







 超级会员免费看
超级会员免费看
 本文对比了五大开源ETL工具:Sqoop、dataX、Kettle、Canal和StreamSets。尽管各有特点,如Sqoop擅长Hadoop与关系数据库间数据迁移,dataX采用插件架构,Kettle是图形化ETL工具,Canal专注MySQL增量同步,StreamSets提供可视化数据流管理,但DataX因其高效、灵活和广泛的数据库支持被推荐为首选。
本文对比了五大开源ETL工具:Sqoop、dataX、Kettle、Canal和StreamSets。尽管各有特点,如Sqoop擅长Hadoop与关系数据库间数据迁移,dataX采用插件架构,Kettle是图形化ETL工具,Canal专注MySQL增量同步,StreamSets提供可视化数据流管理,但DataX因其高效、灵活和广泛的数据库支持被推荐为首选。
1. 摘要
对于数据仓库,大数据集成类应用,通常会采用ETL工具辅助完成。ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。当前的很多应用也存在大量的ELT应用模式。常见的ETL工具或类ETL的数据集成同步工具很多,以下对开源的Sqoop、dataX、Kettle、Canal、StreamSetst进行简单梳理比较。
通过分析,笔者个人建议优先DataX更优。
2. 内容
2.1 Sqoop
2.1.1 介绍
Sqoop,SQL-to-Hadoop 即 “SQL到Hadoop和Hadoop到SQL”。 是Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。主要用于在Hadoop与关系型数据库之间进行数据转移,可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。 sqoop命令的本质是转化为MapReduce程序。sqoop分为导入(import)和导出(export),策略分为table和query,模式分为增量和全量。
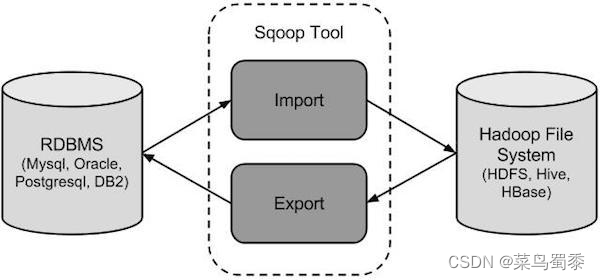
image.png
命令简单示例:
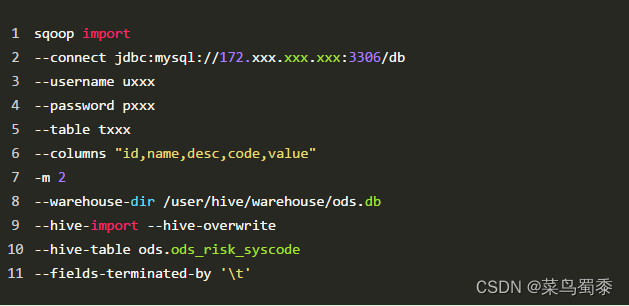
image.png
Sqoop支持全量数据导入和增量数据导入(增量数据导入分两种,一是基于递增列的增量数据导入(Append方式)。二是基于时间列的增量数据导入(LastModified方式)),同时可以指定数据是否以并发形式导入。
2.1.2 特点
1、可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中;
2、sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduce作业,在hadoop集群中运行。采用map-reduce框架同时在多个节点进行import或者export操作,速度比单节点运行多个并行导入导出效率高,同时提供了良好的并发性和容错性;
3、支持insert、update模式,可以选择参数,若内容存在就更新,若不存在就插入;
4、对国外的主流关系型数据库支持性更好。
2.2.3 Github
