






以下是博主的一些个人经验,如果有不对或者不全面的地方,欢迎大家在评论区讨论,后续再做增删
需要数据洗牌的强化学习算法
- 基于经验回放(Experience Replay)的算法
典型算法:
DQN 及其变种(Double DQN、Dueling DQN 等)
DDPG、TD3、SAC
原因:
通过回放缓冲区存储大量历史样本,需随机采样以打破时序相关性,提升样本多样性。举个例子,在一个雷霆战机游戏中,刚开始一直采取射击就能获得高额收益,此时可能前100个动作都会选择射击而不移动,这是不合适的,在训练过程中不利于收敛,或者另一个角度来看,如果把强化学习类比分类任务,如果不打乱顺序,可能会出现“学习遗忘”的现象,不利于网络的训练
不需要数据洗牌的强化学习算法
- 纯在线策略算法(On-Policy)
典型算法:
PPO(Proximal Policy Optimization)
REINFORCE、A2C、A3C、TRPO
原因:
严格依赖时序连续性:
PPO 的优势函数(如 GAE)计算需按时间顺序累积回报(如R_t = r_t + γr_{t+1} + γ²r_{t+2} + …),洗牌会导致奖励分配错误。
策略更新时,新旧策略的概率比率(π_θ(a|s)/π_{θ_old}(a|s))需对应同一轨迹的状态 - 动作对,乱序会破坏这一约束。
在线策略特性:
数据仅使用一次,无需回放缓冲区,保持原始轨迹顺序可确保梯度估计的无偏性。 - 时序敏感型算法
典型场景:
时间序列预测(如股票价格、传感器数据)
基于 LSTM 的序列决策模型
原因:
数据的时序关系本身是核心信息(如 “过去状态→未来状态” 的因果链),洗牌会破坏动态规律。
PPO 的特殊处理(易混淆点)
