






实验一 Linux命令接口
一、实验目的
通过本实验,要求学生熟练掌握Linux各种文件操作命令,包括:使用控制字符执行特殊功能;使用file和strings命令确定文件类型;使用cat利more命令显示文本文件的内容;使用head和tail命令显示文本文件的部分内容;使用wc命令确定单词、行和字符数;使用diff命令比较2个文件;回顾文件和目录命名约定;使用touch命令创建新文件;使用mkdir命令创建新目录;使用rm命令删除文件;使用rm -r命令删除目录。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境: Linux Redhat 9.0或Ubumtu操作系统平台、MacOX或其他类似Unix系统。
三、实验内容和步骤
1. 文件信息命令
步骤1:开机,登录进入GNOME(或你所用Linux版本提供的图形用户接口)。
在GNOME登录框中填写指导老师分配的用户名和口令并登录。
service xrdp restart
使用远程桌面连接

步骤2:访问命令行。
单击红帽子,在“GNOME帮助”菜单中单击“系统工具”-“终端”命令,打开终端窗口。(不同的Linux版本所提供的终端访问的位置可能不同)
步骤3:使用控制字符执行特殊功能。
控制字符用来执行特殊的作业,如中止和启动屏幕输出。
大多数PC键盘有两个控制键。它们通常标记为Ctr1,可以在键盘的左右下角找到。为了输入一个控制字符序列,可按住Ctrl键不放,然后按下键盘上相应的字符。
Ctrl + C:中断当前活动。当你在csh中键入一个不可识别的命令行 (例如,$ls “) ,收到第2个提示符的时候,Ctrl + C也可以用于恢复shell提示符。
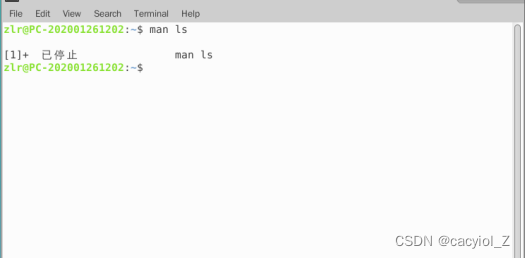
Ctrl + Z:终止当前活动。显示ls命令的手册页面 (man ls) ,然后使用Ctrl -z中止输出。
当你按下Ctrl + Z的时候,发生了什么事情?
当前活动被终止
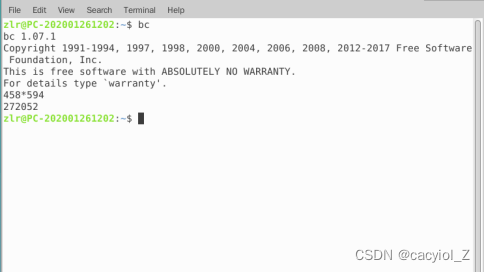
Ctrl + D:表示文件的末尾或者退出。 Ctrl + D用于退出一些Linux工具程序 (bc、write等) ,退出一个终端窗口,注销一个终端会话或者命令行登录会话。作为一个一般的规则,当您出现“死机”时,或者如果Ctrl + C不起作用,可试试Ctrl + D。例如:
1) 在shell提示符下键入bc,启动基本的计算器工具程序。
2) 把两个数字相乘 (键入:458*594,然后按回车键) 。
3) 按Ctrl + D退出计算器。
当使用计算器的时候,你的提示符是什么?
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software
Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty’.
Ctrl + U :擦除整个命令行。Ctrl + U最常用在:
· 一个擦除决定不执行的命令行的快捷方式。
· 如果登录到一个远程系统,退格键不起作用。
· 它可以确保在登录的时候,从一个“空”的用户帐号和口令输入开始。
· 因为在口令输入的时候看不见它们,当知道自己键入了错误字符的时候,使用Ctrl + U擦除密码,重新开始输入。
如果输入一个命令,如ls –R/,有时候,会在按下回车键之前想擦除命令行。输入一个命令,在接下回车键执行命令之前按下Ctrl + U。结果是什么?
整行命令被删除。
步骤4:使用file命令确定文件类型。
在Linux系统中可以找到许多类型的文件。文件类型可以通过使用file命令来确定。当一个用户试图打开或阅读一个文件的时候,这个信息很重要。确定文件类型可以帮助一个用户决定使用哪个程序或命令来打开这个文件。这个命令的输出最常见的是如下几种:文本文件、可执行文件或数据文件。
1) 文本文件:包括ASCII或英语文本、命令文本和可执行的shell脚本。这种类型的文件可以使用cat或more命令读取,可以使用vi或其他文本编辑器编辑。
单击红帽子,在“GNOME帮助”菜单中单击“辅助设施”-“Text Editor”命令,在文本编辑中键入适当内容并保存为test文件。
使用file命令来确定test文件的文件类型。它是哪种类型的文件?
ASCII text

2) 可执行 (或二进制) 文件:包括32位的可执行文件和可扩展链接格式(ELF) 编码文件,和其他动态链接的可执行文件。这种文件类型表示这个文件是一个命令或程序。
单击红帽子,在“GNOME帮助”菜单中单击“办公”-“OpenOffice.org Writer”命令,建立一个文档如ww.sxw。
使用file命令确定你所建立的文件类型。它是哪种类型的文件?(注意文件名部分必须包括扩展名,如file ww.sxw 。)
可执行文件
3) 数据文件:数据文件是由系统中运行的应用创建的。在某些情况下,文件的类型是会说明的。例如,FrameMaker (桌面印刷软件) 文档。
使用file命令确定dir1/coffees子目录中beans文件的文件类型。它是什么文件类型的?
Kofficeapplication/x-kword
步骤5:使用strings命令。
strings命令可以用于打印可执行文件或者二进制文件中的可读字符。
一些有编程背景的人,可以解释strings产生的输出。这个命令在这里只是作为一个展示可执行文件中可打印字符的方法来介绍。strings命令必须用于读取可执行文件,如 /usr/bin/cat。在大多数情况下,strings命令也可以给出命令的使用语法。
使用strings命令查看 /usr/bin/cal文件的可读字符。列出strings命令中的一些输出。
/lib/ld-linux.so.2 libc.so.6 strerror wcstombs wcscpy optind --progname getopt vwarn stderr wcswidth util-linux-2.11y
步骤6:使用cat命令显示文件的内容。
cat命令在屏幕上显示一个文本文件的内容。它常用于显示如脚本文件 (类似批处理文件) 这样的短文本文件。如果文件超过一屏的话,必须使用一个屏幕可以滚动的窗口,如GNOME环境中的终端窗口。
键入 ls /dev > dev1
使用cat命令显示主目录中dev1文件的内容。文本的显示出现了什么情况?
显示出了很长一串文本内容,必须按滚动条才能看全部文本内容。
步骤7:使用more命令显示文件的内容。
more命令是一个用于显示文本文件首选的方法,因为它会自动的一次显示一屏文件内容。如果文件的信息比一屏更长,屏幕的底部显示如下的信息:--More-- (n%) (文件的n%已经显示) 。按下回车键,继续一次显示一行信息。空格键将继续一次显示一屏内容。
使用more命令显示主目录中dev1文件的内容。文本的显示出现了什么情况?
显示出了第一页文本。每按一次回车显示下一行,每按一次空格显示下一页。
步骤8:使用head命令显示文件的一部分。
head命令用于显示一个或多个文本文件的前n行。在默认情况下,如果没有给出 -n选项,将显示前10行。当您只想查看文件的开始的几行,而不管文件的大小的时候,head命令是很有用的。
1) 单独使用head命令,显示主目录中dev1文件的开始部分。显示了多少行?
10行
2) 使用带 -n选项的head命令,显示主目录中dante文件的前20行。您输入什么命令?
head–20dante
步骤9:使用tail命令显示文件的一部分。
使用tail命令,显示文件的最后几行。在默认情况下,如果没有指定 -n选项,将显示最后10行。当检查大型日志文件最近输入内容的时候,tail命令是很有用的。备份工具程序常把备份哪个文件和什么时候做的备份,写到日志文件中去。一个备份日志文件中最后的输入通常是备份文件的总数和备份是否成功完成的信息。-n选项显示了文件的最后n行。
单独使用tail命令,显示主目录中dante文件的末端。显示了多少行?
10行
步骤10:通过使用wc命令,确定行数、单词数和字符数。
wc (单词计数) 命令可以用于显示文本文件的行数、单词数、字节数或者字符数。当确定文件特征或者当比较两个文件的时候,这个命令是很有用的。使用不带选项的wc将给出文件的行数、字节数。使用带一个选项的wc,可以确定想查看的哪一项内容。
使用wc命令确定主目录中dev1文件的行数、单词数和字符数。有多少行、多少个单词和多少个字符?
5374行5374个单词33706个字符
步骤11:使用wc计算目录条目的数目。
使用wc和ls命令确定主目录中条目 (文件和目录) 的数目。为此,必须把ls命令的输出导入到wc命令中。
更多符号是竖线,和后斜线 (\) 在同一个键上。在命令行提示行下,输入命令ls l wc -w。有多少个文件和目录名 (单词) ?
8个
步骤12:使用diff命令确定文件之间的不同之处。
diff (不同) 命令用于比较2个文本文件,找出在它们之间的不同之处。wc命令可以比较文件,因为它计算行数、单词数和字符数。有可能2个文件有相同的行数、单词数和字符数,但是字符和单词不同。diff命令可以从实际上找出文件之间的不同。
这个命令的输出把2个文本文件之间的不同一行一行的显示出来。diff命令有2个选项:-i 和 -c。-i选项忽略字母的大小写,例如A和a相等。-c选项执行细致的比较。
单击红帽子,在“GNOME帮助”菜单中单击“辅助设施”-“Text Editor”命令,创建两个文件fruit1和fruit2,并键入适当内容。
使用diff命令执行细节比较,确定fruit1文件和fruit2文件之间的区别。
在fruit1文件和在fruit2文件中,哪几行是不同的?
fruit1:ghaoujogh bngab ba
fruit2:GNAW BALBNA g joaiwje jannb BHNA;OBNAJBN
1) cat命令:
· 对fruit1文件使用cat命令。
· 对fruit2文件使用cat命令。
· 键入命令行cat fruit1 fruit2 > filex。
· 对filex文件使用cat命令。上面的命令行做了什么工作?
把fruit1和fruit2的文本内容合并在了一起,成为filex文件的文本内容
2) 可以使用哪2个命令来确定2个文件是否相同?
difffruit1fruit2和catfruit1,catfruit2
步骤13:关闭终端窗口,注销。
2. 基本的命令行文件管理
步骤14:回顾Linux的文件和目录命名规则。
在本实验中,我们将创建文件和目录,因此,在开始之前,先来回顾一下Linux文件和目录的命名规则和指导方针。
1) 最大长度:组成文件和目录名最大长度为255个数字字母字符。一般来说,应该尽可能的保持文件名短但是仍然有意义。
2) 非数字字母字符:一些非数字字母字符或者元字符是可用的:下划线 (_) 、连字符号 (-) 和句点 (.) 。这些元字符可以在文件或目录名中使用多次(Feb.Reports.Sales是一个有效的文件或目录名) 。尽管shell允许把星号 (*) 、问号(?) 和发音符号 (~) 、方话号 ([ ]) 、&、管道 [ | ] 、引号 (“”) 和美元符号 ($) 在文件名中使用,但这不是推荐的,因为这些字符对于shell有特殊的意义。分号 (;) 、小于号 (<) 和大于号 (>) 是不允许作为文件名的。
3) 文件名扩展:文件名可以包含一个或多个扩展名。扩展名常被一个应用追加到文件的末端。扩展名通常是1个到3个字符,追加到文件名的末端,之前有一个句点 (.) 。当命名文件的时候,您可以选择使用这个规则。
4) 目录名的扩展名:目录名一般不包含扩展名,但是也没有规则反对这一点。
5) 大小写敏感:Linux文件和目录名是大小写敏感的。Project1和projectl不是同一个文件。在一个目录中,不能够有两个文件有着同样的名字。一般规则都是使用小写字母。
检查表7-1中的文件名,指出它们是否是有效或者推荐的Linux文件或目录名,为什么是或为什么不是。

