









Spring Data JPA简介
JPA 简介
JPA(Java Persistence API)意即 Java 持久化 API,是 Sun 官方在 JDK5.0 后提出的 Java 持久化规范(JSR 338,这些接口所在包为 javax.persistence,详细内容可参考 https://github.com/javaee/jpa-spec。
JPA 的出现主要是为了简化持久层开发以及整合 ORM 技术,结束 Hibernate、TopLink、JDO 等 ORM 框架各自为营的局面。JPA 是在吸收现有 ORM 框架的 基础上发展而来,易于使用,伸缩性强。总的来说,JPA 包括 3 方面的技术:
ORM 映射元数据: 支持 XML 和注解两种元数据的形式,元数据描述对象 和表之间的映射关系。
API: 操作实体对象来执行 CRUD 操作。
查询语言: 通过面向对象而非面向数据库的查询语言(JPQL)查询数据,避免程序的 SQL 语句紧密耦合。
Spring Data JPA 简介
Spring Data 是 Spring 的一个子项目,旨在统一和简化各类型的持久化存储方式,而不拘泥于是关系型数据库还是 NoSQL 数据库。
无论是哪种持久化存储方式,数据库访问对象都会提供对对象的增加、删除、修改和查询的方法,以及排序和分页方法等。
Spring Data 提供了基于这些层面的统一接口以实现持久化操作。
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套 JPA 应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供 了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA可以极大提高开发效率!
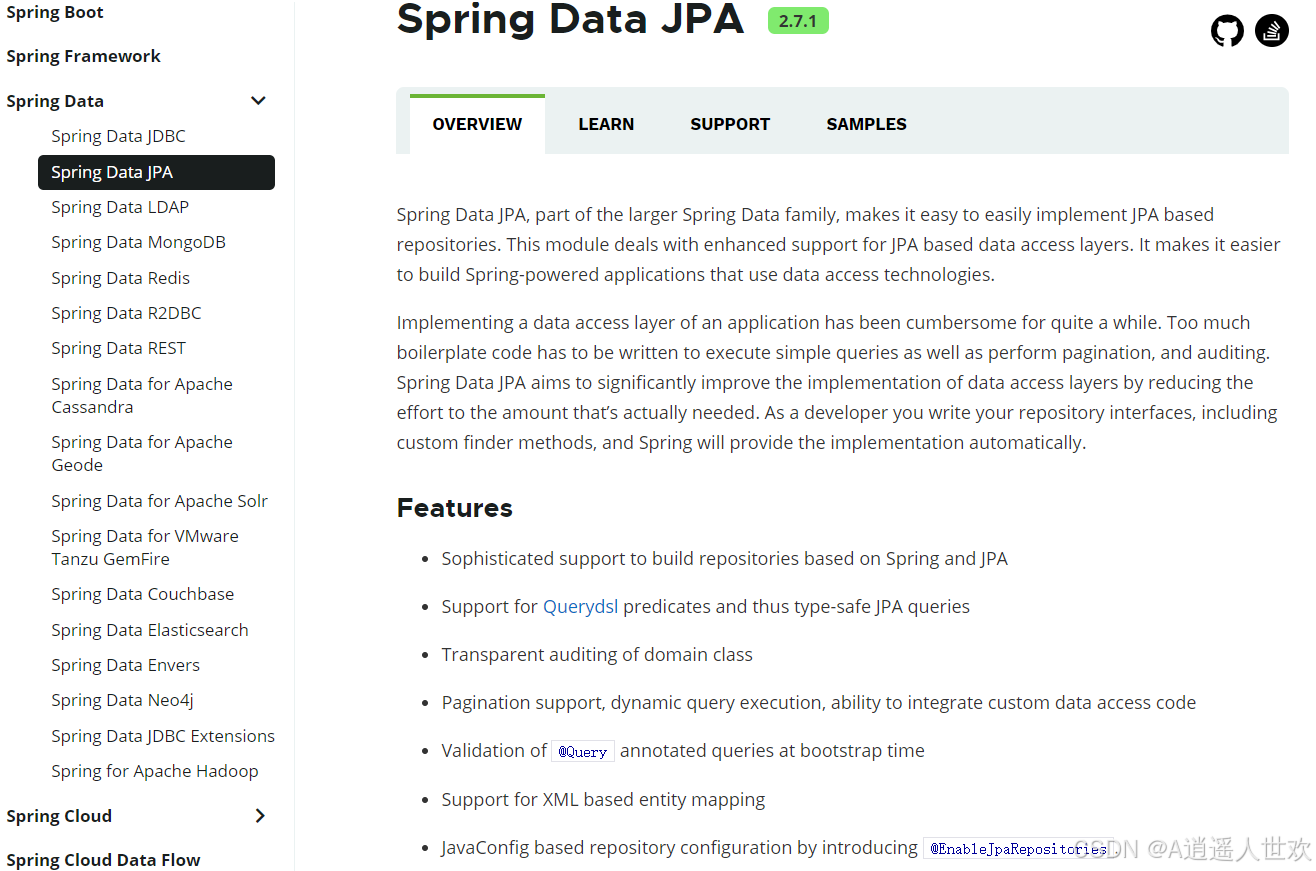
Spring Data JPA 是 Spring Data 家族的一部分,可以轻松实现基于 JPA 的存储库。 此模块处理对基于 JPA 的数据访问层的增强支持。 它使构建使用数据访问技术的 Spring 驱动应用程序变得更加容易。
在相当长的一段时间内,实现应用程序的数据访问层一直很麻烦。 必须编写太多样板代码来执行简单查询以及执行分页和审计。 Spring Data JPA 旨在通过减少实际需要的工作量来显著改善数据访问层的实现。 作为开发人员,您编写 repository 接口,包括自定义查找器方法,Spring 将自动提供实现。
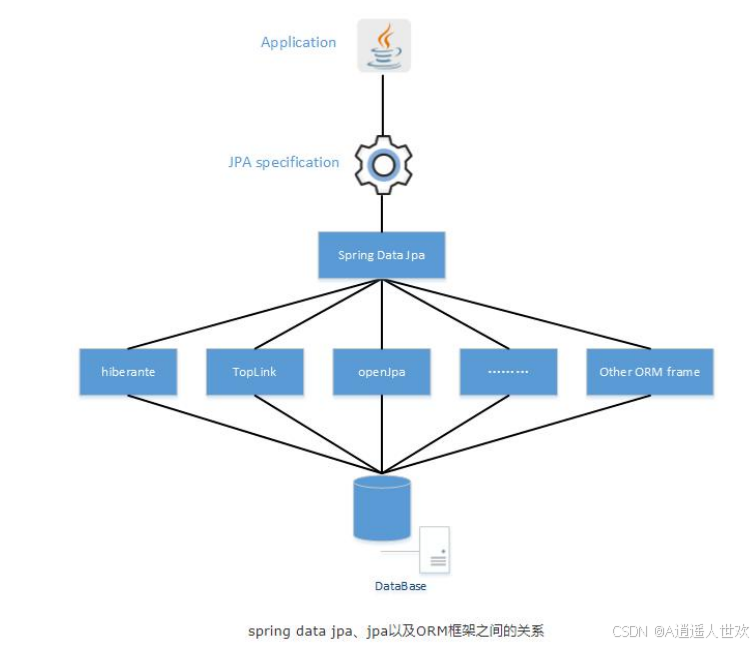
Jpa、Hibernate、Spring Data Jpa 三者之间的关系
JPA 是一套规范,内部是由接口和抽象类组成的。
Hibernate 是一套成熟的 ORM 框架,JPA 的标准的定制是 hibernate 作者参与定制的,所以可以理解 JPA 是 Hibernate 的一个功能子集,而且 Hibernate 实现了 JPA 规范,所以也可以称 hibernate 为 JPA 的一种实现方式,我们使用 JPA 的 API 编程,意味着站在更高的角度上看待问题(面向接口编程)。