https://github.com/apache/sqoop
2.2 dataX
2.2.1 介绍
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
github地址:https://github.com/alibaba/DataX
支持数据源:
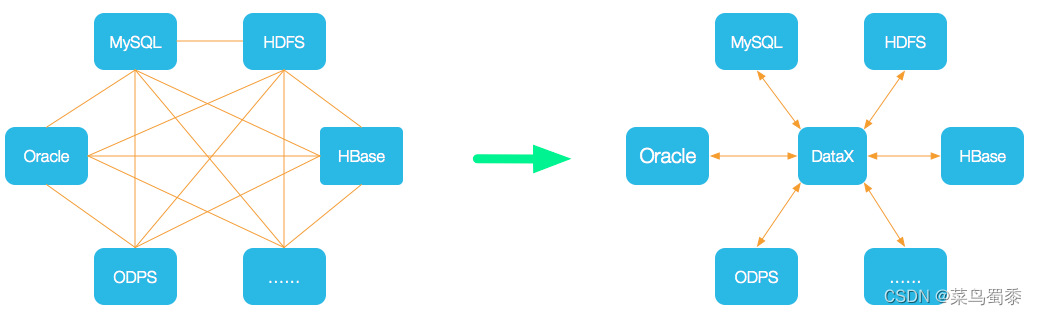
image.png
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader+Writer插件,纳入到整个同步框架中。
目前已到datax3.0框架设计:

image.png
datax使用示例,核心就是编写json配置文件job:

image.png
DataX框架内部通过双缓冲队列、线程池封装等技术,集中处理了高速数据交换遇到的问题,提供简单的接口与插件交互,插件分为Reader和Writer两类,基于框架提供的插件接口,可以十分便捷的开发出需要的插件。缺乏对增量更新的内置支持,因为DataX的灵活架构,可以通过shell脚本等方式方便实现增量同步。
2.2.2 特点
1、异构数据库和文件系统之间的数据交换;
2、采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问;
3、数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC;
4、开放式的框架,开发者可以在极短的时间开发一个新插件以快速支持新的数据库/文件系统。
2.2.3 Github
https://github.com/alibaba/DataX
2.3 Kettle
2.3.1 介绍
Kettle,中文名:水壶,是一款国外免费开源的、可视化的、功能强大的ETL工具,纯java编写,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。
Kettle家族目前包括4个产品:Spoon、Pan、CHEF、Kitchen。
组成部分:
Spoon:允许使用图形化界面实现ETL数据转换过程
Pan:批量运行Spoon数据转换过程
Chef:job(有状态,可以监控到是否执行、执行的速度等)
Kitchen:批量运行chef
2.3.2 特点
- 免费开源:基于Java免费开源软件
- 易配置:可跨平台,绿色无需安装
- 不同数据库:ETL工具集,可管理不同数据库的数据
- 两种脚本文件:transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制
- 图形界面设计:托拉拽,无需写代码
- 定时功能:在Job下的start模块,有一个定时功能,可以每日,每周等方式进行定时
2.3.3 Github
https://github.com/pentaho/pentaho-kettle/
2.4 Canal
2.4.1 介绍
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据实时订阅和消费,目前主要支持了MySQL,也支持mariaDB。
很多大型的互联网项目生产环境中使用,包括阿里、美团等都有广泛的应用,是一个非常成熟的数据库同步方案,基础的使用只需要进行简单的配置即可。