步骤15:使用touch命令创建文件。
每次创建一个新的字处理文档或者电子数据表,就是正在创建一个新文件,应该符合之前提到的文件命名规则。也必须拥有创建文件的目录的足够权限。
使用touch命令,可以同时创建一个或多个文件。一些应用要求在写文件之前,文件必须存在。touch命令对于快速创建需要处理的文件很有用。也可以使用touch命令更新文件被访问的时间和日期,使文件可以再次被备份。当创建文件或目录的时候,可以指定绝对和相对的路径名。
命令格式:
touch filename (s)
1) 在主目录中使用touch命令创建一个名为newfile的文件,应该使用什么命令?
touch newfile
2) 使用touch命令在这个目录中创建另一个叫做filenew的新文件,应该使用什么命令?
touch filenew
3) 输入命令显示practice目录中的文件的长列表。创建的文件列出来了吗?
列出来了
4) 谁是文件的所有者?
root
5) 和文件关连的组是什么?
root
6) 创建的日期和时间是什么?
5月1日 15:35
7) 文件的大小是多少?
26743kB
8) 使用file命令确定newfile的文件类型。它是哪一类的文件?
ASCII text
9) 使用touch命令同时创建3个文件:new1、new2和new3,应该使用什么命令?
touch new1 new2 new3
10) 输入命令显示practice目录中文件的长列表。创建的3个新文件列出来了吗?
列出来了
步骤16:使用mkdir命令创建新目录。
mkdir (创建目录) 命令用于创建目录或文件夹。目录可以包含其他目录,称为子目录,它们可以包含文件。
目录可以使用或者绝对路径名或者相对路径名创建。可以在同一行中指定多个目录名,创建多个新目录。必须有创建目录的足够权限。
mkdir directory_name (s)
1) 从主目录中,使用相对路径名改变到practice目录中。使用什么命令?
cd/practice
2) 使用mkdir命令,在这个目录中创建一个叫做newdir的子目录。使用什么命令?
mkdir/newdir
3) 输入命令,显示practice目录中文件和目录的长列表。创建的目录列出来了吗?
列出来了
4) 目录的所有者是?
Root
5) 文件的大小是多少?
4096kB
6) 使用file命令确定newdir文件的类型。它是哪一类的文件?
目录文件directory
7) 如果名字中没有字符dir,采取别的什么方法来识别出它是一个目录?
颜色识别,目录是蓝色的
8) mkdir命令创建3个目录,目录名分别为high、medium和low,应该使用什么命令?
mkdir/high mkdir/medium mkdir/low
- 用ls命令检查创建是否成功?
成功了
步骤17:使用rm命令删除文件。
rm目录可以删除单个文件或多个文件。可以通过在rm命令之后指定文件的名字,或者使用星号 (*) 和问号 (?) 元字符,同时删除几个文件。在Linux系统中删除的文件是永远被删除了,除非使用图形界面删除文件,它们才能够被恢复。rm命令可以带 –i (交互) 选项使用,它在删除文件之前会提示用户。使用rm -i命令作为防范,避免误删文件:
rm [-i] filename (s)
1) 使用rm命令删除早先在practice目录中创建的newfile文件,应该使用什么命令?
rm -r practice/newfile
2) 输入命令显示practice目录中文件的长列表。创建的文件还在吗?
不在
3) 使用带 -i选项的rm命令,删除早先在practice目录中创建的filenew文件。交互式选项起到什么作用?
在删除之前提醒用户,避免误删文件
4) 删除早先创建的三个名为new1、new2和new3的文件。使用问号 (?) 通配符使用一个命令删除所有三个文件。使用什么命令?
rm new?
5) 输入命令,显示practice目录中文件的长列表。三个文件还在吗?
不在
6) 还有其他的什么方法来删除new1、new2和new3文件?
Rm new[1-3]
步骤18:使用rm -r命令删除目录。
rm -r目录用于删除目录。它将删除从目标目录开始的目录,包括所有的子目录和文件。当rm命令带 -r信息使用的时候,它可以删除单个目录 (空或不空) 或目录树的整节。rm命令可以带 -i选项使用,它在删除目录之前会提醒用户:
rm –r [i] directory_name (s)
1) 删除早先创建的newdir子目录,使用什么命令?
rm-ri practice/newdir
2) 输入命令显示practice目录中文件的长列表,创建的子目录还在吗?
不在
3) 改变到早先创建的mediurn子目录中,输入什么命令?
cd practice/medium
4) 删除早先创建的low子目录,使用什么命令?
rm-ri practice/low
5) 用相对路径名和快捷方式,改变回到practice子目录中,应使用什么命令?
cd
6) 使用一个命令删除high和medium子目录,应使用什么命令?
rm-ri high medium
步骤19:练习所学习到的内容。
通过在practice目录中创建一个三级的目录树,练习使用touch、mkdir和rm命令。试着使用有意义的目录名。记住可以使用一个命令创建整个目录结构。在每个目录中创建多个文件。记住可以使用一个命令创建多个文件。
结束的时候,请删除实验时创建的文件和目录。
步骤20:关闭终端窗口,注销。
四、实验总结
请总结操作系统的作用有哪些?操作系统提供给用户的接口方式有哪些?各有什么特点?本实验中接触到哪些接口方式?
1、操作系统主要起一个全局的协调作用。既能控制大到程序与I/O设备请求的响应,也能处理小到一个文件的打开或关闭的请求。操作系统有处理机管理、内存管理、设备管理、文件管理和用户接口管理五个主要的功能。它可以控制管理计算机的全部硬软件资源,合理组织计算机内部各部件协调工作,为用户提供操作和编辑界面的程序集合。
2、接口方式:系统调用接口、命令行接口和图形用户接口。
命令行接口:包括联机命令行接口(识别用户在控制台或终端输入的命令,解释并执行该命令)和脱机命令行接口(用户利用作业控制语言书写作业控制语句,输入到系统中,控制计算机系统执行相应动作)。命令行接口的使用,对普罗大众存在一定的门槛,全是黑屏的代码也不如图形界面给用户的观感好,命令行接口方式中的命令众多,普通用户难以记忆,使用时感到不方便。
系统调用接口:用户很少直接用到,由一组系统调用组成,每个系统调用是一个完成特定功能的子程序。用户编写的程序可以直接调用这些子程序,由操作系统代为实现用户程序的部分功能。
图形命令接口:对出现在屏幕上的对象直接进行单击、双击、拖拽等操作,以控制和操纵程序的运行。简单直观,大大减轻甚至免除了用户记忆各种命令的负担,极大的方便了用户。
3、本实验中接触到了命令行接口、系统调用接口和图形用户接口。
实验二 观察Linux进程状态
- 实验目的
在本实验中学习Linux操作系统的进程状态,并通过编写一些简单代码来观察各种情况下,Linux进程的状态,进一步理解进程的状态及其转换机制。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境:Linux Ubuntu操作系统,gcc编译器。
三、实验内容和步骤
1、Linux进程状态及其相互转换
Linux中,进程有以下6中状态。
Linux系统中的进程主要有以下六种状态。
(1)TASK_RUNNING(可运行状态)。正在运行的进程或在可运行进程队列(run_queue)中等待运行的进程处于该状态。它实际上包含一般操作系统原理教材中所谓进程三种基本状态中的运行态和就绪两种状态。
当CPU空闲时,进程调度程序只在处于该状态的进程中选择优先级最高的进程运行。Linux中运行态的进程可以进一步细分为3种:内核运行态、用户运行态和就绪态。
(2)TASK_INTERRUPTIBLE(可中断阻塞状态)。处于可中断阻塞状态的进程排成一个可中断阻塞状态进程队列,该队列中的阻塞进程在资源有效时,能被信号或中断唤醒进入到运行态队列。
(3)TASK_UNINTERRUPTIBLE(不可中断阻塞状态)。不可中断指的是进程不响应信号。处于不可中断阻塞状态的进程排成一个不可中断阻塞状态进程队列。该队列中的阻塞进程,不可被其他进程唤醒,只有被使用wake_up()函数明确唤醒时才能转换到可运行的就绪状态。
(4)TASK_STOP/TASK_TRACED(暂停状态)。当进程收到信号SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU时就会进入暂停状态。可向其发送SIGCONT信号,让进程转换到可运行状态。
(5)TASK_DEAD-EXIT_ZOMBIE(僵死状态)。表示进程停止但尚未消亡的一种状态。此时进程已经结束运行并释放掉大部分资源,但父进程尚未收回其PCB。在进程退出时,将状态设为TASK_ZOMBIE,然后发送信号给父进程,由父进程再统计其中的一些数据后,释放它的task_struct结构。处于该状态的进程已经终止运行,但是父进程还没有询问其状态。
(6)TASK_DEAD-EXIT_DEAD(退出状态),处于此状态的进程即将被销毁,EXIT_ DEAD非常短暂,几乎不可能通过ps命令捕捉到。
Linux中进程的状态转换过程如下图所示:
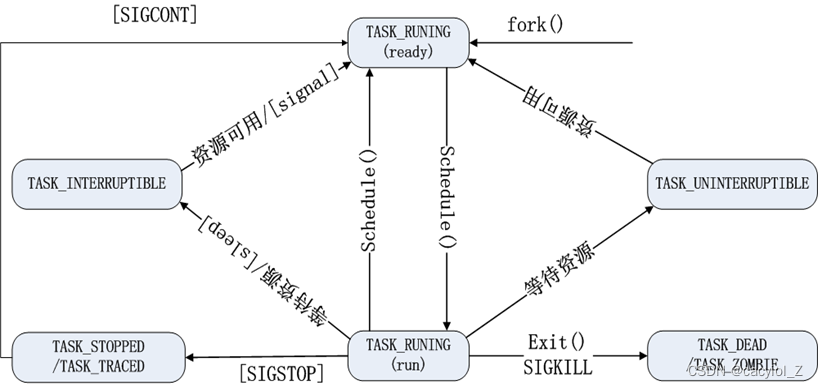
可以使用ps命令查看进程在系统中的状态。在ps命令的显示结果中,5中字符分别代表5种不同的进程状态。
(1)R(TASK_RUNNING):可执行状态或运行状态
(2)S(TASK_INTERRUPTIBLE):可中断阻塞状态,可响应中断、接收信号(如SIGKILL)
(3)D( TASK_ UNINTERRUPTIBLE):不可中断阻塞状态,只能响应中断
(4)T( TASK_ STOPPED/ TASK_ TRACED):暂停状态或跟踪状态
(5)Z( TASK_ DEAD/EXIT_ZOMBIE):退出状态,进程成为僵尸进程
注:在状态字符后面如果带+(如S+),表示进程是前台运行,否则是后台运行。
2 观察进程状态
(一)查看“运行”状态(R)
创建一个C程序,如run_status.c,运行一段长循环,
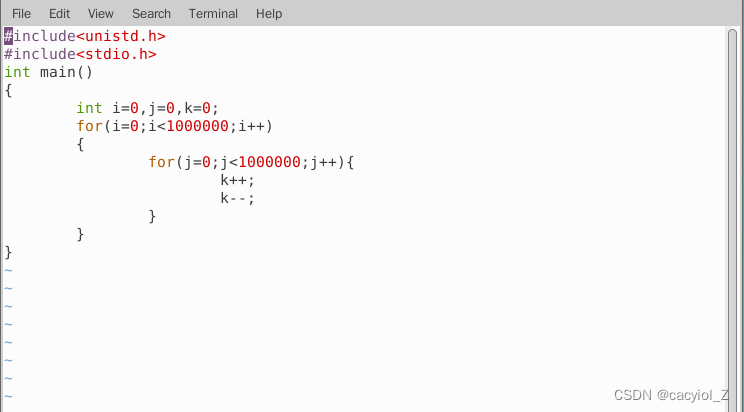
编译链接,后台运行该程序(后接&),并使用ps命令查看 。
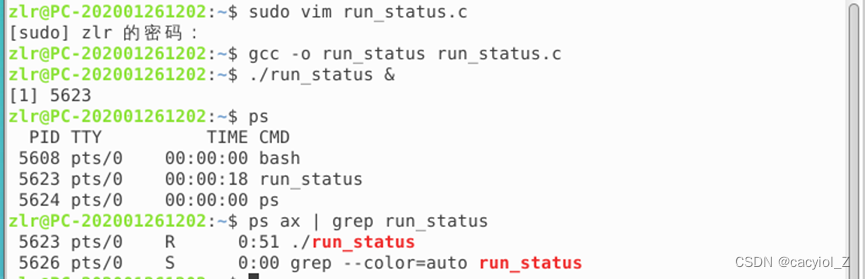
(二)查看“暂停”状态(T)
运行run_status进程,其进入R状态:

使用kill命令,向run_status进程发送SIGSTOP信号,并使用ps命令观察其状态(进入了T状态)
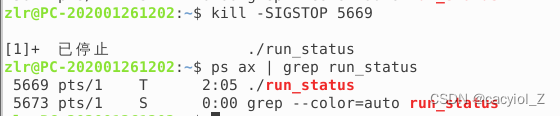
使用kill命令,向run_status进程发送SIGSCON信号,并使用ps命令观察其状态(恢复到R状态)

(三)查看“可中断阻塞”状态(S)
创建一个C程序,如interruptiblie_status.c,让其睡眠30s

编译链接,后台运行该程序(后接&符号),并使用ps命令查看运行状态。
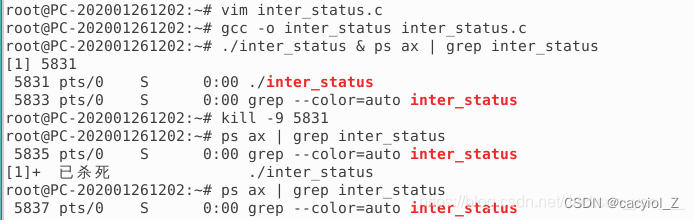
(四)查看“不可中断阻塞”状态(D)
创建一个C程序,如uninter_status.c,让其睡眠30s

编译链接,后台运行该程序(后接&),并使用ps命令查看运行状态
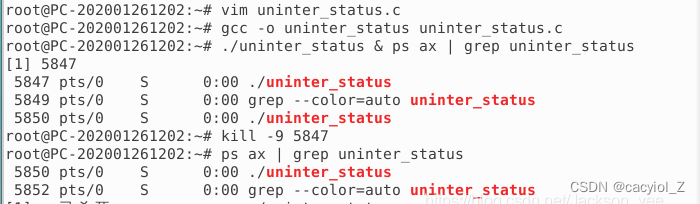
(五)查看“僵尸”进程(Z)
创建一个C程序,如zombie_status.c,在其中创建一个子进程,并让子进程迅速结束,而父进程陷入阻塞

注:父进程进入S状态,子进程进入Z状态。
编译链接,后台运行该程序(后接&),并使用ps命令查看运行状态(30s内)

请写出程序代码及实验结果。实验者也可以不参照前面代码写,但要贴出实验结果。
四、实验总结
分析为什么出现以上现象,并对其进行总结:什么时候出现运行状态、暂停状态、可中断阻塞状态、不可中断阻塞状态、僵尸状态?
1、在查看运行状态的实验中,该进程在0:51时获得CPU正在运行,处于R状态。在查看暂停状态时,进程一开始处于R状态,由于向其发送了SIGSTOP信号,所以转为T状态,后来又向其发送了SIGSCON信号,进程又转为R状态。在查看可中断阻塞状态时,进程一开始处于S状态,由于使用了kill命令,进程被中断。在查看不可中断阻塞状态时,进程一开始处于D状态,使用了kill命令,但进程并没有被中断。在查看僵尸进程时,子进程迅速结束,进入Z状态,而父进程陷入阻塞,进入S状态。
2、出现各种状态的情况:
(1)可运行状态R:当创建一个新进程,系统调用创建原语,该进程为就绪状态,或者进程执行唤醒原语,把处于阻塞状态进程的状态改为就绪状态,或者进程获得CPU正在运行,处于执行状态。
(2)可中断阻塞状态S:进程调用阻塞原语把状态改为阻塞状态,在资源有效时,能被信号或中断唤醒进入到运行态队列。
(3)不可中断阻塞状态D:进程调用阻塞原语把状态改为阻塞状态,不可被其他进程唤醒,只有被使用wake_up()函数明确唤醒时才能转换到可运行的就绪状态。
(4)暂停状态T:由一些特别的信号量控制。当进程收到信号SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU时就会进入暂停状态。可向其发送SIGCONT信号,让进程转换到可运行状态。
(5)僵死状态Z:表示进程停止但尚未消亡的一种状态。此时进程已经结束运行并释放掉大部分资源,但父进程尚未收回其PCB。
实验三 观察Linux进程/线程的异步并发执行
一、实验目的
通过本实验学习如何创建Linux进程及线程,通过实验,观察Linux进程及线程的异步执行。理解进程及线程的区别及特性,进一步理解进程是资源分配单位,线程是独立调度单位。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境:Linux Ubuntu操作系统,gcc编译器。
三、实验内容和步骤
1、进程异步并发执行
1)编写一个C语言程序,该程序首先初始化一个count变量为1,然后使用fork函数创建两个子进程,每个子进程对count加1后,显示“I am son, count=x”或“I am daughter, count=x”,父进程对count加1之后,显示“I am father, count=x”,其中x使用count值代替。最后父进程使用waitpid等待两个子进程结束之后退出。
编译连接后,多次运行该程序,观察屏幕上显示结果的顺序性,直到出现不一样的情况为止,并观察每行打印结果中count的值。
参考程序(实验者也可以自己设计类似程序)
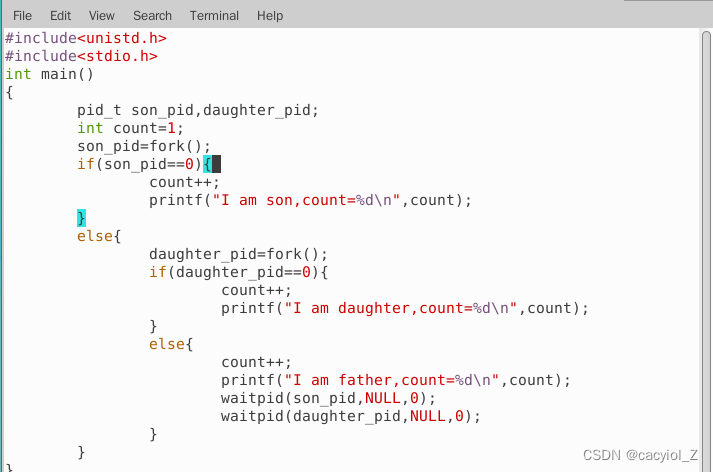
2)如果我们把上面的程序做如下修改:

运行以上这个程序,截图给出该程序的运行结果。并给出此结果的原因。

2、线程异步并发执行
编写一个C语言程序,该程序首先初始化一个count变量为1,然后使用pthread_create函数创建两个线程,每个线程对count加1后,显示“I am son, count=x”或“I am daughter, count=x”,父进程对count加1之后,显示“I am father, count=x”,其中x使用count值代替。最后父进程使用pthread_join等待两个线程结束之后退出。
编译连接后,多次运行该程序,观察屏幕上显示结果的顺序性,直到出现不一样的情况为止,并观察每行打印结果中count的值。
参考程序(实验者亦可以自己设计类似程序)
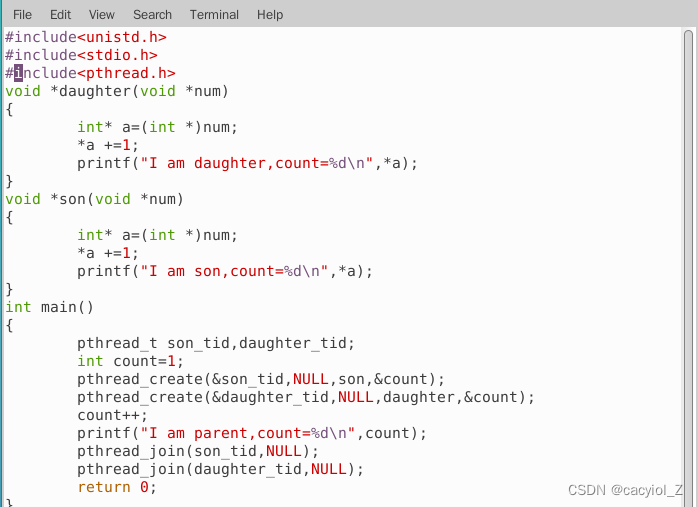


