






X32专项练习部分27
前序和后序遍历叶子节点的相对次序
/*
在任意一棵二叉树的前序序列和后序序列中,各叶子之间的相对次序关系( )。
正确答案: B
不一定相同
都相同
都不相同
互为逆序
首先叶子节点度为0,没有孩子节点
前序遍历 根左右
后序遍历 左右根
明显左子树和右子树的相对次序不变
举个栗子
A
/ \
B C
前序遍历 ABC
后序遍历 BCA
中序遍历 BAC
可见B永远在C的前面
*/
遍历平衡二叉树的时间复杂度和空间复杂度
/*
用常规的非递归方法遍历一个平衡二叉树,所需的时间复杂度和空间复杂度是()
正确答案: A
O(n), O(n)
O(n), O(1)
O(n^2), O(n^2)
O(n), O(n^2)
非递归的访问遍历二叉树的算法中的基本操作是访问结点
不论按哪一种次序进行遍历
对n个结点的二叉树,其时间复杂度均为O(n)
所需辅助空间为遍历过程中栈的最大容量
即树的深度,最坏情况下为n
应该对应单链的情况
则空间复杂度也为O(n)
*/
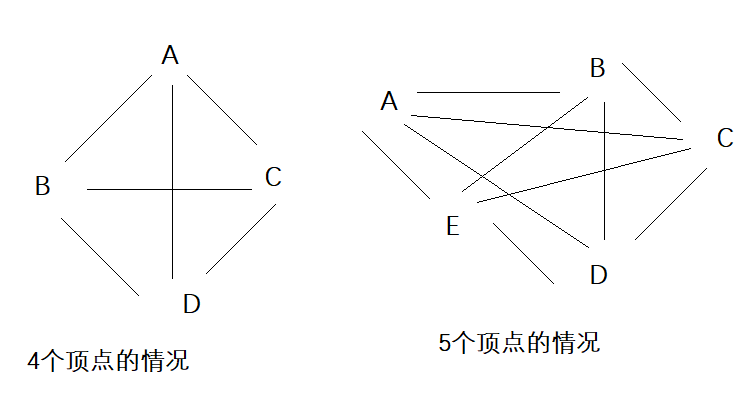
完全连通图
/*
若无向图G = (V.E)中含7个顶点,则保证图G在任何情况下都是连通的
则需要的边数最少是()
正确答案: C
6
15
16
21
为了保证图在任何情况下都是连通的
该图就是完全连通图
也称为无向完全图
就是每个顶点之间都会有1条边相连
存在如下公式
边(l) = n(n - 1)/2
*/
数据库查询中charindex的用法
/*
查询显示雇员的姓名和姓名中是否含有字母A的信息,满足如下条件
如果字符A在姓名的首位,则显示'字符A在首位'
如果字符A在姓名的末位,则显示'字符A在末位'
如果字符A在姓名中不存在,则显示'没有字符A'
其他情况显示'字符A在中间'
下列操作语句正确的是()
select ename, case charindex(‘A‘,ename)
when 1 then ‘字符A在首位‘
when len(ename) then
‘字符A在末位‘
when 0 then ‘没有字符A‘
else ‘字符A在中间‘
end 名称类别 from emp;
考察charindex的用法
charindex判断1个字符串是否包含另一个字符串
数据库索引开始于1
没有指定字符串返回0
*/
SQL数据转存操作
/*
某打车公司要将驾驶里程(drivedistanced)超过5000里的司机信息
转存到一张称为seniordrivers 的表中
他们的详细情况被记录在表drivers 中,正确的sql语句为()
正确答案:D
insert into seniordrivers
drivedistanced>=5000 from drivers where
insert seniordrivers (drivedistanced) values from drivers where drivedistanced>=5000
insert into seniordrivers
(drivedistanced)values>=5000 from drivers where
select * into seniordrivers from drivers where drivedistanced >=5000
B选项没有into,首先排除
AC where语句明显位置不对
D选项select into用法是筛选符合条件的数据,插入到指定表当中
select xxx into (designated location table) from (current table) where (conditions)
注意:
select xxx into (designated location table) from (current table) 要求目标表不存在
因为在插入时会自动创建
insert into (designated location table) select xxx from (current table) 要求目标表存在
*/
使用ALTER关键字修改表属性
/*
修改表test_tbl字段i的缺省值为1000,可以使用SQL语句( )
正确答案: A
ALTER TABLE test_tbl ALTER i SET DEFAULT 1000;
ALTER TABLE test_tbl i SET DEFAULT 1000;
ALTER TABLE test_tbl MODIFY i SET DEFAULT 1000;
ALTER TABLE test_tbl CHANGE i SET DEFAULT 1000;
首先明确缺省值就是默认值
修改表:
ALTER TABLE <表名> <修改选项 + 选项集合>
