






1 在一次报表开发任务中遇到这么一个需求,要求统计用户截止每天的发布文章的所有数量,例如 :
| 日期 | 文章(篇) |
| 2022-01-01 | 20 |
| 2022-01-02 | 16 |
| 2022-01-03 | 32 |
| 2022-01-04 | 18 |
那么统计出的报表数据应如下:
| 日期 | 文章(篇) | 总计 |
| 2022-01-01 | 20 | 20 |
| 2022-01-02 | 16 | 36 |
| 2022-01-03 | 32 | 68 |
| 2022-01-04 | 18 | 86 |
显然使用普通的 group by 是不能满足需求的,应考虑自连接:
SELECT aa.日期, aa.数值, SUM(lj.数值) AS 累计
FROM tb lj INNER JOIN
(SELECT * FROM tb) aa ON lj.日期 <= aa.日期
WHERE (aa.日期 <= '2005-05-04')
GROUP BY aa.日期, aa.数值
ORDER BY aa.日期
2 有一张成绩表(姓名)(班级)(成绩)三个字段,要求写个sql语句选择出不同班级的成绩前三名的学生的信息
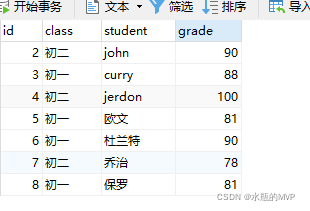
同样我们可以使用自连接加上限制条件来筛选:
SELECT * FROM class A LEFT JOIN class B ON A.class = B.class AND A.grade < B.grade
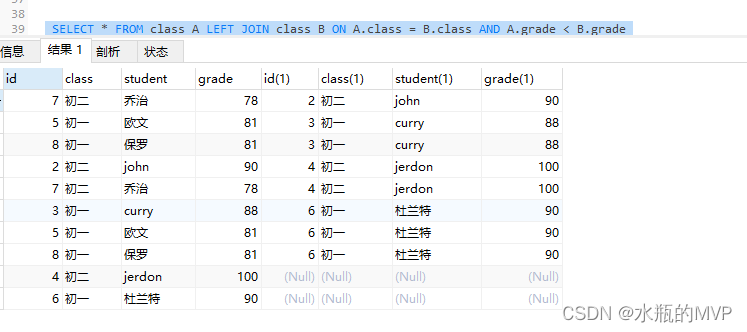
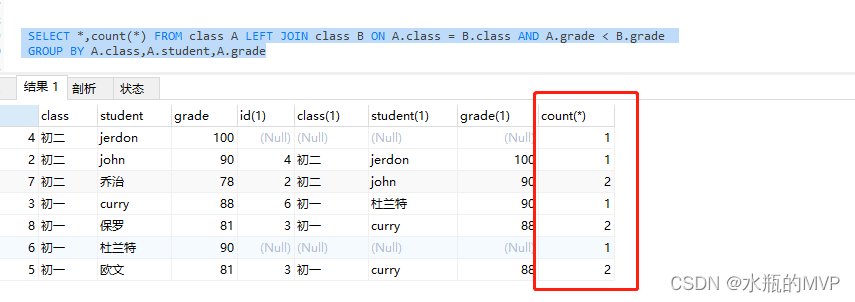
此时的结果还不是我们需求的结果,该SQL可以理解成,排列出了所有比同一班级下任意学生的成绩低的学生信息,如:初二年级比John成绩低的只有乔治,初一年级比curry成绩低的有欧文和保罗,初一年级比杜兰特成绩低的有curry,欧文,保罗,只要在这个排列中的信息出现超过了2次(包括两次),说明有同一班级超过两个学生的成绩高于该学生,代表该学生的信息已经掉出了前两名开外了,我们使用group by + having来进行分组,聚合过滤
SELECT *,count(*) FROM class A LEFT JOIN class B ON A.class = B.class AND A.grade < B.grade
GROUP BY A.class,A.student,A.grade
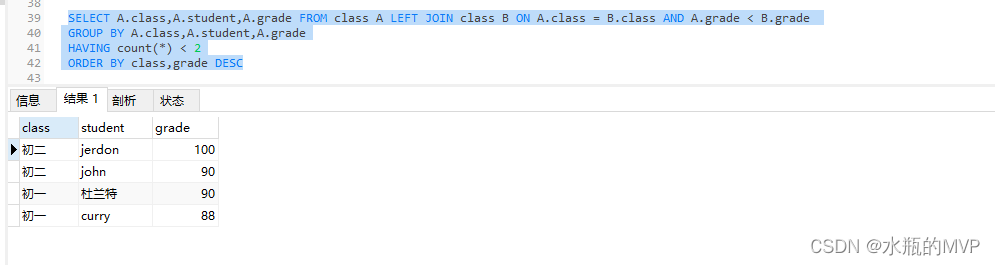
最后我们再添加having,再排序,取出我们需求的结果
SELECT A.class,A.student,A.grade FROM class A LEFT JOIN class B ON A.class = B.class AND A.grade < B.grade
GROUP BY A.class,A.student,A.grade
HAVING count(*) < 2
ORDER BY class,grade DESC

















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









