







'''
获取输入的url地址的协议,是http、https等
'''
print('该站使用的协议是:' + re.findall(r'.*(?=://)',url)[0])
return re.findall(r'.*(?=://)',url)[0]
urlprotocol = url_protocol(url)
def same_url(url):
‘’’
处理输入的url,判断是否为同一站点做准备,爬取的时候不能爬到其它站
‘’’
#将完整的url中的http://删除
url = url.replace(urlprotocol + ‘😕/’,‘’)
if re.findall(r'^www',url) == []:
sameurl = 'www.' + url
if sameurl.find('/') != -1:
sameurl = re.findall(r'(?<=www.).*?(?=/)', sameurl)[0]
else:
sameurl = sameurl + '/'
sameurl = re.findall(r'(?<=www.).*?(?=/)', sameurl)[0]
else:
if url.find('/') != -1:
sameurl = re.findall(r'(?<=www.).*?(?=/)', url)[0]
else:
sameurl = url + '/'
sameurl = re.findall(r'(?<=www.).*?(?=/)', sameurl)[0]
#print('同站域名地址:' + sameurl)
return sameurl
domain_url = url
‘’’
处理url的类,对已访问过的和未访问过的进行记录,待后续使用
‘’’
class linkQuence:
def init(self):
self.visited = [] #已访问过的url初始化列表
self.unvisited = [] #未访问过的url初始化列表
def getVisitedUrl(self): #获取已访问过的url
return self.visited
def getUnvisitedUrl(self): #获取未访问过的url
return self.unvisited
def addVisitedUrl(self,url): #添加已访问过的url
return self.visited.append(url)
def addUnvisitedUrl(self,url): #添加未访问过的url
if url != '' and url not in self.visited and url not in self.unvisited:
return self.unvisited.insert(0,url)
def removeVisited(self,url):
return self.visited.remove(url)
def popUnvisitedUrl(self): #从未访问过的url中取出一个url
try: #pop动作会报错终止操作,所以需要使用try进行异常处理
return self.unvisited.pop()
except:
return None