Spring Data JPA 是 Spring 提供的一套对 JPA 操作更加高级的封装,是在 JPA 规范下的专门用来进行数据持久化的解决方案。
总的来说 JPA 诞生的缘由是为了整合第三方 ORM 框架,实现持久化领域的统一,简化现有 Java EE 和 Java SE 应用的对象持久化的开发工作。JPA 是 一套规范,而不是具体的 ORM 框架。Hibernate、TopLink 等是 JPA 规范 的具体实现,这样的好处是开发者可以面向 JPA 规范进行持久层的开发,而底层的实现则是可以切换的。Spring Data Jpa 则是在 JPA 之上添加另一层抽象,极大地简化持久层开发及 ORM 框架切换的成本。
Spring Boot整合JPA
创建工程
创建 Spring Boot 项目勾选 Spring Data JPA 和 MySQL 驱动包
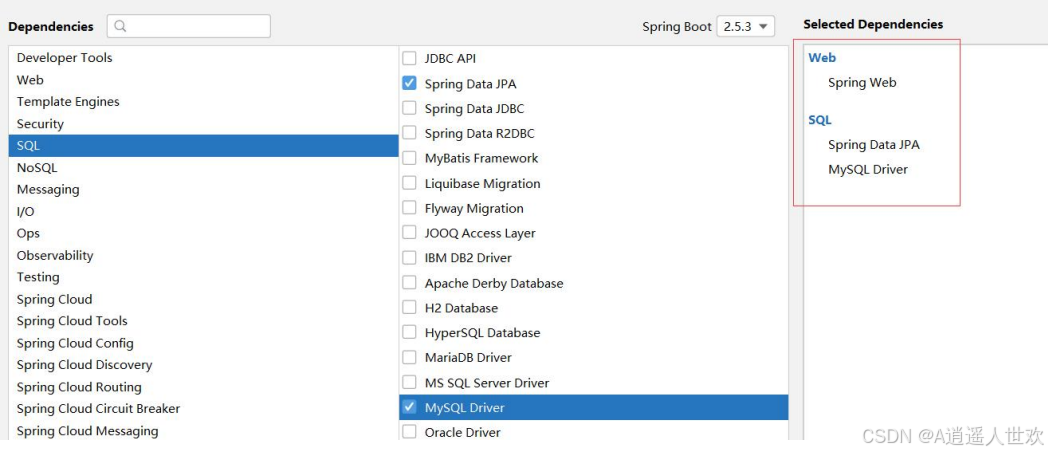
调整 pom.xml 文件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>修改 application-dev.yml 下配置配置文件
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
url: jdbc:mysql://127.0.0.1:3306/cvs_db?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
jpa:
#配置数据库
database: mysql
database-platform: org.hibernate.dialect.MySQL55Dialect #方言
show-sql: true #显示执行的 SQL 语句
hibernate:
#配置名字的策略
naming:
physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
#配置指明在程序启动的时候要删除并且创建实体类对应的表
# validate 加载 Hibernate 时,验证创建数据库表结构
# create 每次加载 Hibernate ,重新创建数据库表结构,这就是导致数据库表数据丢失的原因。
# create-drop 加载 Hibernate 时创建,退出是删除表结构(退出是指退出sessionFactory)
# update 加载 Hibernate 自动更新数据库结构
# none 不启用
ddl-auto: none
logging:
level:
com.sql: debug
javax.sql: debug创建实体类,并添加 JPA 注解
了解 JPA 注解和属性
在 cn.cvs.pojo 包中创建实例类 User
import cn.cvs.util.DateUtil;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.format.annotation.DateTimeFormat;
import javax.persistence.*;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table(name = "t_sys_user")
