








 超级会员免费看
超级会员免费看


本文是 Compaction 调优系列文章的第三篇。在前两篇文章中我们介绍了Compaction的一些基本概念,以及Compaction选择策略和执行过程。本篇我们将从实际使用场景的角度出发,介绍 Compaction 的调优思路和策略。通过本文读者将了解到 Compaction 相关的日志分析、参数调整和 API 的使用。
## 什么情况下需要调整 Compaction 参数
Compaction 的目的是合并多个数据版本,一是避免在读取时大量的 Merge 操作,二是避免大量的数据版本导致的随机IO。并且在这个过程中,Compaction 操作不能占用太多的系统资源。所以我们可以以结果为导向,从以下两个方面反推是否需要调整 Compaction 策略。
-
检查数据版本是否有堆积。
-
检查 IO 和内存资源是否被 Compaction 任务过多的占用。
查看数据版本数量变化趋势
Doris 提供数据版本数量的监控数据。如果你部署了 Prometheus + Grafana 的监控,则可以通过 Grafana 仪表盘的 BE Base Compaction Score 和 BE Cumu Compaction Score 图表查看到这个监控数据的趋势图:
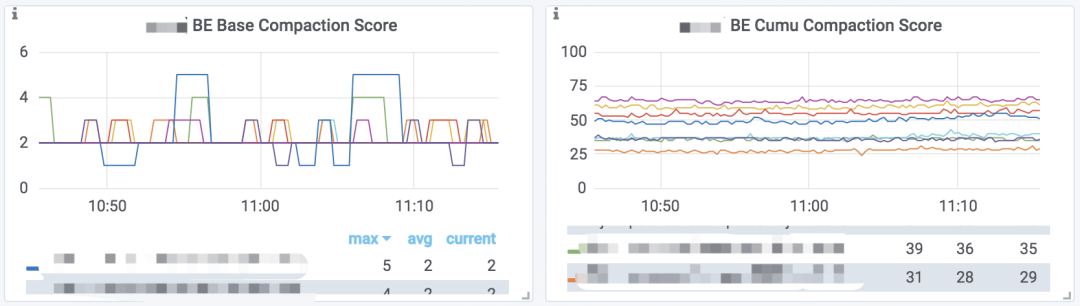
> 这个图表展示的是每个 BE 节点,所有 Tablet 中数据版本最多的那个 Tablet 的版本数量,可以反映出当前版本堆积情况。
> 部署方式参阅:http://doris.incubator.apache.org/master/zh-CN/administrator-guide/operation/monitor-alert.html
如果没有安装这个监控,如果你是用的 Palo 0.14.7 版本以上,也可以通过以下命令在命令行查看这个监控数据的趋势图:
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_BASE_COMPACTION_SCORE", "time" = "last 4 hours");
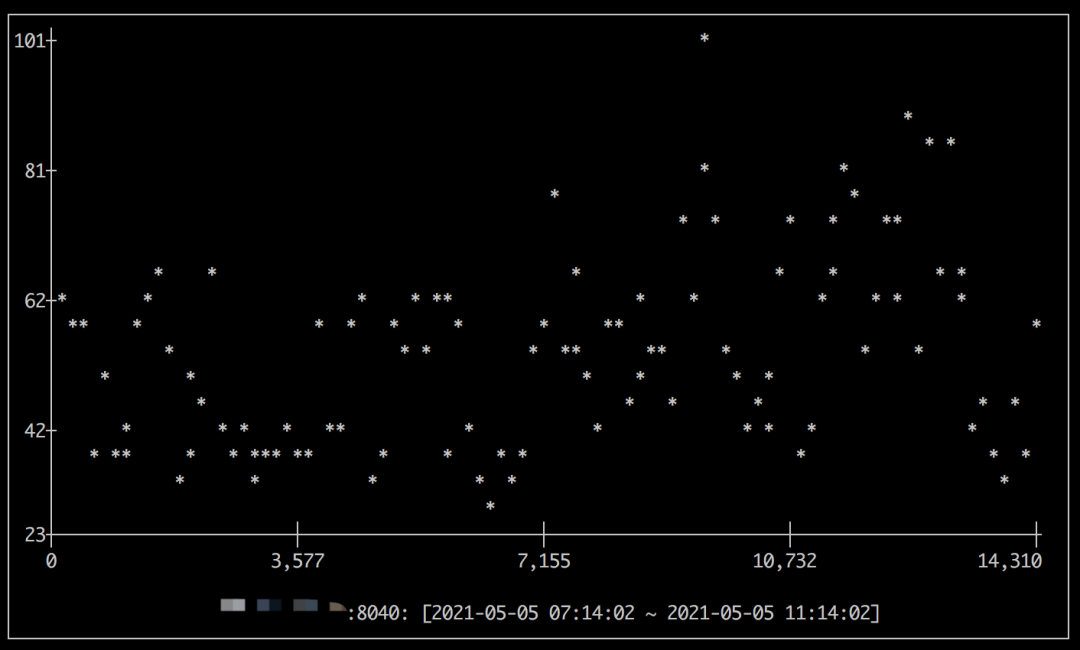
> 该命令具体帮助可执行 HELP ADMIN SHOW METRIC 查看
注意这里有两个指标,分别表示 Base Compaction 和 Cumulative Compaction 所对应的版本数量。在大部分情况下,我们只需要查看 Cumulative Compaction 的指标,即可大致了解集群的数据版本堆积情况。
版本是否堆积没有一个明确的界限,而是根据使用场景和查询延迟进行判断的一个经验值。我们可以按照以下步骤进行简单的推断:
1. 观察数据版本数量的趋势,如果趋势平稳,则说明 Compaction 和导入速度基本持平。如果呈上升态势,则说明 Compaction 速度跟不上导入速度了。如果呈下降态势,说明 Compaction 速度超过了导入速度。如果呈上升态势,或在平稳状态但数值较高,则需要考虑调整 Compaction 参数以加快 Compaction 的进度。
2. 通常版本数量维持在 100 以内可以视为正常。而在大部分批量导入或低频导入场景下,版本数量通常为10-20甚至更低。
查看Compaction资源占用
Compaction 资源占用主要是 IO 和 内存。
对于 Compaction 占用的内存,可以在浏览器打开以下链接:
http://be_host:webserver_port/mem_tracker
在搜索框中输入 AutoCompaction:

则可以查看当前Compaction的内存开销和历史峰值开销。