def unvisitedUrlEmpty(self): #判断未访问过列表是不是为空
return len(self.unvisited)
class Spider():
‘’’
爬取程序
‘’’
def init(self,url):
self.linkQuence = linkQuence() #引入linkQuence类
self.linkQuence.addUnvisitedUrl(url) #并将需要爬取的url添加进linkQuence对列中
self.current_deepth = 1 #设置爬取的深度
def getPageLinks(self,url):
'''
获取页面中的所有链接
'''
sel = html_prase(url)
pageLinks = sel.xpath('//a/@href')
return pageLinks
def processUrl(self,url):
'''
处理相对路径为正确的完整url
'''
true_url = []
for l in self.getPageLinks(url):
if re.findall(r'//',l):
if re.findall('https://',l) or re.findall('http://',l):
true_url.append(l)
elif not re.findall('@',l):
#true_url.append(urlprotocol + '://' + domain_url + l)
true_url.append(urlprotocol+':' + l)
# for l in true_url:
# print(l)
return true_url
def sameTargetUrl(self,url):
'''
判断是否为同一站点链接,防止爬出站外。
'''
same_target_url = []
for l in self.processUrl(url):
if re.findall(domain_url,l):
same_target_url.append(l)
#print(self.same_target_url)
return same_target_url
def unrepectUrl(self,url):
'''
删除重复url,排除指定域名
'''
unrepect_url = []
expect_domain = ['s.wuage.com','static.wuage.com',
'shop.wuage.com','img.wuage.com','medici.wuage.com',
'buyer.wuage.com','item.wuage.com']
for l in self.sameTargetUrl(url):
if l not in unrepect_url and l.split('//')[1].split('/')[0] not in expect_domain:
unrepect_url.append(l)
return unrepect_url
def crawler(self,crawl_deepth=1):
'''
依据深度进行爬取层级控制
'''
