






1 导言
UT 在过去六年中第五次赢得2016年RoboCup 3D模拟联赛冠军,并在2011年[1]、2012年[2]、2014年[3]和2015年[4]赢得比赛,同时在2013年获得第二名。在比赛过程中,该队攻入88球,在赢得14场比赛的过程中只丢了1球。2016年UT奥斯汀别墅代理的许多组件都是从该团队前几年成功参赛作品中重新使用的。这篇文章并不是对2016 UT奥斯丁别墅代理的完整描述,其基础是团队2011的总代理在团队技术报告(5)中充分描述的,而是集中在2016的帮助球队作为冠军重复的变化中。
除了赢得主要的RoboCup 3D模拟联盟比赛外,UT 还赢得了RoboCup 3D模拟联盟技术挑战赛,赢得了三项联盟挑战赛:自由、基帕韦和露台跑步挑战赛。本文还记录了这些挑战以及UT 在挑战中的竞争方法。
论文的其余部分组织如下。第2节介绍了三维仿真领域。第3节详细介绍了2016年UT奥斯汀别墅队的变化和改进(包括标记、开球、高度调整踢选择、间接踢套路和定向踢),第4节分析了这些变化对球队在比赛中整体表现的贡献。第5节描述并分析了用于确定技术挑战获胜者的联赛挑战,第6节总结
2 域描述
RoboCup 3D仿真环境基于SimSpark[6],一种通用的物理多智能体系统模拟器。SimSpark使用开放式动力学引擎(ODE)库对刚体动力学进行真实模拟,包括碰撞检测和摩擦。ODE还为仿人代理中使用的高级电动铰链关节建模提供支持。
比赛包括11对11的经纪人在30 X 20米的场地上踢两个5分钟的半场。模拟中的机器人代理以Aldebaran Nao机器人为模型,该机器人的高度约为57厘米,质量为4.5公斤。每个机器人有22个自由度:每条腿6个,每条手臂4个,脖子2个。为了监视和控制其铰链关节,代理配备了关节感知器和效应器。关节感知器在每个模拟周期(20 ms)为代理提供无噪声的角度测量,而关节效应器允许代理指定移动关节的速度/方向。
每三个模拟周期(60 ms),通过对受限视锥(120 ms)内物体的距离和角度的噪声测量,将有关环境的视觉信息提供给代理◦ ). 代理商还配备了噪音加速计和陀螺仪感应器,以及每个脚底的力阻感应器。此外,代理可以通过发送20字节的消息,每隔一个模拟周期(40毫秒)相互通信。
除了标准Nao机器人模型外,还可以使用标准模型的四个附加变体,即异构类型。标准模型的这些变化包括腿部和手臂长度、臀部宽度的变化,以及机器人脚上脚趾的增加。团队必须使用至少三种不同的机器人类型,任何一种机器人类型的代理不得超过七个,任何两种机器人类型的代理不得超过九个。
2016年RoboCup 3D模拟联赛的比赛与前一年的比赛相比有一些关键变化。第一个是规则的改变,当一名球员在边线出界前最后一次触球时,将先前的直接踢入判给对方球队(另一名球员必须触球才能进球)。这条规则的制定是为了鼓励传球和团队合作,并使踢腿规则更类似于人类足球中的间接踢腿规则。再加上这一规则的改变,以及与人类足球的比赛,如果一名球员连续两次触球(直接或间接),则对方队将获得间接踢。
RoboCup 3D模拟联赛的第二个变化是增加了一个自动裁判,用于判罚犯规。如果与对方球员发生碰撞时,球员的力量(对方球员方向上的速度分量)超过可调阈值,则球员被视为犯了冲锋犯规,并被发射到比赛场地外作为惩罚。如果一名球员最近触球,因此被视为向球扑去,或者如果两名球员同时向对方冲锋,则不要求对该球员进行冲锋。通过减少碰撞次数,同时更好地符合人类足球的规则,罚犯规可以提高比赛质量。
3 2016年的改变
人们注意到球队已经发展出了良好的踢球/传球能力,然后通过传球的套路比赛来开发这些能力,让队友在好的位置上踢球进球。
UT开发并使用了2016年RoboCup比赛的打分系统,以阻止和防守处于危险进攻位置的对手。
3.1 标记
UT小组实施的评分系统是一个包括以下三个步骤的连续过程:
- 标记哪些球员
- 选择哪些角色用于标记目的
- 使用优先的角色分配来分配玩家到位置
在第一步中,使用手工编码的启发式方法来决定哪些对手处于危险的进攻位置,并应加以标记。接下来,从团队默认的队形位置出发,利用Delaunay三角网从球上计算为偏移位置,选择一组队形位置,用标记所需要的位置代替。用匈牙利算法计算待替换的编队位置集合,即最小化标记位置与被标记位置替换的编队位置之间的距离之和。最后,优先级的角色分配是SCRAM角色分配的扩展,用于分配代理移动到团队期望的角色位置( 既为形成目的 ,也为标记目的 )。
3.2 开球
2015年,UT优化了可变距离踢球,使球在一米的增量内被踢出不同距离。这些踢球提供了传球的选择,因为机器人可以从许多潜在的目标中选择踢球。每个潜在的踢球位置根据公式1给定一个得分,选择得分最高的位置作为踢球的位置。方程1惩罚距离对手目标较远的踢球位置,惩罚使球落在对手附近的踢球,也奖励在队友附近落地的踢球。式1中所有距离均以米计测量。