四、实验总结
观察两个实验结果中count值的变化,分析父进程和子进程两者之间的关系以及主线程和子线程之间的关系,写出进程和线程两者之间的区别。
1、第一个的parent、son、daughter中的count都是从1加1变为2,而在第二个,parent、son和daughter中的count是在进程中共享的,先是在son中count加1变为2,然后parent中count又加1变为3,然后daughter中count又加1变为4。
2、父进程和子进程二者只有继承关系,运行过程是彼此独立的,数据也不会进行交换。同一进程中的所有线程共享所在进程的地址空间和全部资源,但线程间都相互独立的并发执行。
3、区别: ①.线程是进程划分成的更小的执行单位。
②.与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
③.线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。
④.线程执行开销小,但不利于资源的管理和保护;而进程正相反。
实验四 使用信号量进行互斥与同步
一、实验目的
本实验介绍在Linux中使用信号量进行进程同步、互斥的方法。读者可以通过实验进一步理解进程间同步与互斥、临界区与临界资源的概念与含义,并学会Linux信号量的基本使用方法。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境:Linux Ubuntu操作系统,gcc编译器。
三、实验内容和步骤
(一)参考:POSIX以及System V
System V:Unix众多版本中的一支,最初由AT&T定义,目前为第四个版本,其中定义了较为复杂的API。
POSIX:Portable Operating System Interface,IEEE为了统一Unix接口而定义的标准,定义了统一的API接口。Linux即支持System API,又支持POSIX API
(二)Linux提供两种信号量:
内核信号量:用于内核中资源共享控制
用户态信号量:主要包括POSIX信号量和SYSTEM V信号量。其中
POSIX信号量分为两类。
无名信号量:主要用于线程间同步,也可用于进程间(由fork产生)同步。
有名信号量:既可用于进程间同步,也可用于线程间同步。
POSIX有名信号量主要包括:
sem_t* sem_open(const char *name, int oflag, mode_t mode, int value)
-
- name: 文件名路径,如’mysem’,会创建/dev/shm/sem.mysem
- oflag:O_CREATE或O_CREATE | O_EXCL
- O_CREATE:如信号量存在,则打开之,如不存在,则创建
- O_CREATE | O_EXCL:如信号量已存在,则返回error
- mode:信号量访问权限,如0666
- value:信号量初始化值
int sem_wait(sem_t *sem)
-
- 测试指定的信号量的值,相当于P操作
- 若sem > 0,则减1立刻返回;
- 若sem = 0,则睡眠直到sem > 0,此时立刻减1,然后返回
- int sem_post(sem_t *sem)
- 释放资源,相当于V操作
- 信号量sem的值加1
- 唤醒正在等待该信号量的进程/线程
int sem_close(sem_t *sem)
-
- 关闭有名信号量
- 进程中,如果使用完信号量,应使用该函数关闭有名信号量
- int sem_unlink(const char *name)
- 删除系统中的信号量
如果有任何进程/线程引用这个信号量,sem_unlink函数不会起到任何作用,即只有最后一个使用该信号量的进程来执行sem_unlink才有效。
(三)实验步骤
step1:通过实例查看不使用互斥时的情况 (假设文件命名为no_sem.c)
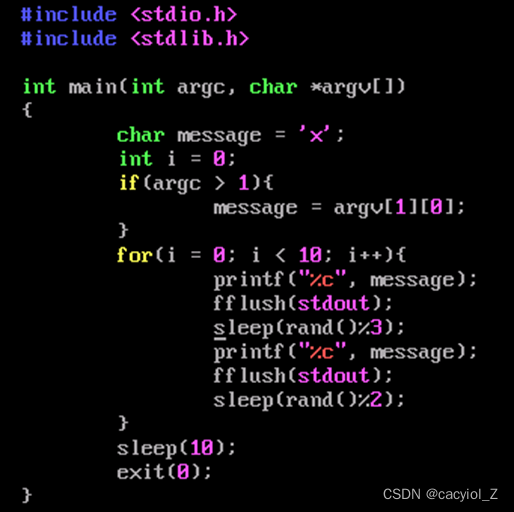
编译链接,同时运行两个进程,显示结果

观察X和O的出现规律,并分析原因。
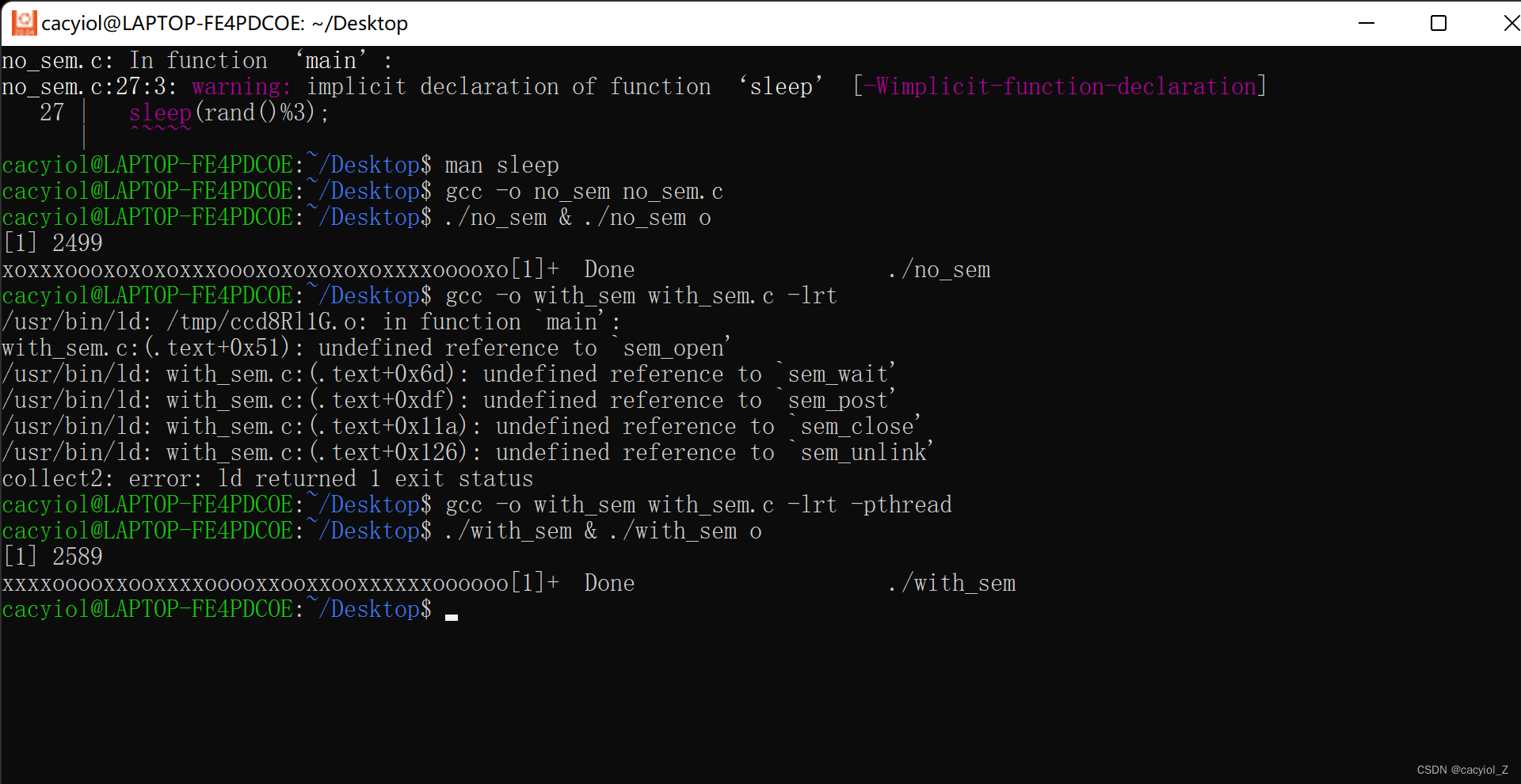
出现无规律,因为两个进程并发执行,并没有进行互斥同步
step2:使用信号量来对临界资源进行互斥 (假设文件命名为with_sem.c)
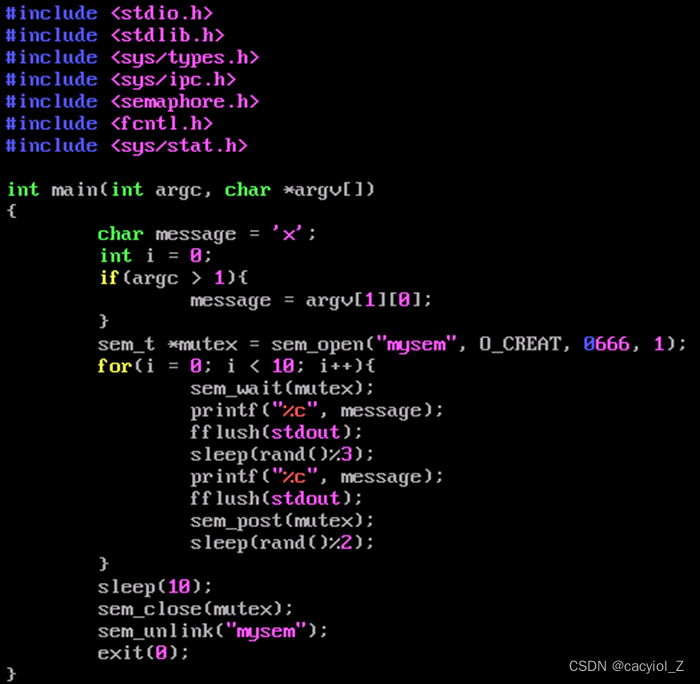
编译链接,同时运行两个进程。

