任务。用没见过的数据集测试,考查模型的通用性和泛化能力。
-
例如,InstructBLIP [51] 在ScienceQA [100] 数据集上报告了准确率,这个数据集包含了科学问题和对应的答案。模型需要在没有见过这些问题的情况下,直接生成答案。
-
微调评估(Fine-tuning Evaluation):在这种设置中,模型在训练时会看到一部分数据集,并在测试时评估其性能。用见过的类似的数据集测试。考查模型在特定任务上的表现。
-
例如,LLaVA [16] 在ScienceQA [100] 数据集上进行了微调,并报告了微调后的性能。这种评估方法通常用于特定领域的任务,如生物医学视觉问答(biomedical VQA)。
4.2 开放集评估
核心概念
开放集评估是指模型的回答可以更加灵活,通常用于聊天机器人场景。因为回答的内容可以是任意的,所以评估比封闭集评估更具挑战性。
评估方法
-
人工评分(Manual Scoring):由人类评估模型生成的回答。这种方法通常涉及手工设计的问题,旨在评估特定维度。例如,mPLUG-Owl [107] 收集了一个视觉相关的评估集,以评估模型对自然图像、图表和流程图的理解能力。
-
GPT评分(GPT Scoring):使用GPT模型对回答进行评分。这种方法通常用于评估多模态对话的性能。例如,LLaVA [16] 提出使用仅文本的GPT-4从不同方面(例如有用性和准确性)对回答进行评分。具体来说,从COCO [108] 验证集中抽取30张图像,每张图像都通过在GPT-4上进行自我指令生成一个问题、一个详细问题和一个复杂推理问题。模型和GPT-4生成的答案都被发送到GPT-4进行比较。
-
案例研究(Case Study):让大模型做案例研究,测试综合能力,需要基本技能,世界知识和推理。例如,一些研究评估了两种典型的先进商用模型,GPT-4V和Gemini。Yang等人 [110] 通过设计一系列跨越不同领域和任务的样本对GPT-4V进行了深入的定性分析,这些任务从基本技能(如字幕生成和目标计数)到需要世界知识和推理的复杂任务(如笑话理解和作为具身代理的室内导航)。Wen等人 [111] 通过设计针对自动驾驶场景的样本,对GPT-4V进行了更集中的评估。Fu等人 [112] 通过将模型与GPT-4V进行比较,对Gemini-Pro进行了全面评估。
5. 挑战和未来方向
-
长文本多模态信息处理能力有限:当前的MLLM在处理长篇多模态上下文信息时存在局限性。这限制了具有更多多模态token的先进模型的发展,例如长视频理解以及包含图像和文本的长篇文档处理。
-
需要提升复杂指令遵循能力:MLLM需要升级以执行更复杂的指令。例如,目前生成高质量问答对数据的主流方法仍然是通过提示闭源的GPT-4V,因为其具有先进的指令遵循能力,而其他模型通常难以实现这一目标。
-
多模态上下文学习(M-ICL)和多模态思维链(M-CoT)技术有待提升:目前对这两种技术的研究仍处于初级阶段,MLLM在这些方面的能力也相对较弱。因此,探索其背后的机制和潜在改进方向具有重要意义。
-
基于MLLM的智能体开发:基于MLLM开发能够与现实世界交互的具身智能体是一个热门话题。这需要模型具备关键能力,包括感知、推理、规划和执行。
-
安全性问题:与LLM类似,MLLM也可能容易受到精心设计的攻击的影响,从而输出有偏见或不可接受的响应。因此,提高模型的安全性将成为一个重要的研究课题。
-
跨学科研究:鉴于MLLM强大的泛化能力和丰富的预训练知识,利用MLLM推动自然科学领域的研究是一个有前景的方向,例如将MLLM应用于医学图像或遥感图像的分析。为了实现这一目标,可能需要将特定领域的多模态知识注入到MLLM中。

















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









