






Large language multimodal models for new‑onset type 2 diabetes prediction using five‑year cohort electronic health records
使用五年队列电子健康记录预测新发2型糖尿病的大型语言多模式模型
Scientific Reports
大语言模型只做文本方面的工作,输出文本方面的特征,与临床数据特征共同做二型糖尿病预测
2型糖尿病 (T2DM) 是世界各国面临的普遍健康挑战。 在本研究中,我们提出了一种新颖的大型语言多模态模型 (LLMMs) 框架,该框架整合了来自临床笔记和实验室结果的多模态数据,用于糖尿病风险预测。 我们从台湾一家医院数据库中收集了 2017 年至 2021 年五年的电子健康记录 (EHRs)。 此数据集包括 1,420,596 条临床笔记、387,392 项实验室结果和 1505 项以上的实验室检测项目。 我们的方法结合了文本嵌入编码器和多头注意力层来学习实验室值,并利用深度神经网络 (DNN) 模块将血液特征与慢性病语义融合到一个潜在空间中。 在我们的实验中,我们观察到将临床笔记与基于文本实验室值的预测相结合,显着增强了单模态模型在早期检测 T2DM 方面的预测能力。 此外,我们在新发 T2DM 预测的接收者操作特征曲线 (AUC) 下获得了大于 0.70 的面积,这证明了利用文本实验室数据进行 LLMs 训练和推断的有效性,并提高了新发糖尿病预测的准确性。
电子健康记录 (EHRs)
特别是,更多的研究集中在使用 EHR 和自然语言处理 (NLP) 来预测慢性疾病 7, 。 随着 EHR 数量的不断增加,结构化和非结构化数据类型(如文本、CT 扫描、MRI 图像等)在深度学习研究中得到更频繁的应用 9 。 例如,研究人员使用 NLP 模型从 中识别心血管疾病 (CVD) 或在过敏、哮喘和免疫学诊所进行研究 11 。 此外,过去几年开发的现有 NLP 模型仅依赖文本数据或 ICD 代码,很难诊断 T2DM 或慢性代谢疾病 12, 。
