







如何使用Elasticsearch?
安装Elasticsearch
https://www.elastic.co/cn/downloads/elasticsearch
这里我们选择的是6.2.2版本的ES,因为我在spring-data-elasticsearch的github上看到最新版本的支持的ES是6.2.2
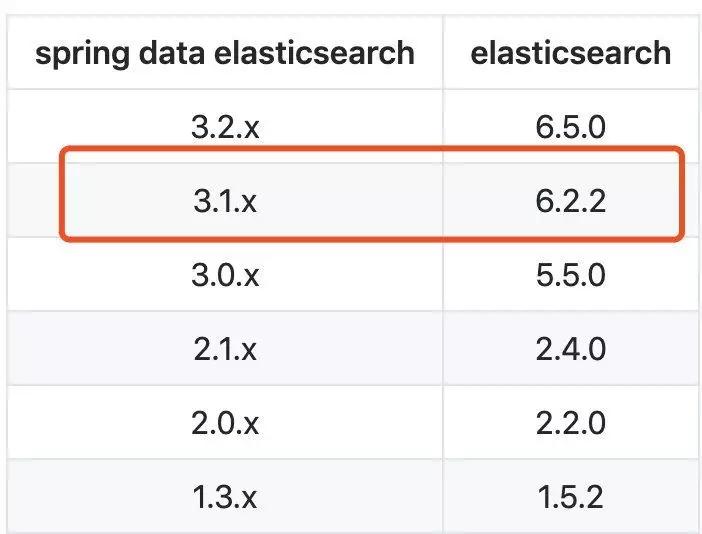
其中3.2.x版本尚未发布正式版,所以这里选择了最新的3.1.8版本,下面我们切换到安装目录的bin目录下,启动es:
./elasticsearch &
这里添加 & 符号的作用是让它在后台运行。

看到这个就说明启动成功了~
安装中文分词器iK
因为,在我们日常的应用中,我们用的比较多的都是中文的分词,所以这里我们需要一个中文的分词器
首先前往github上下载与ES版本对应的zip包
https://github.com/medcl/elasticsearch-analysis-ik/releases
然后在es的安装目录下的plugins下新建一个ik的目录,将zip包解压到该目录下重启es即可~

在es的启动日志中看到这个说明插件已经安装并启动成功!
到这里,我们的前期准备工作就已经结束了,下面的就是在Spring Boot项目中进行操作了~
**添加po
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
m依赖**
我们首先在pom.xml中添加spring-data-elasticsearch的依赖(敲黑板!!这里的版本一定要去参考一下对应的ES的版本,不然就会引起版本兼容性问题而报错!):
org.springframework.data
spring-data-elasticsearch
3.1.8.RELEASE
依赖已经添加完毕,下面我们就通过简单的配置来完成CRUD
CRUD
这里的配置需要注意一个点,我们访问的9200是HTTP的端口号,而使用Java的时候需要配置成9300:
spring:
data:
elasticsearch:
cluster-name: my-applicatioon
cluster-nodes: 127.0.0.1:9300
在启动日志中,我们可以看到这一点:

然后我们通过注解来完成一个index和mapping的创建(即对应关系型数据库中的库和表)
@Data
@Document(indexName = “test”,type = “article”)
public class Article implements Serializable {
private Long id;
@Field(type= FieldType.Text,analyzer = “ik_max_word”)
private String title;
private String content;
}
@Filed注解中的属性可以对分词器进行配置analyzer = “ik_max_word”,这样就可以在查询标题的时候使我们的中文分词器了~
这样,我们就创建了一个index(database)名为test,并新建一个type(table)名为article。
下面,我们如果想要完成CRUD,只需要创建一个接口去继承ElasticsearchRepository即可,如下:














 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









