







软件安装就不多bb了,这边用的小皮
官网:https://old.xp.cn/
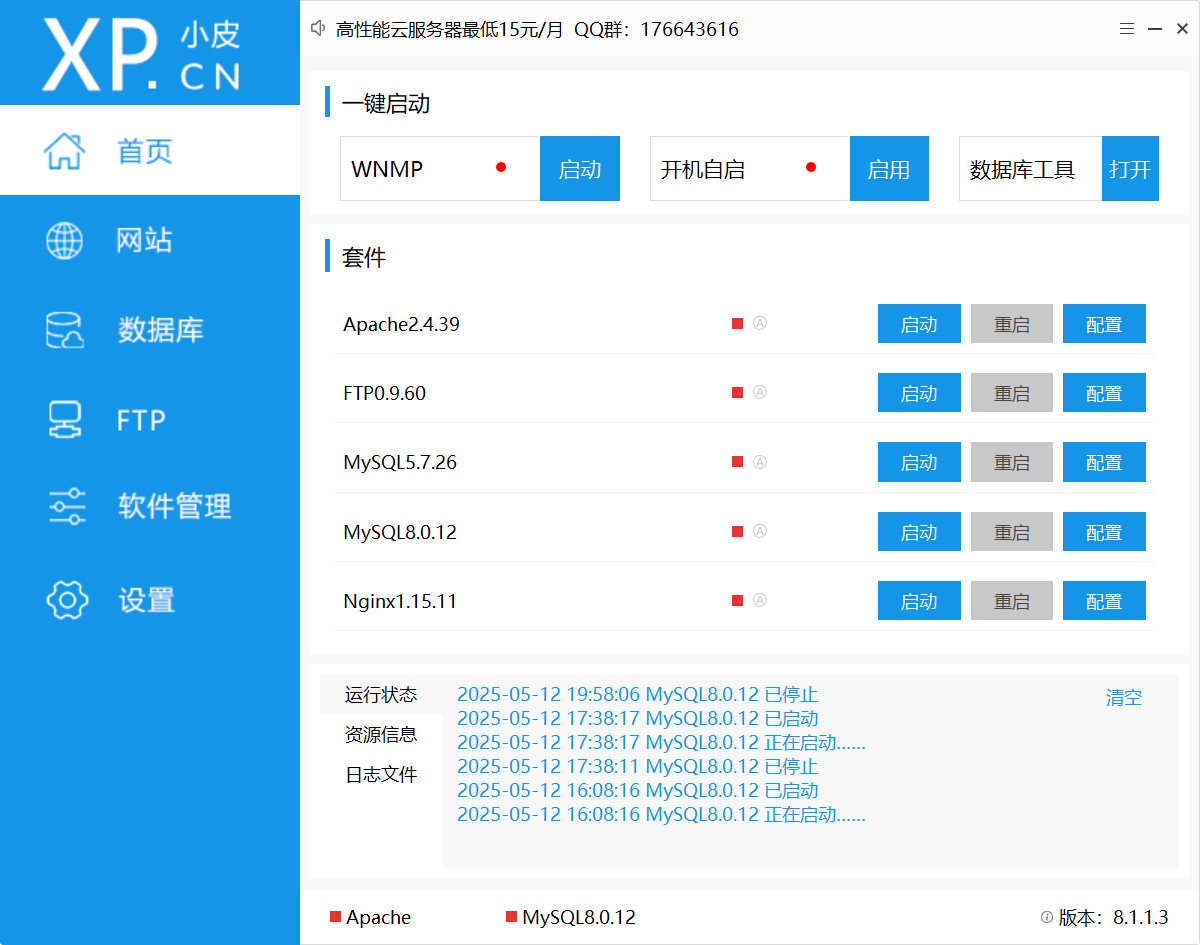
MySQL链接方式
命令连接:了解即可、linux用的多,Python开发用得少
登录:
方式1: mysql -u用户名 -p密码
方式2: mysql -u用户名 -p 回车后再输入密码
方式3: mysql -h主机地址 -p 回车后再输入密码
注意: localhost默认代表本地主机,或者127.0.0.1也代表本机
登出:
方式1: exit
方式2: quit
方式3: \q
注意: 在mac/linux中使用ctrl+d/ctrl+c也能退出
查看ip地址
window: ipconfig
mac/linux: ifconfig工具连接
目前我用的是pycharm2023.2专业版已经自动集成了database tools
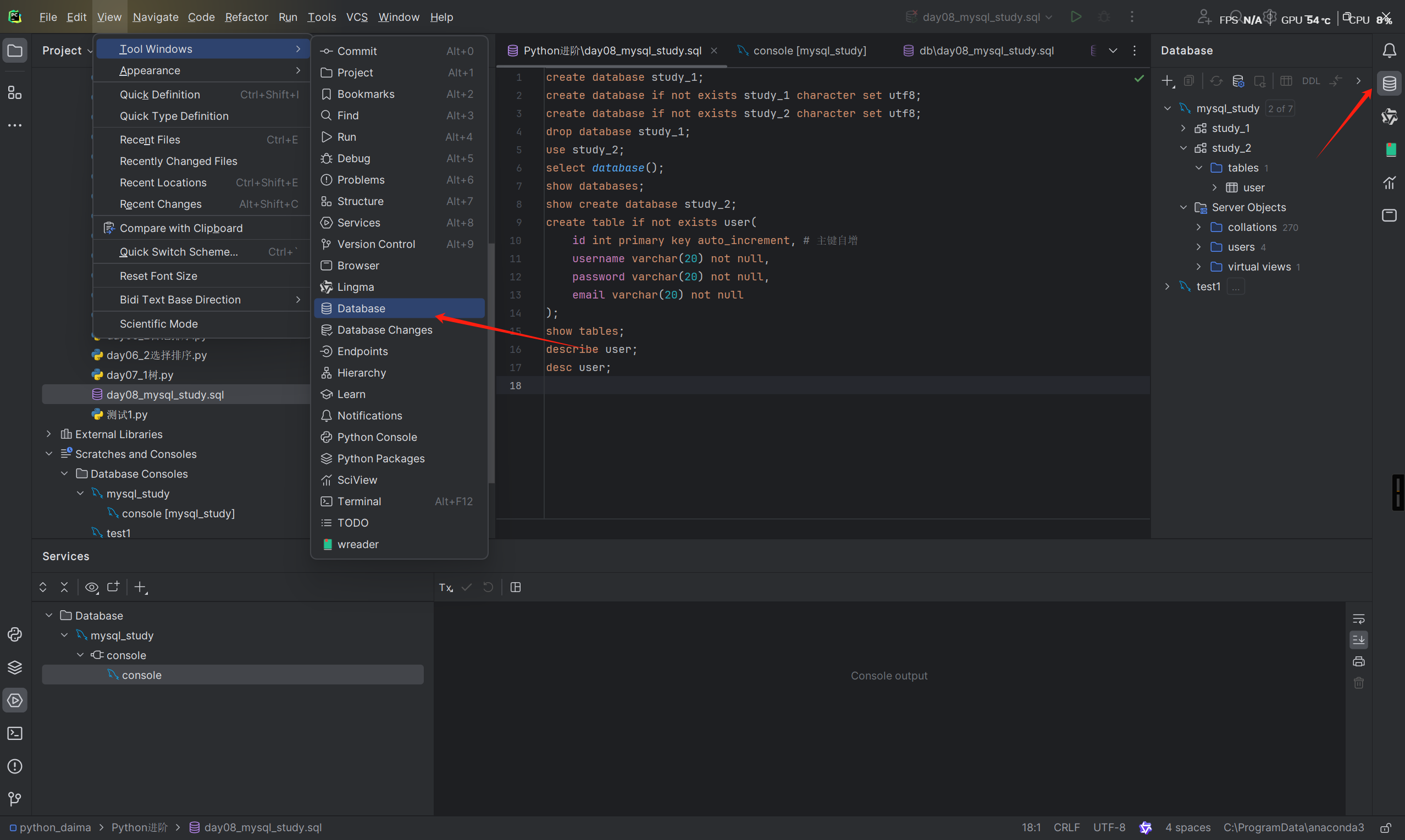 链接方式如下
链接方式如下
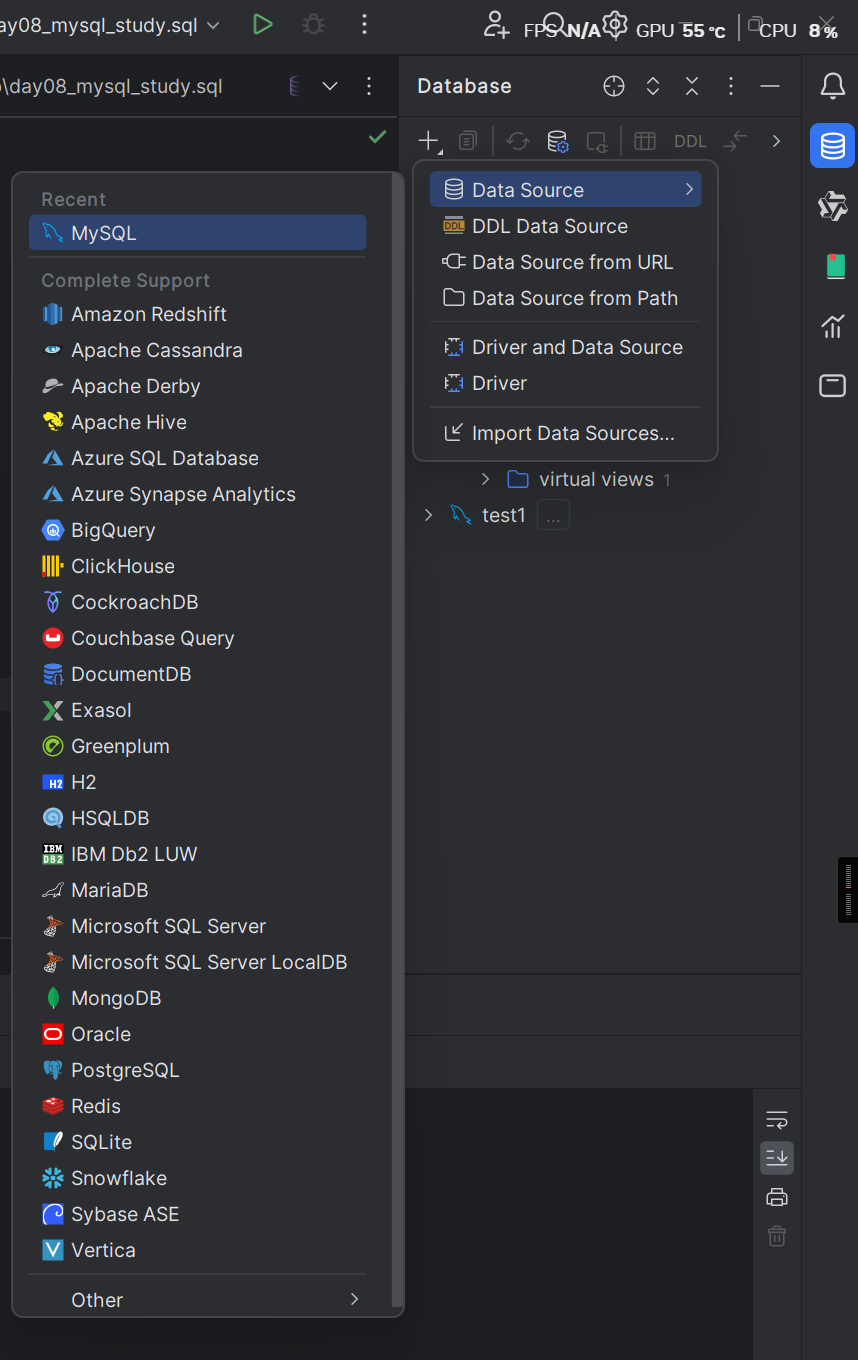
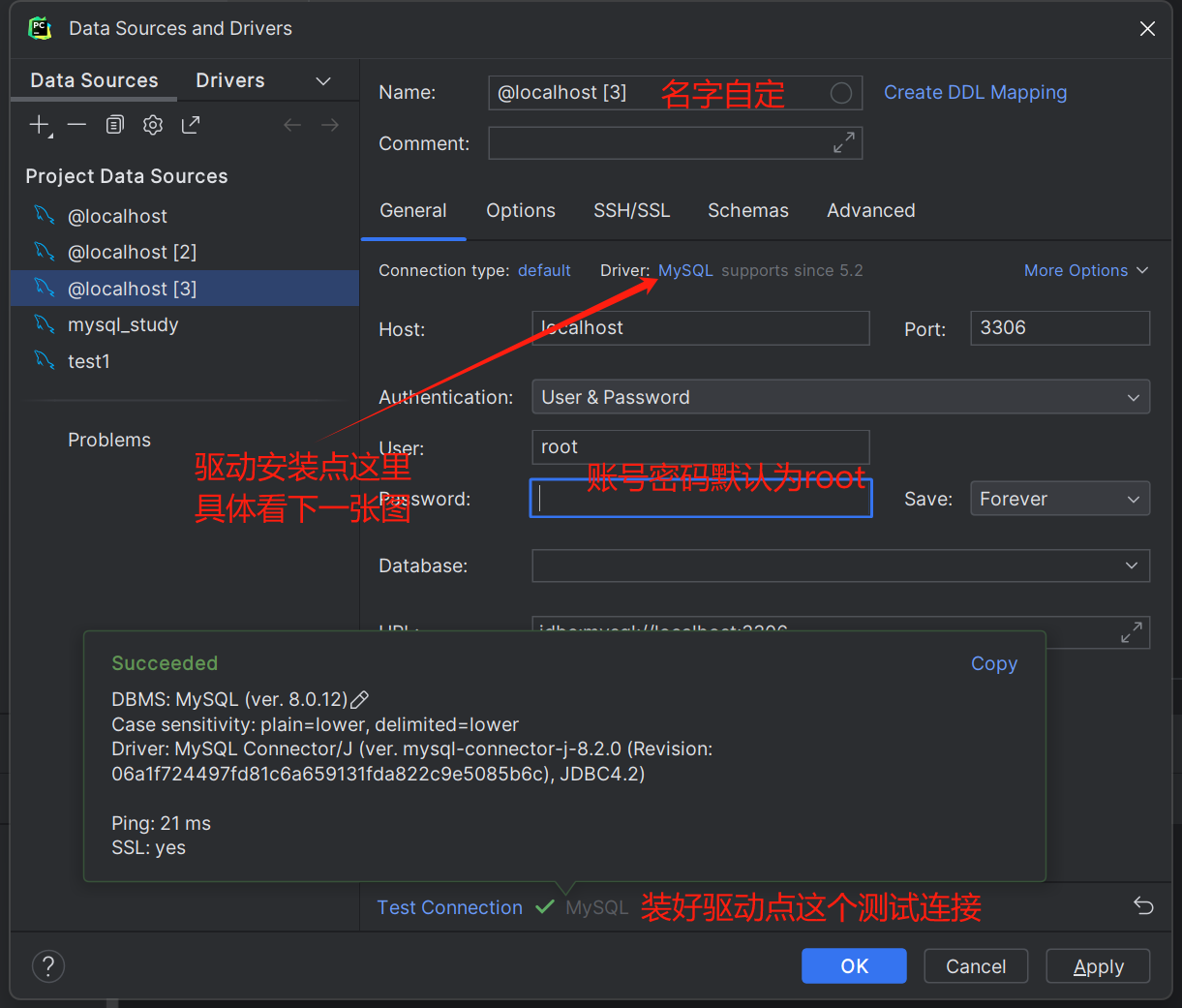 注意!!先在小皮或则自行开启MySQL服务
注意!!先在小皮或则自行开启MySQL服务
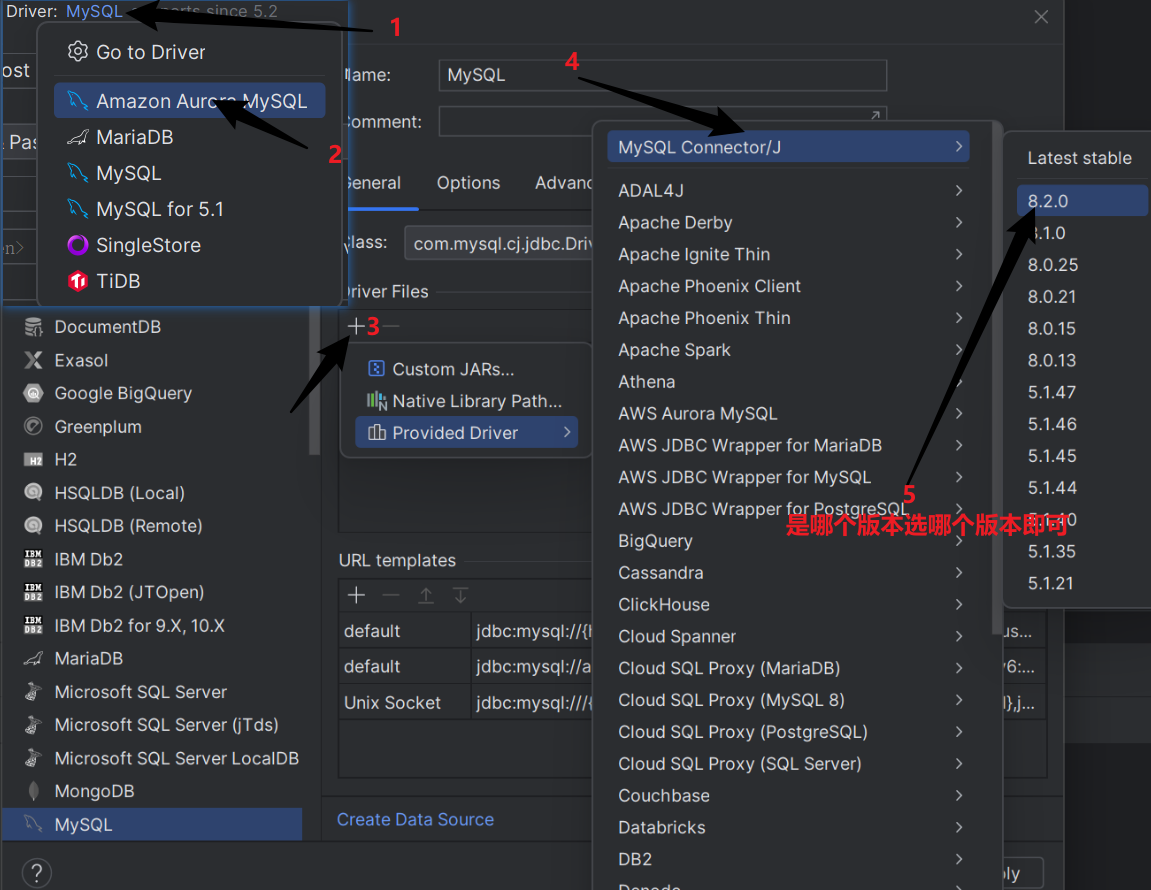
最后点击apply就链接成功了
创建sql文件,我这里是自己手动创建了个类型,后缀为.sql,可以直接创建个py文件改下后缀即可
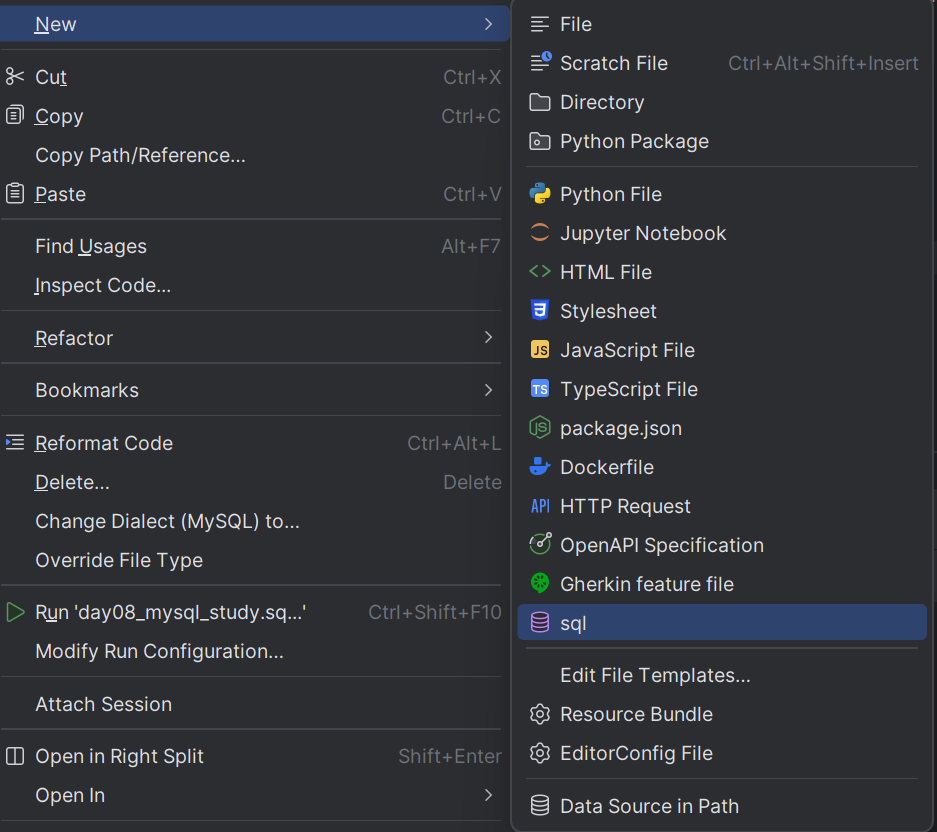 有兴趣可以 自行创建
有兴趣可以 自行创建
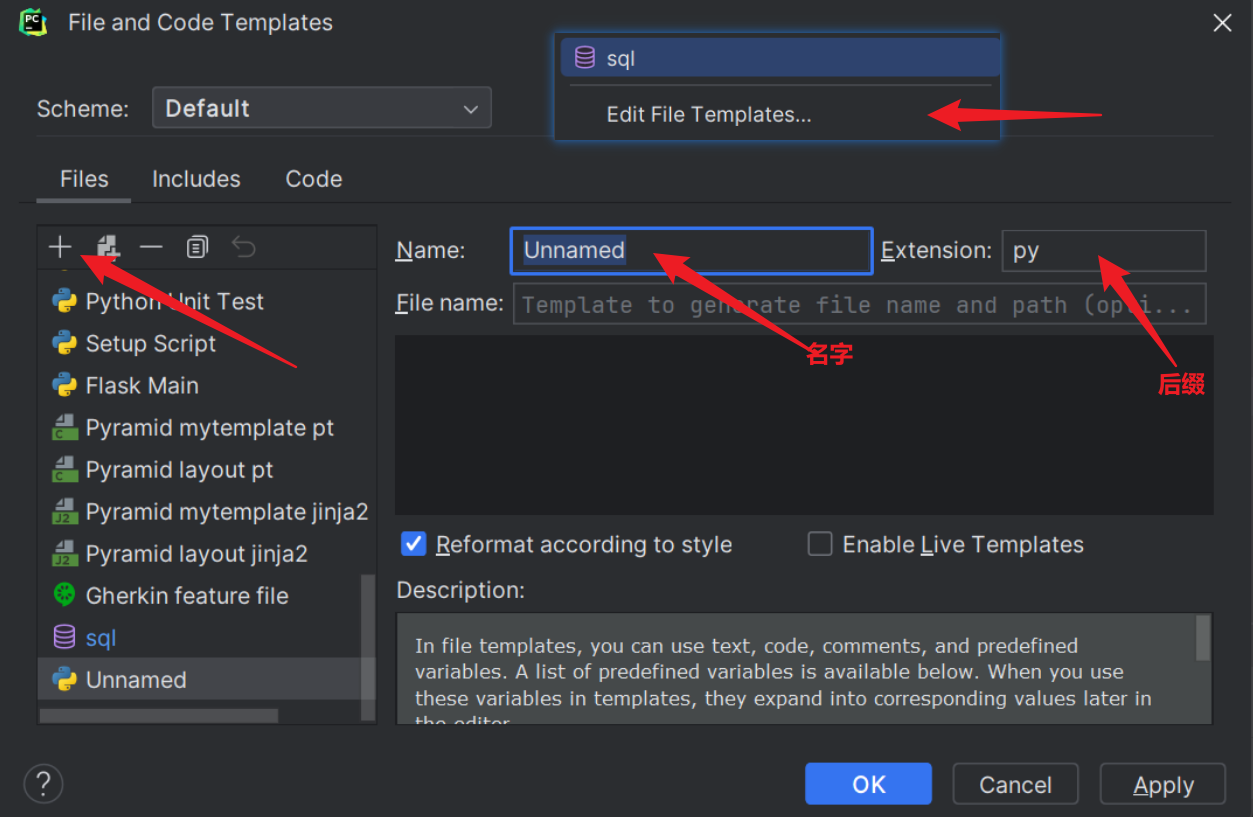 创建完文件后进入文件
创建完文件后进入文件
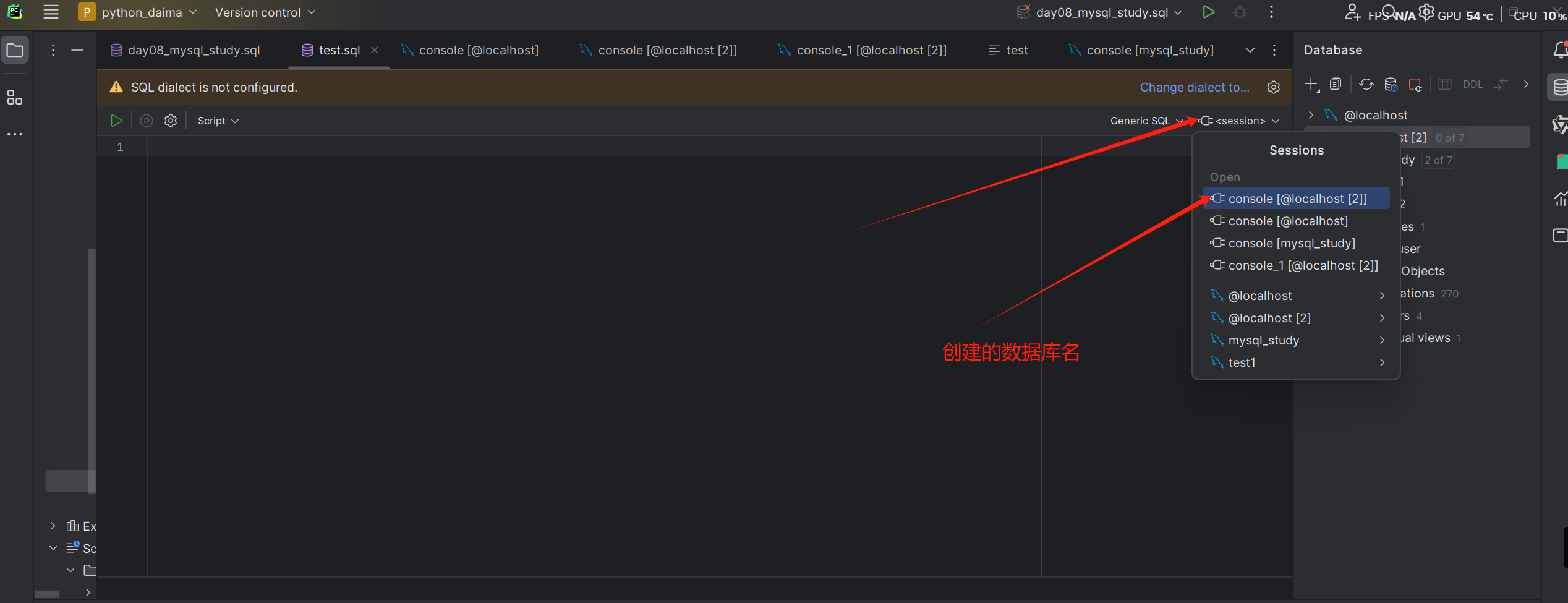 点击session选上之前创建的数据库即可操作
点击session选上之前创建的数据库即可操作
数据库基础语句
SQL分类