public class SysUser {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id; //id
private String account; //账号
private String password; //密码
private String realName; //真实姓名
private Integer roleId; //角色id
private String phone; //电话
private String address; //地址
private Integer sex; //性别
@DateTimeFormat(pattern = "yyyy-mm-dd")
private Date birthday; //出生日期
private Integer createdUserId; //创建人id
private Date createdTime; //创建时间
private Integer updatedUserId; //修改人id
private Date updatedTime; //修改时间
private String idPicPath; //证件照路径
private String workPicPath; //工作证照片路径
@Transient
private Integer age; //用户年龄
@Transient
private String roleIdName; //角色名称
public Integer getAge() {
return DateUtil.getYear(birthday);
}
}添加数据访问层
认识 JPA 的接口:JPA 提供了操作数据库的接口。在开发过程中继承和使用这些接口,可简化现有的持久化开发工作。
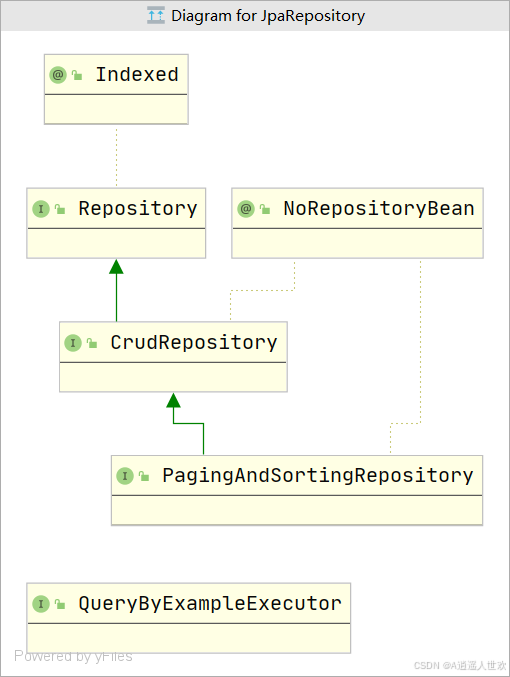
JPA 接口:JpaRepository
1) JpaRepository 继承自 PagingAndSortingRepository。该接口提供了JPA 的相关的实用功能。
2) 结构图
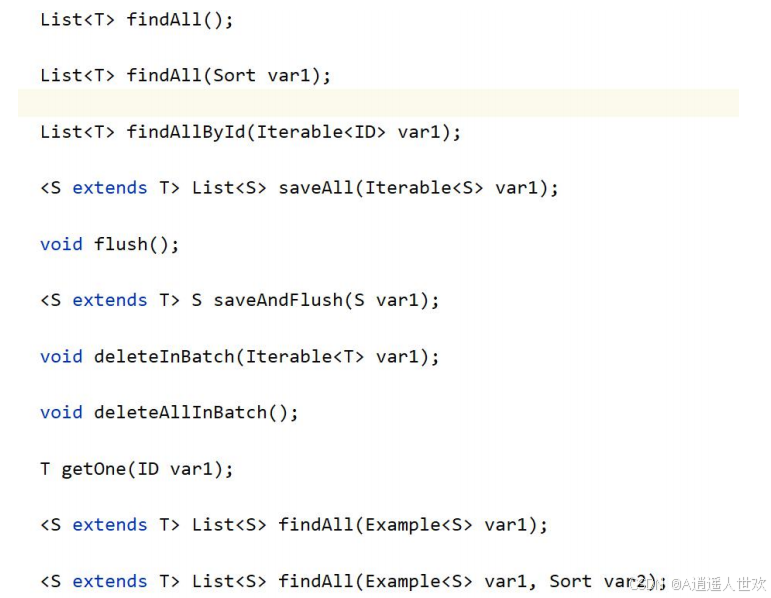
3) 方法列表
3、分页排序接口 PagingAndSortingRepository

4、数据操作接口:CurdRepository
 5、分页接口 Pageable 和 Page
5、分页接口 Pageable 和 Page
分页查询(PageRequest对象)相关函数
在执行查询方法时,可以传入一个PageRequest对象,代表进行分页查询。
PageRequest对象代表了查询的条件和约束,通常包含当前页数,每页几条数据。
也可以在分页查询时指定Direction或Sort。
查询的结果为Page<T>对象,包含当前页所及所有数据相关信息。
Page对象常用方法:
getTotalPages() 总共有多少页
getTotalElements() 总共有多少条数据
getNumber() 获取当前页码
getSize() 每页指定有多少元素
getNumberOfElements() 当前页实际有多少元素
hasContent() 当前页是否有数据
getContent() 获取当前页中所有数据(List<T>)
