







定义
先来看看百度百科的定义:exp函数
exp,高等数学里以自然常数e为底的指数函数,它同时又是航模名词,全称Exponential(指数曲线)。在医药说明中,EXP是指使用期限,即Expiry date(Exp date) 。除此之外,EXP(Expedition) 是世界著名项目管理软件供应商美国Primavera公司的主要产品之一,是国际规范的施工管理和合同及建设信息管理软件。exp还指行业软件的高级专家版,在灵活性和功能上比专业版(pro)更加强大,也更加复杂。
高等数学
高等数学里的以e为底的指数函数。
例:EXP{F(X)}是e的F(X)次方。
C语言
Exp:返回e的n次方,e是一个常数为2.71828
函数名: exp
功 能: 指数函数
用 法: double exp(double x);
所属库:math.h
实例
代码
//计算e的n次方
#include <bits/stdc++.h>
using namespace std;
int main()
{
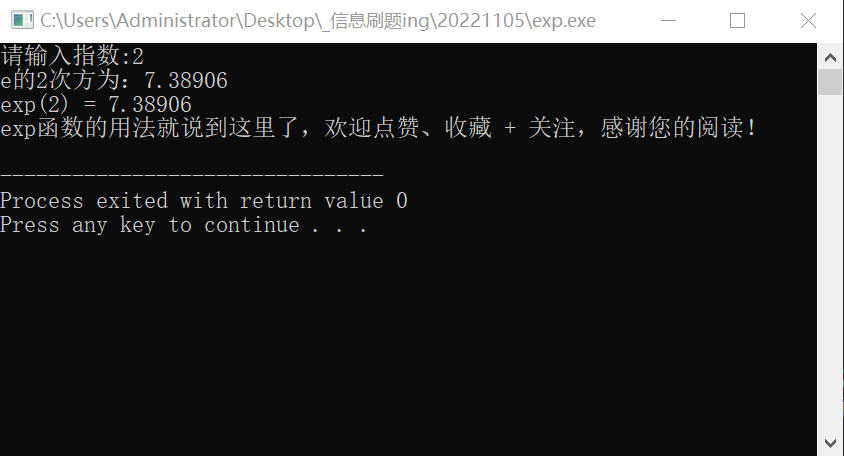
double x;
cout << "请输入指数:";
cin >> x;
double y = exp(x);//返回e的x次方
cout << "e的" << x << "次方为:" << y << endl;
cout << "exp(" << x << ")" << " = " << y << endl;
cout << "exp函数的用法就说到这里了,欢迎点赞、收藏 + 关注,感谢您的阅读!" << endl;
return 0;
}
运行结果


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