近年来,大型语言模型(LLM)已使用大型语料库成功训练,并在自然语言处理任务中显示出显着的有效性14,。 最流行的研究使用开放数据集,例如重症监护医疗信息集市 (MGH) 收集的 MIMIC 系列 16 。 此类数据集包括数值、类别和其他格式。 但是,MIMIC 数据受到样本量小的限制,并且不能充分代表 LLM 诊所和训练任务所需的数据格式多样性。 许多关于 LLM 的医学研究面临着由于临床记录 17 的语料库样本的可用性有限而受到的限制,例如 MIMIC 或英国生物银行数据集 18 ,或者可能与特定疾病相关的固有不平衡 19 。 这些限制可能会导致 LLM 在临床环境中的预测能力和可用性出现偏差。 这些模型在大量文本数据上进行训练,使它们能够辨别嵌入在单词和短语中的复杂统计关系。 此外,研究人员已开始将模态数据与 LLM 结合起来 20 。 此方法解决了数据提取的复杂性以及使用表格数据进行文本建模相关的挑战。 此类 NLP 应用包括文本分类 21,甚至延伸到复杂的医学领域中的临床预测领域 23,。
在这项研究中,我们提出了一种新颖的大型语言多模态模型 (LLMM) 框架,该框架集成了临床笔记和文本实验室值,用于新发 2 型糖尿病的预测。 我们工作的主要贡献如下:
• 我们收集了五年的 EHR 和实验室结果,以研究使用 LLM 和多模态数据来预测新发 T2DM。
• 我们提出了一种将实验室值转换为文本并评估其在训练 LLM 中有效性的方法。 这种方法解决了患者数据缺失问题,并提高了 LLM 的上下文学习能力。
• 我们提出了一种使用 LLM 结合 Shapley Additive exPlanations (SHAP) 25 值来可视化文本实验室值的后验解释和疾病风险评估方法。
SHAP值通过为每个输入特征生成一个贡献度值,帮助用户理解模型如何根据输入数据作出决策。
相关研究
机器学习方法的局限性
本节考察了经典 ML 技术(如 SVM 和 XGBoost 26)在处理大型 EHR 时存在的缺点。 这些方法受到 EHR 数据固有复杂性的挑战,例如缺失条目、样本量倾斜以及处理海量数据集 26 的计算负担。 虽然 XGBoost 的树结构缓解了其中一些挑战,但传统 ML 方法仍然存在一个重大局限性;它们无法有效地使用各种数据模态(包括文本、图像和表格数据)对疾病进行建模和预测。