getSort() 获取分页查询排序规则
isFirst() 当前页是否是第一页
isLast() 当前页是否是最后一页
hasPrevious() 是否有上一页
hasNext() 是否有下一页1) Pageable 是 Spring Data 库中定义的一个接口,用于构造翻页查询,是所有分页相关信息的一个抽象,通过该接口,我们可以得到和分页相关所有信息(例如 pageNumber、pageSize 等),这样,Jpa 就能够通过 Pageable 参数来得到一个带分页信息的 Sql 语句。
2) Pageable 实现:PageRequest

3) Page 接口:用于储存查询的结果集
6、排序类:Sort

7、添加数据访问层的接口
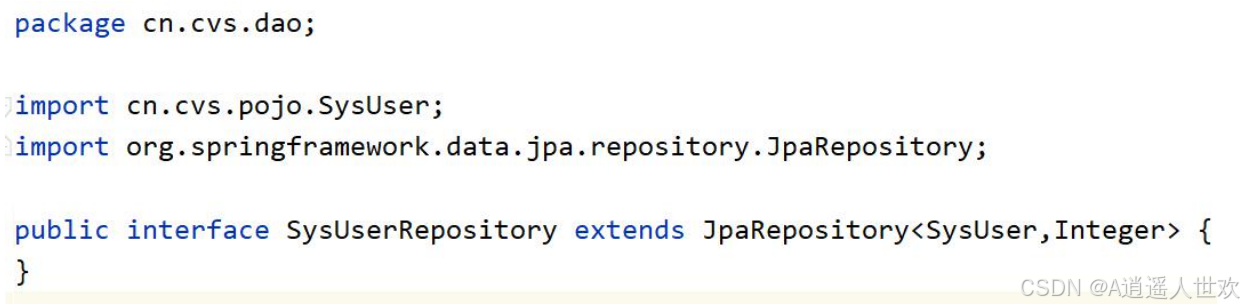
JPA 的查询方式
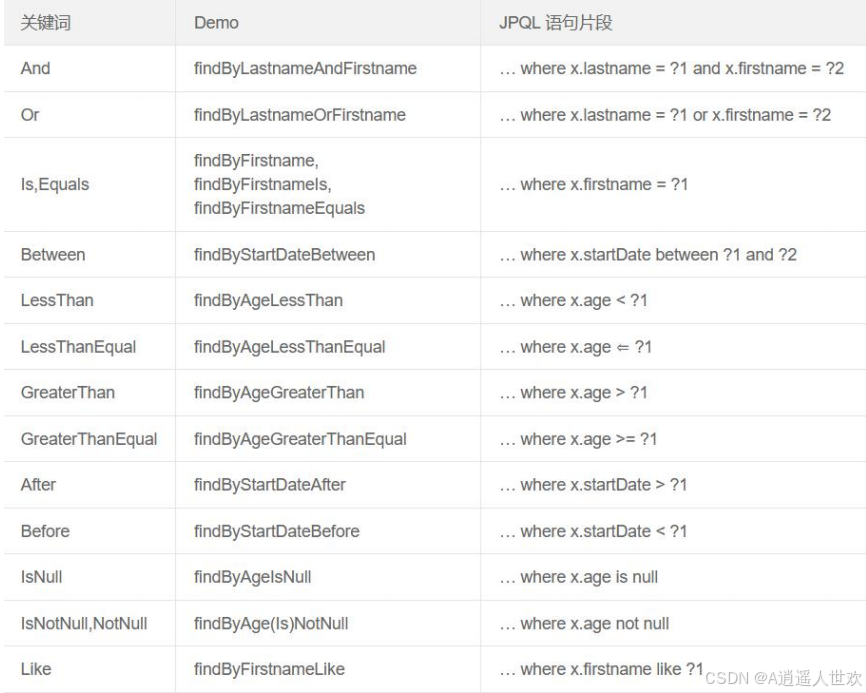
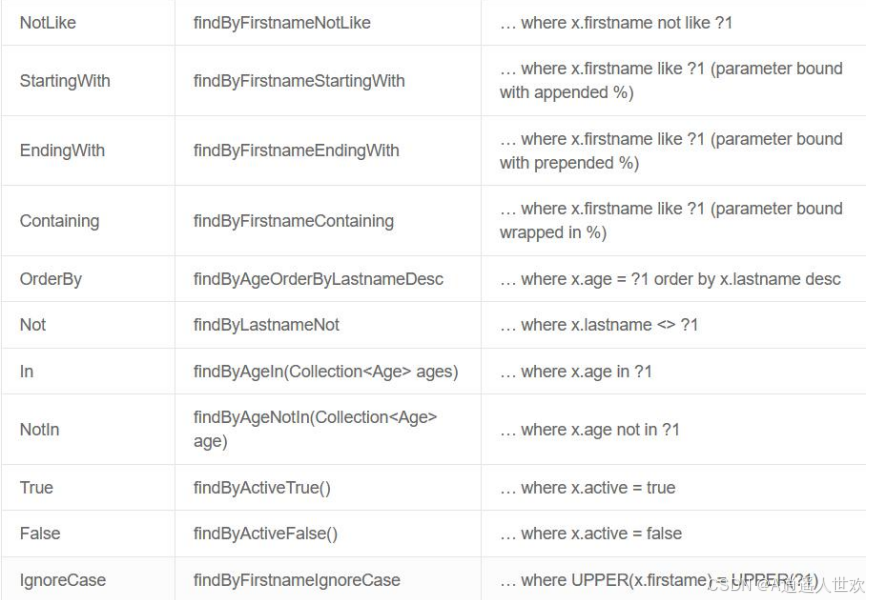
使用约定方法名
约定方法名一定要符合命名规范,Spring Data JPA 会根据前缀、 中间连接词(Or、And、Like、NotNull 等类似 SQL 中的关键词),内部拼接 SQL代理生成方法的实现。


使用 JPQL 查询
JPQL(Java Persistence Query Language),是一种和 SQL 非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的 SQL 语言, 从而屏蔽不同数据库之间的差异。
JPQL 和 SQL 很像,查询关键字都是一样的,唯一的区别是:JPQL 是面向对象的。JPQL 里面不能出现表名,列名,只能出现 java 的类名,属性名,并且区分大小写。不能使用 select *。
JPQL 通过 Query 接口封装执行,封装了执行数据库的查询的相关方法。

使用 ExampleMatcher 进行查询

使用原生 SQL 查询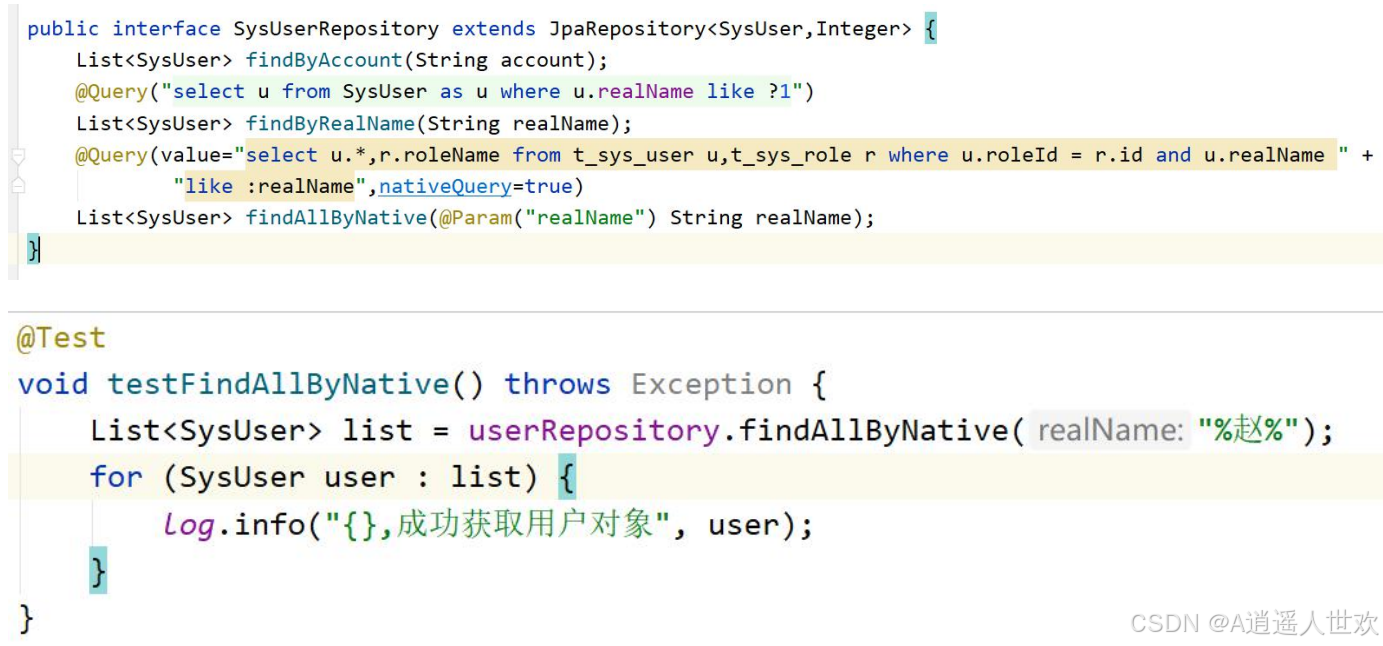
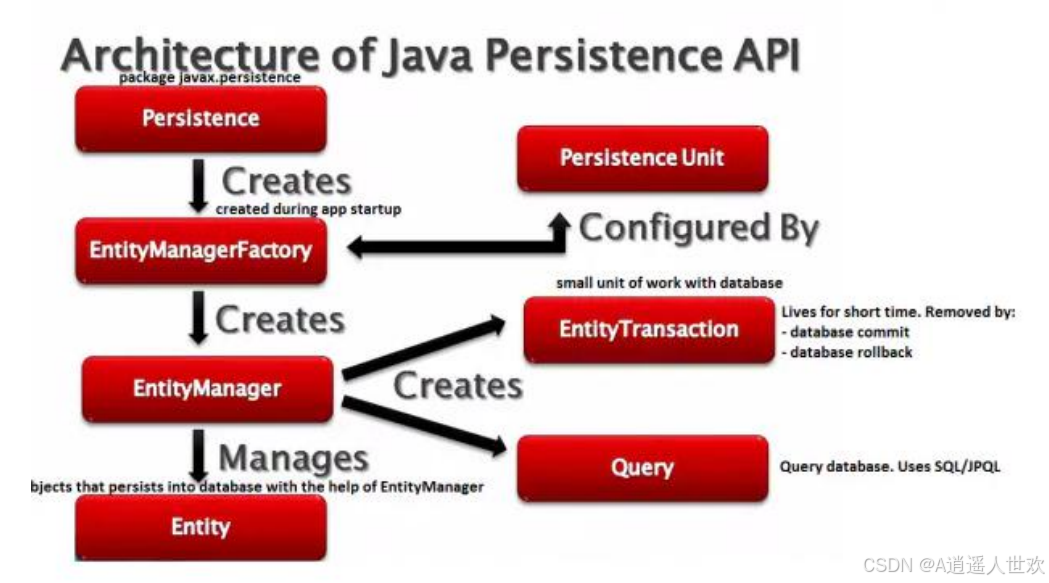
jpa类层次结构
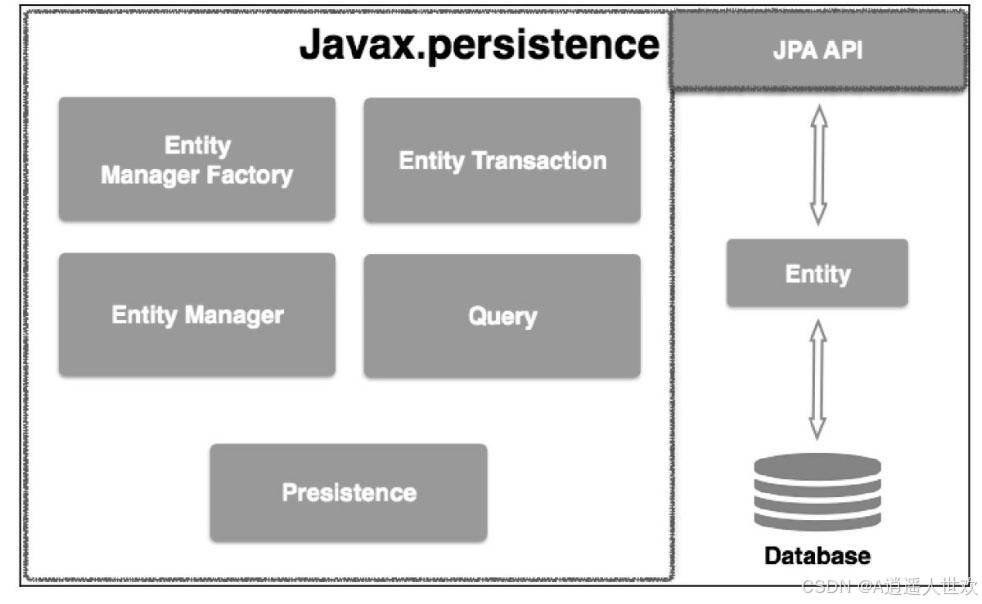
JPA类层次结构的显示单元
| 单元 | 描述 |
| EntityManagerFactory | 一个EntityManager的工厂类,创建并管理多个EntityManager实例 |
| EntityManager | 一个接口,管理持久化操作的对象,工厂原理类似工厂的查询实例 |
| Entity | 实体是持久性对象,是存储在数据库中的记录 |
| EntityTransaction | 与EntityManager是一对一的关系,对于每一个EntityManager的操作由EntityTransaction类维护 |
| Persistence | 这个类包含静态方法来获取EntityManagerFactory实例 |
| Query | 该接口由每个JPA供应商实现,能够获得符合标准的关系对象 |
JPA 的注解
基本注解