观察X和O的出现规律,并分析原因。
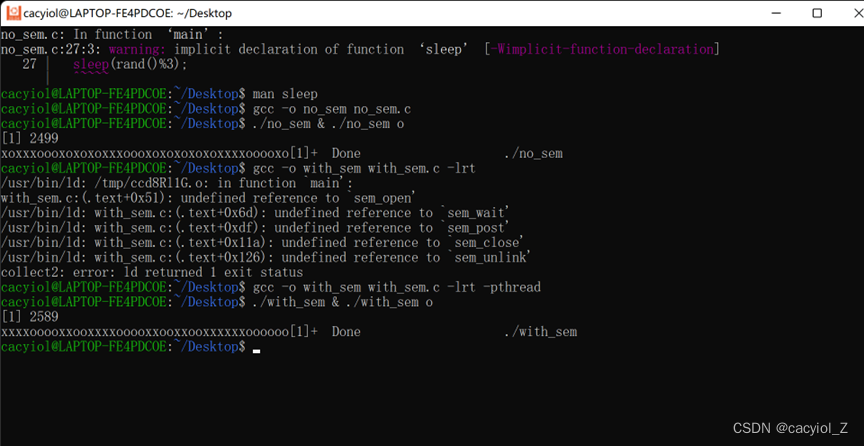
一定是偶数个X后跟着相同偶数个的O,因为在循环开始应用了信号量,进行了互斥,即使在输出第二个字符前sleep但是信号量没有释放,则第二个进程也不能输出,第二个进程阻塞,只有当输出偶数个X后,执行了V操作才能允许第二个进程输出。这样就造成了只有偶数个的情况。
step3:使用信号量来模拟下象棋红黑轮流走子的情况
编写两个C语言程序black_chess.c以及red_chess.c,分别模拟下象棋过程中红方走子和黑方走子过程。走子规则:红先黑后,红、黑双方轮流走子,到第10步,红方胜,黑方输。
编程思路:
设置一下两个同步信号量。
(1)hei:初值为1,代表黑方已经走子,轮到红方走子(满足棋规“红先黑后”)。
(2)hong: 初值为0,代表红方尚未走子。
红棋走子之前,先测试信号量hei,判断黑方是否已经走子,如是,则轮到红方走子,否则阻塞等待黑子走子,有于hei的初值为1,因此一定是红方先走。红方走子完毕后,置信号量hong,通知黑方走子。
黑方走子之前,先测试信号量hong,判断红方是否已经走子,如是,则轮到黑方走子,否则阻塞等待红方走子,由于hong的初值为0,因此在红方没有走子之前,黑方不会走子。黑方走子完毕后,置信号量hei,通知红方走子。
下象棋示例红棋red_chess.c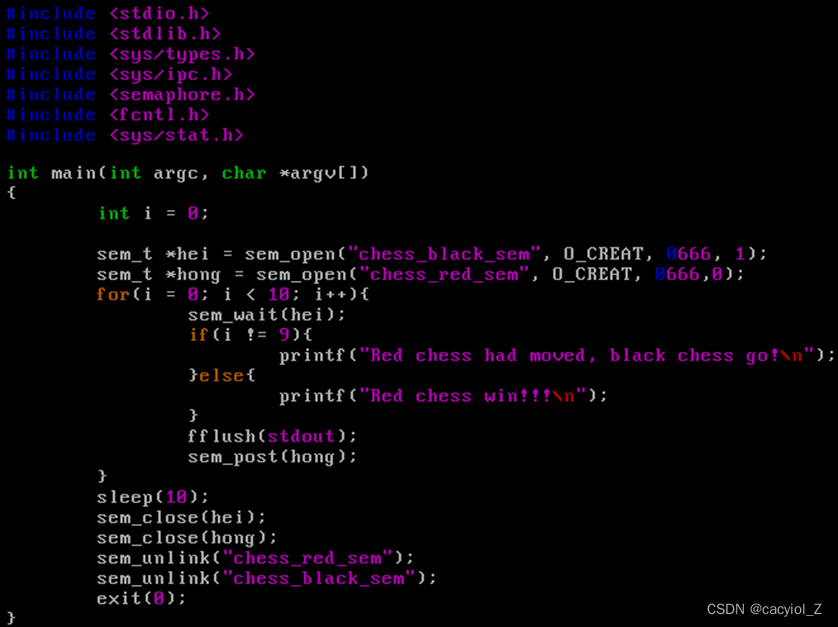
下象棋示例黑棋black_chess.c
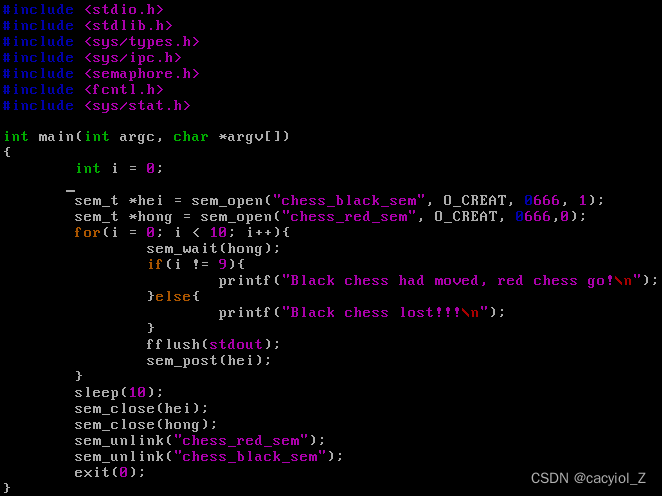
两个进程:红棋和黑棋轮流走子。
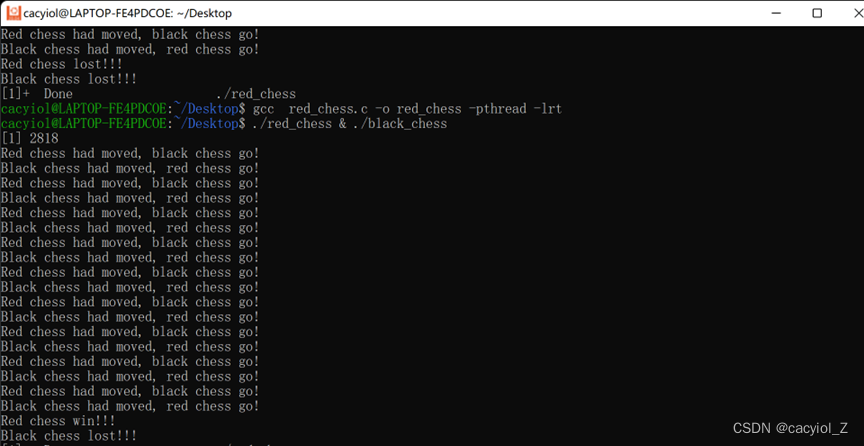
四、实验总结
对程序结果进行分析,并结合操作系统课程中讲授的原理,总结信号量在进程同步和互斥中所起的作用。
防止阻塞,把控进程执行顺序,有效利用资源。信号量<=0时,将阻塞等待其他进程释放资源。这就是在进程互斥的作用。用信号量实现就是在自己下棋前检查对方信号量,是否为1,为1表示已经下了,自己可以下。如果为0 ,表示还没有下,所以应该阻塞等待。在下棋后,将自己的信号量置1,表示自己已经下了,唤醒对方进程。这就是在进程同步的作用。
思考:
(1)对信号量的操作如果没有成对出现,会导致什么现象发生?
(2)用于实现同步、互斥的信号量再出现的位置上各有什么特点?
(3)如果改成“黑先红后” ,红、黑双方轮流走子,到第20步,黑方胜,红方输,如何编程实现?
(1)只有P操作或者只有V操作可能会阻塞进程。
(2)互斥:是在访问临界资源前进行P操作,然后执行V操作
同步:是在程序开始前进行对方信号量的P操作,结束后执行对自己信号量的V操作。
(3)
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <semaphore.h>
int main(int argc, char *argv[])
{
int i = 0;
sem_t *hei = sem_open("chess_black_sem", O_CREAT, 0666, 0);
sem_t *hong = sem_open("chess_red_sem", O_CREAT, 0666, 1);
for (i = 0; i < 20; i++)
{
sem_wait(hei);
if (i != 19)
printf("Red chess had moved, black chess go!\n");
else
printf("Red chess lost!!!\n");
fflush(stdout);
sem_post(hong);
}
sleep(10);
sem_close(hei);
sem_close(hong);
sem_unlink("chess_red_sem");
sem_unlink("chess_black_sem");
exit(0);
}
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ipc.h>
#include <fcntl.h>
#include <semaphore.h>
int main(int argc, char *argv[])
{
int i = 0;
sem_t *hei = sem_open("chess_black_sem", O_CREAT, 0666, 0);
sem_t *hong = sem_open("chess_red_sem", O_CREAT, 0666, 1);
for (i = 0; i < 20; i++)
{
sem_wait(hong);
if (i != 19)
printf("Black chess had moved, red chess go!\n");
else
printf("Black chess win!!!\n");
fflush(stdout);
sem_post(hei);
}
sleep(10);
sem_close(hei);
sem_close(hong);
sem_unlink("chess_red_sem");
sem_unlink("chess_black_sem");
exit(0);
}
gcc red_chess1.c -o red_chess1 -pthread -lrt
gcc black_chess1.c -o black_chess1 -pthread -lrt
./red_chess1 & ./black_chess1
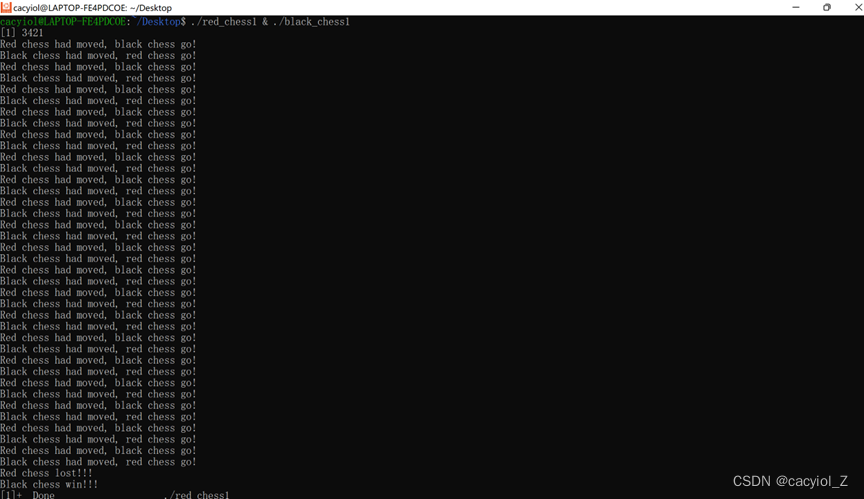
实验五 进程同步问题实现
一、实验目的
利用实验四提供的方法和例子,解决进程同步相关问题,例如:生产者消费者问题,哲学家进餐等问题。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境:Linux Ubuntu操作系统,gcc编译器
三、实验内容
运用实验四中提供的进程同步方法实现如下问题:
1、生产者消费者问题
问题描述:一组生产者进程向一组消费者进程提供产品,两类进程共享一个由n个缓冲区组成的有界缓冲池,生产者进程向空缓冲池中投放产品,消费者进程从放有数据的缓冲池中取得产品并消费掉。
只要缓冲池未满,生产者进程就可以把产品送入缓冲池;只要缓冲池未空,消费者进程便可以从缓冲池中取走产品。
但禁止生产者进程向满的缓冲池再输送产品,也禁止消费者进程从空的缓冲池中提取产品。
为了防止对缓冲池重复操作,故规定在任何时候,只有一个主体可以访问缓冲池。
代码:#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<semaphore.h>
#define PRODUCER_NUM 5 //生产者数目
#define CONSUMER_NUM 5 //消费者数目
#define POOL_SIZE 11//缓冲池大小
int pool[POOL_SIZE]; //缓冲区
int head=0; //缓冲池读取指针
int rear=0; //缓冲池写入指针
sem_t room_sem; //同步信号信号量,表示缓冲区有可用空间
sem_t product_sem; //同步信号量,表示缓冲区有可用产品
pthread_mutex_t mutex;
void *producer_fun(void *arg)
{
while (1)
{
sleep(1);
sem_wait(&room_sem);
pthread_mutex_lock(&mutex);
//生产者往缓冲池中写入数据
pool[rear] = 1;
rear = (rear + 1) % POOL_SIZE;
printf("producer %d write to pool\n", (int)arg);
printf("pool size is %d\n",(rear-head+POOL_SIZE)%POOL_SIZE);
pthread_mutex_unlock(&mutex);
sem_post(&product_sem);
}
}
void *consumer_fun(void *arg)
{
while (1)
{
int data;
sleep(10);
sem_wait(&product_sem);
pthread_mutex_lock(&mutex);
//消费者从缓冲池读取数据
data = pool[head];
head = (head + 1) % POOL_SIZE;
printf("consumer %d read from pool\n", (int)arg);
printf("pool size is %d\n",(rear-head+POOL_SIZE)%POOL_SIZE);
pthread_mutex_unlock(&mutex);
sem_post(&room_sem);
}
}
int main()
{
int i;
pthread_t producer_id[PRODUCER_NUM];
pthread_t consumer_id[CONSUMER_NUM];
pthread_mutex_init(&mutex, NULL); //初始化互斥量
int ret = sem_init(&room_sem, 0, POOL_SIZE-1); //初始化信号量room_sem为缓冲池大小
if (ret != 0)
{
printf("sem_init error");
exit(0);
}
ret = sem_init(&product_sem, 0, 0); //初始化信号量product_sem为0,开始时缓冲池中没有数据
if (ret != 0)
{
printf("sem_init error");
exit(0);
}
for (i = 0; i < PRODUCER_NUM; i++)
{
//创建生产者线程
ret =pthread_create(&producer_id[i], NULL, producer_fun, (void*)i);
if (ret != 0)
{
printf("producer_id error");
exit(0);
}
//创建消费者线程
ret = pthread_create(&consumer_id[i], NULL, consumer_fun, (void*)i);
if (ret != 0)
{
printf("consumer_id error");
exit(0);
}
}
for(i=0;i<PRODUCER_NUM;i++)
{
pthread_join(producer_id[i],NULL);
pthread_join(consumer_id[i],NULL);
}
exit(0); }
操作之前报错解决办法:编译加后缀、部分更改为long型
操作:gcc pv.c -o pv -lpthread
./pv
运行结果:
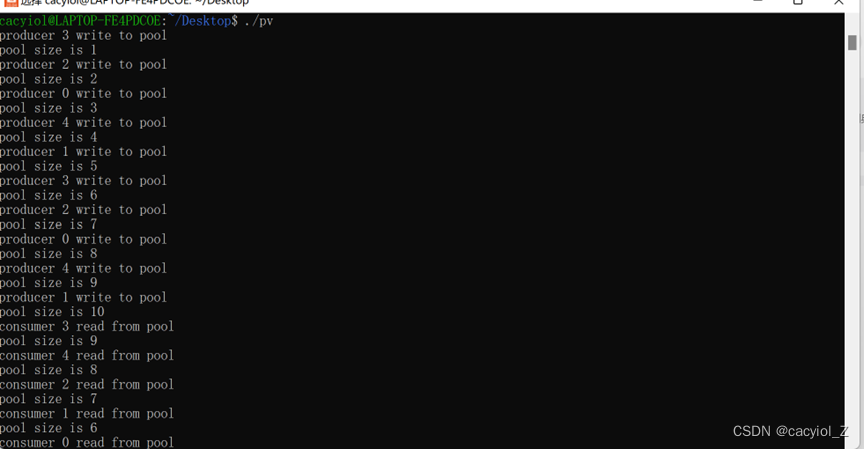
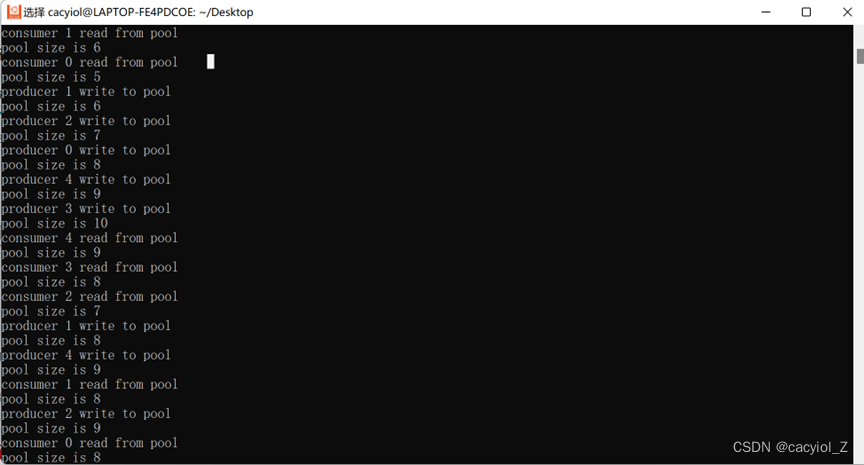
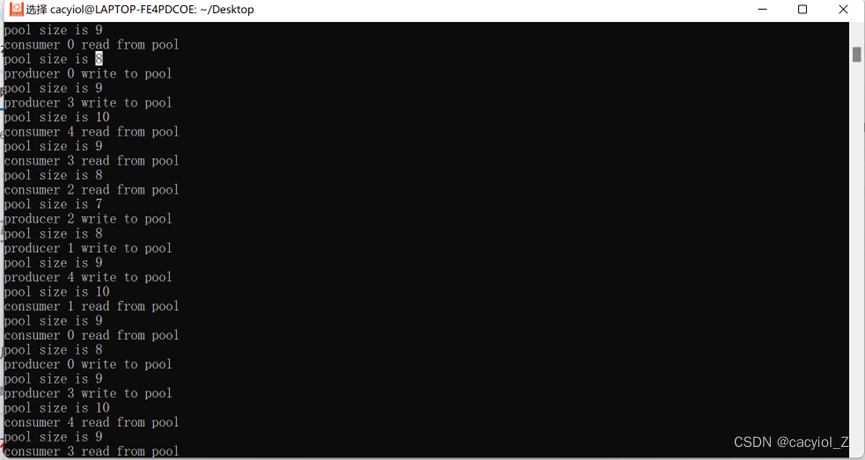
按ctrl+c强制停掉进程
2、哲学家进餐问题
有5位哲学家倾注毕生精力用于思考和吃饭,他们围坐在一张圆桌旁,在圆桌上有5个碗和5支筷子。每位哲学家的行为通常是思考,当其感到饥饿时,便试图取其左右最靠近他的筷子进餐。只有他拿到两支筷子后才能进餐,进餐完毕后,释放两支筷子并继续思考。
要求:采取合适的方法,防止出现死锁的问题。
代码:#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
//规定:只有当哲学接的左右两只筷子均处于可用状态时,才允许他拿起筷子。
//这样可以避免他们同时拿起筷子就餐,导致死锁。
#define N 5 // five philosopher
#define T_EAT 5
#define T_THINK 5
#define N_ROOM 4 //同一时间只允许4人用餐
#define left(phi_id) (phi_id+N-1)%N
#define right(phi_id) (phi_id+1)%N
enum { think , hungry , eat }phi_state[N];
sem_t chopstick[N];
sem_t room;
void thinking(int id){
sleep(T_THINK);
printf("philosopher[%d] is thinking...\n", id);
}
void eating(int id){
sleep(T_EAT);
printf("philosopher[%d] is eating...\n", id);
}
void take_forks(int id){
//获取左右两边的筷子
//printf("Pil[%d], left[%d], right[%d]\n", id, left(id), right(id));
sem_wait(&chopstick[left(id)]);
sem_wait(&chopstick[right(id)]);
//printf("philosopher[%d] take_forks...\n", id);
}
void put_down_forks(int id){
printf("philosopher[%d] is put_down_forks...\n", id);
sem_post(&chopstick[left(id)]);
sem_post(&chopstick[right(id)]);
}
void* philosopher_work(void *arg){
int id = *(int*)arg;
printf("philosopher init [%d] \n", id);
while(1){
thinking(id);
sem_wait(&room);
take_forks(id);
sem_post(&room);
eating(id);
put_down_forks(id);
}
}
int main(){
pthread_t phiTid[N];
int i;
int err;
int *id=(int *)malloc(sizeof(int)*N);
//initilize semaphore
for (i = 0; i < N; i++)
{
if(sem_init(&chopstick[i], 0, 1) != 0)
{
printf("init forks error\n");
}
}
sem_init(&room, 0, N_ROOM);
for(i=0; i < N; ++i){
//printf("i ==%d\n", i);
id[i] = i;
err = pthread_create(&phiTid[i], NULL, philosopher_work, (void*)(&id[i])); //这种情况生成的thread id是0,1,2,3,4
if (err != 0)
printf("can't create process for reader\n");
}
while(1);
// delete the source of semaphore
for (i = 0; i < N; i++)
{
err = sem_destroy(&chopstick[i]);
if (err != 0)
{
printf("can't destory semaphore\n");
}
}
exit(0);
return 0;
}
操作gcc ta.c -o ta -lpthread
./ta
运行结果
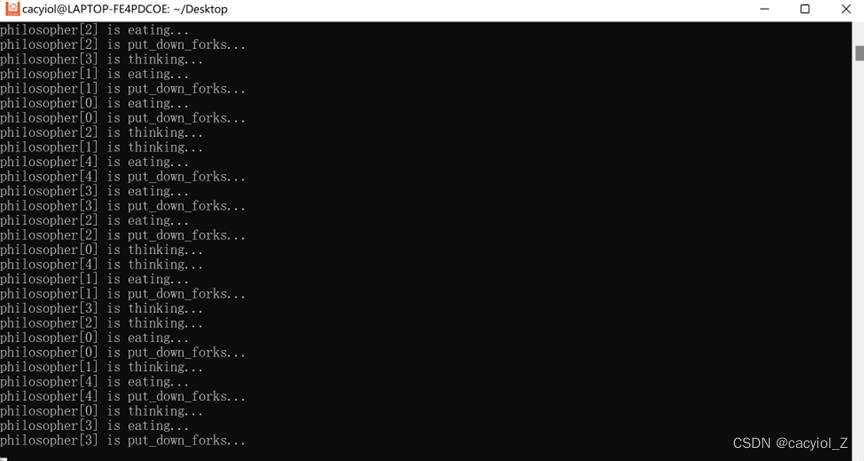
按ctrl+c强制停掉进程
3、和尚打水问题
某寺庙,有小和尚,老和尚若干。有一水缸,由小和尚提水入缸供老和尚饮用。水缸可容10桶水,水取自同一井中。水井径窄,每次中能容下一个桶取水。水桶总数为3个。每人一次取缸水仅为1桶,且不可同时进行。
代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <semaphore.h>
#define P sem_wait
#define V sem_post
#define mutex1 &muteX1
#define mutex2 &muteX2
#define amount &Amount
#define empty &Empty
#define full &Full
#define N 10
sem_t muteX1,muteX2;
sem_t Amount,Empty,Full;
int littleMonkCount= 0;
int BigMonkCount = 0;
int fullcount = 0;
int sum=50;
void* LittleMonk(void *p)
{
while(sum)
{
sum--;
P(empty); //先看水缸里是否满了,没满才能够打水,可以打水的容量-1
littleMonkCount++;
P(amount); //有没有打水桶可以用,有就可以继续打水,可用水桶-1
P(mutex1); //没有其他人打水才能打水
//井边提水
printf("第%d个小和尚在水井提水\n",littleMonkCount);
V(mutex1); //打完水后释放资源
P(mutex2); //回到水缸旁等待倒水,如果此时没有其他小和尚倒水和大和尚取水,即可倒水
//小和尚在水缸旁提水
printf("水缸已有%d桶水,第%d个小和尚在水缸旁倒水\n",fullcount,littleMonkCount);
fullcount++;
V(mutex2); //倒完水后走开
V(amount); //放下水桶,可用水桶+1
littleMonkCount--;
V(full); //水缸里水的桶数加1
}
}
void* BigMonk(void *p)
{
int myFull;
while(sum)
{
sum--;
P(full); //如果有水缸里水,大和尚就找水桶准备打水,没有则在旁边等候
BigMonkCount++;
P(amount); //大和尚看到有水了去拿水桶,没有水桶则等待
P(mutex2); //水缸旁有人则等待,没有则开始打水
printf(" 水缸已有%d桶水,第%d个大和尚在水缸旁提水\n",fullcount,BigMonkCount);
fullcount--;
V(mutex2); //大和尚提完水后离去
V(amount); //放下水桶
BigMonkCount--;
V(empty); //可以打水的数量+1
}
}
int main()
{
int i,j;
//初始化资源个数
sem_init(mutex1, 0, 1); //互斥锁默认为1
sem_init(mutex2,0,1); //互斥锁默认为1
sem_init(amount,0,3); //开始时有3个水桶供使用
sem_init(full,0,0); //开始时水缸里没有水,设置为0
sem_init(empty,0,10); //开始时水缸里最多能装10桶水,设置为10
//创建多个大和尚进程
for(i=1;i<=4;i++){
pthread_t i;
pthread_create(&i, NULL,BigMonk, NULL);
}
//创建多个小和尚进程
for(j=1;j<=10;j++){
pthread_t j;
pthread_create(&j, NULL,LittleMonk, NULL);
}
//观察结果后关闭进程
getchar();
pthread_exit(0);
return 0;
}
gcc heshang.c -o heshang -lpthread
./heshang
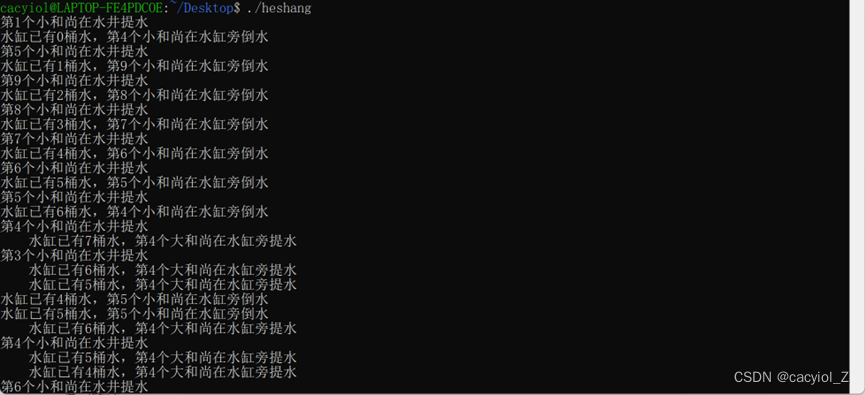
按ctrl+c强制停掉进程
四、实验报告要求:
(1)给出编写的代码,贴出试验结果。
如上所示
(2)结合实验,谈谈你对进程同步的理解和体会。
进程同步是一个操作系统级别的概念,是在多道程序的环境下,存在着不同的制约关系,先进行A才能进行B,或者需要A和B都成功执行才能进行下一步。为了协调这种互相制约的关系,实现资源共享和进程协作,从而避免进程之间的冲突,引入了进程同步。进程同步的主要任务:防止阻塞,通过设置信号量、互斥锁等对多个相关进程在执行次序上进行协调,以使并发执行的诸进程之间 能有效地共享资源和相互合作,从而使程序的执行具有可再现性。
实验六 作业调度算法模拟
- 实验目的
(1)掌握周转时间、等待时间、平均周转时间等概念及其计算方法。
(2)理解五种常用的进程调度算法(FCFS、SJF、HRRF、HPF、RR),区分算法之间的差异性,并用C语言模拟实现各算法。
(3)了解操作系统中高级调度、中级调度和低级调度的区别和联系。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境:Windows或Linux操作系统,C语言编程环境。
三、实验内容和步骤
(一)实验说明
1.基本概念
程序:程序是指静态的指令集合,它不占用系统的运行资源,可以长久地保存在磁盘中。
进程:进程是指进程实体(由程序、数据和进程控制块构成)的运行过程,是系统进行资源分配和调度的一个独立单位。进程执行程序,但进程与程序之间不是一一对应的。通过多次运行,一个程序可以包含多个进程;通过调用关系,同一进程可以被多个程序包含(如一个DLL文件可以被多个程序运用)。
作业:作业由一组统一管理和操作的进程集合构成,是用户要求计算机系统完成的一项相对独立的工作。作业可以是完成了编译、链接之后的一个用户程序,也可以是各种命令构成的一个脚本。
作业调度:作业调度是在资源满足的条件下,将处于后备状态的作业调入内存,同时生成与作业相对应的进程,并为这些进程提供所需要的资源。作业调度适用于多道批处理系统中的批处理作业。根据作业控制块中的信息,检查系统是否满足作业的资源要求,只有在满足作业调度的资源需求的情况下,系统才能进行作业调度。
2. 基本调度算法
1)先来先服务(First-Come First-Served,FCFS)调度算法
先来先服务调度算法遵循按照进入后备队列的顺序进行调度的原则。该算法是一种非抢占式的算法,是到目前为止最简单的调度算法,其编码实现非常容易。该算法仅考虑了作业到达的先后顺序,而没有考虑作业的执行时间长短、作业的运行特性和作业对资源的要求。
2)短作业优先(Shortest-Job-First,SJF)调度算法
短作业优先调度算法根据作业控制块中指出的执行时间,选取执行时间最短的作业优先调度。本实验中规定,该算法是非抢占式的,即不允许立即抢占正在执行中的长进程,而是等当前作业执行完毕再进行调度。
3)响应比高者优先(HRRF)调度算法
FCFS调度算法只片面地考虑了作业的进入时间,短作业优先调度算法考虑了作业的运行时间而忽略了作业的等待时间。响应比高者优先调度算法为这两种算法的折中。响应比为作业的响应时间与作业需要执行的时间之比。作业的响应时间为作业进入系统后的等待时间与作业要求处理器处理的时间之和。
4)优先权高者优先(Highest-Priority-First,HPF)调度算法
优先权高者优先调度算法与响应比高者优先调度算法十分相似,根据作业的优先权进行作业调度,每次总是选取优先权高的作业优先调度。作业的优先权通常用一个整数表示,也叫优先数。优先数的大小与优先权的关系由系统或者用户规定。优先权高者优先调度算法综合考虑了作业执行时间和等待时间的长短、作业的缓急度,作业对外部设备的使用情况等因素,根据系统设计目标和运行环境而给定各个作业的优先权,决定作业调度的先后顺序。
本实验所选用的调度算法均默认为非抢占式调度。
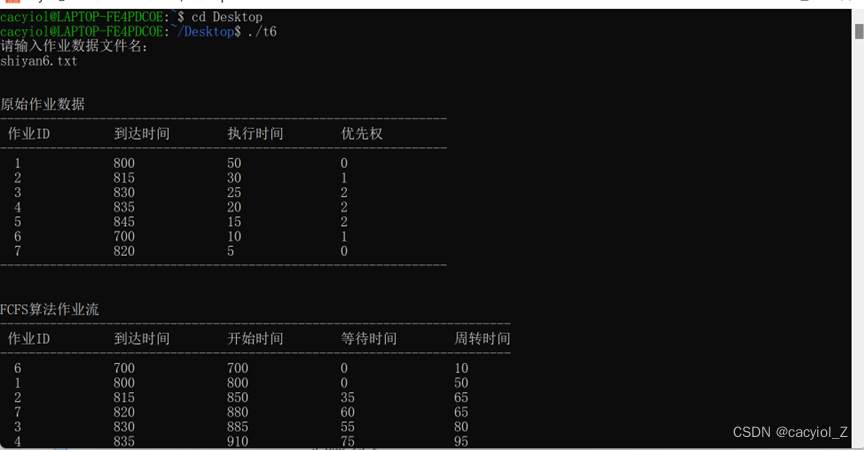
实验所用的测试数据如下表所示。
本实验所用的测试数据如下表所示
表 实验测试数据
| 作业Id | 到达时间 | 执行时间 | 优先权 |
| 800 | 50 | 0 | |
| 2 | 815 | 30 | 1 |
| 3 | 830 | 25 | 2 |
| 4 | 835 | 20 | 2 |
| 5 | 845 | 15 | 2 |
| 6 | 700 | 10 | 1 |
| 7 | 820 | 5 | 0 |
作业的数据结构:
typedef struct node
{
int number; // 作业号
int reach_time;// 作业抵达时间
int need_time;// 作业的执行时间
int privilege;// 作业优先权
float excellent;// 响应比
int start_time;// 作业开始时间
int wait_time;// 等待时间
int visited;// 作业是否被访问过
bool isreached;// 作业是否已经抵达
}job;
重要函数说明
void initial_jobs()
初始化所有作业信息
void reset_jinfo()
重置所有作业信息
int findminjob(job jobs[],int count)
找到执行时间最短的作业。输入参数:所有的作业信息及待查找的作业总数,输出为执行时间最短的作业id
int findrearlyjob(job jobs[],int count)
找到达到最早的作业 输入参数:所有的作业信息及待查找的作业总数,输出参数为最早达到的作业id
void readJobdata()
//读取作业的基本信息
void FCFS()
//先来先服务算法
void SFJschdulejob(job jobs[],int count)
//短作业优先算法 输入参数:所有的作业信息及待查找的作业总数
(二)实验内容
运行程序参考代码(如下所示)
#define _CRT_SECURE_NO_DEPRECATE
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAXJOB 50
typedef struct node
{
int number;
int reach_time;
int need_time;
int privilege;
float excellent;
int start_time;
int wait_time;
int visited;
}job;
job jobs[MAXJOB];
int quantity;
//初始化作业
void initial_jobs()
{
int i;
for (i = 0; i < MAXJOB; i++)
{
jobs[i].number = 0;
jobs[i].reach_time = 0;
jobs[i].privilege = 0;
jobs[i].excellent = 0;
jobs[i].start_time = 0;
jobs[i].wait_time = 0;
jobs[i].visited = 0;
}
quantity = 0;
}
//读取作业信息并输出
void readJobdata()
{
FILE* fp;
char fname[20];
int i;
printf("请输入作业数据文件名:\n");
scanf("%s", fname);
if ((fp = fopen(fname, "r")) == NULL)
{
printf("错误!文件打开失败,请检查\n");
}
else
{
while (!feof(fp))
{
if (fscanf(fp, "%d %d %d %d", &jobs[quantity].number, &jobs[quantity].reach_time, &jobs[quantity].need_time, &jobs[quantity].privilege) == 4)