理想的踢球位置是在球场上处于进攻和开放( 没有对手接近 )位置的队友附近接受传球和射门。对于新的2016年机器人足球世界杯比赛来说,相比于等待队友转播球被踢到的位置,然后才移动到该位置,如果一个在队形中承担中心前锋或前锋角色的机器人移动到计算其队友最接近球的位置,用方程1预期有可能将球踢到的位置。由于方程1给出了离对手较远的位置的更高值,这种行为导致前锋在场上动态移动到开放进攻位置,而不是先前的相对于球站在固定位置的行为- -可能靠近对手,这标志着球员- -等待接收球将可能会落到哪儿。
3.3 调整踢高选择
除了允许更精确的传球外,可变距离的踢球对于在进球时射门也是有用的。一般来说,一脚走的距离越大,球在射门时可能在空中走得越长越高,而且可能越过球门。在2015年的RoboCup比赛中,为了防止意外踢过门,对射门的脚踢仅限于距离球门线不超过7米的人。尽管这种试图限制射门时踢球的距离,但仍有不少射门在射门上方飞行而错过目标。
表1:当球高于球门高度时,不同踢型(不同距离的踢)的100次踢测得的最大向前距离。所有值均以米为单位。

在2016年的RoboCup比赛中,UT奥斯汀维拉队采取了更加校准的方法来防止射门超越目标。不用估计7米作为所有踢球类型的一个踢球距离与球能在高于球门高度的最大向前距离之间的差值,而是直接测量每一个踢球类型的100次踢球尝试中球的最大向前距离。表1显示了四种身体模型(标准Nao模型但添加了脚趾的模型)的代理人对不同踢球的测量结果。利用这些测量,在射门时,选择了不会飞越目标上方的最大功率的踢球——距离最大的踢球,但其前方的目标高度距离小于球与目标的距离。
从表1中的数据可以看出,一脚的距离与球能在目标高度以上的最大向前距离之间并不存在恒定的偏移差。此外,对于许多踢球类型来说,这种差异小于2015年比赛中使用的7米预估值,在去年的比赛中,射门超过了并不奇怪。
3.4 间接定位球
图1:踢入过程中定位球的间接踢形成。黄线代表潜在的通行证
向队形中的队友致意。

随着今年规则的改变( 第 2节概述 )使得间接踢球,并且双击球会导致对方球队的间接任意球,使用套路比赛来间接踢球变得切实可行。在间接踢球过程中,球队切换到如图1所示的阵型,其中3名球员在中途线附近的场上一行传球,另外3名球员在更前沿的进攻位置上一行传球。接球的球员,现在有更多的选项从队员传球到哪个队友,选择将球踢到最佳位置,如3.2节中方程1所决定。接球的球员在接球前还从间接球开始等待10秒钟,以便给其队友在间接球形成中移动到自己指定位置的时间。
3.5 定向踢
图2. 在a、b、c位置上踢球的可能方向(左图)。代理人用a在2016年机器人足球世界杯进球前,背对球射门180 ° "钩子"踢球的位置是球被拉向后,然后被踢到球员后面(右图)。