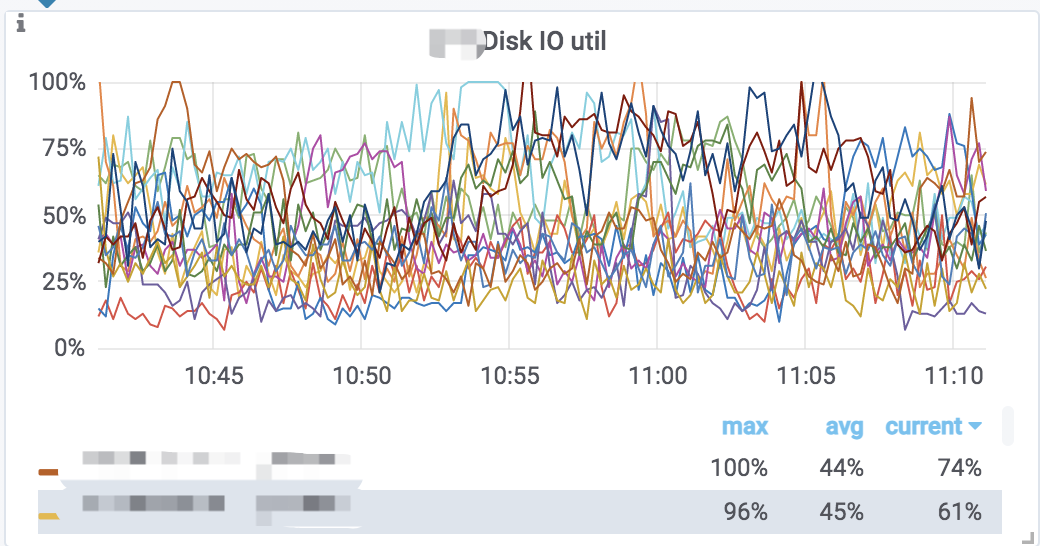
而对于 IO 操作,目前还没有提供单独的 Compaction 操作的 IO 监控,我们只能根据集群整体的 IO 利用率情况来做判断。我们可以查看监控图 Disk IO util:
或者通过命令在命令行查看(Palo 0.14.7 以上版本):
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_DISK_IO", "time" = "last 4 hours");
这个监控展示的是每个 BE 节点上磁盘的 IO util 指标。数值越高表示IO越繁忙。当然大部分情况下 IO 资源都是查询请求消耗的,这个监控主要用于指导我们是否需要增加或减少 Compaction 任务数。
## Compaction 调优策略
如果版本数量有上升趋势或者数值较高,则可以从以下两方面优化 Compaction:
1. 修改 Compaction 线程数,使得同时能够执行更多的 Compaction 任务。
2. 优化单个 Compaction 的执行逻辑,使数据版本数量维持在一个合理范围。
优化前的准备工作
在优化 Compaction 执行逻辑之前,我们需要使用一些命令来进一步查看一些Compaction的细节信息。
首先,我们通过监控图找到一个版本数量最高的 BE 节点。然后执行以下命令分析日志:
$> grep "succeed to do base" log/be.INFO.log.20210505-142010 |tail -n 100
以上两个命令可以查看最近100个执行完成的 compaction 任务:
I0505 17:06:56.143455 675 compaction.cpp:135] succeed to do cumulative compaction. tablet=106827682.505347040.d040c1cdf71e5c95-3a002a06127ccd86, output_version=2-2631, current_max_version=2633, disk=/home/disk6/palo.HDD, segments=57. elapsed time=2.29371s. cumulative_compaction_policy=SIZE_BASED.
通过日志时间可以判断 Compaction 是否在持续正确的执行,通过 elapsed time 可以观察每个任务的执行时间。
我们还可以执行以下命令展示最近100个 compaction 任务的配额(permits):
$> grep "permits" log/be.INFO |tail -n 100
配额和版本数量成正比。
我们可以找到 permits 较大的一个任务对应的 tablet id,如上图permit 为 39 的任务的 tablet id 为 106827970,然后继续分析这个 tablet 的 compaction 情况。
通过 MySQL 客户端连接 Doris 集群后,执行:
mysql> show tablet 106827970;
然后执行后面的 SHOW PROC 语句,我们可以获得这个 tablet 所有副本的详细信息。其中 VersionCount 列表示对应副本的数据版本数量。我们可以选取一个 VersionCount 较大的副本,在浏览器打开 CompactionStatus 列显示的 URL,得到如下Json结果:
{
这里我们可以看到一个 tablet 的 Cumulative Point,最近一次成功、失败的 BC/CC 任务时间,以及每个 rowset 的版本信息。如上面这个示例,我们可以得出以下结论:
1. 基线数据量大约在2-3GB,增量rowset增长到几十MB后就会晋升到BC任务区。
2. 新增rowset数据量很小,且版本增长较快,说明这是一个高频小批量的导入场景。
我们还可以进一步的通过以下命令分析指定 tablet id 的日志:
# 查看 tablet 48062815 最近十个任务的配额情况
另外,我们还可以在浏览器打开以下 URL,查看一个 BE 节点当前正在执行的 compaction 任务:
be_host:webserver_port/api/compaction/run_status
{
这个接口可以看到每个磁盘上当前正在执行的 compaction 任务。
通过以上一系列的分析,我们应该可以对系统的 Compaction 情况有以下判断:
1. Compaction 任务的执行频率、每个任务大致的执行耗时。
2. 指定节点数据版本数量的变化情况。
2. 指定 tablet 数据版本的变化情况,以及 compaction 的频率。
这些结论将指导我们对 Compaction 进行调优。
修改 Compaction 线程数
增加 Compaction 线程数是一个非常直接的加速 Compaction 的方法。但是更多的任务意味着更大的 IO 和 内存开销。尤其在机械磁盘上,因为随机读写问题,有时可能单线程串行执行的效率会高于多线程并行执行。Doris 默认配置为每块盘两个 Compaction 任务(这也是最小的合法配置),最多 10 个任务。如果磁盘数量多于 5,在内存允许的情况下,可以修改 max_compaction_threads 参数增加总任务数,以保证每块盘可以执行两个 Compaction 任务。
对于机械磁盘,不建议增加每块盘的任务数。对于固态硬盘,可以考虑修改 compaction_task_num_per_disk 参数适当增加每块盘的任务数,如修改为 4。注意修改这个参数的同时可能还需同步修改 max_compaction_threads,使得 max_compaction_threads 大于等于 compaction_task_num_per_disk * 磁盘数量。
优化单个 Compaction 任务逻辑
这个优化方式比较复杂,我们尝试从几个场景出发来说明:
场景一:基线数据量大,Base Compaction 任务执行时间长。
BC 任务执行时间长,意味着一个任务会长时间占用 Compaction 工作线程,从而导致其他 tablet 的 compaction 任务时间被挤占。如果是因为 0 号版本的基线数据量较大导致,则我们可以考虑尽量推迟增量rowset 晋升到 BC 任务区的时间。以下两个参数将影响这个逻辑:
cumulative_size_based_promotion_ratio:默认 0.05,基线数据量乘以这个系数,即晋升阈值。可以调大这个系数来提高晋升阈值。
cumulative_size_based_promotion_size_mbytes:默认 1024MB。如果增量rowset的数据量大于这个值,则会忽略第一个参数的阈值直接晋升。因此需要同时调整这个参数来提升晋升阈值。
当然,提升晋升阈值,会导致单个 BC 任务需要处理更大的数据量,耗时更长,但是总体的数据量会减少。举个例子。基线数据大小为 1024GB,假设晋升阈值分别为 100MB 和 200MB。数据导入速度为 100MB/分钟。每5个版本执行一次 BC。那么理论上在10分钟内,阈值为 100MB 时,BC 任务处理的总数据量为 (1024 + 100 * 5)* 2 = 3048MB。阈值为 200MB 是,BC 任务处理的总数据量为 (1024 + 200 * 5) = 2024 MB。