#while self.current_deepth <= crawl_deepth:
while self.current_deepth <= crawl_deepth:
visitedUrl = self.linkQuence.popUnvisitedUrl()
if visitedUrl is None or visitedUrl == '':
continue
self.getPageLinks(visitedUrl)
links = self.unrepectUrl(visitedUrl)
self.linkQuence.addVisitedUrl(visitedUrl)
for link in links:
sel_link = html_prase(link)
print(link)
self.linkQuence.addUnvisitedUrl(link)
self.current_deepth += 1
return self.linkQuence.visited
if name == ‘main’:
spider = Spider(url)
spider.crawler(3)
---
**作者:彭于晏,互联网公司运维技术负责人,拥有10年的互联网开发和运维经验。一直致力于运维工具的开发和运维专家服务的推进,赋能开发,提高效能。**
**最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!**
### 软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)**

还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
***93道网络安全面试题***
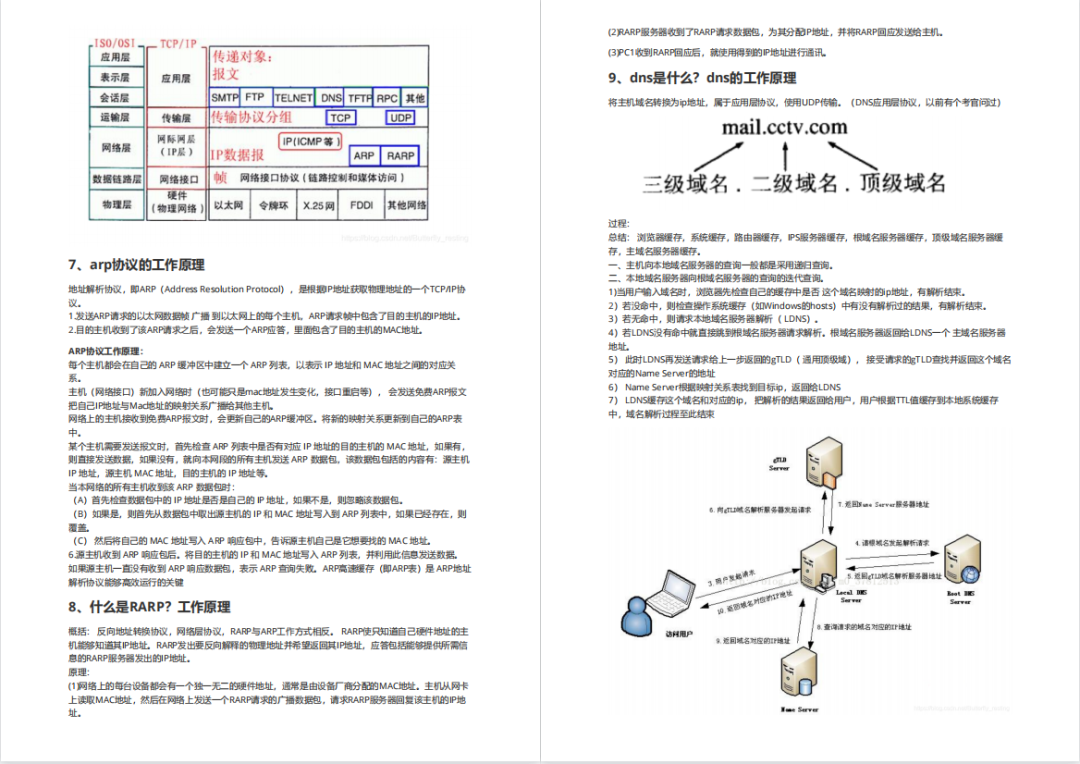


内容实在太多,不一一截图了
### 黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
#### 1️⃣零基础入门
##### ① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的**学习成长路线图**。可以说是**最科学最系统的学习路线**,大家跟着这个大的方向学习准没问题。
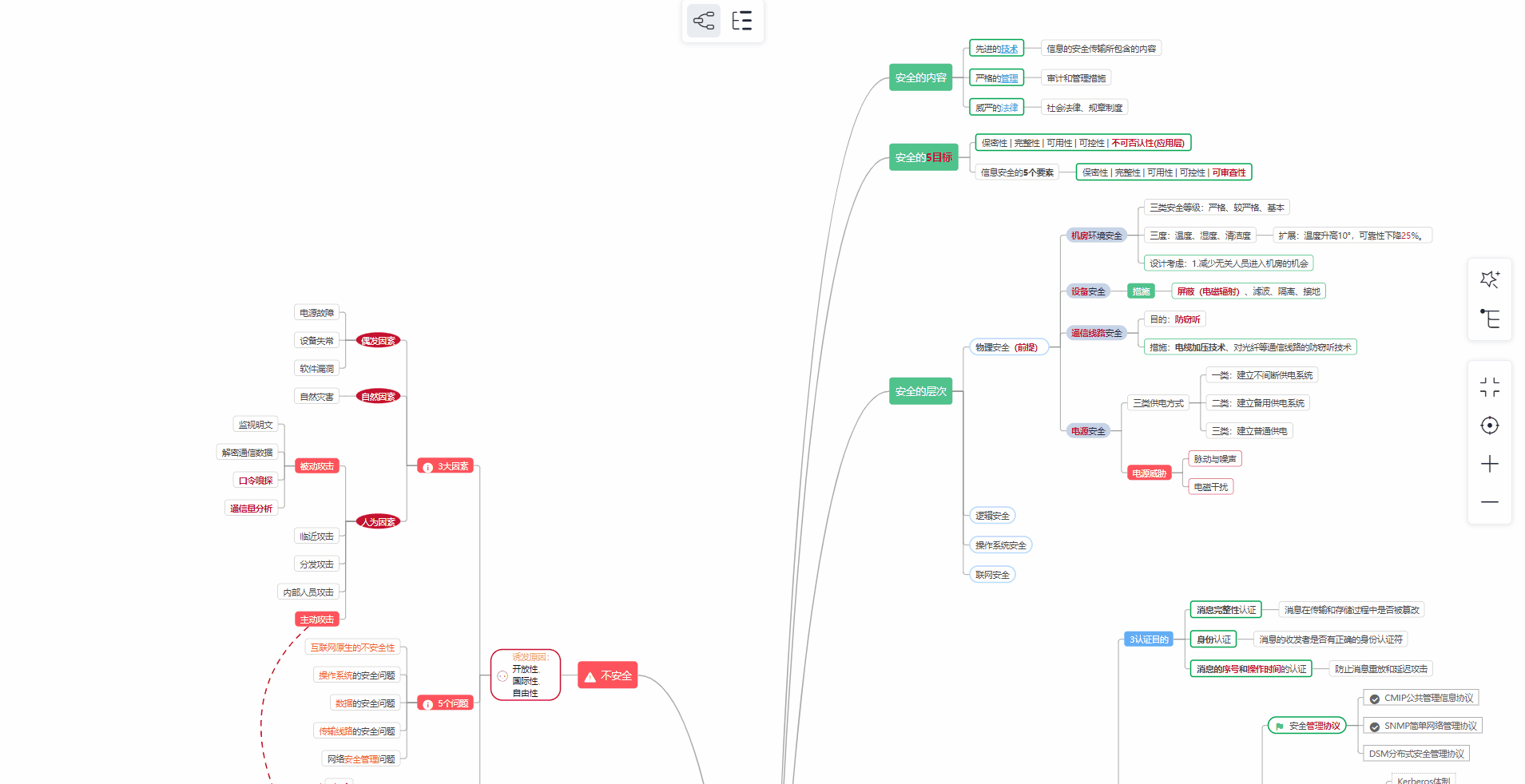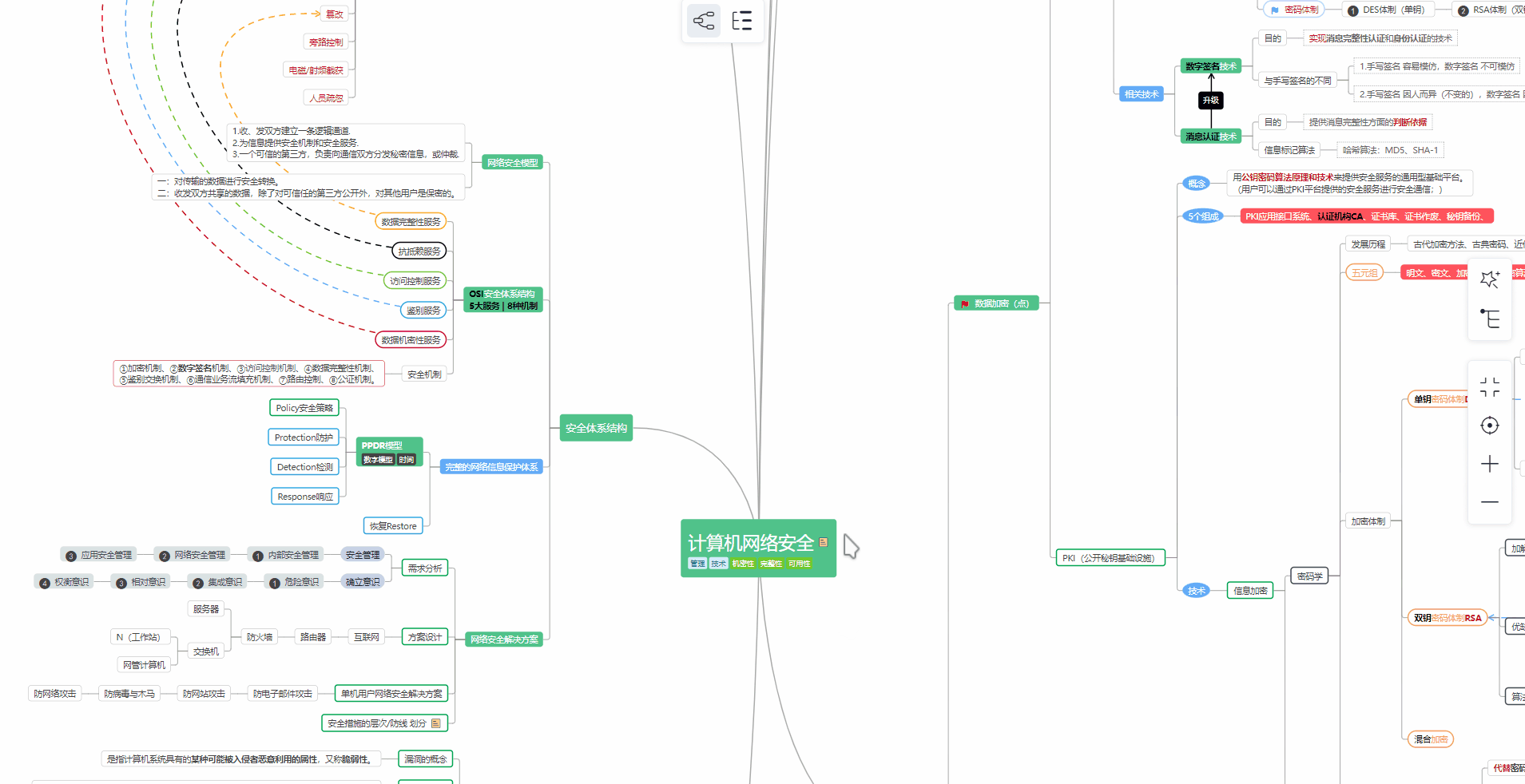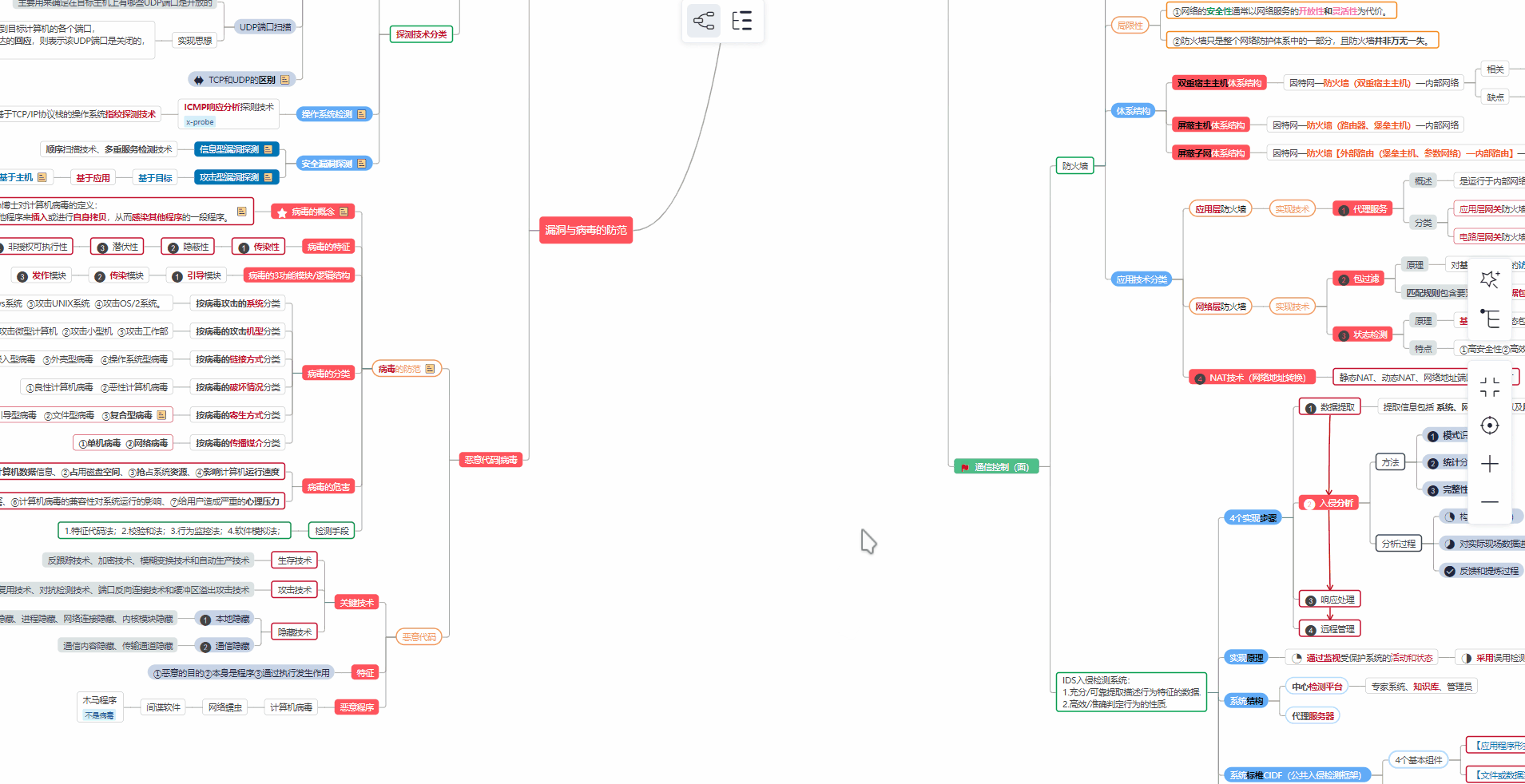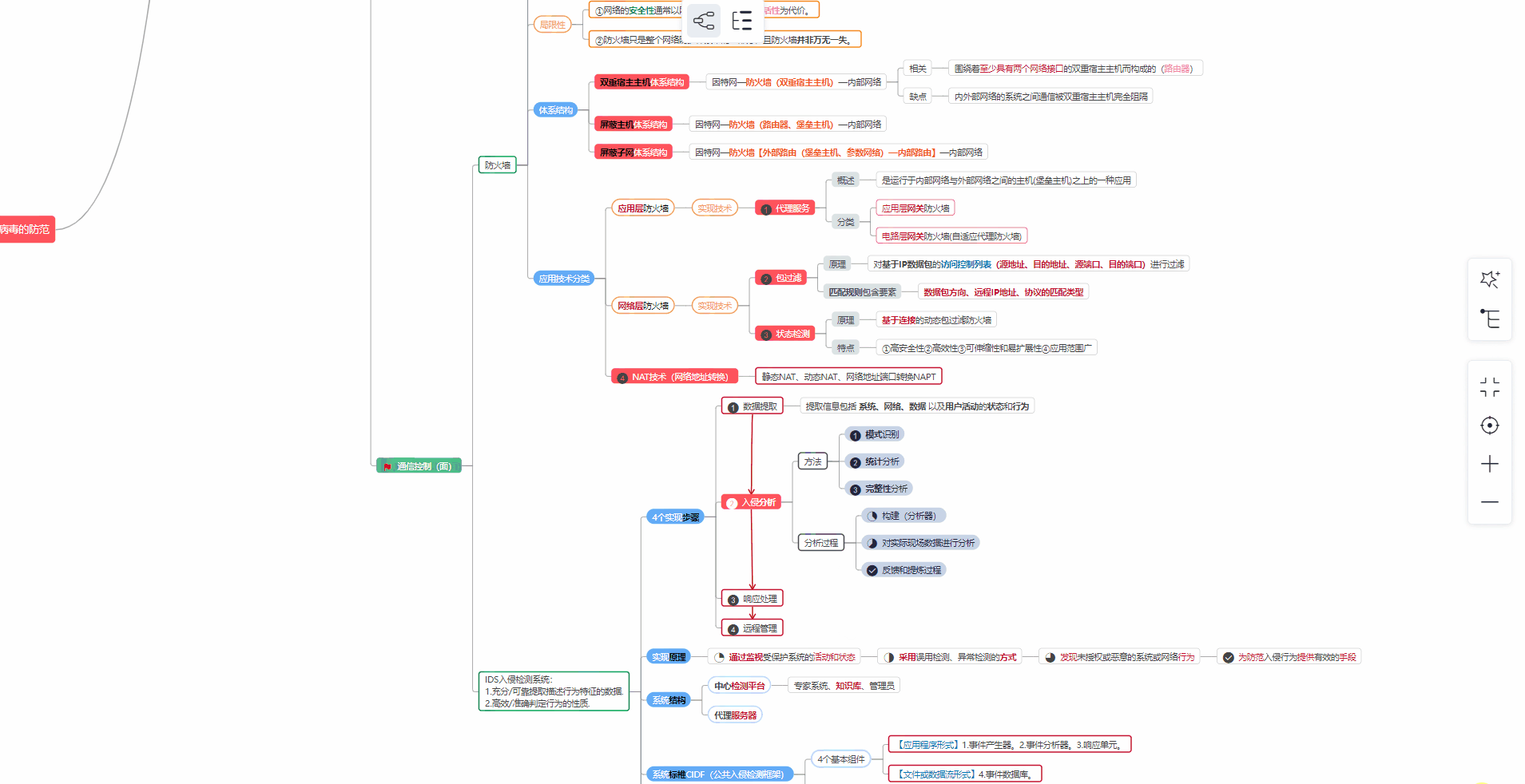
##### ② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

视频提供:

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中...(img-qMQtjxfU-1712900984950)]















 9159
9159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









