






一、约束(了解)
概念:对表中的数据进行限定,保证数据正确性,完整性,有效性
分类:
1.主键约束:primary key
2.非空约束:not null
3.唯一约束:unique
4.外键约束:foreign key
5.默认约束:default
1.非空约束:
not null,值不能为空null
1.创建表时添加非空约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- name非空
);
2.创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;
3.删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
2.唯一约束:
unique,值不能重复
1.创建表时添加唯一约束
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE -- 添加唯一约束
);
注意:mysql中,唯一约束限定的列可以有多个null
2.创建表完后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;
3.删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;
3.主键约束
primary key 非空且唯一
注意:一张表只能有一个字段是主键,主键是表中记录的唯一标识
1.创建表时添加主键约束
CREATE TABLE stu(
id INT PRIMARY KEY,-- 给id添加主键约束
NAME VARCHAR(20)
);
create table tb_class(
id int(11), -- id是主键列
NAME VARCHAR(20)
primary key (id) -- 为stu表的id列设置主键约束
);
2.创建表完后,添加主键约束
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
3.只能删除主键(不能删除非空)
ALTER TABLE stu DROP PRIMARY KEY;
4.自动增长
auto_increment 一个字段的值自增增长1,2,3,4,5
1.创建表时添加主键约束,并且完成自动增长
CREATE TABLE stu(
id INT PRIMARY KEY AUTO_INCREMENT,-- 给id添加主键约束并自动增长
NAME VARCHAR(20)
);
INSERT INTO stu VALUES(NULL,'1');
2.创建表完后,添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
3.删除自动增长
ALTER TABLE stu MODIFY id INT;
4.插入值
INSERT INTO stu(NAME) VALUES('张三');
INSERT INTO stu(NAME) VALUES('李四');
-- 或
INSERT INTO stu VALUES(NULL,'1'),(NULL,'2'),(NULL,'3');
5.联合主键
指的是把两个列看成一个整体,这个整体不为空,唯一,且不重复
1.创建表时添加联合主键
CREATE TABLE stu(
sid INT,
cid INT,
CONSTRAINT s_pk PRIMARY KEY(sid,cid)
);
或
CREATE TABLE stu(
sid INT,
cid INT,
PRIMARY KEY(sid,cid)
);
2.创建表完后,添加联合主键
alter table stu add CONSTRAINT s_pk primary key(sid,cid);
或
alter table stu add primary key(sid,cid);
3.删除联合主键
alter table stu drop primary key;
6.默认约束
default 为某一列指定一个默认的规则
例如:性别默认值1
1.创建表时添加默认约束
CREATE TABLE stu(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) UNIQUE,
hobby VARCHAR(30) NOT NULL,
sex CHAR(1) DEFAULT '1',
age INT
);
2.创建表完后,添加默认约束
ALTER TABLE stu MODIFY COLUMN sex CHAR(1) DEFAULT '1';
3.删除sex的默认约束
ALTER TABLE stu MODIFY sex CHAR(1);
7.外键约束
为什么要有外键约束?
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(30),
age INT,
dep_name VARCHAR(30), dep_location VARCHAR(30)
);
-- 添加数据
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('张三', 20, '研发部', '广州'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('李四', 21, '研发部', '广州'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('王五', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('老王', 20, '销售部', '深圳'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('大王', 22, '销售部', '深圳'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('小王', 18, '销售部', '深圳');
以上数据表的缺点:
1)数据冗余
2)后期还会出现增删改的问题
解决方案:分成 2 张表
-- 创建部门表(id,dep_name,dep_location)
-- 一方,主表
create table department(
id int primary key auto_increment,
dep_name varchar(20),
dep_location varchar(20)
);
-- 创建员工表(id,name,age,dep_id)
-- 多方,从表
create table employee(
id int primary key auto_increment, name varchar(20),
age int,
dep_id int -- 外键对应主表的主键
);
-- 添加 2 个部门
insert into department values(1, '研发部','广州'),(2, '销售部', '深圳'); select * from department;