临床环境中的预测评估对于估计患者患病风险、他们对治疗的潜在反应以及其病情的可能发展至关重要 27 。 传统上,机器学习方法如逻辑回归 28 和随机森林 29 已被用于这些疾病预测任务。 但是,这些方法的一个主要局限性是它们无法有效地模拟医疗事件的时间依赖性,例如诊断、手术和药物出现的顺序。 相反,它们通常主要关注这些事件作为特征是否存在,而没有考虑其序列的重要性。
数据收集和研究设计
在本研究中,我们从 2017 年到 2021 年收集了来自台湾远东纪念医院 (FEMH) 医院数据库的五年电子健康记录 (EHR),包括 1,420,596 份临床记录、387,392 份实验室结果和 1505 多项实验室检验项目。 数据库包含临床记录和实验室结果,如表 2 所述。 本研究已获得 FEMH 伦理审查委员会批准(https:// www. femh-irb. org/),数据已脱敏。 所有伦理审查工作和数据收集均按照伦理委员会的标准指南和规章进行(https:// www. femh-irb. org/ index. php/ regulations)。
在本研究中,我们采用多阶段过滤过程,重点关注与临床相关的,特别是新发 2 型糖尿病患者的信息。 我们的数据收集和预处理工作流程如附图 2 A、C 所述,并遵循以下步骤:首先,我们过滤患者的病历,只包括门诊就诊记录。 接下来,我们确定了第一次发病检测记录之间时间差最小的门诊就诊记录,如图 2 B 所示。 此次就诊可能代表最接近 2 型糖尿病初始检测的会诊。 最后,我们将最接近 2 型糖尿病新发病的记录包含在我们的训练样本中。 如果个体在 2 型糖尿病诊断前记录了两次连续异常的实验室值,则将其识别为阳性样本。 具体来说,这些值是血红蛋白和空腹血糖。 表 1 显示了进行全面生化检测的新发糖尿病患者的人口统计信息。 此过滤后的数据作为我们研究中预训练大语言模型的基础,我们还扩展了 31 个标准的与 2 型糖尿病相关的指标作为我们大语言模型中的输入特征进行预测;这些详细的指标列在“附录”中。 为了增强大型语言模型处理非结构化数据的能力,我们将结合数值到文本的编码方法用于患者的实验室数值。 关于此方法的更多细节将在部分提供。 表 2 简要概述了我们的输入数据格式,详细说明了临床记录以及数值和文本形式的实验室值。 其余部分由数值数据组成,其中明确包含与实验室结果相关的项目。