@Entity:标注用于实体类声明语句之前,指出该 Java 类为实体类,将映射到指定的数据库表。如声明一个实体类 User,将它映射到数据的 smbms_user 表上。
@Table:当实体类与其映射的数据库表名不同名时,需要使用@Table 标注说明,该注解与@Entity 标注并列使用,置于实体类声明语句之前。
1) @Table 注解的常用选项是 name,用于设置数据库的表名。
2) @Table 注解的可选项 catalog,用于设置数据库的目录。
3) @Table 注解的可选项 schema,用于设置表所属的模式。

4) @Table 注解的可选项 uniqueConstraints,用于设置约束条件。
主键
自动主键
默认情况下,主键是一个连续的64位数字(long),它由ObjectDB自动为存储在数据库中的每个新实体对象自动设置。
数据库中的第一个实体对象的主键是1,第二个实体对象的主键是2等等。
当从数据库中删除实体对象时,主键值不会被回收。
一个实体的主键值可以通过声明一个主键字段来访问:
@Entity
public class Project {
@Id
@GeneratedValue
long id; // still set automatically
}@id标注将字段标记为一个主键字段。当定义主键字段时,主键值将被ObjectDB自动注入到该字段中。
@GeneratedValue注释指定主键是由ObjectDB自动分配的
@GeneratedValue注解有两个属性,分别是strategy和generator
generator属性:
generator属性的值是一个字符串,默认为"",其声明了主键生成器的名称
(对应于同名的主键生成器@SequenceGenerator和@TableGenerator)。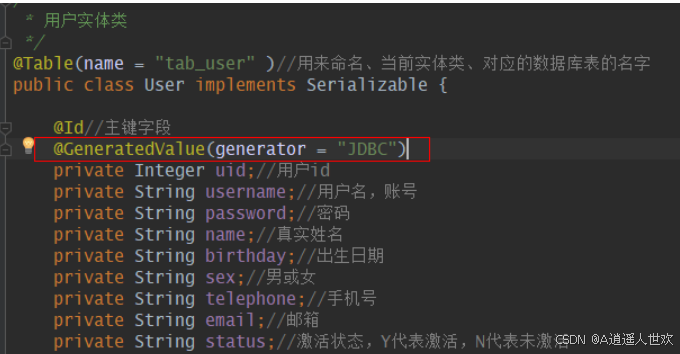
strategy属性:提供四种值:
-AUTO主键由程序控制, 是默认选项 ,不设置就是这个
-IDENTITY 主键由数据库生成, 采用数据库自增长, Oracle不支持这种方式
-SEQUENCE 通过数据库的序列产生主键, MYSQL 不支持
-Table 提供特定的数据库产生主键, 该方式更有利于数据库的移植应用设置主键
如果一个实体有一个没有@generatedvalue标记的主键字段,则不会生成自动主键值,并且应用程序负责通过初始化主键字段来设置主键。这必须在持久化实体对象的任何尝试之前完成。
@Entity
public class Project {
@Id
long id; // must be initialized by the application
}应用程序设置的主键字段可以有以下类型:
原始类型: boolean, byte, short, char, int, long, float, double.
java.lang包中的包装类型:Byte, Short, Character, Integer, Long, Float, Double.
java.math.BigInteger, java.math.BigDecimal.
java.lang.String.
java.util.Date, java.sql.Date, java.sql.Time, java.sql.Timestamp.