-- 添加员工,dep_id 表示员工所在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
select * from employee;
问题:当我们在 employee 的 dep_id 里面输入不存在的部门,数据依然可以添加.但是并没有对应的部门, 实际应用中不能出现这种情况。employee 的 dep_id 中的数据只能是 department 表中存在的 id
解决:需要约束 dep_id 只能是 department 表中已经存在 id
foreign key 让表和表产生关系,从而保证数据正确性
语法:
[CONSTRAINT][外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
1.创建表时添加外键约束:
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT,
dep_id INT, -- 外键对应主表的主键
CONSTRAINT emp_depid_fk FOREIGN KEY(dep_id) REFERENCES department(id)
);
2.创建表完后,添加外键约束
ALTER TABLE employee ADD CONSTRAINT emp_depid_fk FOREIGN KEY(dep_id) REFERENCES department(id);
3.删除外键
ALTER TABLE employee DROP FOREIGN KEY emp_depid_fk;
4.级联操作:主表有所改动,从表就跟着改动
在修改和删除主表的主键时,同时更新或删除副表的外键值,称为级联操作
1.添加级联操作-语法:
ALTER TABLE employee ADD CONSTRAINT emp_depid_fk FOREIGN KEY(dep_id) REFERENCES department(id) ON UPDATE CASCADE ON DELETE CASCADE;
2.分类:
级联更新 ON UPDATE CASCADE
级联删除 ON DELETE CASCADE
二、多表连接查询:重点,难点
准备数据:
# 创建部门表
create table dept(
id int primary key auto_increment,
name varchar(20)
);
insert into dept (name) values ('开发部'),('市场部'),('财务部'); # 创建员工表
create table emp (
id int primary key auto_increment,
name varchar(10),
gender char(1), -- 性别
salary double, -- 工资
join_date date, -- 入职日期
dept_id int,
foreign key (dept_id) references dept(id) -- 外键,关联部门表(部门表的主键)
);
insert into emp(name,gender,salary,join_date,dept_id) values('四阿哥','男',7200,'2013-02-24',1);
insert into emp(name,gender,salary,join_date,dept_id) values('苏公公','男',3600,'2010-12-02',1);
insert into emp(name,gender,salary,join_date,dept_id) values('嬛嬛','女',9000,'2008-08-08',2);
insert into emp(name,gender,salary,join_date,dept_id) values('皇后','女',5000,'2015-10-07',3);
insert into emp(name,gender,salary,join_date,dept_id) values('眉姐姐','女',4500,'2011-03-14',2);
问题:
– 查询所有的员工和所有部门
SELECT * FROM emp;
SELECT * FROM dept;
– 有很多冗余数据
– 笛卡尔积:有两个集合,取这两个集合所有的组成情况
– 消除无用的数据,需要使用多表的连接查询
SELECT * FROM emp,dept;
多表查询的分类:
1.内连接查询
1.隐式内连接:使用where条件消除无用数据
-- 查询所有的员工和所有部门
SELECT * FROM emp,dept WHERE emp.`dept_id`=dept.`id`;
-- 查询所有的员工的姓名,性别和部门名称
SELECT emp.`name`,emp.`gender`,dept.`name` FROM emp,dept WHERE emp.`dept_id`=dept.`id`;
简化:为表起别名
SELECT e.`name`,e.`gender`,d.`name` FROM emp e,dept d WHERE e.`dept_id`=d.`id`;
2.显示内连接:
语法: select 字段列表 from 表名1 【inner】 join 表名2 on 条件
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id`=dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id`=dept.`id`;
注意:1.从哪些表中查询数据 2.条件是什么 3.查询哪些字段
2.外连接查询(重点)
1.左外连接:
语法:select 字段列表 from 表名1 left【outer】 join 表名2 on 条件
查询的是左表所有数据以及两表交集的部分
用左边表的记录去匹配右边表的记录,如果符合条件的则显示;否则,显示 NULL
可以理解为:在内连接的基础上保证左表的数据全部显示
例子:
-- 查询所有员工信息,如果员工有部门,则查询部门名称;如果没有部门,则不显示部门名称
SELECT t1.*,t2.`name` FROM emp t1 LEFT JOIN dept t2 ON t1.`dept_id`=t2.`id`;
2.右外连接:
语法:select 字段列表 from 表名1 right【outer】 join 表名2 on 条件
查询的是右表所有数据以及两表交集的部分
用右边表的记录去匹配左边表的记录,如果符合条件的则显示;否则,显示 NULL
可以理解为:在内连接的基础上保证右表的数据全部显示
例子:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.`dept_id`=t2.`id`;
注意:在左边是左表,在右边是右表
3.子查询
概念:查询中嵌套查询,称嵌套查询为子查询
-- 查询工资最高的员工信息
-- 查询最高工资是多少?