DDL: 数据定义语言:简称DDL(Data Definition Language)
作用: 用来定义数据库对象:数据库,表,列/字段等。
关键字: create,drop,alter等
DML: 数据操作语言:简称DML(Data Manipulation Language)
作用:用来对数据库中表的记录进行更新。
关键字: insert,delete,update等
DQL: 数据查询语言:简称DQL(Data Query Language)
作用:用来查询数据库中表的记录。
关键字: select,from,where等
DCL: 数据控制语言:简称DCL(Data Control Language)
用来定义数据库的访问权限和安全级别,及创建用户。SQL通用语法
1、SQL语句可以单行或多行书写,以分号结尾。
举例: select * from 表名 where 条件;
2、可使用空格和缩进来增强语句的可读性
select *
from 表名
where 条件;
3、MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
例如:select * from 表名 where 条件; SELECT * FROM 表名 WHERE 条件;
大小写切换快捷键: ctrl+shift+u
4、可以使用 /**/,--,# 的方式完成注释
/**/:多行注释,在注释区域内可以随意换行
-- 和# :单行注释,写在语句开头,换行后注释截止。注意: -- 后面必须有一个空格
单行注释快捷键: ctrl+/
多行注释快捷键: ctrl+shift+/数据库增删改查操作
创建数据库: create database [if not exists] 数据库名; 注意: 默认字符集就是utf8
删除数据库: drop database [if exists] 数据库名;
使用/切换数据库: use 数据库名;
查看所有的数据库名: show databases;
查看当前使用的数据库: select database();
查看指定库的建库语句: show create database 数据库名;example:
# 一.数据库的增删改查
# 1.创建数据库:
create database test;
create database test; # 报错,因为test已经存在
# if not exists: 如果库不存在就创建,存在就忽略
create database test1;
create database IF NOT EXISTS test1; # 存在忽略
create database IF NOT EXISTS test2; # 不存在就创建
# character set utf8: 设置编码为utf8,注意: mysql大多数版本已经都默认utf8
create database test3 CHARACTER SET utf8;
create database test4 CHARSET utf8;
# 2.删除数据库:
drop database test4;
# if exists: 如果库存在就删除,不存在就忽略
drop database IF EXISTS test4;
# 3.切换数据库:
use test;
use test1;
# 4.1查看所有库:
show databases;
# 4.1查看当前库:
select database();
# 4.3查看建库语句:
show create database test;数据类型
字符串类型: varchar(字符长度)
整数类型: int 注意: 默认长度是11,如果int不够用就用bigint
浮点类型: float(python默认) 或者 double(java默认) decimal(默认是有效位数是10,小数后位数是0)
日期时间: date datetime year库中表增删改查操作
创建表: create table [if not exists] 表名(字段1名 字段1类型 [字段1约束] , 字段2名 字段2类型 [字段2约束] ...);
删除表: drop table [if exists] 表名;
修改表名: rename table 旧表名 to 新表名;
注意: 修改表中字段本质都是修改表,咱们后面演示此处略