| ADD COLUMN <列名> <类型> -- 增加列
| CHANGE [COLUMN] <旧列名> <新列名> <新列类型> -- 修改列名或类型
| ALTER [COLUMN] <列名> { SET DEFAULT <默认值> | DROP DEFAULT } -- 修改/删除 列的默认值
| MODIFY [COLUMN] <列名> <类型> -- 修改列类型
| DROP [COLUMN] <列名> -- 删除列
| RENAME TO <新表名> -- 修改表名
| CHARACTER SET <字符集名> -- 修改字符集
| COLLATE <校对规则名> -- 修改校对规则(比较和排序时用到)
这道题
alter table <表名> alter column <字段名> set default <默认值>;
*/
10进制乱码字符串解码工具类HTMLDecoder
// 同行给了这么一个需求,实现一把
class HTMLDecoder {
/**
* 解码
* @param str 乱码字符串
* @return 中文
*/
public static String decode(String str) {
String[] tmp = str.split(";&#|&#|;");
// System.out.println(Arrays.toString(tmp));
StringBuffer sb = new StringBuffer("");
for (int i = 0; i < tmp.length; i++) {
if (tmp[i].matches("\\d{5}")) {
sb.append((char) Integer.parseInt(tmp[i]));
// System.out.println(sb.toString());
} else {
sb.append(tmp[i]);
}
}
return sb.toString();
}
/**
* 编码
* @param str 中文
* @return 乱码字符串
*/
public static String strToDecode(String str) {
char[] tmp = str.toCharArray();
// System.out.println(Arrays.toString(tmp));
StringBuffer sb = new StringBuffer("");
for (int i = 0; i < tmp.length; i++) {
sb.append("&#").append((int) tmp[i]).append(";");
}
return sb.toString();
}
public static void main(String[] args) {
String decode1 = HTMLDecoder.decode("一坨代码");
System.out.println(decode1);
String code1 = HTMLDecoder.strToDecode("一坨代码");
System.out.println(code1);
}
}
高水位线的回收以及trustcate关键字的使用
/*
下面有关sql 语句中 delete、truncate的说法正确的是?()
正确答案: A C
论清理表数据的速度,truncate一般比delete更快
truncate命令可以用来删除部分数据。
truncate只删除表的数据不删除表的结构
delete能够回收高水位(自增ID值)
1:处理效率:drop>trustcate>delete
2:删除范围:drop删除整个表(结构和数据一起删除)
trustcate删除全部记录,但不删除表结构;delete只删除数据
3:高水位线:delete不影响自增ID值,高水线保持原位置不动
trustcate会将高水线复位,自增ID变为1
注意:
trustcate是删除表的,然后重新建一个空的新表
高水位线的意思就是你如果使用delete删除数据
虽然删除数据了
但是数据库容量并没有减少
也就是使用delete语句删除数据时高水位线之涨不降
可以理解为一个包装盒只拿走了里面的东西
还留着外包装继续占有空间
除非使用trustcate语句
使用select语句查询数据时,数据库会扫描高水位线以下的数据块
因为高水位线没有变化,所以扫描的时间不会减少
所以才会出现使用delete删除数据以后,查询的速度还是和delete以前一样
*/
















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