为2011年的比赛创造了包含逆运动学的定向踢,但由于性能不佳,后来停止使用,重新引入并利用重叠分层学习将其集成到具有4型身体模型( 标准的 Nao模型 ,但添加了脚趾 )的智能体中。与标准前踢不同的是,代理人必须花时间在球后排成要被踢的方向,定向踢允许代理人从多个角度和相对球位快速接近并踢球( 实例球位置和踢球方向如图 2所示 )。
4 主要比赛结果及分析
在赢得2016年机器人杯比赛时,UT以14胜零负的完美记录结束了比赛。在比赛中,该队进了88球,只丢了1球。尽管以完美的记录结束比赛,但比赛中相对较少的比赛数量,再加上RoboCup 3D模拟器的复杂和随机环境,使得很难确定UT队在统计上明显优于其他球队。然而,在比赛结束时,所有团队都被要求发布他们在比赛中使用的二进制文件。UT 与其他八支球队在比赛中发布的二进制文件进行1000场比赛的结果如表2所示。
表2:UT发布的二进制文件在2016年RoboCup上与所有其他球队发布的二进制文件进行1000场比赛时的表现。这包括排名(a队在2016年比赛中取得的排名)、平均目标差(括号中的值为标准误差)、胜负平局记录以及支持/反对的目标。
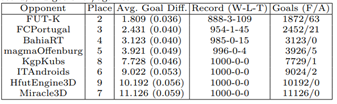
UT在与每个对手的比赛中,平均进球数相差至少超过1.8个。此外,UT在表2中的8000场比赛中只输了4场,对所有球队的胜利率超过88%。这表明UT赢得2016年比赛绝非偶然。下面的小节分析了第3节中描述的一些组成部分,这些组成部分有助于团队的主导绩效。
4.1 部件分析
表3:UT队在2016年RoboCup上与前三名球队进行1000场比赛时,在有无得分的情况下取得的平均球差和进球数(括号内为进球数与得分的抵消球数的百分比)。

在转向标记(第3.1节)的UT团队版本和2016年RoboCup团队发布的每个二进制文件之间进行了1000场比赛。只有比赛前三名的球队在没有得分的情况下,与得分相同的球队相比,得分数有明显差异(没有其他球队在没有得分的情况下得分超过6个)。与前三名球队的比赛结果如表3所示。对所有三支球队,在不使用记分的情况下,平均得分差距都会下降。此外,对手的进球数和在比赛中进球的百分比在没有得分的情况下急剧增加。这些结果表明,盯人防守有很大的提高,而且在防守定位球时非常有效。
表4:UT队在2016年RoboCup上与所有球队进行9000场比赛(每名对手1000场比赛)时,不同版本的UT队取得的平均进球差异。