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
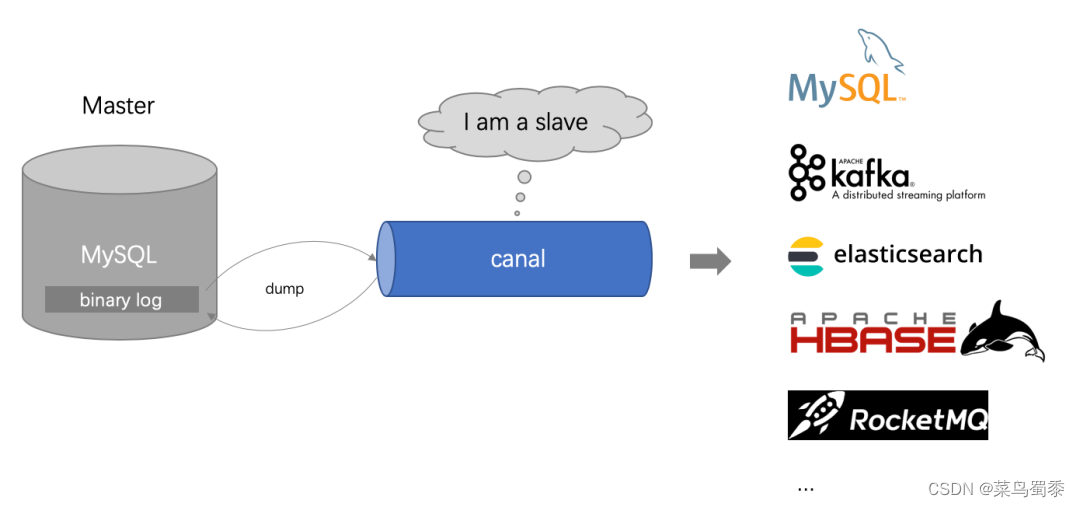
image.png
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
与其问canal能做什么,不如说数据同步有什么作用。
但是canal的数据同步不是全量的,而是增量。基于binary log增量订阅和消费,canal可以做:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护
- 业务cache(缓存)刷新
- 带业务逻辑的增量数据处理
2.4.2 特点
canal是通过模拟成为mysql 的slave的方式,监听mysql 的binlog日志来获取数据,binlog设置为row模式以后,不仅能获取到执行的每一个增删改的脚本,同时还能获取到修改前和修改后的数据,基于这个特性,canal就能高性能的获取到mysql数据数据的变更。
2.4.3 Github
github地址:https://github.com/alibaba/canal
2.5 StreamSets
2.5.1 介绍
Streamsets是一个大数据实时采集ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。
数据源支持MySQL、Oracle等结构化和半/非结构化,目标源支持HDFS、Hive、Hbase、Kudu、Solr、Elasticserach等。创建一个Pipelines管道需要配置数据源(Origins)、操作(Processors)、目的地(Destinations)三部分。
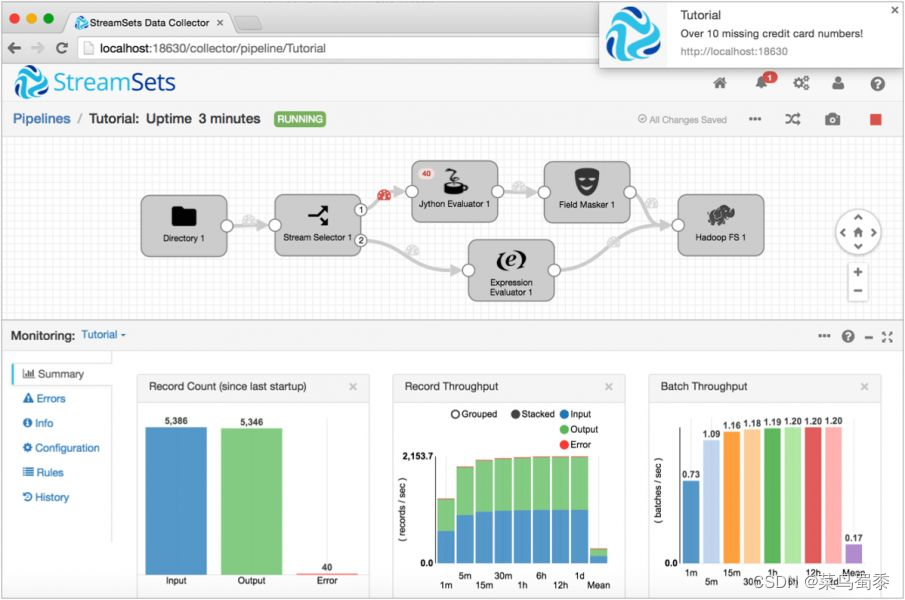
image.png

image.png
2.5.2 特点
Streamsets的强大之处:
- 拖拽式可视化界面操作,No coding required 可实现不写一行代码
- 强大整合力,100+ Ready-to-Use Origins and Destinations,支持100+数据源和目标源
- 可视化内置调度监控,实时观测数据流和数据质量
2.5.3 Github
地址:https://github.com/streamsets/
2.6 Sqoop和Datax的区别
2.6.1 特点对比
1、sqoop采用map-reduce计算框架进行导入导出,而datax仅仅在运行datax的单台机器上进行数据的抽取和加载,速度比sqoop慢了许多;
2、sqoop只可以在关系型数据库和hadoop组件之间进行数据迁移,而在hadoop相关组件之间,比如hive和hbase之间就无法使用。sqoop互相导入导出数据,同时在关系型数据库之间,比如mysql和oracle之间也无法通过sqoop导入导出数据。
与之相反,datax能够分别实现关系型数据库hadoop组件之间、关系型数据库之间、hadoop组件之间的数据迁移;
3、sqoop是专门为hadoop而生,对hadoop支持度好,而datax可能会出现不支持高版本hadoop的现象;