SELECT MAX(salary) FROM emp;-- 9000
SELECT * FROM emp WHERE emp.`salary`=9000;
-- 一条sql语句完成。子查询
SELECT * FROM emp WHERE emp.`salary`=(SELECT MAX(salary) FROM emp);
子查询不同情况
1.子查询结果是单行单列的:
*子查询可以作为条件,使用运算符去判断。运算符:> >= < <= = <>
-- 查询员工工资小于平均工资的人
SELECT AVG(salary) FROM emp;
SELECT * FROM emp WHERE emp.`salary`<(SELECT AVG(salary) FROM emp);
2.子查询结果是多行单列的:
*子查询可以作为条件,使用运算符去判断。运算符:in(集合)
-- 查询财务部和市场部所有的员工信息
SELECT id FROM dept WHERE NAME='财务部' OR NAME ='市场部';-- 2 3
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
SELECT * FROM emp WHERE dept_id IN(SELECT id FROM dept WHERE NAME='财务部' OR NAME ='市场部');
3.子查询结果是多行多列的:
*子查询可以作为一张虚拟的表参与查询
-- 查询员工入职日期2011-11-11日之后的员工信息和部门信息
SELECT * FROM emp WHERE emp.`join_date`>'2011-11-11';
SELECT * FROM dept t1,(SELECT * FROM emp WHERE emp.`join_date`>'2011-11-11') t2
WHERE t1.`id`=t2.dept_id;
多表连接查询步骤:
1.知道查询的是哪些表,表最好起别名
2.知道表和表关系
3.找出字段分别在哪些表中
三、事务(面试)
1.事务的基本介绍
1.概念:如果一个包含很多个步骤的业务操作,被事务管理,这些操作要么同时成功,要么同时失败。
2.操作:(SQL语句)
开启事务:start transaction;
回滚:rollback;
提交:commit;
3.例子:转账的操作
-- 创建数据表
CREATE TABLE account (
id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10),
balance DOUBLE
);
-- 添加数据
INSERT INTO account (NAME, balance) VALUES ('张三', 1000), ('李四', 1000);
模拟张三给李四转 500 元钱,一个转账的业务操作最少要执行下面的 2 条语句: 张三账号-500
李四账号+500
-- 张三账号-500
update account set balance = balance - 500 where name='张三';
-- 李四账号+500
update account set balance = balance + 500 where name='李四';
假设当张三账号上-500 元,服务器崩溃了。李四的账号并没有+500 元,数据就出现问题了。我们需要保证其中一条 SQL 语句出现问题,整个转账就算失败。只有两条 SQL 都成功了转账才算成功。这个时候就需要用到事务。
START TRANSACTION;
UPDATE account SET balance = balance - 500 WHERE NAME='张三';
-- 服务器崩溃
UPDATE account SET balance = balance + 500 WHERE NAME='李四';
ROLLBACK;
COMMIT;
SELECT * FROM account;
4.MYSQL数据库中事务默认自动提交
事务提交方式:
自动提交:mysql
一条DML增删改语句会自动提交一次事务
手动提交:Oracle
需要先开启事务,再提交
5.查询和修改默认提交方式:
查看事务的默认提交方式:
SELECT @@autocommit;-- 1 自动提交 0 手动提交
修改事务默认提交方式:
SET @@autocommit=0;
2.事务的四大特征(重点:面试)
1.原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
2.持久性:当事务提交或者回滚之后,数据库会持久化保存数据
3.隔离性:多个事务之间。相互独立
4.一致性:事务操作前后,数据的总量不变
3.事务的隔离级别(重点:面试)
概念:多个事务之间是隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题。
*存在问题:
1.脏读:一个事务,读取到了另一个事务没有提交的数据
2.不可重复读(虚读):在同一个事务中,两次读取到的数据不一样
3.幻读(Oracle):一个事务DML表中的数据,另一个事务添加了一条数据,第一个事务查询不到第二个事务添加的数据
*隔离级别:
1.read uncommitted:读未提交
产生:脏读,不可重复读,幻读
2.read committed:读已提交
产生:不可重复读,幻读
3.repeatable read:可重复读 ——MYSQL
产生:幻读(ORACLE)
4.serializable:串行化
可以解决所有的问题
注意:隔离级别从小到大安全性越来越高,但是效率越来越低
*数据库的隔离级别查询与修改(了解)
查询:SELECT @@tx_isolation;
mysql数据库的默认隔离级别是:repeatable read:可重复读
修改:SET GLOBAL TRANSACTION ISOLATION LEVEL 级别字符串;
四、DCL
管理用户,授权
注意:先使用mysql数据库,才可以用DCL语句
DCL和DDL,DML,DQL不太一样。语句写法和数据库的版本
1.管理用户:(工作中不使用)
添加用户:
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
用户名:自定义
主机名:loacalhost本机 %远程
密码:自定义的
例:
CREATE USER 'dog'@'localhost' IDENTIFIED BY '123456';
CREATE USER 'pig'@'%' IDENTIFIED BY '123456';
查看用户:
SELECT * FROM USER;
删除用户:
DROP USER '用户名'@'主机名';
例:
DROP USER 'pig'@'%';
修改用户密码:
use mysql;
mysql5.5版本和mysql5.7版本:
SET PASSWORD FOR 'root'@'localhost'=PASSWORD('123456');
mysql8.0版本:
ALTER USER 'lisi'@'localhost' IDENTIFIED BY '123';
flush privileges;-- 刷新
2.授权:(重点:考到的概率大)
1.查询权限:
语法:SHOW GRANTS FOR '用户名'@'主机名';
例:SHOW GRANTS FOR 'dog'@'localhost';
该用户可以操作哪个数据库的哪些表。如果要授予该用户对所有数据库和表的相应操作
权限则可用*表示,如*.*
2.授予权限:
语法:GRANT 权限 1, 权限 2... ON 数据库名.表名 TO '用户名'@'主机名';
GRANT…ON…TO 授权关键字
权限 授予用户的权限,如 CREATE、ALTER、SELECT、INSERT、UPDATE 等。如果要授
予所有的权限则使用 ALL
数据库名.表名 该用户可以操作哪个数据库的哪些表。如果要授予该用户对所有数据库和表的 相应操作权限则可用*表示,如*.*
'用户名'@'主机名' 给哪个用户授权,注:有 2 对单引号
例:
GRANT CREATE,SELECT,UPDATE,DROP,INSERT ON pn.`account` TO 'dog'@'localhost';
GRANT ALL ON pn.`account` TO 'dog'@'localhost';
3.撤销权限
语法:revoke 权限 1, 权限 2... on 数据库名.表名 from '用户名'@'主机名';
例: REVOKE ALL ON pn.`account` FROM 'dog'@'localhost';
五、数据库的设计(了解)
1.多表之间的关系
1.三种关系
一对一(了解)
如:人和身份证
分析:一个人只能有一个身份证,一个身份证只能对应一个人
一对多(多对一)
部门和员工
分析:一个部门有多个员工,一个员工只能对应一个部门
多对多:
学生和课程
一个学生可以选择很多课程,一个课程可以被很多学生选择
2.实现三种关系
一对一(了解)
如:人和身份证
实现方式:可以在任意一方添加外键指向另一方的主键,还可以只建立一张表
一对多(多对一)
部门和员工
实现方式:在多的一方建立外键,指向一的一方的主键
多对多:
学生和课程
实现方式:借助第三张中间表,中间表至少包含两个字段,这两个字段作为第三张表的外键(也叫做联合主键)
分别指向两张表的主键
3.案例:淘宝网-商品分类表,商品表,用户表和收藏表
-- 创建商品分类表 tab_category
-- cid 商品分类主键,自动增长
-- cname 商品分类名称非空
create table tab_category (
cid int primary key auto_increment,
cname varchar(100) not null unique
);
-- 添加商品分类数据:
insert into tab_category (cname) values ('女装'), ('男装'), ('美妆'), ('零食');
select * from tab_category;
-- 创建商品表 tab_goods
/*
rid 商品主键,自动增长
rname 商品名称非空,唯一
rdate 上架时间,日期类型
cid 外键,所属分类
*/
create table tab_goods(
gid int primary key auto_increment,
rname varchar(100) not null unique,
price double,
rdate date,
cid int,
foreign key (cid) references tab_category(cid)
);
-- 添加旅游线路数据
INSERT INTO tab_goods VALUES
(NULL, '雪纺连衣裙', 1499, '2018-01-27', 1),
(NULL, '精致衬衫', 699, '2018-02-22', 3),
(NULL, '旺仔牛奶', 89, '2018-01-27', 2),
(NULL, '螺蛳粉',70, '2017-12-23', 2),
(NULL, '牛仔短裙', 799, '2018-04-10', 4);
select * from tab_route;
/*
创建用户表
tab_user uid 用户主键,自增长
username 用户名长度 100,唯一,非空password 密码长度 30,非空
name 真实姓名长度 100 birthday 生日
sex 性别,定长字符串 1
telephone 手机号,字符串 11
email 邮箱,字符串长度 100
*/
create table tab_user (
uid int primary key auto_increment,
username varchar(100) unique not null,
password varchar(30) not null,
name varchar(100),
birthday date,
sex char(1),
telephone varchar(11),
email varchar(100)
);
-- 添加用户数据
INSERT INTO tab_user VALUES
(NULL, 'cz110', 123456, '左璧莹', '1990-07-07', '女', '13888888888', '66666@qq.com'),