UTAustinVilla 发布了二进制文件(无定向踢)。
NoGettingOpen 分配给前锋角色的代理不尝试打开。
NoKickHeightTuning 射门时,踢腿选择未调整高度。
NoIndirectKickSetPlays 没有间接踢。
DirectionalKicks使用定向踢。
由于删除表4中的大多数组成部分减少了平均目标差异,这些组成部分对团队是有益的。让被分配到前锋角色的球员开球(第3.2节)稍微提高了表现,并将对所有对手的平均进球数从5.476增加到5.526。根据身高(第3.3节)调整投篮时选择哪种踢腿也会增加平均目标差。这种改进很可能是由于不再将球踢过球门,因为对所有对手的平均投篮得分百分比从未调整的29.69%增加到了踢高调整的32.05%:以适当的力量踢球,使球飞入球门但不越过球门的能力是一项宝贵的技能在比赛期间。虽然使用间接踢套路(第3.4节)时,平均球差仅略有增加,但使用套路时,间接踢的平均得分百分比从27.10%上升到34.78%。
唯一影响表现的变化是使用定向踢。据了解,在比赛期间,选择用定向踢传球,而不是用较长的一脚射门会降低表现,因此在半决赛和决赛中,定向踢被禁用。然而,定向踢确实将比赛中的平均传球尝试次数从13.020次增加到15.838次,并将平均控球时间(队友比任何对手离球都近)百分比从56.71%提高到59.81%。如果球队的守门员行为有所改善,在选择何时射门时需要更具选择性,那么定向踢可能会变得更有用。
4.2 附加锦标赛竞争分析
表5:2016年RoboCup上与所有其他团队发布的二进制文件进行1000场比赛时,各团队的平均目标差异(行)(列)。球队在赢球(正目标差)和输球(负目标差)方面的优势从大到小依次排列。
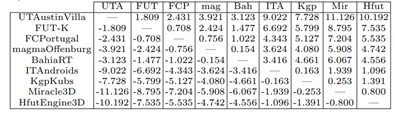
为了进一步分析锦标赛竞争,表5显示了2016年RoboCup与所有其他球队进行1000场比赛时,各球队在RoboCup上的平均进球差异。值得注意的是,团队在赢(正目标差)和输(负目标差)方面的顺序严格控制着团队赢的每个对手,也会输给击败同一团队的每个对手。然而,相对目标差并没有这种相同的属性,因为相对于另一支球队而言,一支球队在对抗一个对手时表现更好,但相对于同一支球队而言,对抗另一个对手时并不总是表现更好。然而,就相对进球差异而言,UT占据主导地位,因为UT对每个对手的进球差异高于所有其他球队对同一对手的进球差异。
5 Technical Challenges
5.1 Free Challenge
- 团队就与团队相关的研究主题进行五分钟的演示。然后,联盟中的每一支球队将前五名的表现进行排名,其中最佳的获得5票,第五名获得1票。
- 联盟之外的RoboCup社区的几位受人尊敬的成员进行了投票,他们的选票被计算为两倍。
- 获胜者是获得最多选票的球队
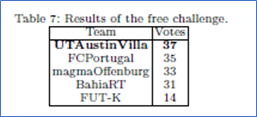
- The FC Portugal team介绍了一种学习算法,学习参数化踢球从而将球踢到不同的距离。而且这个算法运行机器人和球处于不同的相对位置。
- The magmaOffenburg team介绍了在(raw actuator space)原始执行器中学习踢腿
- The BahiaRT team 讨论了对现有的防御系统的延申
- The FUT-K team 介绍了他们防止对手长传的方法。
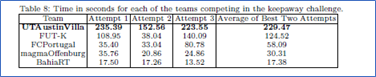
4.2 Keepaway Challenge
- 三名代理试图控球并且将球尽可能远离另外的一个对手代理
- 球必须保持在场地上一个慢慢缩小的正方形区域内,五分钟后,这个区域最终会缩小到零。
- 如果对手代理接触当球或球离开场地上允许的区域时,keepaway结束,时间就是分数
Keepaway挑战三角形(左图)和正方形(右图)的队形。红色的盒子是keepaway区域。黄线表示下一个传球的位置。蓝线显示使用第二级踢预期的代理移动(一旦传球发生,移动到队形中的新位置)。
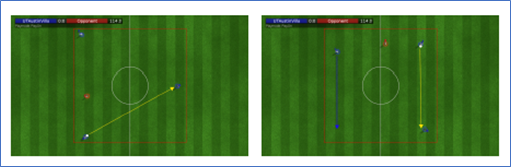
- UT Austin Villa创建了两个阵型,用于图所示的keepaway挑战赛。在第一个队形中,代理将自己排列成三角形。球上的代理等待对手靠近,然后该代理将球传给从球上测量的对手和队友之间的角度最大的队友(球传给对手截获传球机会最小的队友)。在第二个阵型中,代理们呈正方形,队友可以在90°方向的位置上接到球。三角形队形和正方形队形采用相同的传球策略。
- 但是,除此之外,踢球预期被扩展到第二级——球员预计并从球员踢球时广播下一(第一)传球的位置跑向第二传球的位置,以便队友在传球后处于指定的队形位置。在keepaway尝试开始时随机选择要使用的队形。
5.3 Gazebo Running Challenge
- 这个比赛是robcup为了Gazebo机器人模拟器开发了一款plugin(插件)
- 在Gazebo模拟器中,要求在20秒中尽可能快的走而且不跌倒。
- UT使用CMA-ES算法并优化了快走参数,
每个参赛团队进行了五次跑步尝试,并根据平均的走路速度来打分。UT 以超过1米/秒的速度赢得了挑战。UT 的每一次跑步速度都高于所有其他球队的速度。