4、sqoop只支持官方提供的指定几种关系型数据库和hadoop组件之间的数据交换,而在datax中,用户只需根据自身需求修改文件,生成相应rpm包,自行安装之后就可以使用自己定制的插件;
2.6.2 性能对比
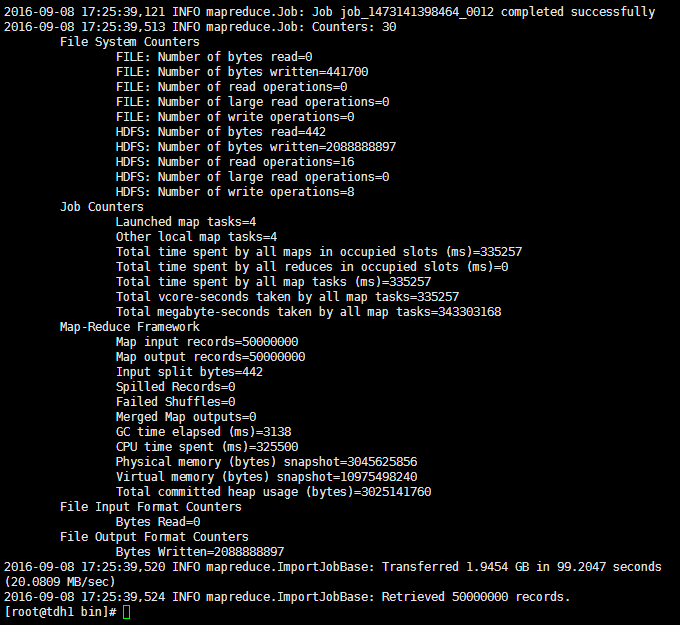
1、mysql->hdfs
在mysql中生成50,000,000条数据,将这些数据分别使用datax和sqoop导入到hdfs中,分别比较它们的性能参数:
在mysql中生成50,000,000条数据,将这些数据分别使用datax和sqoop导入到hdfs中,分别比较它们的性能参数:
sqoop:
| 属性 | 值 |
|---|---|
| CPU时间(ms) | 325500 |
| 读取物理内存快照大小(byte) | 3045625856 |
| 读取虚拟内存快照大小(byte) | 10975498240 |
| 平均速率(MB/s) | 20.0809 |
| 总时间(s) | 99.2047 |
5.DataX性能对比 - 图1
datax:
| 属性 | 值 |
|---|---|
| CPU平均占用率(%) | 21.99 |
| 平均速率(MB/s) | 4.95 |
| 总时间(s) | 202 |
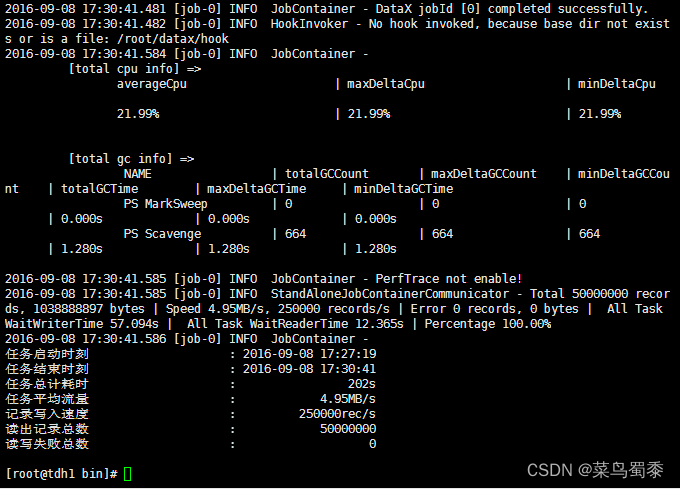
image.png
2、oracle->hdfs
在oracle中生成50,000,000条数据,将这些数据分别使用datax和sqoop导入到hdfs中,分别比较它们的性能参数:
sqoop:
| 属性 | 值 |
|---|---|
| CPU时间 | 86510毫秒 |
| 读取物理内存快照大小 | 2865557504 |
| 读取虚拟内存快照大小 | 10937077760 |
| 平均速率 | 6.4137MB/s |
| 总时间 | 94.9979s |
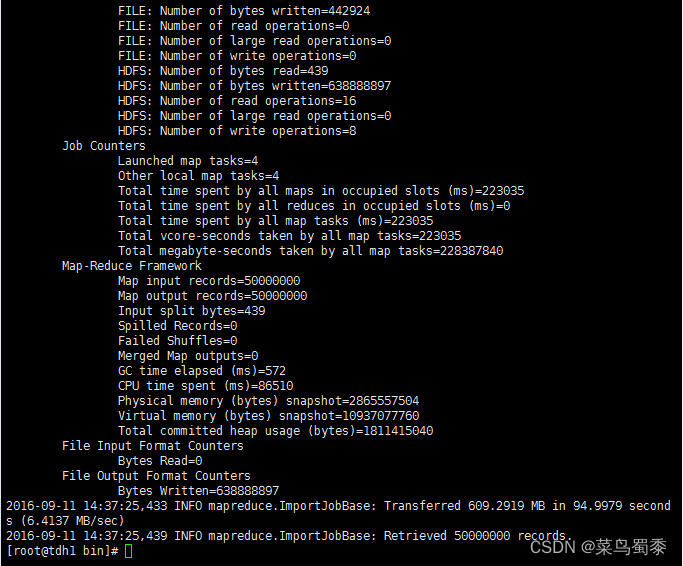
image.png
datax:
| 属性 | 值 |
|---|---|
| CPU平均占用率 | 15.50% |
| 平均速率 | 5.14MB/s |
| 总时间 | 122s |
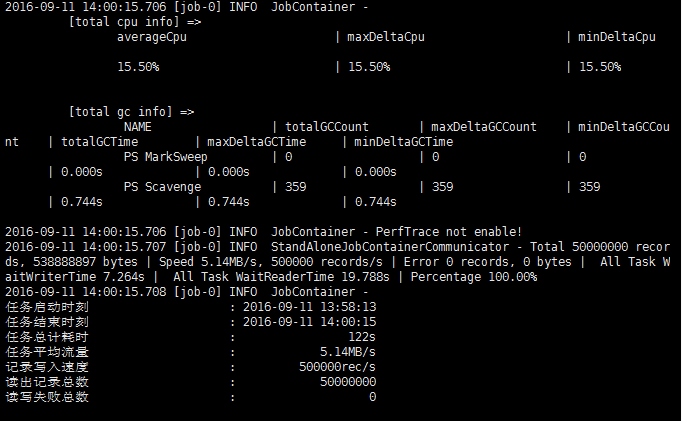
image.png
2.6.3 与TDH的兼容性
1、与TDH中的hadoop版本兼容,能够将关系型数据库中数据导入TDH中的hdfs中;
2、datax拥有一个sqoop没有的功能,就是将数据从hdfs导入到hbase,但是该功能目前仅仅支持的hbase版本为:0.94.x和1.1.x两个。而TDH中hyperbase的hbase版本为0.98.6,所以也不支持TDH的Hyperbase。
2.7 Datax和Kettle的对比
| 比较维度 | 产品 | Kettle | DataX |
|---|---|---|---|
| 设计及架构 | 适用场景 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 |
| 支持数据源 | 多数关系型数据库 | 少数关系型数据库和大数据非关系型数据库 | |