(NULL, 'cz119', 654321, '王伟杰', '1999-09-09', '男', '13999999999', '99999@qq.com');
select * from tab_user;
/*
创建收藏表 tab_favorite
gid 商品id,外键
date 收藏时间
uid 用户id,外键
rid 和 uid 不能重复,设置复合主键,同一个用户不能收藏同一个线路两次
*/
create table tab_favorite (
gid int, -- 商品ID
date datetime,
uid int,-- 用户id
-- 创建复合/联合主键
primary key(gid,uid),
foreign key (gid) references tab_goods(gid), foreign key(uid) references tab_user(uid)
);
-- 增加收藏表数据
INSERT INTO tab_favorite VALUES
(1, '2018-01-01', 1), -- 小左选择雪纺连衣裙
(2, '2018-02-11', 1), -- 小左选择精致衬衫
(3, '2018-03-21', 1), -- 小左选择旺仔牛奶
(2, '2018-04-21', 2), -- 小王选择精致衬衫
(3, '2018-05-08', 2), -- 小王选择旺仔牛奶
(5, '2018-06-02', 2); -- 小王选择牛仔短裙
select * from tab_favorite;
2.数据库设计的范式
1 .什么是范式:
好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。建立科学的,规范的数据库就需要满足一些规则来优化数据的设计和存储,这些规则就称为范式。
2 .三大范式:
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF,)其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
第一范式每一列不可再拆分,称为原子性。
第二范式就是在第一范式的基础上所有列完全依赖于主键列
第三范式就是在满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其它的列来间接依赖于主键
案例
第一范式
1、每一列属性都是不可再分的属性值,确保每一列的原子性
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
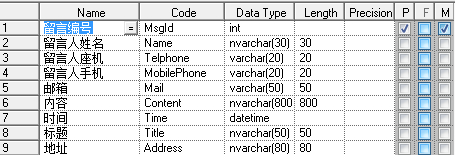
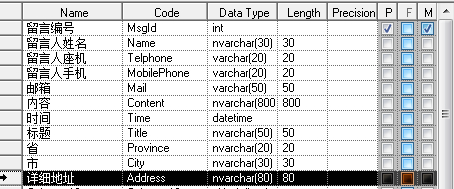
如果需求知道那个省那个市并按其分类,那么显然第一个表格是不容易满足需求的,也不符合第一范式。
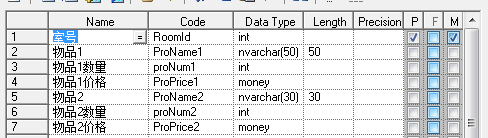

显然第一个表结构不但不能满足足够多物品的要求,还会在物品少时产生冗余。也是不符合第一范式的。
第二范式
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
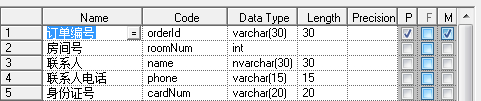
一个人同时订几个房间,就会出来一个订单号多条数据,这样子联系人都是重复的,就会造成数据冗余。我们应该把他拆开来。


这样便实现啦一条数据做一件事,不掺杂复杂的关系逻辑。同时对表数据的更新维护也更易操作。
第三范式
数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号–> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)–(所在院校,院校地址,院校电话)
最后:
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
六、数据库的备份和还原(了解)
1.命令行:
先备份,删库跑路,再还原
备份:mysqldump -u用户名 -p密码 数据库名称>保存路径
例如:mysqldump -uroot -p123456 mydb>d://d.sql
还原:
1.登录数据库
2.删除数据库 drop database mydb;
3.新建一个空的数据库 create database mydb;
4.使用数据库 use mydb;
5.执行文件 sourse 文件路径 source d://a.sql;
6.显示表
2.图像化工具SQLyog
[外链图片转存中…(img-qGcQDd1H-1679487537546)]
[外链图片转存中…(img-92HBsuPd-1679487537547)]
这样便实现啦一条数据做一件事,不掺杂复杂的关系逻辑。同时对表数据的更新维护也更易操作。
第三范式
数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号–> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)–(所在院校,院校地址,院校电话)
最后:
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
六、数据库的备份和还原(了解)
1.命令行:
先备份,删库跑路,再还原
备份:mysqldump -u用户名 -p密码 数据库名称>保存路径
例如:mysqldump -uroot -p123456 mydb>d://d.sql
还原:
1.登录数据库
2.删除数据库 drop database mydb;
3.新建一个空的数据库 create database mydb;
4.使用数据库 use mydb;
5.执行文件 sourse 文件路径 source d://a.sql;
6.显示表
2.图像化工具SQLyog















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