查看所有表: show tables;
查看指定表的建表语句: show create table 表名;为表的键添加约束
主键约束: primary key 特点: 修饰列对应的值非空唯一
主键自增: AUTO_INCREMENT 特点: 修饰主键对应的值不指定主键字段或者用0和null占位代表自动使用自增
非空约束: not null 特点: 修饰列对应的值不能为空
唯一约束: unique 特点: 修饰列对应的值不能重复
默认约束: default 特点: 修饰列对应的值提前设置默认值
exam:
# 创建day01_db数据库
create database day01_db;
# 使用day01_db库
use day01_db;
# 操作表的前提: 先创建库,并使用它
# 需求:创建学生表,用于存储学生的姓名,年龄,身高,生日信息
create table student(
id int,
name VARCHAR(100),
age int,
height float,
birthday date
);
create table test1(
id int
);
create table IF NOT EXISTS test1(
id int
);
# 删除表
drop table test1;
drop table IF EXISTS test1;
# 修改表名
rename TABLE student to stu;
# 查看所有表
show tables;
# 查看建表语句
/*
1.表名字段名都自动加了反引号``,注意: 关键字的会忽略
2.int加了默认长度11
3.所有字段值设置了默认值null
4.如果是字符串类型还设置了默认编码
5.默认选择了存储引擎,有的版本默认myisam,有的版本默认innodb
6.整个表也都设置了默认编码
*/
show create table stu;修改表中字段(增删改)
注意: 操作字段本质就是在修改表
添加字段: alter table 表名 add [column] 字段名 字段类型 [字段约束];
删除字段: alter table 表名 drop [column] 字段名;