枚举类型
引用一个实体对象
复合主键
复合主键由多个主键字段组成。每个主键字段必须是上面列出的支持类型之一。
例如,以下项目实体类的主键由两个字段组成:
@Entity @IdClass(ProjectId.class)
public class Project {
@Id
int departmentId;
@Id
long projectId;
}当一个实体有多个主键字段时,JPA需要定义一个特殊的ID类,该类是使用@idclass注释附加到实体类的。ID类反映了主键字段,它的对象可以表示主键值:
Class ProjectId {
int departmentId;
long projectId;
}ObjectDB不强制定义ID类。但是,如果实体对象必须按照检索实体部分中所示的主键来检索实体对象,那么就需要ID类
嵌入式主键
表示复合主键的另一种方法是使用可嵌入的类:
@Entity
public class Project {
@EmbeddedId ProjectId id;
}
@Embeddable
Class ProjectId {
int departmentId;
long projectId;
}主键字段是在可嵌入类中定义的。
该实体包含一个单独的主键字段,该字段用@EmbeddedId 注释,并包含一个可嵌入类的实例。
当使用这个表单时,没有定义一个单独的ID类,因为可嵌入的类本身可以表示完整的主键值。
@EmbeddedId和@IdClass的区别
@idClass
使复合主键类成为非嵌入类,使用 @IdClass 批注为实体指定一个复合主键类(通常由两个或更多基元类型或 JDK 对象类型组成)。从原有数据库映射时(此时数据库键由多列组成),通常将出现复合主键。
复合主键类具有下列特征:
它是一个普通的旧式 Java 对象 (POJO) 类。
它必须为 public,并且必须有一个 public 无参数构造函数。
如果使用基于属性的访问,则主键类的属性必须为 public 或 protected。
它必须是可序列化的。
它必须定义 equals 和 hashCode 方法。
这些方法的值相等性的语义必须与键映射到的数据库类型的数据库相等性一致。
它的字段或属性的类型和名称必须与使用 @Id 进行批注的实体主键字段或属性的类型和名称相对应。
@EmbeddedId
使复合主键类成为由实体拥有的嵌入类
使用 @EmbeddedId 批注指定一个由实体拥有的可嵌入复合主键类(通常由两个或更多基元类型或 JDK 对象类型组成)。从原有数据库映射时(此时数据库键由多列组成),通常将出现复合主键。
复合主键类具有下列特征:
它是一个普通的旧式 Java 对象 (POJO) 类。
它必须为 public,并且必须有一个 public 无参数构造函数。
如果使用基于属性的访问,则主键类的属性必须为 public 或 protected。
它必须是可序列化的。
它必须定义 equals 和 hashCode 方法。
这些方法的值相等性的语义必须与键映射到的数据库类型的数据库相等性一致。
当实体的属性与其映射的数据库表的列不同名时需要使用@Column 标注说明,该属性通常置于实体的属性声明语句之前(置于属性的getter方法之前),还可与 @Id 标注一起使用。
@Column
@Column(insertable = false,updatable = false)
@Column 标注的常用属性是 name,用于设置映射数据库表的列名。此外,该标注还包含其它多个属性,如:unique 、nullable、length 等。
unique表示该字段是否为唯一标识,默认为false。如果表中有一个字段需要唯一标识,则既可以使用该标记,也可以使用@Table标记中的@UniqueConstraint。
nullable表示该字段是否可以为null值,默认为true。
insertable 表示在使用“INSERT”脚本插入数据时,是否需要插入该字段的值。
updatable表示在使用“UPDATE”脚本插入数据时,是否需要更新该字段的值。insertable和updatable属性一般多用于只读的属性,例如主键和外键等。这些字段的值通常是自动生成的。