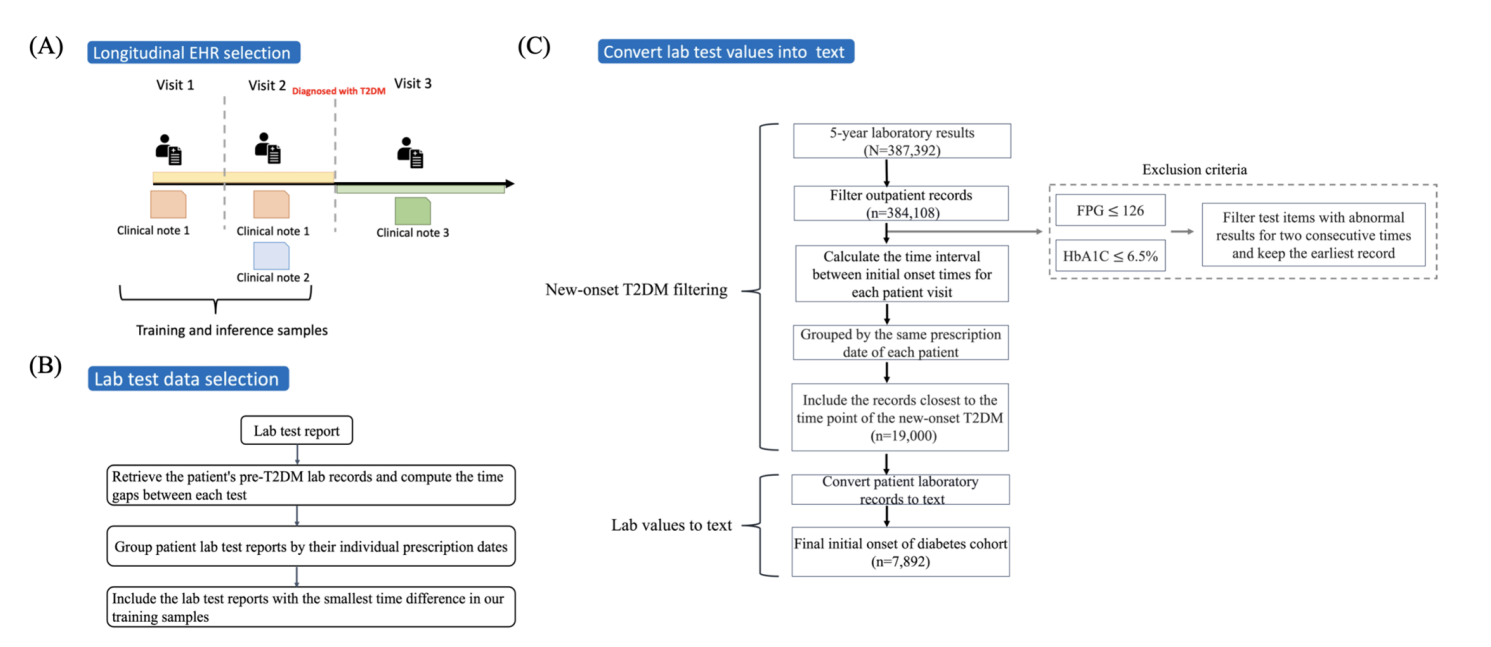
图 2. 研究方法包括对 EHR 和实验室测试中 T2DM 的研究程序。 面板 (A) 说明了过滤纵向 EHR 数据以获得新发 T2DM 患者的过程。 面板 (B) 描绘了通过选择连续访问之间最短的时间间隔对患者的实验室测试数据进行分组的过程。 专家小组 © 展示了整个数据预处理步骤,包括过滤新发 2 型糖尿病病例并将最终值转换为文本格式。
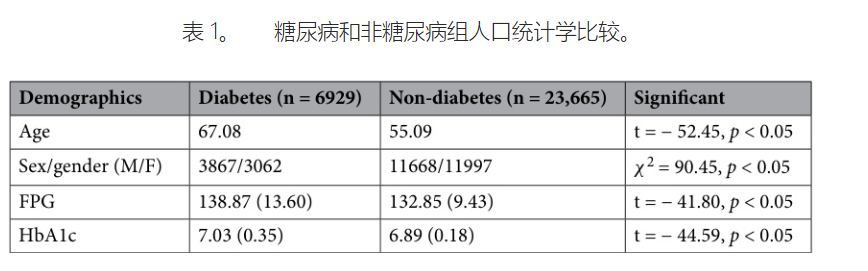
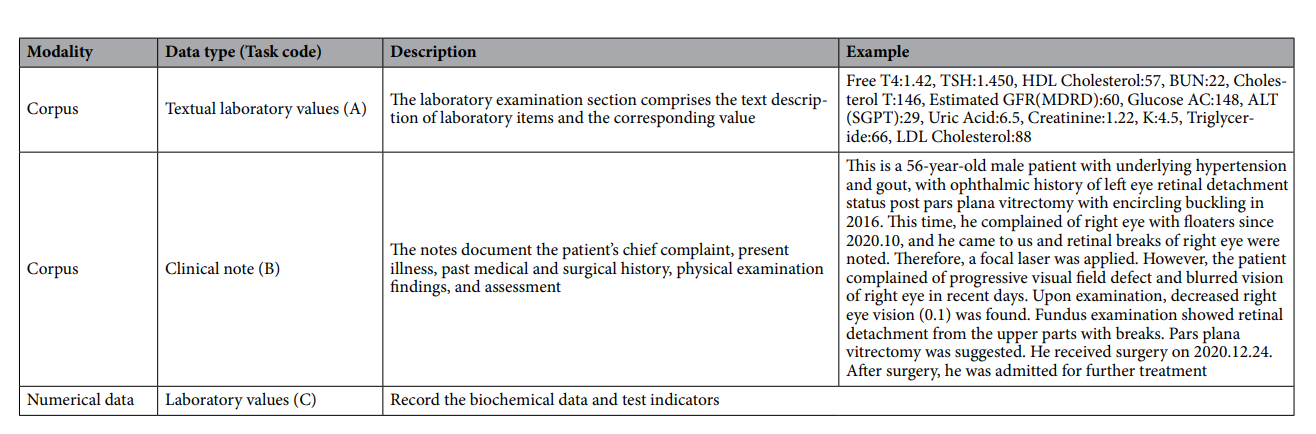
表 2。 LLMMs 训练格式概述,包括语料库和模式细节。
方法
大型语言多模态模型
大多数大型语言模型 (LLM) 可以在应用于下游模型之前,使用大规模文本数据进行训练。 然而,大多数电子健康记录 (EHR) 包含数值信息(例如,年龄、住院时间和实验室值)和类别信息,这限制了大型语言模型在模态数据上的预测任务。 在我们的研究中,我们研究了两种预训练方法:(1)我们使用了一种多模态技术,该技术将文本嵌入编码器与融合在实验室数据上的多头注意力机制相结合(2)我们将患有慢性病患者的实验室结果转换为文本数据,并将文本化实验室文本进行标记化,以预训练大型语言模型。
在我们的第一个子模型管道中,我们开发了一种大型语言模型预训练单模态方法,用于从 EHR 语料库中提取文本特征嵌入,如图 1b(顶部)所示。我们使用了诸如 BERT 41、RoBERTa 42、BiomedBERT 43、Flan- 和 GPT- 等主要的语言单模态方法,对我们的 FEMH 语料库进行各种标记化和预训练技术,使模型能够理解大量的特定领域的临床知识和上下文语义。
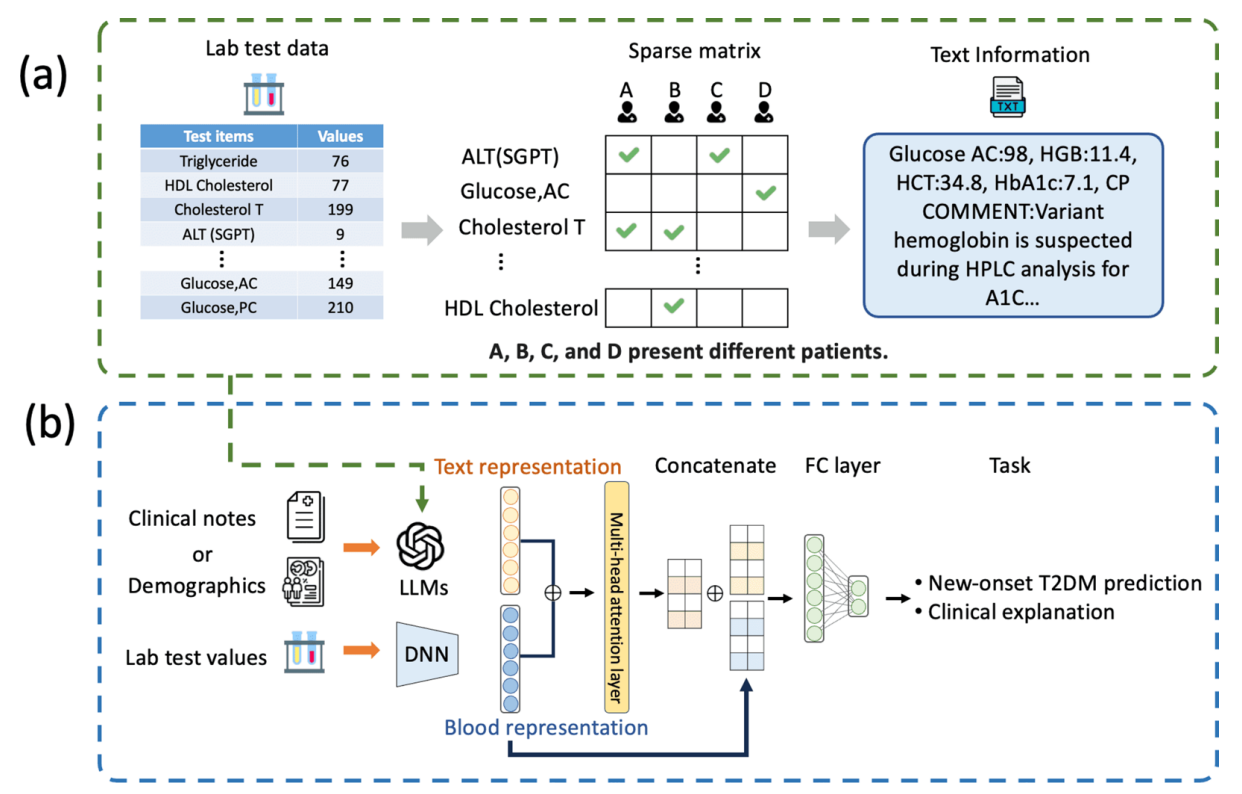
图 1. LLMMs 的整体框架。 面板 (a) 显示了对实验室数值进行文本化后训练语言模型的数值到文本。 面板 (b) 演示了 LLMMs 提出了单模态语言模型和 DNN 模块,以从临床笔记和实验室数值中提取和嵌入特征。 然后,使用多头注意力模块进行最终的特征融合,用于下游分类任务。