修改字段名和字段类型: alter table 表名 change [column] 旧字段名 新字段名 字段类型 [字段约束];
modify只修改字段类型: alter table 表名 modify [column] 字段名 字段类型 [字段约束];
查看字段信息: desc 表名;eaxm
# 三.表中字段的增删改查
# 注意: 修改表中字段本质都是在修改表!!!
# 添加字段
alter table stu add weight double ;
# 注意: 如果字段名是关键字,需要用反引号引起来!!!
alter table stu add `desc` VARCHAR(100) ;
# 删除字段
alter table stu drop weight;
alter table stu drop `desc`;
# 修改字段
alter table stu change birthday bir DATETIME;
alter table stu change bir birthday DATETIME;
alter table stu change birthday birthday date;
# 注意: 了解modify,因为只能改类型,所以大家以后直接记change即可
alter table stu MODIFY height DOUBLE;
# 查看字段信息
desc stu;表中记录操作
插入数据记录: insert into 表名 (字段名...) values (具体值...) , (具体值...);
注意1: 具体值要和前面的字段名以及顺序一一对应上
注意2: 如果要插入的是所有字段,那么字段名可以省略(默认代表所有列都要插入数据)
注意3: 如果要插入多条记录,values后多条数据使用 逗号 分隔
修改数据记录: update 表名 set 字段名=值 [where 条件];
注意: 如果没有加条件就是修改对应字段的所有数据
删除数据记录: delete from 表名 [where 条件];
注意: 如果没有加条件就是删除所有数据
清空所有数据:
方式1: delete from 表名; 注意:此方式有警告