场景二:增量数据版本数量增长较快,Cumulative Compaction 处理过多版本,耗时较长。
max_cumulative_compaction_num_singleton_deltas 参数控制一个 CC 任务最多合并多少个数据版本,默认值为 1000。我们考虑这样一种场景:针对某一个 tablet,其数据版本的增长速度为 1个/秒。而其 CC 任务的执行时间 + 调度时间是 1000秒(即单个 CC 任务的执行时间加上Compaction再一次调度到这个 tablet 的时间总和)。那么我们可能会看到这个 tablet 的版本数量在 1-1000之间浮动(这里我们忽略基线版本数量)。因为在下一次 CC 任务执行前的 1000 秒内,又会累积 1000 个版本。
这种情况可能导致这个 tablet 的读取效率很不稳定。这时我们可以尝试调小 max_cumulative_compaction_num_singleton_deltas 这个参数,这样一个 CC 所要合并的版本数更少,执行时间更短,执行频率会更高。还是刚才这个场景,假设参数调整到500,而对应的 CC 任务的执行时间 + 调度时间也降低到 500,则理论上这个 tablet 的版本数量将会在 1-500 之间浮动,相比于之前,版本数量更稳定。
当然这个只是理论数值,实际情况还要考虑任务的具体执行时间、调度情况等等。
## 手动 Compaction
某些情况下,自动 Compaction 策略可能无法选取到某些 tablet,这时我们可能需要通过 Compaction 接口来主动触发指定 tablet 的 Compaction。我们以 curl 命令举例:
curl -X POST http://192.168.1.1:8040/api/compaction/run?tablet_id=106818600\&schema_hash=6979334\&compact_type=cumulative
这里我们指定 id 为 106818600,schema hash 为 6979334 的 tablet 进行 Cumulative Compaction(compact_type参数为 base 则触发 Base Compaction)。其中 schema hash 可以通过 SHOW TABLET tablet_id 命令得到的 SHOW PROC 命令获取。
如果提交成功,则会返回:
{"status": "Success", "msg": "compaction task is successfully triggered."}
这是一个异步操作,命令只是提交compaction 任务,之后我们可以通过以下 API 来查看任务是否在运行:
curl -X GET http://192.168.1.1:8040/api/compaction/run_status?tablet_id=106818600\&schema_hash=6979334
返回结果:
{
当然也可以直接查看 tablet 的版本情况:
curl -X GET http://192.168.1.1:8040/api/compaction/show?tablet_id=106818600\&schema_hash=6979334
End
我们通过三篇文章系统的阐述了 Compaction 的原理和调优过程,希望能够帮助用户更好的维护 Doris 集群。Compaction 策略是 Doris 比较复杂的一个数据处理逻辑,需要考虑的状态和情况非常多,因此也在不断完善中,最终希望能够自动的适配各种负载场景,减轻用户的运维压力。















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