- PPO 的 Mini-Batch 训练≠数据洗牌
PPO 允许将轨迹数据分割为多个 Mini-Batch 进行多轮优化(论文中通常为 3-10 次迭代),但需注意:
轨迹内顺序不可打乱:每个 Mini-Batch 必须包含完整的时序片段(如 t=1~20 步的连续数据),以保证 GAE 计算的正确性。
轨迹间可随机排列:不同轨迹的 Mini-Batch 可随机顺序输入,但单条轨迹内样本需保持原始顺序。 - 错误洗牌的后果
若完全打乱 PPO 数据(如随机混排所有时间步):
GAE 计算失效:未来奖励无法正确归因到当前动作,优势函数估计偏差大。
策略更新不稳定:新旧策略比率计算错误,可能导致策略剧烈震荡甚至发散。
总结对比表
算法类型 是否需要洗牌 关键原因
DQN、SAC ✅ 需要 依赖经验回放,需打破样本间时序相关性
PPO、A2C ❌ 不需要 优势函数计算依赖时序,在线策略无需历史数据
基于 LSTM 的序列模型 ❌ 不需要 网络结构显式建模时序依赖
行为克隆(专家轨迹) ❌ 不需要 需保留专家演示的动作顺序
PPO打乱数据顺序和不打乱顺序效果对比(平衡车模型)
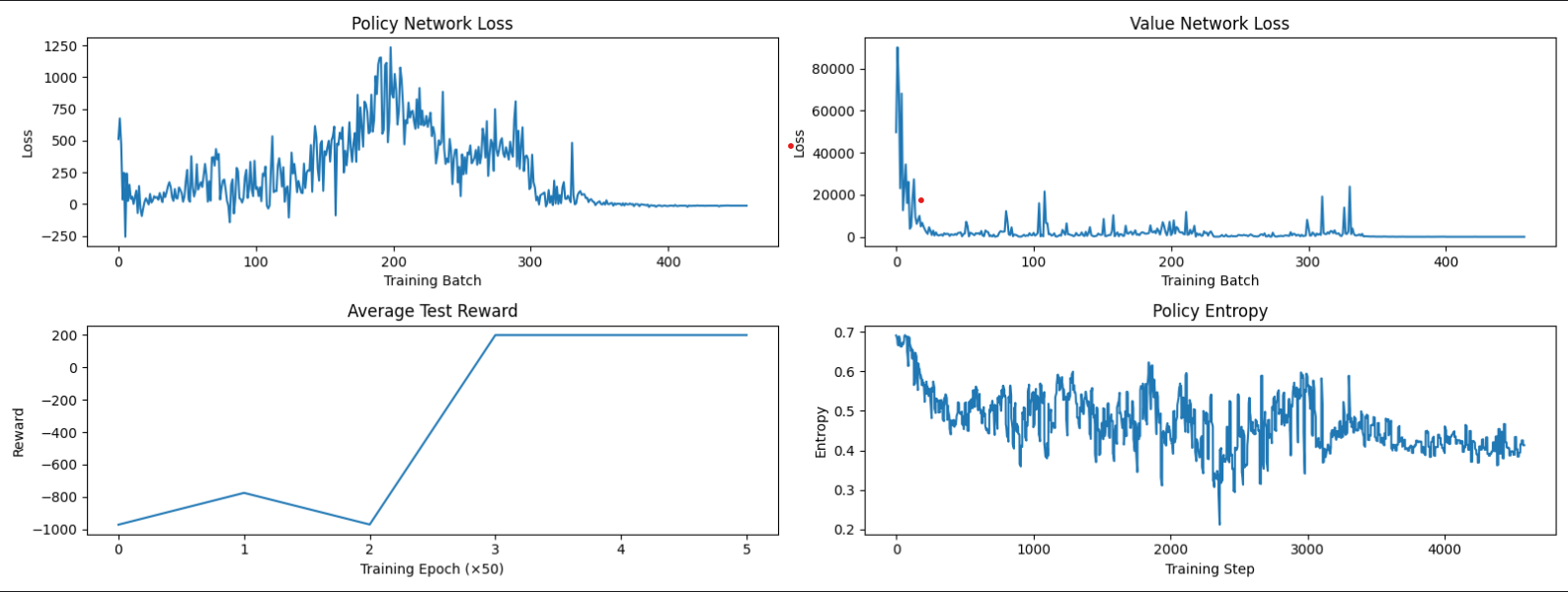
上图为PPO采用GAE优势估计,但数据顺序打乱
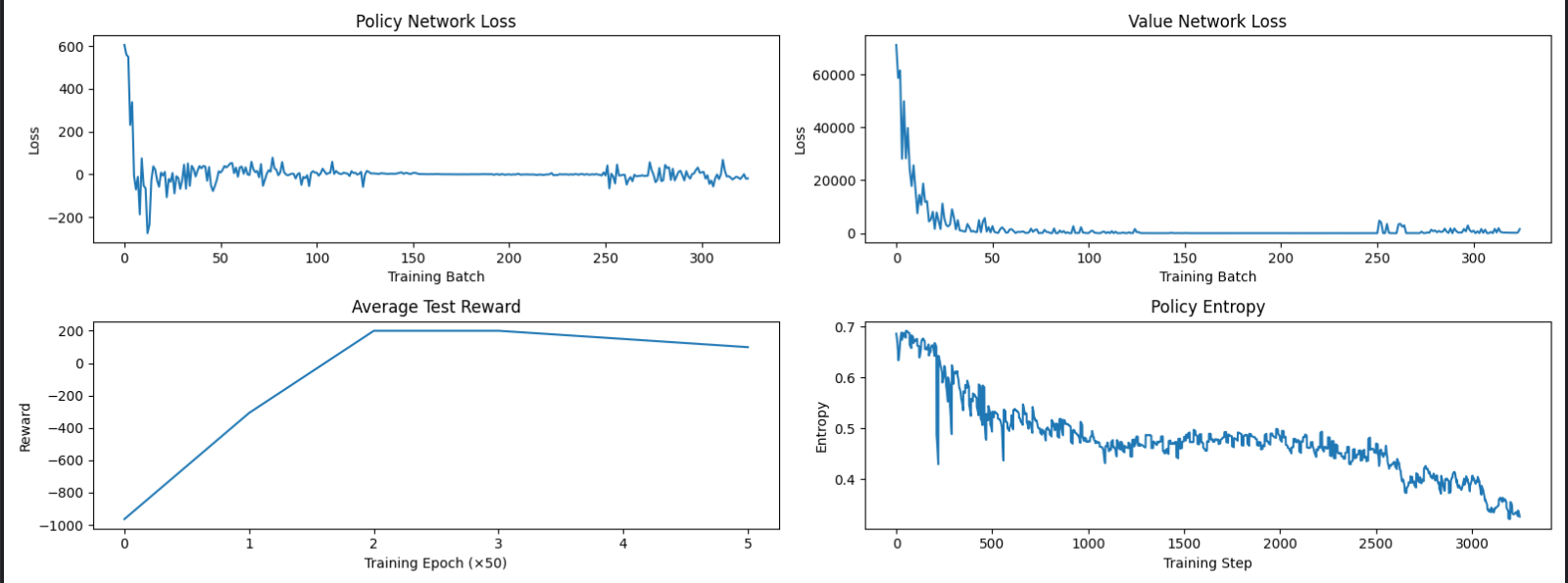
上图为PPO采用GAE优势估计,但顺序不打乱
两者效果还是有一定区别,而且这次数据顺序打乱随机运行出来的效果其实相对很好,有时甚至会出现不收敛的情况。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