方式2: truncate [table] 表名; 注意: 此方式没有警告 exam
/*
操作库的前提: 先启动mysql服务,并连接它
操作表的前提: 先有库,并使用它
操作数据的前提: 先有表,并有对应字段
*/
# 创建库
create database day02_db;
# 使用库
use day02_db;
# 创建表
create table student(
id int,
name VARCHAR(100),
age int
);
# 插入数据
# 指定字段插入一条数据
insert into student(name) values ('张三');
# 指定字段插入多条数据
insert into student(name) values ('李四'),('王五'),('赵六');
# 注意: 不指定字段本质代表指定所有字段
# 不指定字段插入一条数据
insert into student values (1,'张三',18);
# 不指定字段插入多条数据
insert into student values (1,'张三',18),(2,'李四',18),(3,'王五',18);
# 修改数据
# 修改李四的年龄为28
update student set age = 28 where name = '李四';
# 修改王五和赵六的年龄为39
update student set age = 39 where name = '王五' or name = '赵六';
# 修改赵六的id为4,年龄为40
update student set id = 4,age = 40 where name = '赵六';
# 注意: 如果没有加条件,修改的是所有数据(慎用!!!)
update student set age = 12; # 报黄警告!然后弹窗警告,如果非要执行,选择execute
# 删除数据
# 删除id为1的记录
delete from student where id = 1;
# 删除id为1,以及id为3的记录
delete from student where id = 2 or id = 3;