quantity++;
}
printf("\n\n原始作业数据\n");
printf("---------------------------------------------------------------\n");
printf(" 作业ID\t\t到达时间\t执行时间\t优先权\n");
printf("---------------------------------------------------------------\n");
for (i = 0; i < quantity; i++)
{
printf(" %-8d\t%-8d\t%-8d\t%-8d\n", jobs[i].number, jobs[i].reach_time, jobs[i].need_time, jobs[i].privilege);
}
printf("---------------------------------------------------------------\n");
}
}
//重置作业信息
void reset_jinfo()
{
int i;
for (i = 0; i < MAXJOB; i++)
{
jobs[i].start_time = 0;
jobs[i].wait_time = 0;
jobs[i].visited = 0;
}
}
//找到最早到达作业,返回地址,全部到达返回-1
int findrearlyjob(job jobs[], int count)
{
int rearlyloc = -1;
int rearlyjob = -1;
for (int i = 0; i < count; i++)
{
if (rearlyloc == -1)
{
if (jobs[i].visited == 0)
{
rearlyloc = i;
rearlyjob = jobs[i].reach_time;
}
}
else if (rearlyjob > jobs[i].reach_time && jobs[i].visited == 0)
{
rearlyjob = jobs[i].reach_time;
rearlyloc = i;
}
}
return rearlyloc;
}
//查找当前current_time已到达未执行的最短作业,若无返回最早到达作业
int findminjob(job jobs[], int count, int current_time)
{
int minjob = -1;
int minloc = -1;
for (int i = 0; i < count; i++)
{
if (minloc == -1)
{
if (jobs[i].reach_time <= current_time && jobs[i].visited == 0)
{
minjob = jobs[i].need_time;
minloc = i;
}
}
else if (minjob > jobs[i].need_time && jobs[i].visited == 0 && jobs[i].reach_time <= current_time)
{
minjob = jobs[i].need_time;
minloc = i;
}
//作业执行时间一样最短,但到达时间不同
else if (minjob == jobs[i].need_time && jobs[i].visited == 0 && jobs[i].reach_time <= current_time && jobs[minloc].reach_time > jobs[i].reach_time)
{
minloc = i;
}
}
if (minloc == -1)
minloc = findrearlyjob(jobs, quantity);
return minloc;
}
//查找当前current_time已到达未执行的最优先作业
int findhighprivilegejob(job jobs[], int count, int current_time)
{
//int t;
int privilegejob = -1;
int privilegeloc = -1;
int privilege = -1;
for (int i = 0; i < count; i++)
{
if (privilegeloc == -1)
{
if (jobs[i].reach_time <= current_time && jobs[i].visited == 0)
{
privilege = jobs[i].privilege;
privilegejob = jobs[i].need_time;
privilegeloc = i;
}
}
else if (privilege < jobs[i].privilege && jobs[i].visited == 0 && jobs[i].reach_time <= current_time)
{
privilege = jobs[i].privilege;
privilegejob = jobs[i].need_time;
privilegeloc = i;
}
else if (privilege == jobs[i].privilege && jobs[i].visited == 0 && jobs[i].reach_time <= current_time && privilegejob > jobs[i].need_time)
{
privilegejob = jobs[i].need_time;
privilegeloc = i;
}
}
if (privilegeloc == -1)
privilegeloc = findrearlyjob(jobs, quantity);
return privilegeloc;
}
//查找当前current_time已到达未执行的响应比最高的作业
int findhrrfjob(job jobs[], int count, int current_time)
{
int hrrfjob = -1;
int hrrfloc = -1;
float responsejob = -1.0;
for (int i = 0; i < count; i++)
{
if (hrrfloc == -1)
{
if (jobs[i].reach_time <= current_time && jobs[i].visited == 0)
{
hrrfjob = jobs[i].need_time;
responsejob = (float)(current_time - jobs[i].reach_time + jobs[i].need_time) / jobs[i].need_time;
hrrfloc = i;
}
}
else if (responsejob < ((float)(current_time - jobs[i].reach_time + jobs[i].need_time) / jobs[i].need_time) && jobs[i].visited == 0 && jobs[i].reach_time <= current_time)
{
responsejob = (float)(current_time - jobs[i].reach_time + jobs[i].need_time) / jobs[i].need_time;
hrrfjob = jobs[i].need_time;
hrrfloc = i;
}
else if (responsejob == ((float)(current_time - jobs[i].reach_time + jobs[i].need_time) / jobs[i].need_time) && jobs[i].visited == 0 && jobs[i].reach_time <= current_time && hrrfjob > jobs[i].need_time)
{
hrrfjob = jobs[i].need_time;
hrrfloc = i;
}
}
if (hrrfloc == -1)
hrrfloc = findrearlyjob(jobs, quantity);
return hrrfloc;
}
void FCFS()
{
int i;
int current_time = 0;
int loc;
int total_waitime = 0;
int total_roundtime = 0;
loc = findrearlyjob(jobs, quantity);
printf("\n\nFCFS算法作业流\n");
printf("------------------------------------------------------------------------\n");
printf(" 作业ID\t\t到达时间\t开始时间\t等待时间\t周转时间\n");
printf("------------------------------------------------------------------------\n");
current_time = jobs[loc].reach_time;
for (i = 0; i < quantity; i++)
{
if (jobs[loc].reach_time > current_time)
{
jobs[loc].start_time = jobs[loc].reach_time;
current_time = jobs[loc].reach_time;
}
else
{
jobs[loc].start_time = current_time;
}
jobs[loc].wait_time = current_time - jobs[loc].reach_time;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time, jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime += jobs[loc].wait_time;
total_roundtime = total_roundtime + jobs[loc].wait_time + jobs[loc].need_time;
loc = findrearlyjob(jobs, quantity);
}
printf("------------------------------------------------------------------------\n");
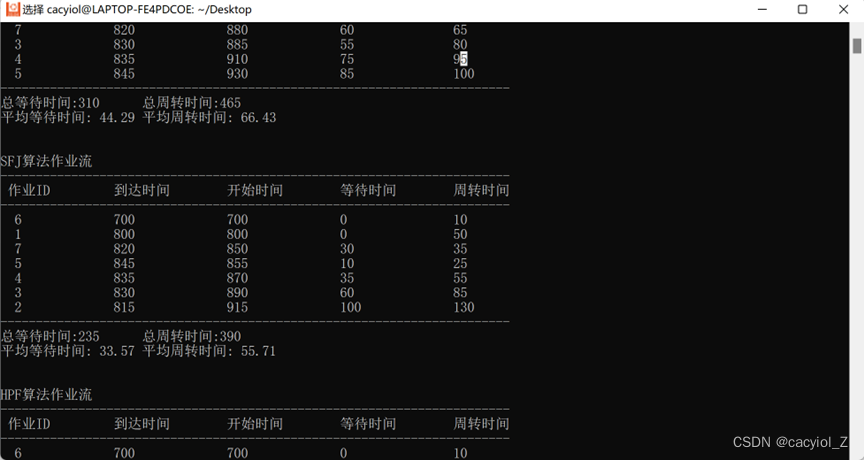
printf("总等待时间:%-8d 总周转时间:%-8d\n", total_waitime, total_roundtime);
printf("平均等待时间: %4.2f 平均周转时间: %4.2f\n", (float)total_waitime / (quantity), (float)total_roundtime / (quantity));
}
void SFJschdulejob(job jobs[], int count)
{
int i;
int current_time = 0;
int loc;
int total_waitime = 0;
int total_roundtime = 0;
loc = findrearlyjob(jobs, quantity);
printf("\n\nSFJ算法作业流\n");
printf("------------------------------------------------------------------------\n");
printf(" 作业ID\t\t到达时间\t开始时间\t等待时间\t周转时间\n");
printf("------------------------------------------------------------------------\n");
current_time = jobs[loc].reach_time;
jobs[loc].start_time = jobs[loc].reach_time;
jobs[loc].wait_time = 0;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time, jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime = 0;
total_roundtime = jobs[loc].need_time;
loc = findminjob(jobs, quantity, current_time);
for (i = 1; i < quantity; i++)
{
if (jobs[loc].reach_time > current_time)
{
jobs[loc].start_time = jobs[loc].reach_time;
current_time = jobs[loc].reach_time;
}
else
{
jobs[loc].start_time = current_time;
}
jobs[loc].wait_time = current_time - jobs[loc].reach_time;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time, jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime += jobs[loc].wait_time;
total_roundtime = total_roundtime + jobs[loc].wait_time + jobs[loc].need_time;
loc = findminjob(jobs, quantity, current_time);
}
printf("------------------------------------------------------------------------\n");
printf("总等待时间:%-8d 总周转时间:%-8d\n", total_waitime, total_roundtime);
printf("平均等待时间: %4.2f 平均周转时间: %4.2f\n", (float)total_waitime / (quantity), (float)total_roundtime / (quantity));
}
void HPF(job jobs[], int count)
{
int i;
int current_time = 0;
int loc;
int total_waitime = 0;
int total_roundtime = 0;
loc = findrearlyjob(jobs, quantity);
printf("\n\nHPF算法作业流\n");
printf("------------------------------------------------------------------------\n");
printf(" 作业ID\t\t到达时间\t开始时间\t等待时间\t周转时间\n");
printf("------------------------------------------------------------------------\n");
current_time = jobs[loc].reach_time;
jobs[loc].start_time = jobs[loc].reach_time;
jobs[loc].wait_time = 0;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time, jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime = 0;
total_roundtime = jobs[loc].need_time;
loc = findhighprivilegejob(jobs, quantity, current_time);
for (i = 1; i < quantity; i++)
{
if (jobs[loc].reach_time > current_time)
{
jobs[loc].start_time = jobs[loc].reach_time;
current_time = jobs[loc].reach_time;
}
else
{
jobs[loc].start_time = current_time;
}
jobs[loc].wait_time = current_time - jobs[loc].reach_time;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time,
jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime += jobs[loc].wait_time;
total_roundtime = total_roundtime + jobs[loc].wait_time + jobs[loc].need_time;
loc = findhighprivilegejob(jobs, quantity, current_time);
}
printf("------------------------------------------------------------------------\n");
printf("总等待时间:%-8d 总周转时间:%-8d\n", total_waitime, total_roundtime);
printf("平均等待时间: %4.2f 平均周转时间: %4.2f\n", (float)total_waitime / (quantity), (float)total_roundtime / (quantity));
}
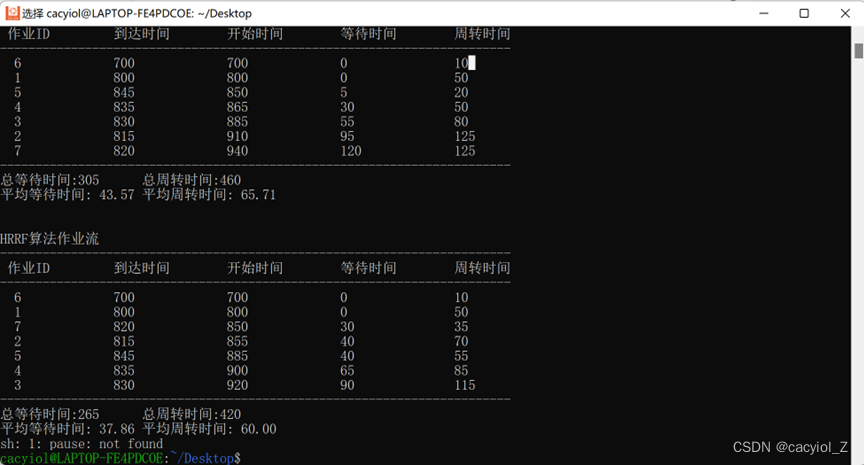
void HRRF(job jobs[], int count)
{
int i;
int current_time = 0;
int loc;
int total_waitime = 0;
int total_roundtime = 0;
loc = findrearlyjob(jobs, quantity);
printf("\n\nHRRF算法作业流\n");
printf("------------------------------------------------------------------------\n");
printf(" 作业ID\t\t到达时间\t开始时间\t等待时间\t周转时间\n");
printf("------------------------------------------------------------------------\n");
current_time = jobs[loc].reach_time;
jobs[loc].start_time = jobs[loc].reach_time;
jobs[loc].wait_time = 0;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time, jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime = 0;
total_roundtime = jobs[loc].need_time;
loc = findhrrfjob(jobs, quantity, current_time);
for (i = 1; i < quantity; i++)
{
if (jobs[loc].reach_time > current_time)
{
jobs[loc].start_time = jobs[loc].reach_time;
current_time = jobs[loc].reach_time;
}
else
{
jobs[loc].start_time = current_time;
}
jobs[loc].wait_time = current_time - jobs[loc].reach_time;
printf(" %-8d\t%-8d\t%-8d\t%-8d\t%-8d\n", loc + 1, jobs[loc].reach_time, jobs[loc].start_time, jobs[loc].wait_time,
jobs[loc].wait_time + jobs[loc].need_time);
jobs[loc].visited = 1;
current_time += jobs[loc].need_time;
total_waitime += jobs[loc].wait_time;
total_roundtime = total_roundtime + jobs[loc].wait_time + jobs[loc].need_time;
loc = findhrrfjob(jobs, quantity, current_time);
}
printf("------------------------------------------------------------------------\n");
printf("总等待时间:%-8d 总周转时间:%-8d\n", total_waitime, total_roundtime);
printf("平均等待时间: %4.2f 平均周转时间: %4.2f\n", (float)total_waitime / (quantity), (float)total_roundtime / (quantity));
}
int main()
{
initial_jobs();
readJobdata();
FCFS();
reset_jinfo();
SFJschdulejob(jobs, quantity);
reset_jinfo();
HPF(jobs, quantity);
reset_jinfo();
HRRF(jobs, quantity);
system("pause");
return 0;
}
要求:
- 通过程序的打印信息来检查作业信息的读入是否正确。
gcc test6.c -o test6
./test6
- 运行FCFS算法,检查其运算结果是否正确
运行情况如题1所示,运行结果正确
3、根据下图所示补充短作业优先代码,并计算其等待时间和周转时间。
void SFJschdulejob(job jobs[],int count) //6175432
{
int i;
int current_time = 0;
int total_waitime=0;
int total_roundtime=0;
int loc;
int earlyest = findrearlyjob(jobs,quantity);
loc = findminjob(jobs,jobs[earlyest].reach_time);
//输出作业流
printf("\n\nSFJ算法作业流\n");
printf("------------------------------------------------------------------------\n");
printf("\tjobID\treachtime\tstarttime\twaittime\troundtime\n");
//每次循环找出最短作业作业并打印相关信息e
for(i = 0;i<quantity;i++){
if(jobs[loc].reach_time>current_time){
jobs[loc].start_time = jobs[loc].reach_time;
current_time = jobs[loc].reach_time+jobs[loc].need_time;
jobs[loc].wait_time = 0;
}else{
jobs[loc].start_time = current_time;
jobs[loc].wait_time = current_time-jobs[loc].reach_time;
current_time+=jobs[loc].need_time;
}
printf("\t%-8d\t%-8d\t%-8d\t%-8d\t%-8d\n",jobs[loc].number,jobs[loc].reach_time,jobs[loc].start_time,jobs[loc].wait_time,
jobs[loc].wait_time+jobs[loc].need_time);
total_waitime+=jobs[loc].wait_time;
total_roundtime+=jobs[loc].wait_time+jobs[loc].need_time;
jobs[loc].visited=1;
loc = findminjob(jobs,current_time);
}
printf("总等待时间:%-8d 总周转时间:%-8d\n",total_waitime,total_roundtime);
printf("平均等待时间: %4.2f 平均周转时间: %4.2f\n",(float)total_waitime/(quantity),(float)total_roundtime/(quantity));
}
int updatePrivilege(job jobs[],int current_time){
int next = -1;
int max_privilege = -1;
int i;
while(max_privilege==-1){
for(i = 0;i<quantity&&jobs[i].reach_time<=current_time;i++){
if(jobs[i].visited!=1){
jobs[i].wait_time = current_time-jobs[i].reach_time;
jobs[i].excellent = (double)jobs[i].wait_time/(double)jobs[i].need_time;
if(jobs[i].excellent>max_privilege){
max_privilege = jobs[i].excellent;
next = i;
}
}
}
if(max_privilege==-1){
int early_time=10000,i;
for(i = 0;i<quantity;i++){
if(jobs[i].reach_time<early_time&&jobs[i].reach_time>current_time&&jobs[i].visited!=1){
early_time = jobs[i].reach_time;
next = i;
jobs[i].excellent = (double)jobs[i].wait_time/(double)jobs[i].need_time;
max_privilege = jobs[i].excellent;
}
}
}
}
return next;
}
总等待时间:235 总周转时间:390
平均等待时间:33.57 平均周转时间:55.71