大型定量特征编码
对于我们的特征选择,我们选择了与 T2DM 相关的具有代表性的实验室检验项目作为我们的第二个子模型输入,如“附录”所示。 从临床角度来看,这种方法允许大型语言多模态模型识别具有相似 T2DM 风险的群体。 我们首先通过用平均值插补来处理每个血液检查中的缺失值。 然后,使用 Z 分数对数据进行标准化。 在训练过程中,使用一个简单的深度神经网络 (DNN) 来提取关键的血液检查特征,如图 1b(底部面板)所示。 随后,这些提取的特征与单模态语言模型已经学习到的文本潜在特征相结合。 然后,将此子模型与大型语言模型集成,在潜在空间中融合组合特征,同时结合提取的血液检查特征和来自 T2DM 语料库的语义信息。
• 血液检测项目:eGFR (MDRD)、CRP、高敏CRP、HDL胆固醇、LDL胆固醇、血糖PC 120分钟、血糖PC 90分钟、随机血糖、载脂蛋白A1、血糖、PC 15分钟、总胆固醇、肌酐、随机血糖 (POCT)、Na、血糖PC、血糖AC、HGH (生长激素)、总LDH、血糖 PC 180分钟、HbA1c、C肽6分钟、血糖PC 60分钟、BUN、血糖AC (POCT)、K、eGFR (CKD-EPI 胱抑素C)、血糖PC 30分钟、甘油三酯、ALT (SGPT)、AST (SGOT)、肌酐 (POCT)。
多头注意力融合
我们设计了一个注意力模块来计算两个领域嵌入以获得注意力分数,并提高各个单模态对整体模型预测的贡献。 我们将两个嵌入连接起来,一个是来自 LLM 编码器的文本表示,另一个是来自 DNN 输出的血液表示。 因此,我们使用了一个多头注意力模块来促进潜空间中来自两个领域的特征的改进融合。 此注意力机制允许我们对文本和血液向量执行点积运算。 我们将嵌入向量连接为注意力模块的查询、键和值,以生成注意力加权矩阵。 通过比较查询和键的相关性,注意力权重确定每个值在回答当前查询时的重要性,其中较高的注意力权重表示该值对于查询解析的更大意义。 接下来,为了增强潜在特征融合,我们将来自多头注意力嵌入的最终连接编码特征与 LLMs 和 DNN 输出向量一起用于最终的全连接层。 此外,为了可视化可解释的上下文文本并提供相应的权重,我们计算了基于 LLMMs 的注意力权重输出的 Shapley 值,在“文本实验室结果的可解释注意力”部分提供了我们上下文语料库的全面解释能力。