# 注意: 如果不加条件删除的是所有数据(慎用!!!)
delete from student; # 报黄警告!然后弹窗警告,如果非要执行,选择execute
# 为了演示truncate删除数据,重新插入多条
insert into student values (1,'张三',18),(2,'李四',18),(3,'王五',18);
# truncate也能删除所有数据
truncate table student; # 不会警告,官方推荐使用truncate清空数据,为什么? 后面讲解外检约束
外键约束关键字: foreign key
外键约束语法: [CONSTRAINT 约束名] FOREIGN KEY (外键字段) REFERENCES 主表名(主键字段);
外键约束作用:
限制从表插入数据: 从表插入数据的时候如果外键值是主表主键中不存在的,就插入失败
限制主表删除数据: 主表删除数据的时候如果主键值已经被从表外键的引用,就删除失败
外键约束好处: 保证数据的准确性和完整性
多表查询:连接查询
多表查询的核心:是把多个表拼成一个表来查询
合并方式

其他多表查询:
自连接:特殊的内连接,座标和右表是同一个表,起别名做两个表用
子查询:本质是一个查询的结果作为另一个查询的条件或者表或者字段来使用,注意子查询作为表时需要取别名使用
areas.sql文件已上传
use day02_db;
# 注意:如果要删除有外键约束的主从表,先删除从表,再删除主表
drop table if exists products1;
drop table if exists category1;
# 创建分类表
CREATE TABLE category1
(
cid VARCHAR(32) PRIMARY KEY, # 分类id
cname VARCHAR(100) # 分类名称
);
# 商品表
CREATE TABLE products1
(
pid VARCHAR(32) PRIMARY KEY,
pname VARCHAR(40),
price DOUBLE,
category_id VARCHAR(32),
-- 建表时添加外键约束: CONSTRAINT [外键约束名] FOREIGN KEY (外键名) REFERENCES 主表名 (主表主键)
CONSTRAINT FOREIGN KEY (category_id) REFERENCES category1 (cid)
);
# 查看存储引擎
show create table category1;
show create table products1;
-- 删除外键约束
-- alter table 从表名 drop FOREIGN KEY 外键约束名;
alter table products1 drop FOREIGN KEY products1_ibfk_1;
-- 建表后添加外键约束
-- alter table 从表名 add CONSTRAINT [外键约束名] FOREIGN KEY (外键名) REFERENCES 主表名 (主表主键)
# alter table products1 add CONSTRAINT wj FOREIGN KEY (category_id) REFERENCES category1 (cid) ;
-- 外键约束的特点
/*
限制从表插入数据: 从表插入数据的时候如果外键值是主表主键中不存在的,就插入失败
限制主表删除数据: 主表删除数据的时候如果主键值已经被从表外键的引用,就删除失败
*/
# 限制从表插入数据: 从表插入数据的时候如果外键值是主表主键中不存在的,就插入失败
insert into products1 values('p1','小米',999,'c001'); -- 失败,报错Cannot add or update a child row: a foreign key constraint fails...
-- 等主表category1插入c001分类后,再执行上述语句,就成功了
insert into category1 values('c001','手机'); -- 成功
insert into products1 values('p1','小米',999,'c001');-- 成功
# 限制主表删除数据: 主表删除数据的时候如果主键值已经被从表外键的引用,就删除失败
delete from category1 where cid='c001'; -- 失败,报错Cannot delete or update a parent row: a foreign key constraint fails
-- 等从表products1外键不引用c001这条记录后,再执行上述语句,就会成功了
-- 注意: 不引用有两种方案: 要么直接删除从表对应记录行(不建议),要么把对应的引用改为null(建议)
update products1 set category_id = null where category_id = 'c001';
delete from category1 where cid='c001'; -- 成功
drop table if exists products1;
drop table if exists category1;
# ---------------------------------------------------------------------------------------
# TODO 演示多个表如何join连接成一个大宽表
# 交叉连接
select * from category c join products p;
# TODO 多练习内连接!!!
select * from category c join products p on c.id = p.category_id;
# 左外连接
select c.*,p.* from category c left join products p on c.id = p.category_id;
# 右外连接
select c.*,p.* from category c right join products p on c.id = p.category_id;
# 全外连接
select c.*,p.* from category c left join products p on c.id = p.category_id
union
select c.*,p.* from category c right join products p on c.id = p.category_id;
# 执行资料中的areas.sql脚本
# 自连接
# 需求: 查询'河北省'下所有的城市
select *
from areas as shi
join areas sheng on shi.pid = sheng.id
where sheng.title = '河北省';
# 需求: 查询'邯郸市'下所有的区县
select *
from areas as quxian
join areas shi on quxian.pid = shi.id
where shi.title = '邯郸市';
# 子查询
# 需求: 查询'河北省'下所有的城市
select * from areas where pid = (select id from areas where title = '河北省');
# 需求: 查询'邯郸市'下所有的区县
select * from areas where pid = (select id from areas where title = '邯郸市');
内置函数 :
可以看成excel函数升级版
官网文档:https://dev.mysql.com/doc/refman/8.0/en/functions.html
有需要可以自行查看,这里主要介绍一下开窗函数
开窗函数
作用:查询每一行数据时,使用指定的窗口函数对每行关联的一组数据进行处理。
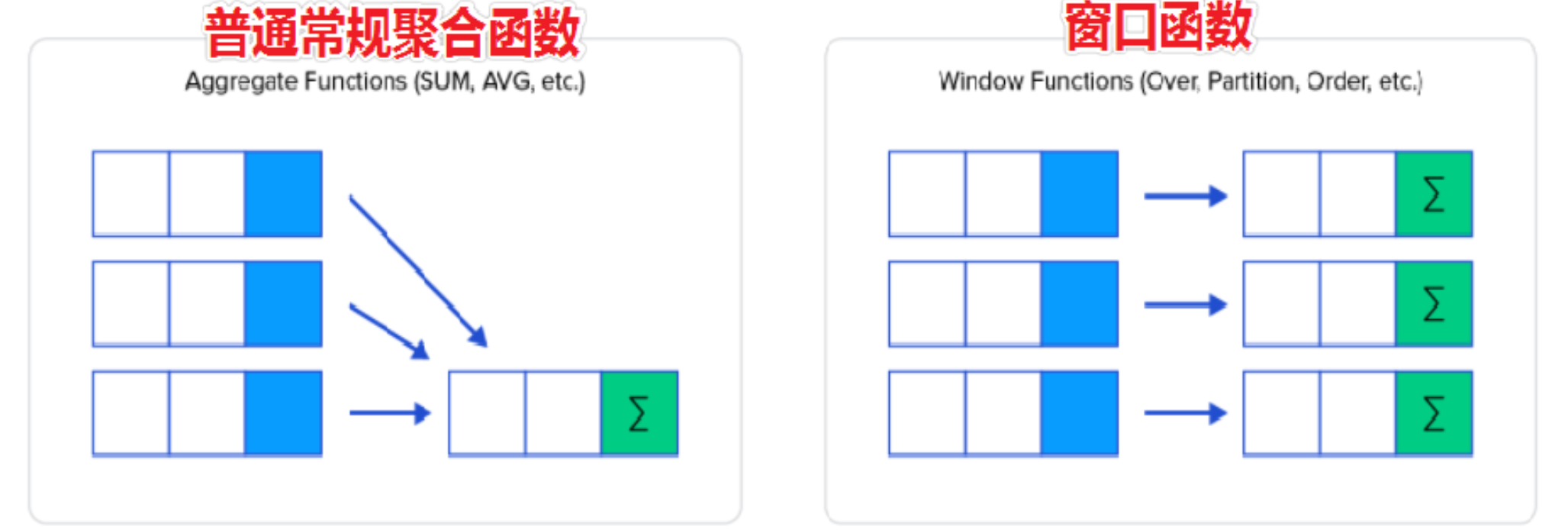
基本语法:<ranking function> OVER (ORDER BY 列名, ...) OVER(...)的作用就是设置每一行数据关联的一组数据范围,OVER()时,每行关联的数据范围都是整张表的数据。
RANK():产生的排名序号 ,有并列的情况出现时序号不连续 如排名 1124
DENSE_RANK() :产生的排序序号是连续的,有并列的情况出现时序号会重复,如1123
ROW_NUMBER() :返回连续唯一的行号,排名序号不会重复 如1234
create database day03_db;
use day03_db;
# --------------------------------------------------------------------------
# 常见函数
# 工资+奖金
select 10000 + null;
select 10000 + 0;
select 10000 + ifnull(10, 0);
select 10000 + ifnull(null, 0);