作业调度实验流程图
4、参考以上算法的实现方法,编写高响应比优先算法和优先权高者优先算法。
注:请把以上4个要求的程序实现及运行结果写在实验报告中。
四、实验总结
由四种算法的测试数据来看,算法思想不同,所需的等待时间和周转时间也不同。
表1 算法与等待时间、执行时间、优先级的关系
| 作业调度算法 | 等待时间 | 执行时间 | 优先权 |
| FCFS | √ | ||
| SJF | √ | ||
| HRRF | √ | √ | |
| HPF | √ |
由表1得出FCFS算法仅考虑作业的到达时间,先来先服务,就是说到达时间早的会优先执行;SJF算法主要考虑作业的执行时间,哪个作业需要的执行时间短,就先执行哪个;HRRF算法同时考虑了作业的等待时间和执行时间,是FCFS和SJF算法的折中;HPF算法仅考虑作业的优先权,优先权高者先执行。
我们实验结果中可以发现对测试数据而言,每种算法都有它的最佳适应环境。并非HRRF算法的平均等待时间和平均周转时间最短。对于这组作业,SJF算法的平均等待时间和平均周转时间比 HRRF算法和HPF算法的短,说明最适合这个作业的调度算法是SJF。由此可以得出判断算法的好坏要根据具体的作业,如果对于a作业A算法的平均等待时间和周转时间是最短的,那说明A算法是最适合a作业的调度算法。
请总结一下本次实验的收获、教训和感受,结合课本内容谈一下你对操作系统中各种作业调度算法优缺点的理解。
FCFS算法它只考虑进程进入就绪队列的先后,而不考虑它的下一个CPU周期的长短及其他因素。比较有利于长作业,而不利于短作业,有利于CPU繁忙型作业,而不利于I/O繁忙型作业。并且适于批处理系统,不适于分时系统。
SJF算法可以是抢占的或非抢占的。当一个新进程到达就绪队列而以前进程正在执行时,就需要选择了。新进程的下次 CPU 执行,与当前运行进程的尚未完成的 CPU 执行相比,可能还要小。抢占 SJF 算法会抢占当前运行进程,而非抢占 SJF 算法会允许当前运行进程以先完成 CPU 执行。抢占 SJF 调度有时称为最短剩余时间优先调度。易于实现,照顾了短进程,缩短了短进程的等待时间,体现了短进程优先原则,改善了平均周转时间和平均带权周转时间,有利于提高系统的吞吐量。但是对长进程不利,甚至会导致长进程长时间无法得到关注而使得系统整体性能下降,完全未考虑进程的急迫程度,因而不能保证紧迫性进程会被及时处理,进程的运行时间很难精确估计,进程在运行前不一定能真正做到短进程被优先调度。
HRRF算法最高响应比优先算法是介于先来先服务算法(FCFS)和最短作业优先算法(SJF)之间的一种算法,它既考虑了作业的等待时间,又考虑了作业的处理时间既照顾了短作业又照顾了长作业,同时也照顾了先到达进程。但是调度之前需要计算各个进程的响应比,增加了系统开销,导致对实时进程无法做出及时反映。
HPF算法在进程等待队列中选择优先级最高的来执行。常被用于批处理系统中,还可用于实时系统中。调度灵活,能适应多种调度需求。但是进程优先级的划分和确定每个进程优先级比较困难,同时抢占式调度增加了系统开销。
实验七 动态分区分配方式的模拟
一、实验目的
了解动态分区分配方式中使用的数据结构和分配算法,并进一步加深对动态分区存储管理方式及其实现过程的理解。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境: Windows或Linux操作系统, C语言编程环境。
三、实验内容
1、用C语言分别实现采用首次适应算法和最佳适应算法的动态分区分配过程alloc( )和回收过程free( )。其中,空闲分区通过空闲分区链来管理:在进行内存分配时,系统优先使用空闲区低端的空间。
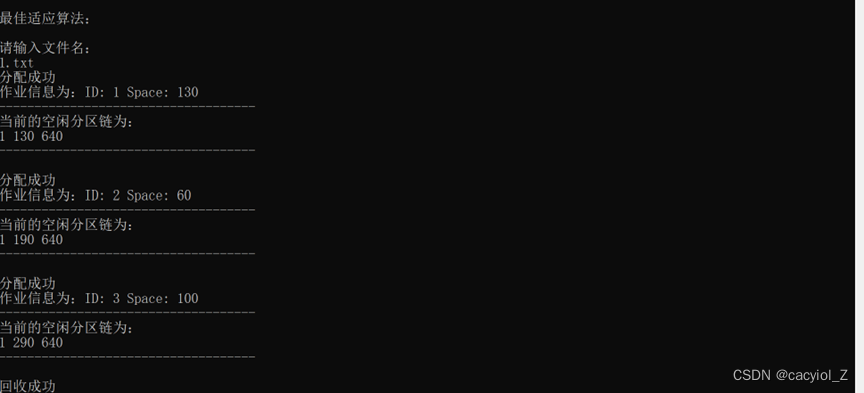
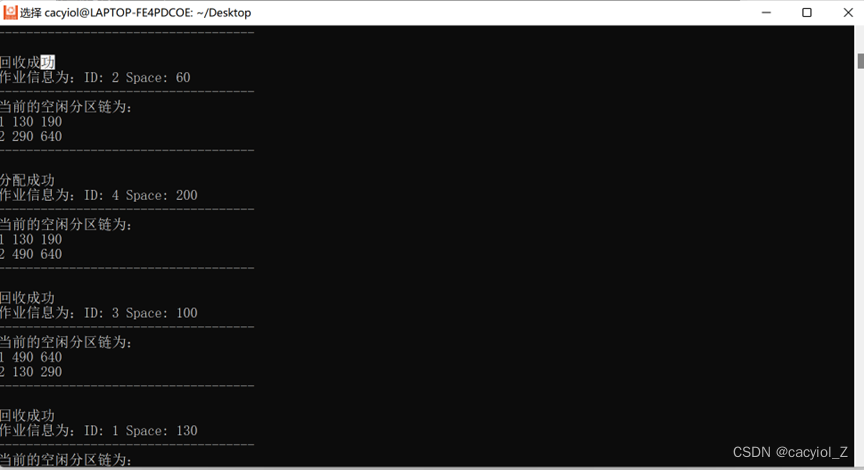
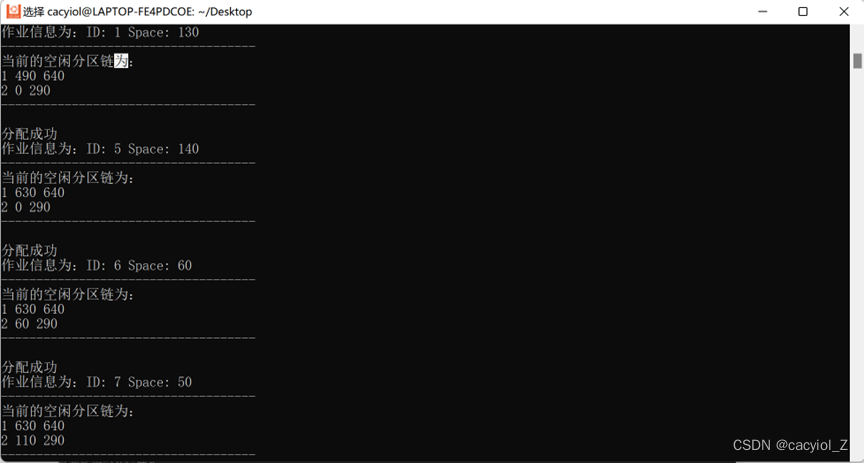
2、假设初始状态下,可用的内存空间为640KB,并有下列的请求序列:
•作业1申请130KB。
•作业2申请60KB。
•作业3申请100KB。
•作业2释放60KB。
•作业4申请200KB。
•作业3释放100KB。
•作业1释放130KB。
•作业5申请140KB。
•作业6申请60KB。
•作业7申请50KB。
•作业6释放60KB。
请分别采用首次适应算法和最佳适应算法,对内存块进行分配和回收,要求每次分配和回收后显示出空闲分区链的情况。
3、实验报告要求:
(1)给出具体的设计过程,贴出相应的代码,截图给出试验结果。
(2)结合实验情况,谈谈你对存储管理的理解和体会。
代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
struct Jobs
{
int jobID;
int addr_start;
int addr_end;
struct Jobs *next;
};
struct Unoccupied_block
{
struct Unoccupied_block *previous;
int addr_start;
int addr_end;
struct Unoccupied_block *next;
};
struct Blocking_queue
{
int jobID;
int space;
struct Blocking_queue *next;
};
struct Jobs *jobhead;
struct Blocking_queue *bqhead;
struct Unoccupied_block *ubhead;
bool empty()
{
// 判断阻塞队列是否为空
if (bqhead->next == NULL)
return true;
return false;
}
// 按照空闲分区的大小从小到大排序
void sort()
{
// 冒泡排序
struct Unoccupied_block *t = ubhead->next;
int length = 0;
// 获得长度
while (t)
{
length++;
t = t->next;
}
t = ubhead->next;
// 冒泡排序的变形算法
for (int i = 0; i < length - 1; i++)
{
for (int j = 0; j < length - i - 1; j++)
{
struct Unoccupied_block *a, *b, *temp;
temp = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
int count = j;
while (count--)
{
t = t->next;
}
a = t;
b = t->next;
if (a->addr_end - a->addr_start > b->addr_end - b->addr_start)
{
temp->addr_start = a->addr_start;
temp->addr_end = a->addr_end;
a->addr_start = b->addr_start;
a->addr_end = b->addr_end;
b->addr_start = temp->addr_start;
b->addr_end = temp->addr_end;
}
t = ubhead->next;
}
}
}
// 按照开始位置排序
void sort2()
{
// 冒泡排序
struct Unoccupied_block *t = ubhead->next;
int length = 0;
// 获得长度
while (t)
{
length++;
t = t->next;
}
t = ubhead->next;
// 冒泡排序的变形算法
for (int i = 0; i < length - 1; i++)
{
for (int j = 0; j < length - i - 1; j++)
{
struct Unoccupied_block *a, *b, *temp;
temp = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
int count = j;
while (count--)
{
t = t->next;
}
a = t;
b = t->next;
if (a->addr_start > b->addr_start)
{
temp->addr_start = a->addr_start;
temp->addr_end = a->addr_end;
a->addr_start = b->addr_start;
a->addr_end = b->addr_end;
b->addr_start = temp->addr_start;
b->addr_end = temp->addr_end;
}
t = ubhead->next;
}
}
}
void Output()
{
struct Unoccupied_block *t = ubhead->next;
int count = 0;
printf("------------------------------------\n");
printf("当前的空闲分区链为:\n");
while (t)
{
count++;
printf("%d %d %d\n", count, t->addr_start, t->addr_end);
t = t->next;
}
printf("------------------------------------\n\n");
}
void InsertJob(struct Jobs newJob)
{
// 找到作业队列队尾,插入信息
// !注意需要分配空间,不能直接使用&newJob,因为它是局部变量,跳出该作用域后自动销毁,直接使用导致不可预料的结果
struct Jobs *t1 = jobhead;
while (t1->next)
t1 = t1->next;
struct Jobs *t = (struct Jobs *)malloc(sizeof(struct Jobs));
t->jobID = newJob.jobID;
t->addr_start = newJob.addr_start;
t->addr_end = newJob.addr_end;
t->next = NULL;
t1->next = t;
}
void InsertBQ(struct Blocking_queue newJob)
{
// 找到阻塞队列队尾,插入作业信息
struct Blocking_queue *t = bqhead;
while (t->next)
t = t->next;
struct Blocking_queue *t2 = (struct Blocking_queue *)malloc(sizeof(struct Blocking_queue));
t2->jobID = newJob.jobID;
t2->space = newJob.space;
t2->next = NULL;
t->next = t2;
}
void DeleteJob(int id, int *start, int *end)
{
// 删除作业链表中的项
struct Jobs *t = jobhead;
while (t->next)
{
if (t->next->jobID == id)
break;
t = t->next;
}
// 保存删除作业的信息
*start = t->next->addr_start;
*end = t->next->addr_end;
t->next = t->next->next;
printf("回收成功\n");
printf("作业信息为:ID: %d Space: %d\n", id, *end - *start);
}
struct Blocking_queue *DeleteBQ(int id)
{
// 删除阻塞队列中指定作业号的项,并且返回删除那一项后面的结点
struct Blocking_queue *t = bqhead;
while (t->next)
{
if (t->next->jobID == id)
break;
t = t->next;
}
t->next = t->next->next;
return t->next;
}
bool Arrange(int newJobID, int newJobSpace, bool blockFlag)
{
// 得到三个队列的第一个有效结点
struct Unoccupied_block *head1 = ubhead->next;
struct Jobs *head2 = jobhead->next;
struct Blocking_queue *head3 = bqhead->next;
// 标记是否分配到空间
bool flag = false;
while (head1)
{
// 这个分区大于要求的大小,则取下一部分分配,此时只需修改链表即可
if (head1->addr_end - head1->addr_start > newJobSpace)
{
printf("分配成功\n");
printf("作业信息为:ID: %d Space: %d\n", newJobID, newJobSpace);
struct Jobs newjob;
newjob.addr_start = head1->addr_start;
newjob.addr_end = newjob.addr_start + newJobSpace;
newjob.jobID = newJobID;
newjob.next = NULL;
InsertJob(newjob);
head1->addr_start += newJobSpace;
flag = true;
break;
}
// 若等于,就需要删除这个空闲分区表项
else if (head1->addr_end - head1->addr_start == newJobSpace)
{
printf("分配成功\n");
printf("作业信息为:ID: %d Space: %d\n", newJobID, newJobSpace);
struct Jobs newjob;
newjob.addr_start = head1->addr_start;
newjob.addr_end = head1->addr_end;
newjob.jobID = newJobID;
newjob.next = NULL;
InsertJob(newjob);
head1->previous->next = head1->next;
flag = true;
break;
}
// 否则,寻找下一项
else
head1 = head1->next;
}
if (!flag)
{
printf("分配失败\n");
printf("作业信息为:ID: %d Space: %d\n", newJobID, newJobSpace);
struct Blocking_queue newJob;
newJob.jobID = newJobID;
newJob.space = newJobSpace;
newJob.next = NULL;
// 若处理的本来就是阻塞队列中的作业,且还没有分配成功,就不需要再次进入阻塞队列
if (!blockFlag)
InsertBQ(newJob);
return false;
}
return true;
}
void Free(int newJobID)
{
// 找到三个链表的有效结点
struct Unoccupied_block *head1 = ubhead->next;
struct Jobs *head2 = jobhead->next;
struct Blocking_queue *head3 = bqhead->next;
// 删除指定作业,并从作业链表中得到作业的信息
int jobAddrStart, jobAddrEnd;
DeleteJob(newJobID, &jobAddrStart, &jobAddrEnd);
// 先按照开始位置排序一遍,这样就允许两个算法共用一个回收函数了
sort2();
struct Unoccupied_block *indexInsert = ubhead;
// 寻找插入位置
while (indexInsert)
{
if (head1 == NULL || head1->addr_start >= jobAddrEnd)
{
// 如果删除的作业的结束位置在第一个表项之前,或无表项,那么就要在头结点后插入,直接赋值结束查找
indexInsert = ubhead;
break;
}
else if (indexInsert->addr_end <= jobAddrStart && (indexInsert->next == NULL || indexInsert->next->addr_start >= jobAddrEnd))
break;
else
indexInsert = indexInsert->next;
}
// 前后无邻接,且是个空表
if (indexInsert->next == NULL)
{
struct Unoccupied_block *newItem = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
newItem->addr_start = jobAddrStart;
newItem->addr_end = jobAddrEnd;
indexInsert->next = newItem;
newItem->previous = indexInsert;
newItem->next = NULL;
return;
}
// 前后无邻接的情况,直接插入表项
if (indexInsert->addr_end < jobAddrStart && indexInsert->next->addr_start > jobAddrEnd)
{
struct Unoccupied_block *newItem = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
newItem->addr_start = jobAddrStart;
newItem->addr_end = jobAddrEnd;
indexInsert->next->previous = newItem;
newItem->next = indexInsert->next;
newItem->previous = indexInsert;
indexInsert->next = newItem;
return;
}
// 前后都邻接
else if (indexInsert->addr_end == jobAddrStart && indexInsert->next->addr_start == jobAddrEnd)
{
indexInsert->addr_end = indexInsert->next->addr_end;
struct Unoccupied_block *t = indexInsert->next;
if (t->next == NULL)
{
indexInsert->next = NULL;
return;
}
t->next->previous = indexInsert;
indexInsert->next = t->next;
return;
}
// 前邻接,修改前面的一项,把它的结束位置修改为释放作业的结束位置
else if (indexInsert->addr_end == jobAddrStart)
{
indexInsert->addr_end = jobAddrEnd;
return;
}
// 后邻接,修改后面的一项,把它的开始位置修改为释放作业的开始位置
else if (indexInsert->next->addr_start == jobAddrEnd)
{
indexInsert->next->addr_start = jobAddrStart;
return;
}
}
void first_fit(bool altype)
{
// 读入文件中的数据,这里假设文件中的数据复合逻辑,比如说,不存在释放还在阻塞队列中作业等非法情况
FILE *fp;
printf("请输入文件名:\n");
char filename[20];
scanf("%s", filename);
if ((fp = fopen(filename, "r")) == NULL)
{
printf("打开文件错误\n");
return;
}
// 初始化三个链表,空闲分区,阻塞队列与已分配空间的作业
jobhead = (struct Jobs *)malloc(sizeof(struct Jobs));
jobhead->next = NULL;
bqhead = (struct Blocking_queue *)malloc(sizeof(struct Blocking_queue));
bqhead->next = NULL;
ubhead = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
struct Unoccupied_block *first = (struct Unoccupied_block *)malloc(sizeof(struct Unoccupied_block));
// 这里设置空闲分区表为双向链表
first->addr_start = 0;
first->addr_end = 640;
first->next = NULL;
first->previous = ubhead;
ubhead->next = first;
ubhead->previous = NULL;
ubhead->addr_start = -1;
ubhead->addr_end = -1;
while (!feof(fp))
{
struct Jobs newJob;
int id, type, space;
fscanf(fp, "%d %d %d", &id, &type, &space);
if (type == 1)
{
Arrange(id, space, false);
if (altype)
sort();
Output();
}
else if (type == 0)
{
Free(id);
if (altype)
sort();
// 如果阻塞队列中有未完成分配的作业,取出一项进行分配,直到处理完所有阻塞作业
if (!empty())
{
struct Blocking_queue *t = bqhead->next;
while (t)
{
printf("处理阻塞队列中的作业%d\n", t->jobID);
// 若阻塞队列中的一个作业分配成功,则从阻塞队列中取下这个作业
if (Arrange(t->jobID, t->space, true))
{
if (altype)
sort();
t = DeleteBQ(t->jobID);
continue;
}
t = t->next;
}
}
Output();
}
}
}
int main(void)
{
// 减少代码冗余,因为两个算法只是对内存进行分配回收后是否排序的问题,所以仅用一个函数,用一个标志位区分是否排序
printf("*******************************************************\n\n");
printf("首次适应算法:\n\n");
first_fit(false);
printf("*******************************************************\n\n");
printf("最佳适应算法:\n\n");
first_fit(true);
return 0;
}
/*
代码调试过程中用到的测试数据
验证实验指导书的例子:
1 1 130
2 1 60
3 1 100
2 0 60
4 1 200
3 0 100
1 0 130
5 1 140
6 1 60
7 1 50
6 0 60
*/