columnDefinition(大多数情况,几乎不用)表示创建表时,该字段创建的SQL语句,一般用于通过Entity生成表定义时使用。(也就是说,如果DB中表已经建好,该属性没有必要使用。)
table表示当映射多个表时,指定表的表中的字段。默认值为主表的表名。
length表示字段的长度,当字段的类型为varchar时,该属性才有效,默认为255个字符。
precision和scale precision属性和scale属性表示精度,当字段类型为double时,precision表示数值的总长度,scale表示小数点所占的位数。
-name 定义了被标注字段在数据库表中所对应字段的名称;
@Basic表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为
@Basic fetch: 表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主支抓取和延迟加载,默认为 EAGER.
optional:表示该属性是否允许为null, 默认为true
@Transient并非一个到数据库表的字段的映射,表示非持久化属性
关联关系注解
*如何确定单向与双向关联?
在实际开发中,是采用单向关联还是双向关联,要看具体的业务需求,如果业务只需要在获取一方的实体时获取另一方的实体,而不是两边都能获取,那就采用单向关联。反之,如果需要在两边的实体中都能获取到对方,就使用双向关联。
@OneToOne一对一
双向关联,每一方都能获取到对方的实体
CREATE TABLE `person` (
`id` varchar(255) NOT NULL,
`pname` varchar(255) DEFAULT NULL,
`idcard` varchar(255),(外键)
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `idcard` (
`id` varchar(255) NOT NULL,
`cardnum` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;@Entity
@Table(name="person")
public class Person {
@Id
@GenericGenerator(name="uuidGenerator", strategy="uuid")
@GeneratedValue(generator="uuidGenerator")
private String id;
@Column(name="pname")
private String pname;
@OneToOne(cascade=CascadeType.ALL)
@JoinColumn(name="idcard")
private IdCard card;
}@Entity
@Table(name="idcard")
public class IdCard {
@Id
@GenericGenerator(name="uuidGenerator", strategy="uuid")
@GeneratedValue(generator="uuidGenerator")
private String id;
@Column(name="cardNum")
private String cardNum;
@OneToOne
@mappedBy(name="card")
private Person person;
}@OneToMany一对多单向关联
@JoinColumn指明该属性所关联的外键。
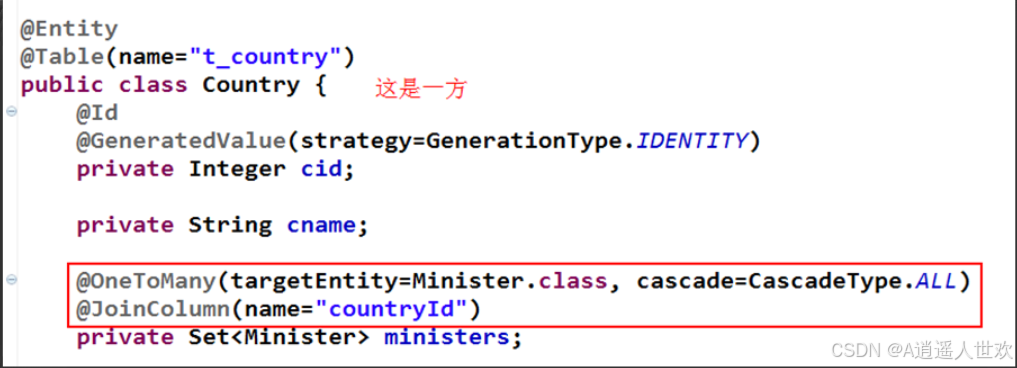
targetEntity:指明该属性所关联的类。
cascade:指定级联类型。其为数组,使用多种级联,则可使用{ }赋值。其值为Cascade常量:
对于一对多单向关联关系的多方,由于其不具备维护关联关系的能力,即没有一方对象作为属性,所以这里是不用设置关联相关的注解的。
关系的维护分为两类:
级联Cascade,在操作一方时,是否对另一方也执行同样的操作。
外键的维护inverse,在操作一方时,是否自动维护外键关系。比如如果将 多方的对象添加给以一的一方,因为外键由多方维护,hibernate为了保证添加的这个多方对象的外键是正确的,会自动给这个多方的外键设置值(也就是一的一方的主键)
外键维护,在xml配置中使用inverse属性,在注解中使用mappedBy注解来声明。
cascade与inverse
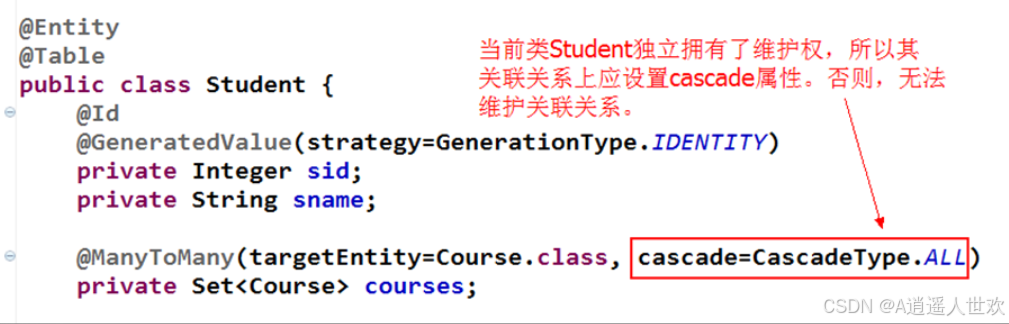
1.cascade,指把对当前对象的操作 级联到 关联对象上。
一般在one to one ,one to many设置级联。
配置了这个属性后,当对当前对象执行如save等更新数据库的操作时,当前实体所关联的实体也会执行相应的操作。
2.inverse
默认值为true, 表示让对方来维护关系。设为false,自己维护关系。
inverse主要有两个作用:
1)维护外键
主控方保存时,是否自动update被控方的外键字段。外键字段指向的就是当前保存的实体。
2)维护级联
决定当前设置的级联是否有用,自己维护关系时,对方设置的级联就不会生效,对方保存时不会让本方也保存。而对方维护关系,则与此相反。一对多双向关联
这其中增加了mappedBy属性。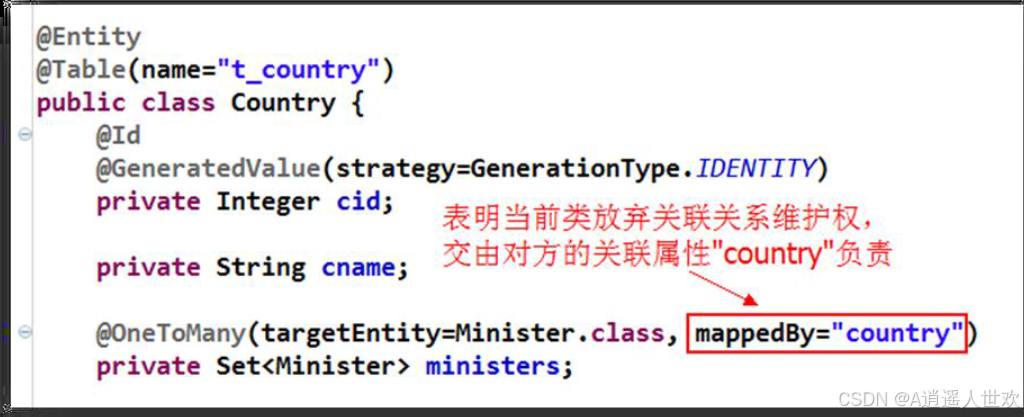
mappedBy属性用法:
该属性与关联关系的维护权相关。
该属性应放在放弃维护权一方。
该属性值为对方的关联属性,表明以后的关联关系将由它来负责。
使用该属性的注解,无需也不能再设置cascade属性。
该属性只可能在双向关联中使用。
使用了该属性,将不能再使用@JoinColumn注解。因为@JoinColumn注解表示其所注解的属性将来通过set方法设值后,会与DB中哪个字段相关联。
mappedBy属性表示当前注解的关联属性放弃了维护权,即使执行了set方法将值设置入,其也不会写入到DB中。
也正因为放弃了维护权,与DB无关了,所以设置了mappedBy属性的注解,再设置cascade也就无意义了。
一个是使被注解者与DB相关,一个是使被注解者放弃与DB的关系,它们是相互矛盾的
@mappedBy注解
1)mappedBy(name="对方标准代表当前实体的属性“)
2)只存在于OneToOne,OneToMany,ManyToMany, 不能在ManyToOne中
3)与joincolumn或jointable互斥。因为joincolumn在拥有方声明了被拥有方,而mappedby定义在被拥有方,指向拥有方。
4)一般拥有方为拥有外键的那一方,在一对多中是在多方。
有什么用:
让拥有方来自动维护与当前实体的关系。与inverse对应。inverse=true
在注解中没有设置mappedBy时,默认双方都维护关系,就如inverse。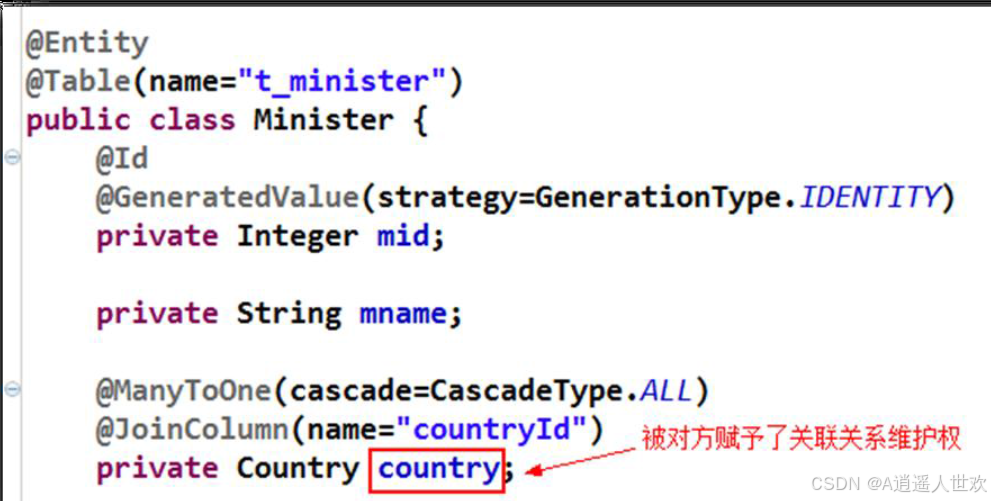 自关联
自关联
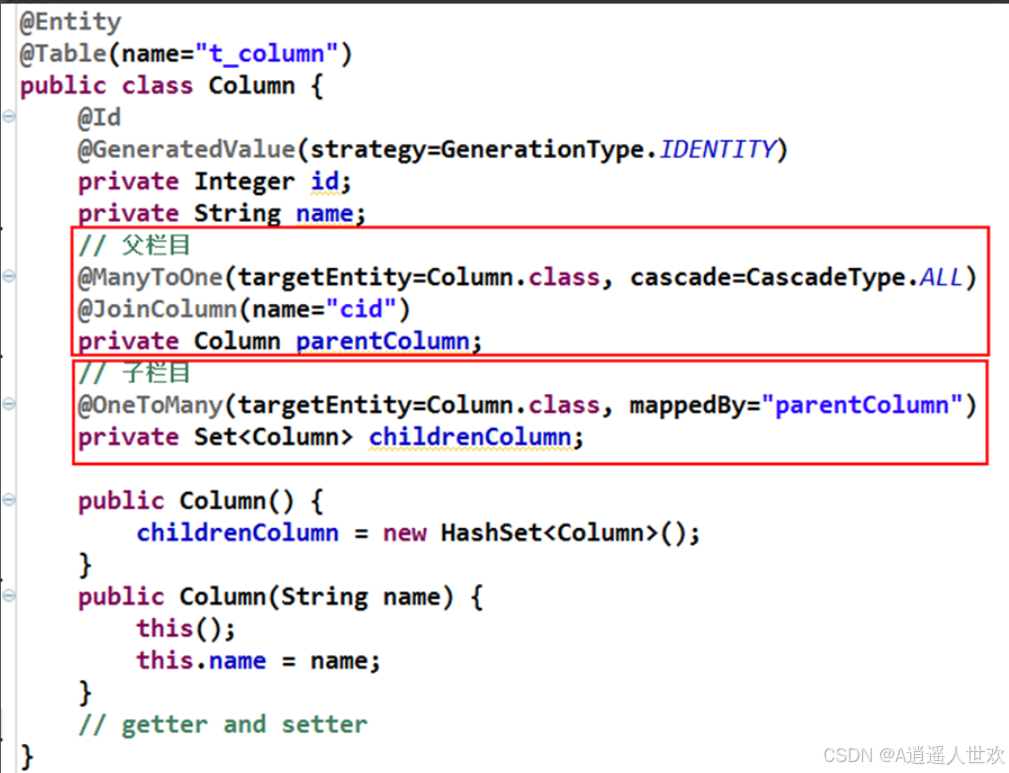
@ManyToOne多对一单向关联
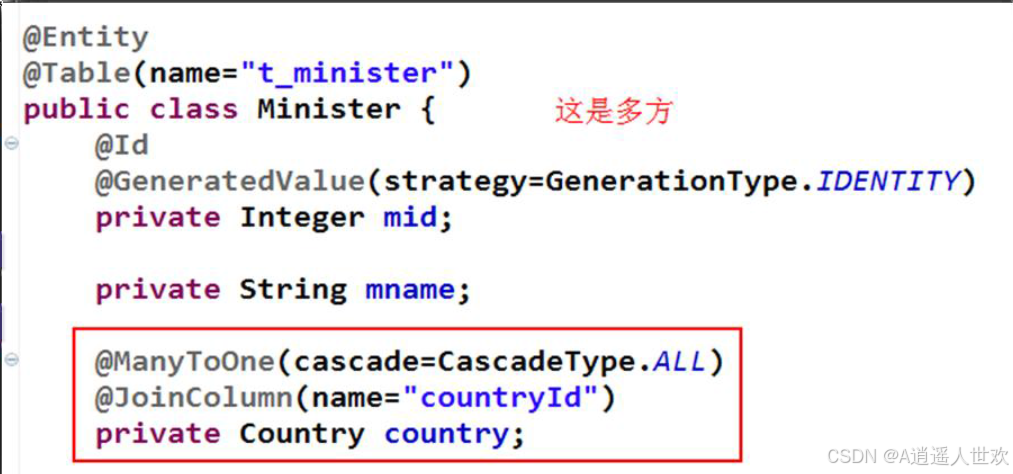
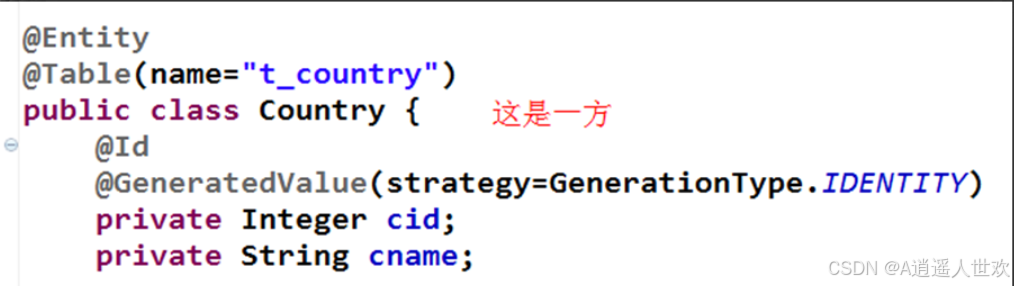
@ManyToMany多对多单向关联
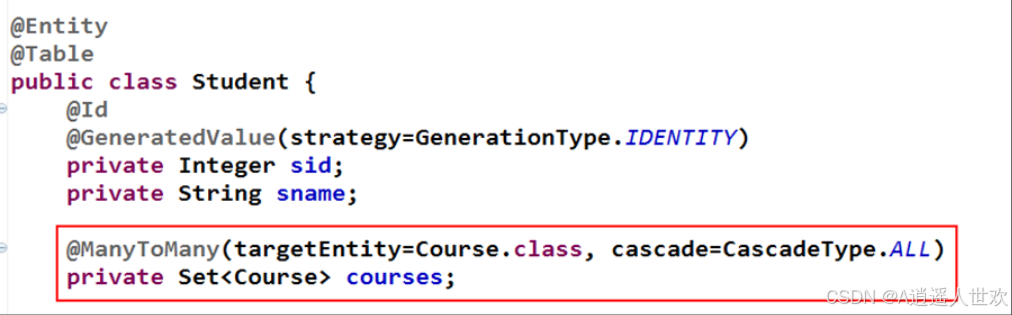
多对多关联使用@ManyToMany注解。其会自动生成一个中间表,表名为两个关联对象的映射表名的联合:表1_表2。该表包含两个字段,字段名也与表名相关。字段名分别为:表1_id与表2_id。当然,默认的表名与字段名均可通过@JoinTable进行修改(不研究)。
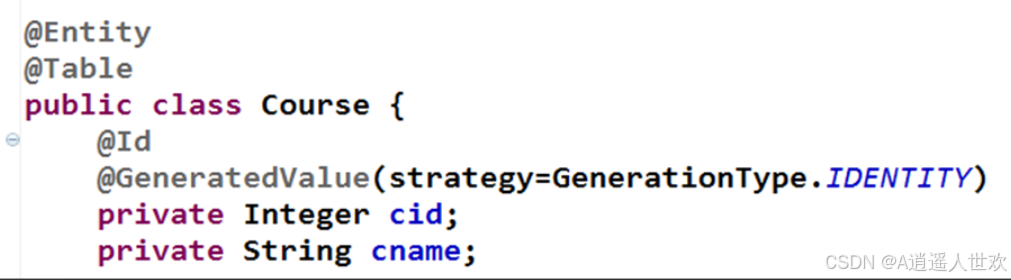
多对多双向关联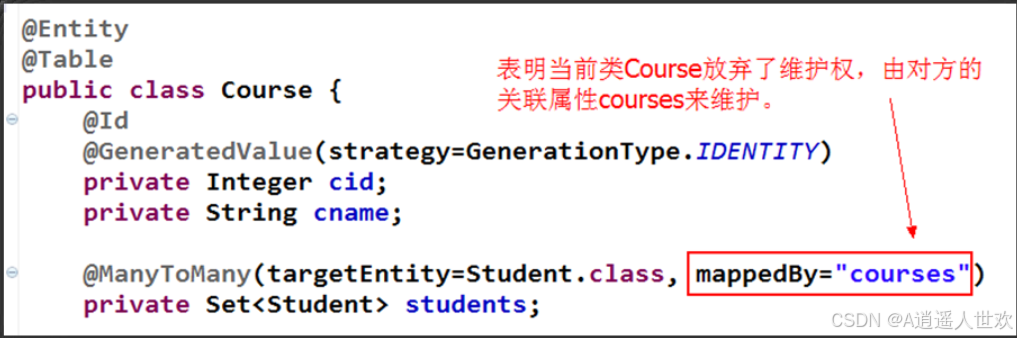

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