| 开发语言 | Java | Python、Java | |
| 可视化web界面 | KettleOnline代码收费Kettle-manager代码免费 | Data-Web代码免费 | |
| 底层架构 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 | 支持单机部署和集群部署两种方式 | |
| 功能 | CDC机 | 基于时间戳、触发器等 | 离线批处理 |
| 抽取策略 | 支持增量,全量抽取 | 支持全量抽取。不支持增量抽取要通过shell脚本自己实现 | |
| 对数据库的影响 | 对数据库表结构有要求,存在一定侵入性 | 通过sql select 采集数据,对数据源没有侵入性 | |
| 自动断点续传 | 不支持 | 不支持 | |
| 数据清洗 | 围绕数据仓库的数据需求进行建模计算,清洗功能相对复杂,需要手动编程 | 需要根据自身清晰规则编写清洗脚本,进行调用(DataX3.0 提供的功能)。 | |
| 数据转换 | 手动配置schema mapping | 通过编写json脚本进行schema mapping映射 | |
| 特性 | 数据实时性 | 非实时 | 定时 |
| 应用难度 | 高 | 高 | |
| 是否需要开发 | 是 | 是 | |
| 易用性 | 低 | 低 | |
| 稳定性 | 低 | 中 | |
| 抽取速度 | 小数据量的情况下差别不大,大数据量时datax比kettle快。 | datax对于数据库压力比较小 | |
| 其他 | 实施及售后服务 | 开源软件,社区活跃度高 | 阿里开源代码,社区活跃度低 |
3. 参考
(4)数据同步之道(Sqoop、dataX、Kettle、Canal、StreamSets) https://www.modb.pro/db/86290
(1)数据抽取工具比对:Kettle、Datax、Sqoop、StreamSets https://blog.csdn.net/xiaozm1223/article/details/89670460
(2)ETL学习总结(2)——ETL数据集成工具之kettle、sqoop、datax、streamSets 比较 https://zhanghaiyang.blog.csdn.net/article/details/104446610
(3)数据集成工具Kettle、Sqoop、DataX的比较 https://www.cnblogs.com/bayu/articles/13335917.html
(5)Datax与Sqoop的对比 https://blog.csdn.net/lzhcoder/article/details/107902791
(6)Datax和Kettle的对比 https://blog.csdn.net/lzhcoder/article/details/120830522
(7)超详细的Canal入门,看这篇就够了! https://blog.csdn.net/yehongzhi1994/article/details/107880162
如有侵权,请联系本人
删除。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