实验室值的文本转换
传统上,疾病建模主要依赖于数值实验室值。 然而,对于大多数血液检测项目,存在不同的患者具有不同的测量项目或测量在不同时间点进行的情况,这导致了实验室值稀疏的问题,如图 1a 所示。近期研究利用了手动插入相同模板作为伪笔记(例如,“鉴于生命体征:脉搏为 {值}…”)到文本实验室值中 46。 受此观点的启发,我们在数值到文本转换过程中考虑了更细致的方法,我们计算了训练数据中每个患者在糖尿病发病前所有记录与最近糖尿病发病点之间的时间差。 随后,我们根据这些记录与糖尿病发病的时间接近程度将它们分组。 我们的训练数据集包含从护理报告的 SOAP(主观、客观、评估、计划)部分中提取的客观信息。 这些报告包括以下条目:“血压/脉搏测量上传数据 - :mmHg;PR:72/分钟 [OU],无明显糖尿病性视网膜病变 。 这些非结构化数据包含由专业护士记录的生命体征和实验室检测结果,从而保留了关于患者的重要症状信息。
为了应对这一挑战,我们首先遵循既定流程从患者数据中提取实验室值数据,然后进行非文本序列化编码并生成编码器到文本的嵌入。 这为我们的LLM模型促进了更直接的语料库编码。 此方法减轻了测试项目中数据稀疏的问题,并克服了LLM模型仅根据数值特征预测文本结果的局限性。 此外,它还有助于解决患者大部分实验室检测项目数据缺失的情况。
结果
单模态方法比较
在我们的研究中,我们最初使用传统的机器学习方法验证了单模态的定量指标。 我们选择常用的机器学习算法作为评估单模态实验室测试值的基线,包括逻辑回归、K近邻 (KNN)、K均值、支持向量机 (SVM)、随机森林、XGBoost、CatBoost和深度神经网络 (DNN)。 在表3中,我们可以观察到,诸如逻辑回归之类的线性分类器的准确率仅为0.79,而KNN和K均值则表现出更好的性能。 基于树的方法,如随机森林、XGBoost和CatBoost,能够在不同的指标测量下有效地达到高于0.85的准确率。 最后,我们将三层DNN在定量指标上的性能进行了比较,发现其在精确率和召回率方面性能较低。 值得注意的是,上述实验结果表明,虽然在单模态上使用机器学习方法具有一定的预测能力,但它受到基于非结构化数据进行预测的限制。