理解与体会
算法没有优劣之分。算法不同,分配情况和空闲分区以及回收空闲分区的方法也不同。面对不同的存储管理需求,要灵活采取不同的存储管理算法。首次适应算法从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。该算法倾向于使用内存中低地址部分的空闲区。最佳适应算法从全部空闲区中找出能满足作业要求的、且大小最小的空闲分区,这种方法能使碎片尽量小。为适应此算法,空闲分区表(空闲区链)中的空闲分区要按从小到大进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留大的空闲区,但造成许多小的空闲区。应根据具体需求设计具体方案。
实验八 页面置换模拟程序设计
一、实验目的
1、通过软件模拟页面置换过程,加深对请求页式存储管理实现原理的理解
2、理解和掌握OPT、FIFO和LRU三种页面置换算法,深入分析三者之间的优缺点。
二、实验环境
硬件环境:计算机一台,局域网环境;
软件环境: Windows或Linux操作系统, C语言编程环境。
三、实验内容和步骤
参考设计思路
(1)重要数据结构
① 页表数据结构
typedef struct
{
int vmn;
int pmn;
int exist;
int time;
}vpage_item;
vpage_item page_table[VM_PAGE];
页表是虚地址向物理地址转换的依据,包含虚页号所对应的实页号,是否在物理内存中。
页表中增加了一个time项,用于替换算法选择淘汰页面,在不同的替换算法中,time含义不一样。
在LRU算法中,time为最近访问的时间。该虚页每访问一次,time置为当前访问时刻,淘汰页面时,淘汰time值最小的,即最久没有被使用的。
在FIFO算法中,time为该虚页进入内存的时间。只有当该虚页从外存进入内存时,才置该标志。淘汰页面时,淘汰time值最小的,即最早进入内存的虚页。
在OPT算法中,time没有任何意义。
② 物理页位图数据结构
vpage_item * ppage_bitmap[PM_PAGE];
物理页位图是用于记录物理页是否被使用,用于物理页内存的分配。正常情况下是一个数组,元素值为0时,代表相应物理页没有装入任何虚页,值为1时,代表该物理页装入虚页。但为方便替换算法检索要替换出去的虚页,数组的每个元素值为当前放在该物理页的页表项的指针。若值为NULL,则表示该物理页没有被占用,当值不为NULL时,表示正在占用该物理页的虚页。
③指令相关数据结构
//每条指令信息
typedef struct{
int num;
int vpage;
int offset;
int inflow;
}instr_item;
//指令数组
instr_item instr_array[TOTAL_INSTR];
//指令流数据结构
struct instr_flow{
instr_item *instr;
struct instr_flow *next;
};
//指令流头数据结构
struct instr_flow_head{
int num;
struct instr_flow *next;
};
struct instr_flow_head iflow_head;
每条指令包括指令号、该指令所属虚页及页内偏移(这两项可以根据指令号计算出来,增加这两项是为了方便编程)。inflow是一个辅助项,用于构建指令流。
本题要求,按照规则生成的指令流中,应包含所有的共320条指令。但每次随机生成的指令号,可能已在指令流中,因此最终指令流中的指令数可能远远超过320条指令。
设置inflow的目的是为了便于统计是否320条指令均已加入到指令流中。在该条指令加入到指令流中时,如果inflow为0,表示该指令尚未在指令流中,则统计数加1;如果inflow为1,表示该指令已经加入过指令流,该指令虽然再次加入指令流,但统计数不增加。这样,当统计计数为320时,表示所有的指令均已加入到指令流中。
struct instr_flow为指令流数据结构,struct instr_flow_head始终指向指令流的头,其中num用于指令流中指令数量计数,用于计算缺页率。
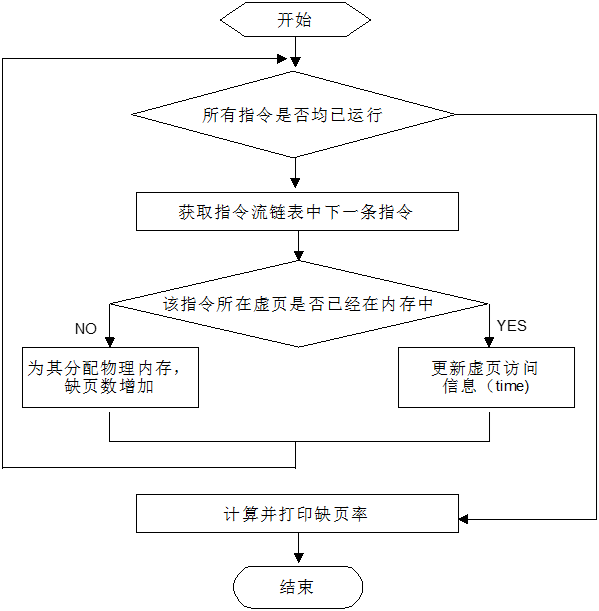
(2)主程序,如下图所示。

