






 本文详细介绍了有监督学习和无监督学习的特点、区别,以及机器学习的建模流程,包括数据获取、预处理、特征工程、模型训练和评估。同时探讨了模型拟合问题及其产生原因,如欠拟合和过拟合。
本文详细介绍了有监督学习和无监督学习的特点、区别,以及机器学习的建模流程,包括数据获取、预处理、特征工程、模型训练和评估。同时探讨了模型拟合问题及其产生原因,如欠拟合和过拟合。
1.说明有监督学习和无监督学习的各自的特点及区别
有监督学习的特点:
-
输入数据是由输入特征值和目标值所组成, 即输入的训练数据是有标签的.
-
数据集: 需要人工标注数据.
-
无监督学习的特点:
-
输入的数据没有被标记, 没有标签;
-
根据样本间的相似性, 对样本集聚类, 以发现事物内部的结构及相互关系.
区别:
有监督学习输入的数据是有标签的, 而无监督学习输入的数据是无标签的。区别如下图:

2. 说明下机器学习的建模流程
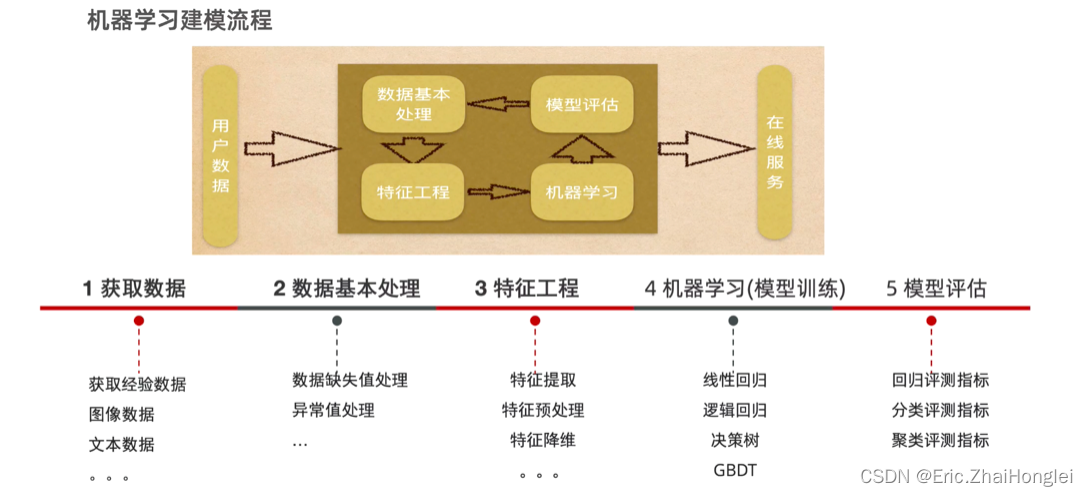
1. 获取数据
2. 数据基本处理
3. 特征工程
4. 机器学习(模型训练)
5. 模型评估
注意:
在整个建模流程中, 数据基本处理 和 特征工程 一般是耗时, 耗精力最多的!!!
3.说下模型拟合问题及产生的原因
模型拟合会出现三种情况:
-
刚好拟合: 表示模型对样本点的拟合情况刚刚好.
-
原因: 特征选取和模型选取及训练刚刚好.
-
-
欠拟合: 模型在训练集上表现很差、在测试集表现也很差.
-
原因: 模型过于简单.
-
-
过拟合: 模型在训练集上表现很好、在测试集表现很差.
-
原因: 模型过于复杂, 数据不纯, 训练数据太小.
-
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