早期2型糖尿病预测的模态数据
为了改善在出现临床症状之前的早期预测和2型糖尿病风险,这项任务使用了基于相关临床记录或实验室值的预测模型,将其制定为一个二元分类问题。 我们评估了三种数据格式作为LLM模型训练的输入:(A) 文本形式的实验室值,(B) 临床记录,以及 © 实验室值。 之后,我们根据不同的NLP框架或LLM模型架构的单模态语言模型评估了早期2型糖尿病预测,如表3所示。
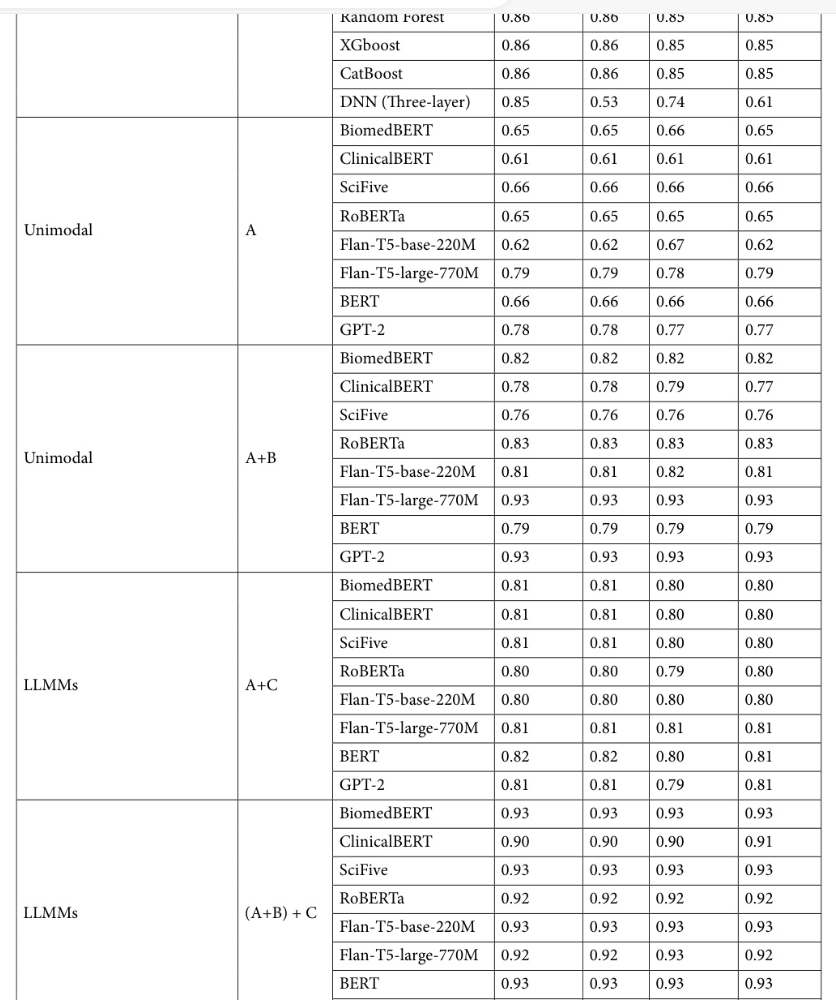
基于文本实验室语料库的纵向2型糖尿病风险预测
目前大多数临床环境中的实践依赖于血液检查来确认2型糖尿病的初步诊断。 为了主动预测患2型糖尿病的风险,我们估计了在90、180、270和365天的时间间隔内新发2型糖尿病的可能性。 然后,我们使用AUC和精确率-召回率曲线下面积(AUPRC)指标评估了模型的性能。 为了训练和评估我们的模型,我们首先从文本实验室数据中选择了具有2型糖尿病发病记录的患者,并将其与相同数量的随机抽样的阴性样本相结合。
图3说明了各种单模态语言模型在不同时间段(T天)预测2型糖尿病发病情况的性能。 值得注意的是,实验室报告的文本后处理有助于减轻我们训练数据集中数据样本不平衡的挑战。 此外,实验表明,对于各种 LLM,在不同的预测时间范围内,预测性能始终如一且稳定。 有趣的是,一些模型甚至在预测窗口增加时表现出性能提升。 例如,BiomedBERT 在提前 365 天做出的预测中实现了 0.72 的 AUC 和 AUPRC。 同样,更大的 Flan-T5 模型在所有预测阶段都保持了高于 0.70 的 AUC 和 AUPRC。
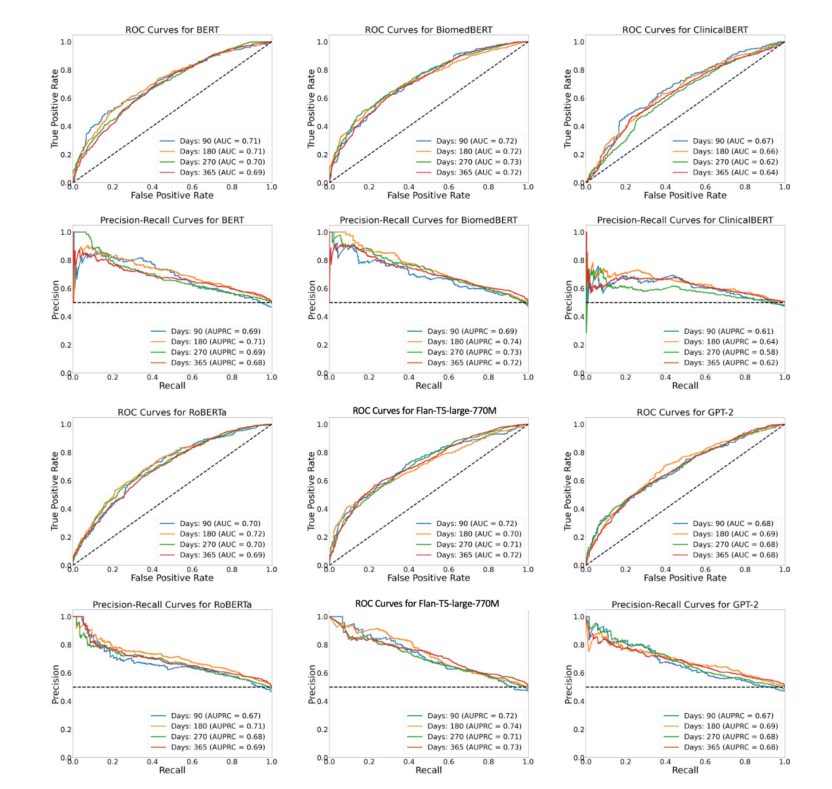
图 3. 评估不同单模态 LLM 在提前 T 天预测早期 T2DM 中的性能,这些模型是在文本实验室值上训练的。
文本实验室结果的可解释注意