(3)指令流生成流程
指令流的生成按照实验要求生成,其算法流程如下图所示。

(4)物理内存分配流程
物理内存分配时,需要根据当前置换算法选择淘汰页面。其算法流程下图所示。

(5)运行流程图,如下图所示。
(6)三种置换算法
①OPT算法:在当前指令的后续指令流中,寻找已在内存中的虚页,哪个最远才被使用,反过来,如果先找到最近三个(物理页面总数为4)也在内存中的虚页,则剩下的那个虚页肯定就是最远才被使用的虚页,该虚页被淘汰,其物理内存分配给当前指令所在的虚页。
②FIFO算法:在已在物理内存中的虚页中,寻找time最小的虚页(最早进入物理内存的虚页),该虚页即是被淘汰的虚页。
③LRU算法:思想同FIFO算法,但time最小的虚页含义是最久没有被使用的虚页。
在这三种置换算法中,OPT的算法稍微复杂一些,下图给了该算法的程序流程图。

注:程序实例代码请见附件。
代码:
// OS.cpp: 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include<stdio.h>
#include<stdlib.h>
#define VM_PAGE 7 /*假设每个页面可以存放10条指令,则共有32个虚页*/
#define PM_PAGE 4 /*分配给作业的内存块数为4*/
#define TOTAL_INSERT 18
typedef struct
{
int vmn;
int pmn;
int exist;
int time;
}vpage_item;
vpage_item page_table[VM_PAGE];
vpage_item* ppage_bitmap[PM_PAGE];
int vpage_arr[TOTAL_INSERT] = { 1,2,3,4,2,6,2,1,2,3,7,6,3,2,1,2,3,6 };
void init_data() //数据初始化
{
for (int i = 0; i<VM_PAGE; i++)
{
page_table[i].vmn = i + 1; //虚页号
page_table[i].pmn = -1; //实页号
page_table[i].exist = 0;
page_table[i].time = -1;
}
for (int i = 0; i<PM_PAGE; i++) /*最初4个物理块为空*/
{
ppage_bitmap[i] = NULL;
}
}
void FIFO()/*FIFO页面置换算法*/
{
int k = 0;
int i;
int sum = 0;
int missing_page_count = 0;
int current_time = 0;
bool isleft = true; /*当前物理块中是否有剩余*/
while (sum < TOTAL_INSERT)
{
if (page_table[vpage_arr[sum] - 1].exist == 0)
{
missing_page_count++;
if (k < 4)
{
if (ppage_bitmap[k] == NULL) /*找到一个空闲物理块*/
{
ppage_bitmap[k] = &page_table[vpage_arr[sum] - 1];
ppage_bitmap[k]->exist = 1;
ppage_bitmap[k]->pmn = k;
ppage_bitmap[k]->time = current_time;
k++;
}
}
else
{
int temp = ppage_bitmap[0]->time; /*记录物理块中作业最早到达时间*/
int j = 0; /*记录应当被替换的物理块号*/
for (i = 0; i < PM_PAGE; i++)
{
if (ppage_bitmap[i]->time < temp)
{
temp = ppage_bitmap[i]->time;
j = i;
}
}
ppage_bitmap[j]->exist = 0;
ppage_bitmap[j] = &page_table[vpage_arr[sum] - 1]; /*更新页表项*/
ppage_bitmap[j]->exist = 1;
ppage_bitmap[j]->pmn = j;
ppage_bitmap[j]->time = current_time;
}
}
current_time++;
sum++;
}
printf("FIFO算法缺页次数为:%d\t缺页率为:%f\t置换次数为:%d\t置换率为:%f", missing_page_count, missing_page_count / (float)TOTAL_INSERT, missing_page_count - 4, (missing_page_count - 4) / (float)TOTAL_INSERT);
}
void LRU()
{
}
void OPT()
{
}
int main()
{
int a;
printf("请输入需要选择的页面置换算法:1.FIFO\t2.LRU\t3.OPT\t输入0结束\n");
do
{
scanf_s("%d", &a);
switch (a)
{
case 1:
init_data();
FIFO();
break;
case 2:
init_data();
LRU();
break;
case 3:
init_data();
OPT();
break;
}
} while (a != 0);
return 0;
}
实验报告要求:
(1)贴出试验结果。
(2)分析实验结果产生的原因,总结从实验观察到的结果。分析三种置换算法的缺页率的差异。
(3)结合操作系统课程中讲授的原理,写出本次实验的心得体会。
代码:
#include<stdio.h>
#include<stdlib.h>
#define VM_PAGE 7 /*假设每个页面可以存放10条指令,则共有32个虚页*/
#define PM_PAGE 4 /*分配给作业的内存块数为4*/
#define TOTAL_INSERT 18
typedef enum __bool { false = 0, true = 1, } bool;
typedef struct
{
int vmn;
int pmn;
int exist;
int time;
}vpage_item;
vpage_item page_table[VM_PAGE];
vpage_item* ppage_bitmap[PM_PAGE];
int vpage_arr[TOTAL_INSERT] = { 1,2,3,4,2,6,2,1,2,3,7,6,3,2,1,2,3,6 };
void init_data() //数据初始化
{
int i;
for (i = 0; i < VM_PAGE; i++)
{
page_table[i].vmn = i + 1; //虚页号
page_table[i].pmn = -1; //实页号
page_table[i].exist = 0;
page_table[i].time = -1;
}
for (i = 0; i < PM_PAGE; i++) /*最初4个物理块为空*/
{
ppage_bitmap[i] = NULL;
}
}
void FIFO()/*FIFO页面置换算法*/
{
int k = 0;
int i;
int sum = 0;
int missing_page_count = 0;
int current_time = 0;
bool isleft = true; /*当前物理块中是否有剩余*/
while (sum < TOTAL_INSERT)
{
if (page_table[vpage_arr[sum] - 1].exist == 0)
{
missing_page_count++;
if (k < 4)
{
if (ppage_bitmap[k] == NULL) /*找到一个空闲物理块*/
{
ppage_bitmap[k] = &page_table[vpage_arr[sum] - 1];
ppage_bitmap[k]->exist = 1;
ppage_bitmap[k]->pmn = k;
ppage_bitmap[k]->time = current_time;
k++;
}
}
else
{
int temp = ppage_bitmap[0]->time; /*记录物理块中作业最早到达时间*/
int j = 0; /*记录应当被替换的物理块号*/
for (i = 0; i < PM_PAGE; i++)
{
if (ppage_bitmap[i]->time < temp)
{
temp = ppage_bitmap[i]->time;
j = i;
}
}
ppage_bitmap[j]->exist = 0;
ppage_bitmap[j] = &page_table[vpage_arr[sum] - 1]; /*更新页表项*/
ppage_bitmap[j]->exist = 1;
ppage_bitmap[j]->pmn = j;
ppage_bitmap[j]->time = current_time;
}
}
current_time++;
sum++;
}
printf("FIFO算法缺页次数为:%d\t缺页率为:%f\t置换次数为:%d\t置换率为:%f", missing_page_count, missing_page_count / (float)TOTAL_INSERT, missing_page_count - 4, (missing_page_count - 4) / (float)TOTAL_INSERT);
}
void LRU()
{
int k = 0;
int i;
int sum = 0;
int missing_page_count = 0;
int current_time = 0;
bool isleft = true; /*当前物理块中是否有剩余*/
while (sum < TOTAL_INSERT) {
if (page_table[vpage_arr[sum] - 1].exist == 0) {
missing_page_count++;
if (k < 4)
{
if (ppage_bitmap[k] == NULL) /*找到一个空闲物理块*/
{
ppage_bitmap[k] = &page_table[vpage_arr[sum] - 1];
ppage_bitmap[k]->exist = 1;
ppage_bitmap[k]->pmn = k;
ppage_bitmap[k]->time = current_time;
k++;
}
}
else {
int temp = ppage_bitmap[0]->time; /*记录物理块中作业最早到达时间*/
int j = 0; /*记录应当被替换的物理块号*/
for (i = 0; i < PM_PAGE; i++)
{
if (ppage_bitmap[i]->time < temp)
{
temp = ppage_bitmap[i]->time;
j = i;
}
}
ppage_bitmap[j]->exist = 0;
ppage_bitmap[j] = &page_table[vpage_arr[sum] - 1]; /*更新页表项*/
ppage_bitmap[j]->exist = 1;
ppage_bitmap[j]->pmn = j;
ppage_bitmap[j]->time = current_time;
}
}
else {
for (i = 0; i < PM_PAGE; i++) {
if (ppage_bitmap[i]->vmn == page_table[vpage_arr[sum] - 1].pmn)
{
ppage_bitmap[i]->time = current_time;
break;
}
}
}
current_time++;
sum++;
}
printf("LRU算法缺页次数为:%d\t缺页率为:%f\t置换次数为:%d\t置换率为:%f", missing_page_count, missing_page_count / (float)TOTAL_INSERT, missing_page_count - 4, (missing_page_count - 4) / (float)TOTAL_INSERT);
}
void OPT()
{
int k = 0;
int sum = 0;
int missing_page_count = 0;
int current_time = 0;
bool isleft = true; /*当前物理块中是否有剩余*/
while (sum < TOTAL_INSERT) {
if (page_table[vpage_arr[sum] - 1].exist == 0) {
missing_page_count++;
if (k < 4)
{
if (ppage_bitmap[k] == NULL) /*找到一个空闲物理块*/
{
ppage_bitmap[k] = &page_table[vpage_arr[sum] - 1];
ppage_bitmap[k]->exist = 1;
ppage_bitmap[k]->pmn = k;
ppage_bitmap[k]->time = current_time;
k++;
}
}
else {
int used[VM_PAGE] = { 0 },i,l;
int count = 0;
for (i = sum+1; i < TOTAL_INSERT; i++) {
if (page_table[vpage_arr[i] - 1].exist == 1) {
used[page_table[vpage_arr[i] - 1].vmn-1] = 1;
}
int count = 0;
for (l = 0; l < VM_PAGE; l++) {
if (used[l] == 1) {
count++;
}
}
if (count == 3) {
break;
}
}
for (i = 0; i < PM_PAGE; i++) {
if (used[ppage_bitmap[i]->vmn-1] == 0) {
ppage_bitmap[i]->exist = 0;
ppage_bitmap[i] = &page_table[vpage_arr[sum] - 1];
ppage_bitmap[i]->exist = 1;
ppage_bitmap[i]->pmn = i;
ppage_bitmap[i]->time = current_time;
}
}
}
}
current_time++;
sum++;
}
printf("OPT算法缺页次数为:%d\t缺页率为:%f\t置换次数为:%d\t置换率为:%f", missing_page_count, missing_page_count / (float)TOTAL_INSERT, missing_page_count - 4, (missing_page_count - 4) / (float)TOTAL_INSERT);
}
int main()
{
int a;
printf("\t\t\t\t*****************请输入需要选择的页面置换算法********************\n");
printf("\t\t\t\t\t\t\t1:FIFO\n\t\t\t\t\t\t\t2:LRU\n\t\t\t\t\t\t\t3:OPT\n\t\t\t\t\t\t\t输入0结束\n");
do
{
scanf_s("%d", &a);
switch (a)
{
case 1:
init_data();
FIFO();
break;
case 2:
init_data();
LRU();
break;
case 3:
init_data();
OPT();
break;
}
} while (a != 0);
return 0;
}
运行结果:
FIFO算法

LRU算法
![]()
OPT算法
![]()
实验思考
根据运行结果显示,最佳页面替换算法的缺页率、置换次数和置换率均是最低的。最佳页面替换算法提前预知了未来,是一种无法实现的理想模型。它只能作为一种复盘的标杆,用来衡量在当前情况下,哪种算法更合适。算法没有优劣之分,适合当前处理任务的,就是好的算法。譬如在本次实验下,不能因为LRU算法的缺页率、置换次数和置换率均高于其他算法,就否定LRU算法。LRU 算法优势在于算法实现难度不大,对于热点数据, LRU 效率会很好。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