6 结论
UT赢得了2016年RoboCup 3D模拟联盟主要比赛以及所有技术联盟挑战赛。8使用比赛中发布的二进制文件获取的数据显示,UT 在比赛中获胜具有统计学意义。2016年UT奥斯汀维拉队在1000场比赛中以平均0.561(+/-0.029)个进球击败了2015年球队的冠军二人组,比2015年有了显著的进步。
为了使新团队更容易加入RoboCup 3D模拟联盟,同时也为现有团队提供有益的资源,UT 团队已经发布了他们的基本代码[18]。9该代码版本为RoboCup 3D模拟联盟的新团队提供了一个功能齐全的代理和良好的起点(新KgpKubs团队在2016年的比赛中使用了该代码)。此外,获得2016年RoboCup HARTING开源奖第二名的代码发布为开展多领域研究提供了一个基础平台,包括机器人技术、多智能体系统和机器学习。
致谢
This work has taken place in the Learning Agents Research Group (LARG) at UT Austin. LARG research in 2016 is supported in part by grants from NSF (CNS-1330072, CNS-1305287), ONR (21C184-01), and AFOSR (FA9550-14-1-0087). Peter Stone serves on the Board of Directors of Cogitai, Inc. The terms of this arrangement have been reviewed and approved by UT Austin in accordance with its policy on objectivity in research.
References
- MacAlpine, P., Urieli, D., Barrett, S., Kalyanakrishnan, S., Barrera, F., LopezMobilia, A., S¸tiurc˘a, N., Vu, V., Stone, P.: UT Austin Villa 2011: A champion agent in the RoboCup 3D soccer simulation competition. In: Proc. of 11th Int. Conf. on Autonomous Agents and Multiagent Systems (AAMAS 2012). (2012)
- MacAlpine, P., Collins, N., Lopez-Mobilia, A., Stone, P.: UT Austin Villa: RoboCup 2012 3D simulation league champion. In: RoboCup-2012: Robot Soccer World Cup XVI. LNAI. Springer (2013)
- MacAlpine, P., Depinet, M., Liang, J., Stone, P.: UT Austin Villa: RoboCup
2014 3D simulation league competition and technical challenge champions. In: RoboCup-2014: Robot Soccer World Cup XVIII. LNAI. Springer (2015) - MacAlpine, P., Hanna, J., Liang, J., Stone, P.: UT Austin Villa: RoboCup 2015 3D simulation league competition and technical challenges champions. In: RoboCup2015: Robot Soccer World Cup XIX. LNAI. Springer (2016)
- MacAlpine, P., Urieli, D., Barrett, S., Kalyanakrishnan, S., Barrera, F., LopezMobilia, A., S¸tiurc˘a, N., Vu, V., Stone, P.: UT Austin Villa 2011 3D Simulation Team report. Technical Report AI11-10, The Univ. of Texas at Austin, Dept. of Computer Science, AI Laboratory (2011)
- Boedecker, J., Asada, M.: Simspark–concepts and application in the robocup 3d soccer simulation league. In: SIMPAR-2008 Workshop on the Universe of RoboCup Simulators. (2008) 174–181
- MacAlpine, P., Price, E., Stone, P.: SCRAM: Scalable collision-avoiding role assignment with minimal-makespan for formational positioning. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI-15). (2015)
- MacAlpine, P., Depinet, M., Stone, P.: UT Austin Villa 2014: RoboCup 3D simulation league champion via overlapping layered learning. In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI-15). (2015)
- Akiyama, H., Noda, I.: Multi-agent positioning mechanism in the dynamic environment. In: RoboCup 2007: Robot Soccer World Cup XI. LNAI. Springer (2008)
- Kuhn, H.W.: The hungarian method for the assignment problem. Naval Research Logistics Quarterly 2 (1955) 83–97
- MacAlpine, P., Stone, P.: Prioritized role assignment for marking. In: RoboCup 2016: Robot Soccer World Cup XX. LNAI. Springer (2016)
- Abdolmaleki, A., Simoes, D., Lau, N., Reis, L.P., Neumann, G.: Learning a humanoid kick with controlled distance. In: RoboCup 2016: Robot Soccer World Cup XX. LNAI. Springer (2016)
- Dorer, K., Kurz, V.: Learning a kick while walking in raw actuator space. (2016)
- da Silva, C., Soares, A., Argollo, E., Sim˜oes, M.A.C., Frias, D., de Souza, J.R.: M´odulo cooperativo de defesa para um time de futebol de agentes humanoides
autˆonomos. In: XIII Workshop de Trabalhos de Inicia¸c˜ao Cient´ıfica e Gradua¸c˜ao da Escola Regional de Computa¸c˜ao Bahia - Alagoas - Sergipe. (2015) - Koenig, N., Howard, A.: Design and use paradigms for gazebo, an open-source multi-robot simulator. In: Intelligent Robots and Systems (IROS). (2004)
- MacAlpine, P., Barrett, S., Urieli, D., Vu, V., Stone, P.: Design and optimization of an omnidirectional humanoid walk: A winning approach at the RoboCup 2011
3D simulation competition. In: Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence (AAAI-12). (2012) - Hansen, N.: The CMA Evolution Strategy: A Tutorial. (2009) http://www.lri.fr/~hansen/cmatutorial.pdf.
- MacAlpine, P., Stone, P.: UT Austin Villa robocup 3D simulation base code release. In: RoboCup 2016: Robot Soccer World Cup XX. LNAI. Springer (2016)















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