SHAP 源于博弈论,并生成 Shapley 值来解释特征的重要性。 尤其是在出血性卒中数据(例如,时间序列生命体征)中,基于 SHAP 的方法已被用作特征重要性解释的基线 48。 在基于 SHAP 的 EHR 可解释性研究中,通过 SHAP 分析识别出了预测各种疾病的最重要临床特征。 此分析结合了预训练的 Word2Vec 嵌入,以及双向门控循环单元 (BiGRU) 架构 49 或用于临床笔记可视化和解释的多模态 Transformer 50。 鉴于 LLM 在上下文理解方面的卓越能力,我们提出了一种可解释的方法来分析文本实验室值和临床笔记的复杂语料库。 我们的方法利用这种上下文优势来提供有意义的解释。 我们首先对 LLM 进行预训练,以在编码过程中强调词语位置,这允许计算注意分数。 随后,我们利用 SHAP 值分析了临床笔记和文本实验室数据的组合语料库。 此可视化工具有助于我们理解语料库中单词的个体贡献。 通过突出显示每个词对从 LLM 输出预测特定临床术语的正面或负面影响,SHAP 值增强了模型的临床解释能力。
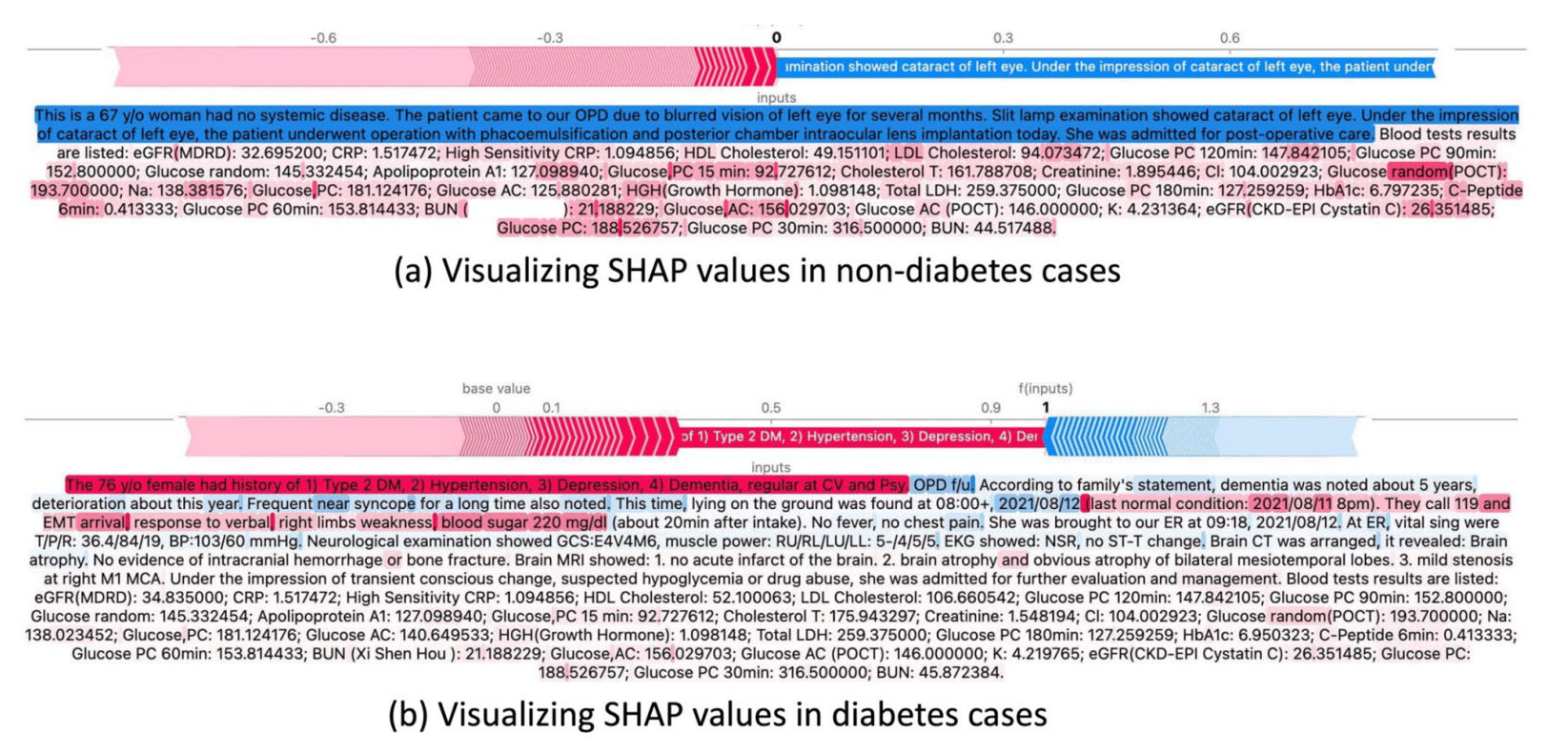
图 4。 使用 SHAP 值对糖尿病患者和非糖尿病患者的解释样本进行比较和可视化。
图 4 展示了使用 SHAP 值对非糖尿病患者进行样本分析。 红色突出显示表示与疾病发作风险较高的词语相关,而蓝色突出显示表示与该病例相关的较低风险因素。 此可视化揭示了临床指标与预测结果之间复杂的相互作用。 在图 4a 中,重点关注实验室文本数据中的非糖尿病病例,较浅的颜色代表低风险测试项目。 这些指标包括葡萄糖和 A1C 水平等关键指标,它们可以提供潜在 T2DM 的早期预警信号。 相反,我们使用图 4b 所示的糖尿病患者案例,分析了 SHAP 值在特征重要性方面的有效性。 此案例描述了一名糖尿病患者,该患者有多种慢性病史,血糖水平为 。 我们的分析表明,影响最大的特征是 T2DM,而其他对预测结果贡献显著的重要特征包括高血压、抑郁症和痴呆症等各种健康状况。 通过识别和分析叙述中的关键关键词,该模型揭示了文本数据与 T2DM 结果之间的错综复杂的关系,提供了对预测过程的全面洞察。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