select 10000 + if(10 is null, 0, 10);
select 10000 + if(null is null, 0, 10);
select if(10 % 2 = 0, '偶数', '奇数');
select if(9 % 2 = 0, '偶数', '奇数');
select
case
when 10 % 2 = 0 then '偶数'
else '奇数'
end;
select
case 1
when 1=1 then '周一'
when 1=2 then '周二'
when 1=3 then '周三'
when 1=4 then '周四'
when 1=5 then '周五'
when 1=6 then '周六'
when 1=7 then '周日'
else '数字无效'
end;
select
case 2
when 1 then '周一'
when 2 then '周二'
when 3 then '周三'
when 4 then '周四'
when 5 then '周五'
when 6 then '周六'
when 7 then '周日'
else '数字无效'
end;
select replace('你TMD哦','TMD', '挺萌的');
help 'count';
# ---------------------------------开窗函数-----------------------------------------
# TODO 1.开窗函数的over()
# 准备数据
# TODO 把资料中的students脚本执行一下
# 需求1: 求每个学生的分数和平均分的差值
# 方式1:原始子查询
select name,score,
(select avg(SCORE) from day03_db.students) as avg_score,
score - (select avg(SCORE) from day03_db.students) as diff
from day03_db.students;
# 方式2: TODO 开窗函数
select name,score,
avg(score) over() as avg_score,
score - avg(score) over() diff
from day03_db.students;
# TODO 2.开窗函数的over(partition by 分组字段名)
# 需求: 求每个学生的分数和'同性别'的平均分的差值
# TODO 开窗函数
select name,score,gender,
avg(score) over(partition by gender) as avg_score,
score - avg(score) over(partition by gender) diff
from day03_db.students;
# TODO 2.开窗函数的over(order by 排序字段名)
# 需求: 按照整个班级把所有分数降序排序,并生成编号
select *,
row_number() over (order by score desc) as r1,
dense_rank() over (order by score desc) as r2,
rank() over (order by score desc) as r3
from day03_db.students;
# TODO 3.开窗函数的over(partition by 分组字段名 order by 排序字段名)
# 需求: 按照每个性别内所有分数降序排序,并生成编号
select *,
row_number() over (partition by gender order by score desc) as r1,
dense_rank() over (partition by gender order by score desc) as r2,
rank() over (partition by gender order by score desc) as r3
from day03_db.students;
# TODO 综合练习
# 需求: 获取每个性别下分数最高的学生信息(并列且连续)
# 注意: 如果子查询作为表使用,必须起别名!!!
# 方式1: 子查询方式
select *
from (
select *,
dense_rank() over (partition by gender order by score desc) as r
from day03_db.students
) t
where r = 1;
#方式2: with表达式
with t as(
select *,
dense_rank() over (partition by gender order by score desc) as r
from day03_db.students
)
select * from t where r = 1;
# -----------------------------------------------------------
select * from jing_dong.goods;
select * from jing_dong.user;
# TODO 事务是自动Tx:AUTO插入数据,一次自动插入
insert into jing_dong.user values(2,'binzi',123);
# -----------------------------------------------------------------
# TODO 可以把上述的TX:AUTO 改为Manual手动操作事务
insert into jing_dong.user values(3,'lisi',123);
# 注意: 数据不会立刻插入到表中,而是放到了内存缓冲区中,等待你告诉它是提交还是回滚
rollback;
# 注意: 如果先回滚了数据,就是从缓存区删除了数据,再提交没有意义了
commit;
# TODO 演示成功操作
insert into jing_dong.user values(3,'lisi',123);
commit;
# -----------------------------------------------------------------
insert into jing_dong.goods(name,cate_name,brand_name) value ('测试','测试','测试');
update jing_dong.goods set price = 99999 where name='测试';
DELETE from jing_dong.goods where name = '测试';
# ------------------------------------------------------------
# sql注入问题
select * from jing_dong.user where user='abc' and pwd='' or 1=1 or '';
pymysql:python中用于连接数据库的插件
安装pymysql库
命令: pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple/
pymysql使用
pymysql使用步骤:
1.导入模块
2.创建连接
3.创建游标
4.执行sql
5.关闭游标
6.关闭连接
示例:
# 1.导入pymysql模块
import pymysql
# 2.创建连接对象
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='root',
database='jing_dong'
)
# 3.创建游标对象
cur = conn.cursor()
# 4.执行sql
row = cur.execute('SELECT * FROM goods')
print(f'影响了{row}行')
# fetchone: 一次拿一条数据
# data1 = cur.fetchone()
# print(data1)
# fetchall: 一次拿剩下的所有的数据
data2 = cur.fetchall()
print(data2)
# 5.关闭游标
cur.close()
# 6.关闭连接
conn.close()sql语句改row.execute就行
拓展: 事务->要么都成功,都失败 (特性: 原子性 一致性 隔离性 持久性)
存储引擎: innodb支持事务 myisam不支持事务
增删改操作: 如果数据库底层是innodb引擎,必须手动commit提交
数据提交:commit()
数据回滚:rollback()拓展: 事务->要么都成功,都失败 (特性: 原子性 一致性 隔离性 持久性)
存储引擎: innodb支持事务 myisam不支持事务
增删改操作: 如果数据库底层是innodb引擎,必须手动commit提交
数据提交:commit()
数据回滚:rollback()

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









